 實現圖像識別神經網絡的步驟
實現圖像識別神經網絡的步驟
整理:python架構師 來源:python技術迷
我們的下一個任務是使用先前標記的圖像來訓練神經網絡,以對新的測試圖像進行分類。因此,我們將使用nn模塊來構建我們的神經網絡。
實現圖像識別神經網絡的步驟如下:
步驟1:
在第一步中,我們將定義一個類,該類將用于創建我們的神經模型實例。這個類將繼承自nn模塊,因此我們首先需要導入nn包。
from torch import nn class classifier (nn.Module):我們的類后面將是一個init()方法。在init()中,第一個參數將始終是self,第二個參數將是我們將稱為輸入節點數的輸入層節點數,第三個參數將是隱藏層的節點數,第四個參數將是第二隱藏層的節點數,最后一個參數將是輸出層的節點數。
def __init__(self,input_layer,hidden_layer1,hidden_layer2,output_layer):
步驟2:
在第二步中,我們調用init()方法以提供各種方法和屬性,并初始化輸入層、隱藏層和輸出層。請記住,我們將處理全連接的神經網絡。
super(),__init__() self.linear1=nn.Linear(input_layer,hidden_layer1) self.linear2=nn.Linear(hidden_layer1,hidden_layer2) self.linear3=nn.Linear(hidden_layer2,output_layer) def __init__(self,input_layer,hidden_layer1,hidden_layer2,output_layer):
專屬福利
點擊領取:最全Python資料合集
步驟3:
現在,我們將進行預測,但在此之前,我們將導入torch.nn.functional包,然后我們將使用forward()函數,并將self作為第一個參數,x作為我們嘗試進行預測的任何輸入。
import torch.nn.functional as func def forward(self,x):
現在,傳遞給forward()函數的任何輸入將傳遞給linear1對象,我們將使用relu函數而不是sigmoid。這個輸出將作為輸入傳遞到我們的第二隱藏層,并且第二隱藏層的輸出將饋送到輸出層,并返回最終層的輸出。
注意:如果我們處理的是多類別數據集,就不會在輸出層應用任何激活函數。
x=func.relu(self.linear1(x)) x=func.relu(self.linear2(x)) x=self.linear3(x) return x
步驟4:
在下一步中,我們將設置我們的模型構造函數。根據我們的初始化器,我們必須設置輸入維度、隱藏層維度和輸出維度。
圖像的像素強度將饋送到我們的輸入層。由于每個圖像都是28*28像素,總共有784個像素,將其饋送到我們的神經網絡中。因此,我們將784作為第一個參數傳遞,我們將在第一和第二隱藏層中分別取125和60個節點,在輸出層中我們將取十個節點。
model=classification1(784,125,65,10)
步驟5:
現在,我們將定義我們的損失函數。nn.CrossEntropyLoss() 用于多類別分類。該函數是log_softmax()函數和NLLLoss()函數的組合,NLLLoss是負對數似然損失。對于具有n個類別的任何訓練和分類問題,都使用交叉熵。因此,它使用對數概率,因此我們傳遞行輸出而不是softmax激活函數的輸出。
criteron=nn.CrossEntropyLoss()之后,我們將使用熟悉的優化器,即Adam。
optimizer=torch.optim.Adam(model.parameters(),lr=0.001)
步驟6:
在接下來的步驟中,我們將指定epoch的數量。我們初始化epoch的數量并在每個epoch分析損失。我們將初始化兩個列表,即loss_history和correct_history。
loss_history=[] correct_history=[]
步驟7:
我們將從迭代每個epoch開始,對于每個epoch,我們必須迭代由訓練加載器提供的每個訓練批次。每個訓練批次包含一百個圖像以及在train加載器中訓練的一百個標簽。
for e in range(epochs):
for input, labels in training_loader:
步驟8:
當我們迭代圖像的批次時,我們必須將它們展平,并使用view方法進行形狀變換。
注意:每個圖像張量的形狀是(1,28,28),這意味著總共有784個像素。
根據神經網絡的結構,我們的輸入值將與連接輸入層和第一隱藏層的權重矩陣相乘。為了進行這個乘法,我們必須使我們的圖像變為一維。我們需要將每個圖像從28行2列展平為784個像素的單行。
inputs=input.view(input.shape[0],-1)現在,借助這些輸入,我們得到輸出。
outputs=model(inputs)
步驟9:
借助輸出,我們將計算總分類交叉熵損失,并最終將輸出與實際標簽進行比較。我們還將基于交叉熵標準確定錯誤。在執行訓練傳遞的任何部分之前,我們必須像之前一樣設置優化器。
loss1=criteron(outputs,labels) optimizer.zero_grad() loss1.backward() optimizer.step()
步驟10:
為了跟蹤每個epoch的損失,我們將初始化一個變量loss,即running_loss。對于計算出的每個批次的每個損失,我們必須將其添加到每個單一批次的所有批次中,然后在每個epoch計算出最終損失。
loss+=loss1.item()現在,我們將將這個累積的整個epoch的損失附加到我們的損失列表中。為此,在循環語句之后使用else語句。因此,一旦for循環結束,那么將調用else語句。在這個else語句中,我們將打印在特定epoch計算的整個數據集的累積損失。
epoch_loss=loss/len(training_loader) loss_history.append(epoch_loss)
步驟11:
在接下來的步驟中,我們將找到網絡的準確性。我們將初始化正確的變量并賦值為零。我們將比較模型對每個訓練圖像的預測與圖像的實際標簽,以顯示在一個epoch中有多少個預測是正確的。
對于每個圖像,我們將取得最大分數值。在這種情況下,將返回一個元組。它返回的第一個值是實際的頂值-模型為該批次內的每個單一圖像制作的最大分數。因此,我們對第一個元組值不感興趣,第二個將對應于模型制作的最高預測,我們將其稱為preds。它將返回該圖像的最大值的索引。
_,preds=torch.max(outputs,1)
步驟12:
每個圖像輸出將是一個值的集合,其索引范圍從0到9,因為MNIST數據集包含從0到9的類。因此,最大值發生的位置對應于模型做出的預測。我們將比較模型對圖像的所有這些預測與圖像的實際標簽,以查看它們中有多少個是正確的。
correct+=torch.sum(preds==labels.data)這將給出每個圖像批次的正確預測數量。我們將以與epoch損失和準確性相同的方式定義epoch準確性,并打印epoch損失和準確性。
epoch_acc=correct.float()/len(training_loader)
print('training_loss:{:.4f},{:.4f}'.format(epoch_loss,epoch_acc.item()))
這將產生預期的結果,如下所示:
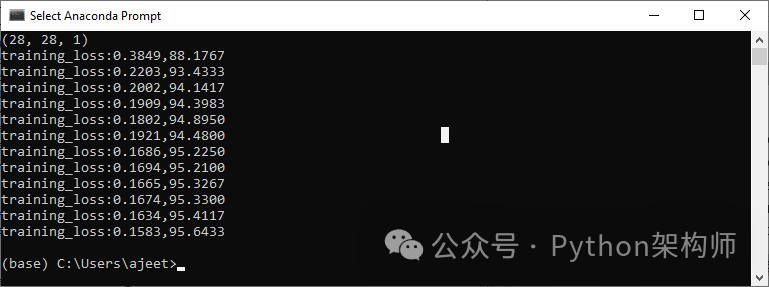
步驟13:
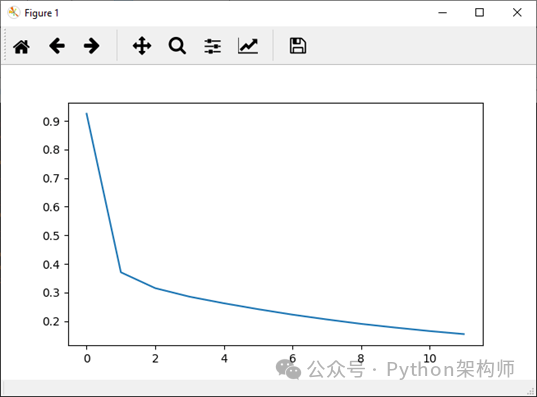
現在,我們將將整個epoch的準確性附加到我們的correct_history列表中,并為更好的可視化,我們將繪制epoch損失和準確性。
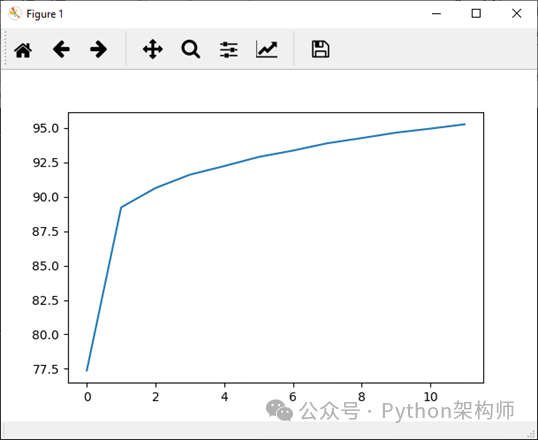
plt.plot(loss_history,label='Running Loss History') plt.plot(correct_history,label='Running correct History')Epoch Loss
Epoch accuracy
完整代碼
import torch
import matplotlib.pyplot as plt
import numpy as np
import torch.nn.functional as func
from torch import nn
from torchvision import datasets, transforms
transform1=transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.5,),(0.5,))])
training_dataset=datasets.MNIST(root='./data',train=True,download=True,transform=transform1)
training_loader=torch.utils.data.DataLoader(dataset=training_dataset,batch_size=100,shuffle=True)
def im_convert(tensor):
image=tensor.clone().detach().numpy()
image=image.transpose(1,2,0)
print(image.shape)
image=image*(np.array((0.5,0.5,0.5))+np.array((0.5,0.5,0.5)))
image=image.clip(0,1)
return image
dataiter=iter(training_loader)
images,labels=dataiter.next()
fig=plt.figure(figsize=(25,4))
for idx in np.arange(20):
ax=fig.add_subplot(2,10,idx+1)
plt.imshow(im_convert(images[idx]))
ax.set_title([labels[idx].item()])
class classification1(nn.Module):
def __init__(self,input_layer,hidden_layer1,hidden_layer2,output_layer):
super().__init__()
self.linear1=nn.Linear(input_layer,hidden_layer1)
self.linear2=nn.Linear(hidden_layer1,hidden_layer2)
self.linear3=nn.Linear(hidden_layer2,output_layer)
def forward(self,x):
x=func.relu(self.linear1(x))
x=func.relu(self.linear2(x))
x=self.linear3(x)
return x
model=classification1(784,125,65,10)
criteron=nn.CrossEntropyLoss()
optimizer=torch.optim.Adam(model.parameters(),lr=0.0001)
epochs=12
loss_history=[]
correct_history=[]
for e in range(epochs):
loss=0.0
correct=0.0
for input,labels in training_loader:
inputs=input.view(input.shape[0],-1)
outputs=model(inputs)
loss1=criteron(outputs,labels)
optimizer.zero_grad()
loss1.backward()
optimizer.step()
_,preds=torch.max(outputs,1)
loss+=loss1.item()
correct+=torch.sum(preds==labels.data)
else:
epoch_loss=loss/len(training_loader)
epoch_acc=correct.float()/len(training_loader)
loss_history.append(epoch_loss)
correct_history.append(epoch_acc)
print('training_loss:{:.4f},{:.4f}'.format(epoch_loss,epoch_acc.item()))
審核編輯:湯梓紅
-
神經網絡
+關注
關注
42文章
4717瀏覽量
100010 -
圖像識別
+關注
關注
9文章
514瀏覽量
38149 -
python
+關注
關注
53文章
4753瀏覽量
84081
原文標題:PyTorch 教程-圖像識別中神經網絡的實現
文章出處:【微信號:vision263com,微信公眾號:新機器視覺】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
使用Python卷積神經網絡(CNN)進行圖像識別的基本步驟
【uFun試用申請】基于cortex-m系列核和卷積神經網絡算法的圖像識別
基于賽靈思FPGA的卷積神經網絡實現設計
圖像預處理和改進神經網絡推理的簡要介紹
改進概率神經網絡實現紋理圖像識別
基于改進的神經網絡的紋理圖像識別
卷積神經網絡用于圖像識別的原理





 工商網監
工商網監
評論