 Sparse4D-v3:稀疏感知的性能優化及端到端拓展
Sparse4D-v3:稀疏感知的性能優化及端到端拓展
極致的感知性能與極簡的感知pipeline一直是牽引我們持續向前的目標。為了實現該目標,打造一個性能優異的端到端感知模型是重中之重,充分發揮深度神經網絡+數據閉環的作用,才能打破當前感知系統的性能上限,解決更多的corner case,讓系統更加魯棒。因此,在Sparse4D-v3中,我們主要做了兩部分工作,其一是進一步提升模型的檢測性能,另一是將Sparse4D拓展為一個端到端跟蹤模型,實現多視角視頻到目標運動軌跡端到端感知。
在Sparse4D-v2的落地過程中,我們發現其感知性能仍然具備一定的提升空間。
1. 首先,我們從訓練優化的角度對Sparse4D進行了分析。我們觀察發現以稀疏形式作為輸出的模型,大多數都面臨這個收斂困難的問題,收斂速度相對較慢、訓練不穩定導致最終指標不高。因此我們參考DETR-like 2D檢測算法,引入了最為有效的提升模型訓練穩定性的輔助任務——"query denoising",并將其在時序上進行了拓展;
2. 其次,我們觀察到相比以dense-heatmap做輸出的模型,以稀疏形式作為輸出的模型其距離誤差明顯要更大。經過分析與實驗論證,我們認為這是由于檢測框置信度不足以反應框的精度導致的。因此,我們能提出另外一個輔助訓練任務 "quality estimation",這個任務不僅讓模型的檢測指標更高,還在一定程度上加速了模型收斂;
3. 最后,為了進一步提升模型性能,我們還對網絡結構進行了小幅的優化。對于instance feature直接的特征交互模塊,我們提出decoupled attention,在幾乎不增加推理時延的情況下提升了感知效果。
除了可以獲得更高效的檢測能力以外,我們致力于發展稀疏感知框架的另一原因就是其能夠更容易的將下游任務(如跟蹤、預測及規劃)以端到端的形式擴展進來。因此,在Sparse4D-v3中,我們成功地將多目標跟蹤任務加入到模型中,實現了極致簡潔的訓練和推理流程,既無需在訓練過程中添加跟蹤約束,也無需進行任何的跟蹤后處理(關聯、濾波和生命周期關聯),并且NuScenes上的實驗結果證實了該跟蹤方案的有效性。我們希望Sparse4D-v3的端到端跟蹤方案會推動多目標跟蹤算法的快速發展。
1. Temporal Instance Denoising
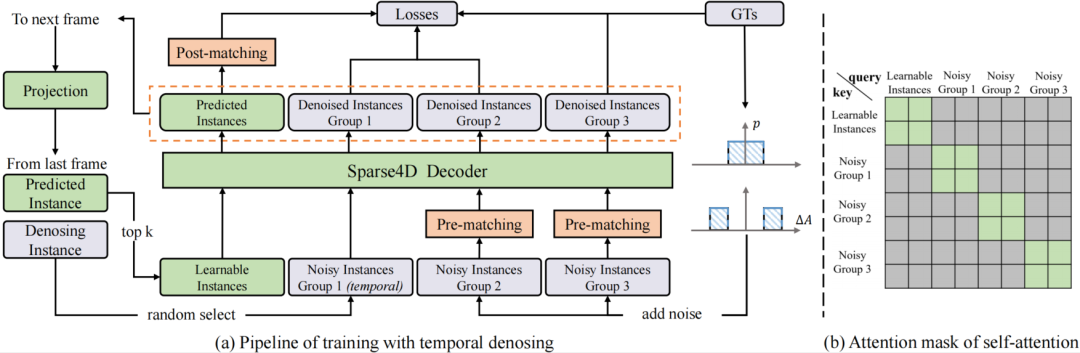
(a)中灰色和橙色模塊僅在訓練中使用,推理階段只需保留; (b)灰色方格代表attention mask=True。
我們對GT加上小規模噪聲來生成noisy instance,用decoder來進行去噪,這樣可以較好的控制instance和GT之間的偏差范圍,decoder 層之間匹配關系穩定,讓訓練更加魯棒,且大幅增加正樣本的數量,讓模型收斂更充分,以得到更好的結果。具體來說,我們設置兩個分布來生產噪聲Delta_A,用于模擬產生正樣本和負樣本,對于3D檢測任務加噪公式如下:
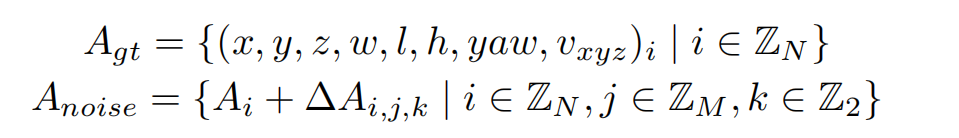
3D檢測加噪公式
加上噪聲的GT框需要重新和原始GT進行one2one匹配,確定正負樣本,而并不是直接將加了較大擾動的GT作為負樣本,這可以緩解一部分的分配歧義性。噪聲GT需要轉為instance的形式以輸入進網絡中,首先噪聲GT可以直接作為anchor,把噪聲GT編碼成高維特征作為anchor embed,相應的instance feature直接以全0來初始化。
為了模擬時序特征傳遞的過程,讓時序模型能得到denoising任務更多的收益,我們將單幀denoising拓展為時序的形式。具體地,在每個訓練step,隨機選擇部分noisy-instance組,將這些instance通過ego pose和velocity投影到當前幀,投影方式與learnable instance一致。
具體實現中,我們設置了5組noisy-instance,每組最大GT數量限制為32,因此會增加5*32*2=320個額外的instance。時序部分,每次隨機選擇2組來投影到下一幀。每組instance使用attention mask完全隔開,與DINO中的實現不一樣的是,我們讓noisy-instance也無法和learnable instance進行特征交互,如上圖(b)。
2.Quality Estimation
除了denoising,我們引入了第二個輔助監督任務,Quality Estimation,初衷一方面是加入更多信息讓模型收斂更平滑,另一方面是讓輸出的置信度排序更準確。對于第二點,我們在實驗過程中,發現兩個異常現象:
1.相比dense-based算法,query-based算法的mATE(mean Average-Translation Error)指標普遍較差,即使是confidence高的預測結果也會存在較大的距離誤差,如下圖(a);
2. Sparse4D在行人上的Precision-Recall曲線前半段會迅速降低,如下圖(b);
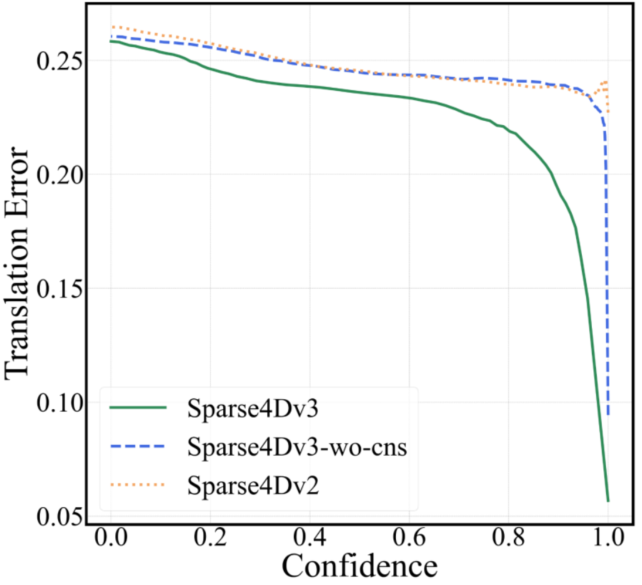
(a)confidence-translation error曲線,NuScenes val set
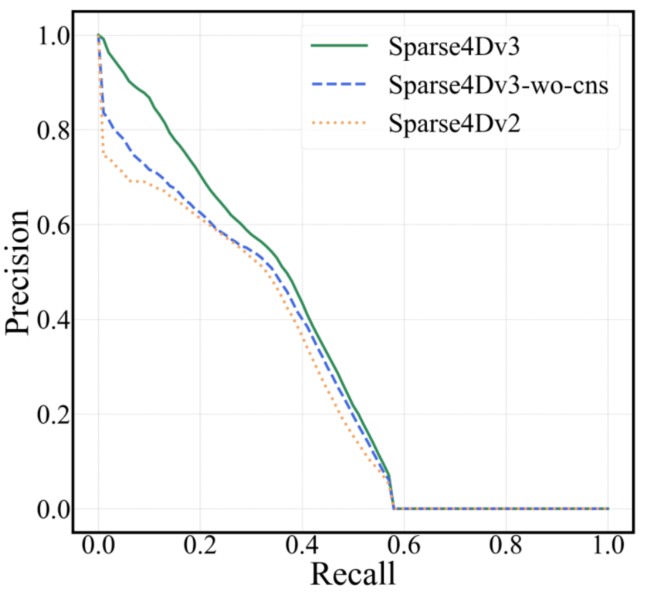
(b)precision-recall error曲線,NuScenes val set
上述現象說明,Sparse4D輸出的分類置信度并不適合用來判斷框的準確程度,這主要是因為one2one 匈牙利匹配過程中,正樣本離GT并不能保證一定比負樣本更近,而且正樣本的分類loss并不隨著匹配距離而改變。而對比dense head,如CenterPoint或BEV3D,其分類label為heatmap,隨著離GT距離增大,loss weight會發生變化。
因此,除了一個正負樣本的分類置信度以外,還需要一個描述模型結果與GT匹配程度的置信度,也就是進行Quality Estimation。對于3D檢測來說,我們定義了兩個quality指標,centerness和yawness,公式如下:
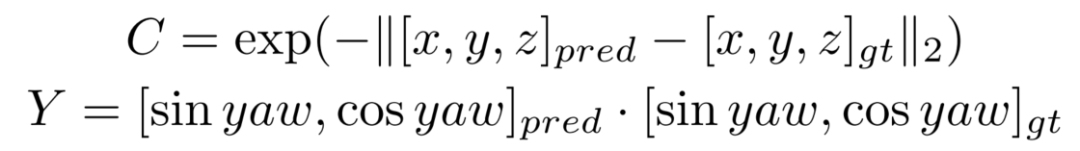
對于centerness和yawness,我們分別用cross entropy loss和focal loss來進行訓練。
從上圖的曲線來看,對比Sparse4D v3和v2,可以看出加入Quality Estimation之后,有效緩解了排序不準確的問題。
3. Decoupled Attention
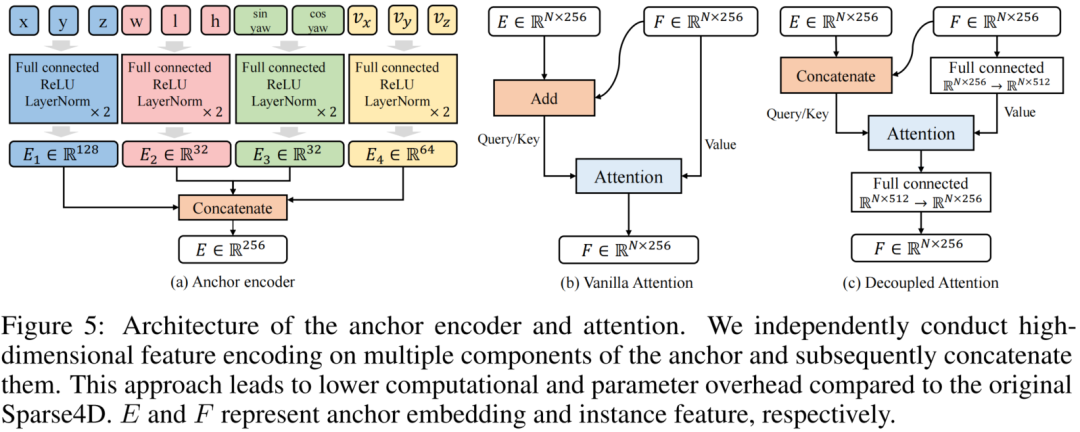
Sparse4D中有兩個instance attention模塊,1)instance self-attention和2)temporal instance cross-attention。在這兩個attention模塊中,將instance feature和anchor embed相加作為query與key,在計算attention weights時一定程度上會存在特征混淆的問題,如圖下所示。

為了解決這問題,我們對attention模塊進行了簡單的改進,將所有特征相加操作換成了拼接,提出了decoupled attention module,結構如下圖所示。
4. End to End 3D Multi-object Tracking
由于Sparse4D已經實現了目標檢測的端到端(無需dense-to-sparse的解碼),進一步的我們考慮將端到端往檢測的下游任務進行拓展,即多目標跟蹤。我們發現當Sparse4D經過充分檢測任務的訓練之后,instance在時序上已經具備了目標一致性了,即同一個instance始終檢測同一個目標。因此,我們無需對訓練流程進行任何修改,只需要在inference階段對instance進行ID assign即可,infer pipeline如下所示。

對比如MOTR(v1 & v3)、TrackFormer、MUTR3D等一系列端到端跟蹤算法,我們的實現方式具有以下兩點不同:
訓練階段,無需進行任何tracking的約束。這一做法一定程度上打破了對多目標跟蹤訓練的常規認知,我們進行以下簡單分析:
a. 對于3D檢測任務,我們加入了他車的運動補償,當上一幀檢測結果和速度估計準確時,投影到當前幀的temporal instance就可以準確的匹配到同一目標。因此,我們認為目標檢測任務的優化目標和目標跟蹤一致,當檢測任務訓練充分時,即使不需要加入tracking約束,也可以獲得不錯的跟蹤效果。加入tracking 約束的實驗我們也嘗試過,但會導致檢測和跟蹤指標均降低;
b. 相比于MOTR等2D跟蹤算法,3D跟蹤可以利用運動補償,一定程度上消除檢測和跟蹤任務在優化目標上的GAP,我認為這可能是Sparse4D能去掉tracking 約束的一大原因;
c. 另外,相比于MUTR3D等3D跟蹤算法,Sparse4D的檢測精度顯著高于MUTR3D,也只有當檢測精度足夠高時,才能擺脫對tracking 約束的依賴。
2. Temporal instance不需要卡高閾值,大部分temporal instance不表示一個歷史幀的檢測目標。MOTR等方法中,為了更貼近目標跟蹤任務,采用的track query會經過高閾值過濾,每個track query表示一個確切的檢測目標。而Sparse4D中的temporal instance設計出發點是為了實現時序特征融合,我們發現有限的temporal instance數量會降低時序模型的性能,因此我們保留了更多數量的temporal instance,即使大部分instance為負樣本。
5. 實驗驗證
Ablation Study
在NuScenes validation數據集上進行了消融實驗,可以看出Sparse4D-v3的幾個改進點(temporal instance denoising、decoupled attention和quality estimation)對感知性能均有提升。
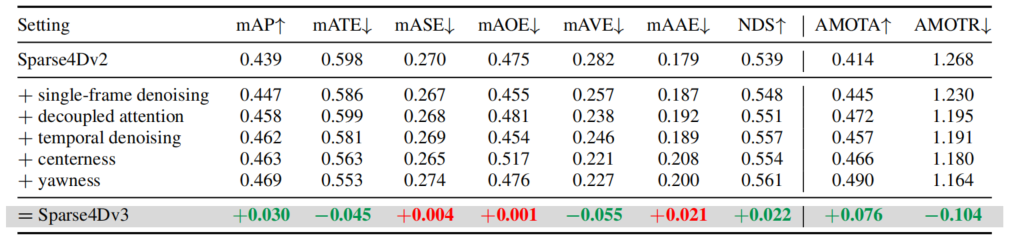
Ablation Experiments of Sparse4D-v3
Compare with SOTA
在NuScenes detection和tracking兩個benchmark上,Sparse4D均達到了SOTA水平。
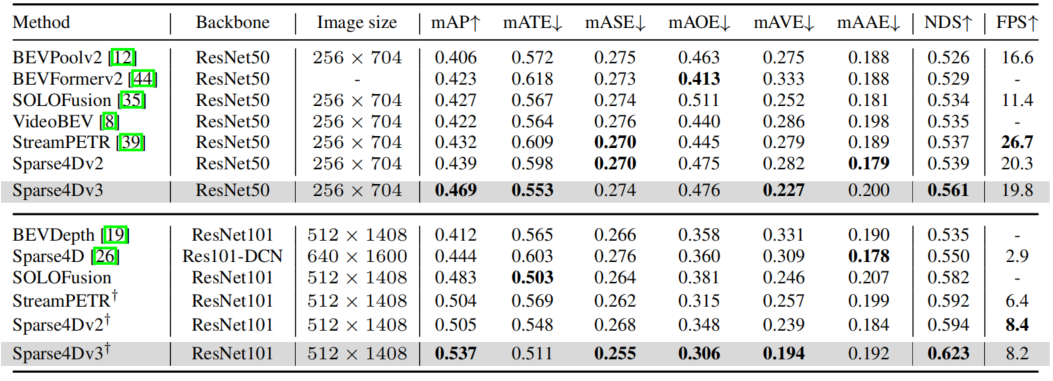
Results of Detection 3D on NuScenes Validation Set
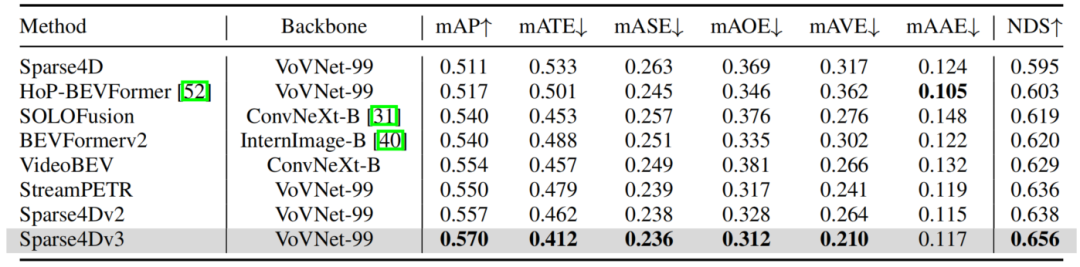
Results of Detection 3D on NuScenes Test Set
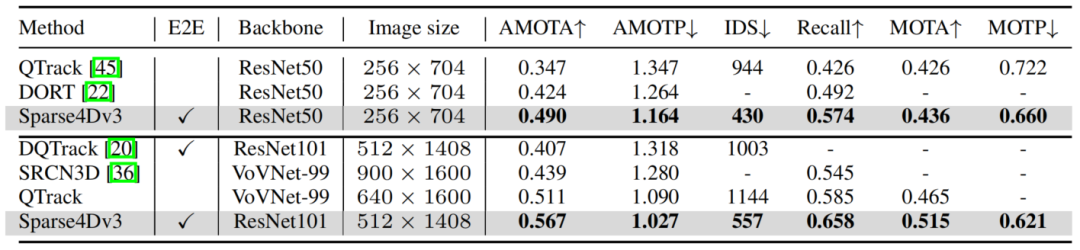
Results of Tracking 3D on NuScenes Validation Set

Results of Tracking 3D on NuScenes Test Set
Cloud-Based Performance Boost
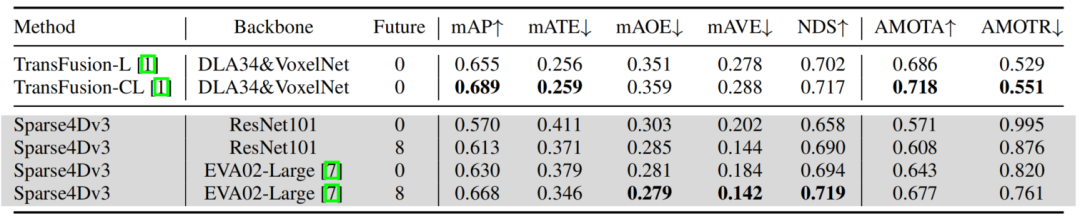
針對云端系統,為了進一步提升模型的性能,我們進行了Offline 模型和加大backbone的嘗試。
1. Offline 模型是通過加入未來幀特征,讓模型獲得更好效果,速度估計精度大幅提升,感知結果也更加平滑,對云端真值系統具有重要的意義。具體實現上,我們用Sparse4D-v1的多幀采樣的方式來融合未來幀特征,共加入了未來8幀的特征。這里的未來幀融合方式計算復雜度較高,如何搭建更加高效的Offline 模型,也是今后重要的研究方向之一;
2. 我們采用EVA02-large作為backbone,這一改進帶來的性能提升非常顯著。特別是對于稀有類別,EVA02的檢測精度有10+個點的提升。這主要得益于EVA02具有更大的參數量,經過更充分的預訓練,其參數量是ResNet101/VoVNet的3倍,并且在ImageNet-21k基于EVA-CLIP蒸餾+Mask Image Model的形式進行了充分的自監督訓練。大參數量+大數據+自監督訓練,讓模型收斂到更平坦的極值點,更加魯棒,具備更強的泛化性;
我們最終在NuScenes test數據集上獲得了NDS=71.9和AMOTA=67.7,在部分指標上甚至超過了LiDAR-based和multi-modality的模型。
展望與總結
在對長時序稀疏化3D 目標檢測的進一步探索過程中,我們主要有如下的收獲:
1. 卓越的感知性能:我們在稀疏感知框架下進行了一系列性能優化,在不增加推理計算量的前提下,讓Sparse4D在檢測和跟蹤任務上都取得了SOTA的水平;
2. 端到端多目標跟蹤:在無需對訓練階段進行任何修改的情況下,實現了從多視角視頻到目標軌跡的端到端感知,進一步減小對后處理的依賴,算法結構和推理流程非常簡潔。
我們希望Sparse4D-v3能夠成為融合感知算法研究中的新的baseline,更多的研發者已經加入進來。我們這里給出幾個值得進一步探索的方向:
1. Sparse4D-v3中對多目標跟蹤的探索還比較初步,跟蹤性能還有提升空間;
2. 如何在端到端跟蹤的基礎上,進一步擴展下游任務(如軌跡預測和端到端planning)是重要的研究方向;
3. 將Sparse4D拓展為多模態模型,具有非常大的應用價值;
4. Sparse4D還有待擴展為一個并行的多任務模型,比如加入online mapping、2D detection等。
.
審核編輯:湯梓紅
-
噪聲
+關注
關注
13文章
1118瀏覽量
47369 -
算法
+關注
關注
23文章
4599瀏覽量
92639 -
模型
+關注
關注
1文章
3171瀏覽量
48711 -
深度神經網絡
+關注
關注
0文章
61瀏覽量
4518
原文標題:Sparse4D-v3:稀疏感知的性能優化及端到端拓展
文章出處:【微信號:horizonrobotics,微信公眾號:地平線HorizonRobotics】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
移動協作機器人的RGB-D感知的端到端處理方案
稀疏鏡像在OpenHarmony上的應用
基于虛擬時鐘的MANET端到端性能分析模型
端到端的802.11n測試/802.11v網絡協議解析
SDN中的端到端時延
應用少、成本高,3D感知技術在手機端變得可有可無
基于深度神經網絡的端到端圖像壓縮方法

華為發布“5G+8K”3D VR端到端解決方案
一種端到端的立體深度感知系統的設計

5G供給端優化和需求端應用拓展
CCV 2023 | SparseBEV:高性能、全稀疏的純視覺3D目標檢測器

理想汽車自動駕駛端到端模型實現






 工商網監
工商網監
評論