 SVM的使用方法
SVM的使用方法
上一篇本著回歸傳統的觀點,在這個深度學習繁榮發展的時期,帶著大家認識了一位新朋友,英文名SVM,中文名為支持向量機,是一種基于傳統方案的機器學習方案,同樣的,支持根據輸入的數據進行訓練,以進行分類等任務。
那么怎么理解這個支持向量呢,簡單來說,這些支持向量就是我們從輸入數據中挑選的一些代表性數據。這些數據可以是一個或多個,當我們通過訓練獲取這些向量即得到了一個svm模型后,所有采集到的新數據,都要和這些代表數據進行對比以判斷歸屬。當然這里的支持向量根據分類的類別數,可以存在多組,以實現多分類。
為了更好的說明,SVM的工作原理,這里用一個python代碼給大家展示一下如何使用SVM進行一個單分類任務。之后還會給大家介紹一個小編和同事開發的實際應用SVM的異常檢測項目,讓大家實際看下SVM的應用效果。
那就先從python代碼開始,先開門瞧瞧SVM的世界,請看代碼:
(悄悄地說:請各位事先安裝numpy,matplotlib以及scikit-learn庫)
import numpy as np import matplotlib.pyplot as plt from sklearn import svm from sklearn.datasets import load_iris # Load the Iris dataset iris = load_iris() X = iris.data[:, :2] # Select only the first two features for visualization # Select a single class for one-class classification (Class 0) X_train = X[iris.target == 0] # Create and train the One-Class SVM model model = svm.OneClassSVM(kernel='rbf', nu=0.05, gamma = 1) model.fit(X_train) # Generate test data x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1 y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1 xx, yy = np.meshgrid(np.linspace(x_min, x_max, 500), np.linspace(y_min, y_max, 500)) Z = model.predict(np.c_[xx.ravel(), yy.ravel()]) Z = Z.reshape(xx.shape) # Plot the training data and decision boundary plt.scatter(X_train[:, 0], X_train[:, 1], color='blue', label='Inliers') plt.contourf(xx, yy, Z, levels=[-1, 0], colors='lightgray', alpha=0.5) plt.contour(xx, yy, Z, levels=[0], linewidths=2, colors='darkred') support_vector_indices = model.support_ support_vectors = X_train[support_vector_indices] # pait the support vector plt.scatter(support_vectors[:, 0], support_vectors[:, 1], color='red', label='Support Vectors') plt.xlabel('Sepal length') plt.ylabel('Sepal width') plt.title('One-Class SVM - Iris Dataset') plt.legend() plt.show()以上代碼,我們就使用svm. OneClassSVM構建了一個單分類SVM模型,并使用著名的鳶尾花數據集進行模型訓練;最終利用matplotlib庫進行結果繪制,結果通過model.predict獲取,并將最終訓練得到的支持向量用紅色點繪制出來,先來看看運行效果:
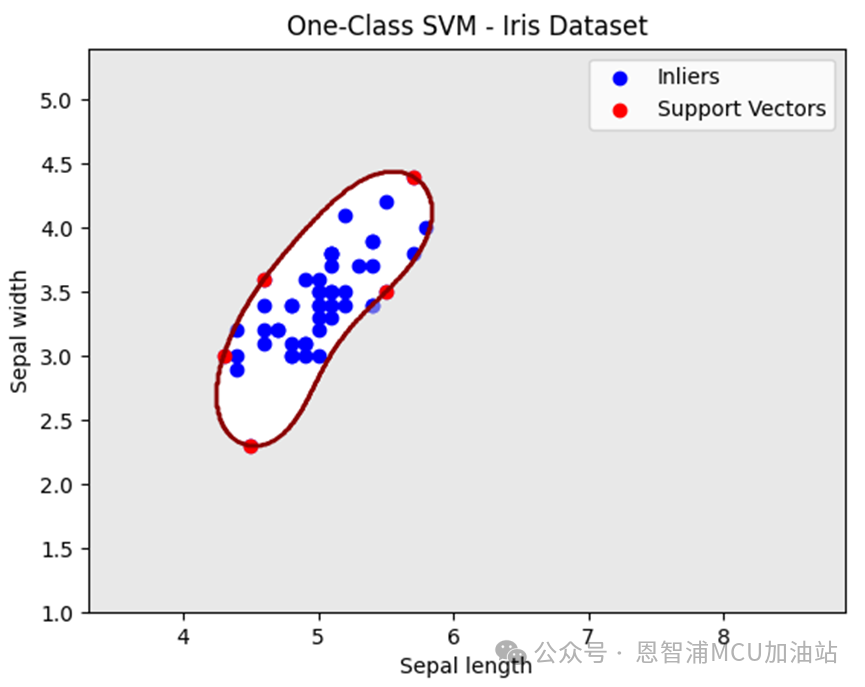
中間的暗紅色區域就是模型所訓練出來的決策區域,可以簡單認為落在紅色區域里面的點就是屬于我們這一類的。這里我們在訓練SVM模型時候,選擇了兩個特征,分別是花萼的長度以及寬度,當然也可以多選擇幾組特征(只不過不好圖形化顯示了)。
相信大家也注意到了,svm.OneClassSVM函數中有兩個參數,nu和gamma,這兩個可是模型好壞的關鍵:
nu 控制訓練誤差和支持向量數之間的權衡。它表示訓練誤差的上限和支持向量數的下限。較小的nu 值允許更多的支持向量和更靈活的決策邊界,而較大的 nu 值限制支持向量數并導致更保守的決策邊界。
gamma 定義每個訓練樣本的影響力。它確定訓練樣本的影響范圍,并影響決策邊界的平滑程度。較小的 gamma 值使決策邊界更平滑,并導致每個訓練樣本的影響范圍更大。相反,較大的值使決策邊界更復雜,并導致每個訓練樣本的影響范圍更小。
接下來我們就實際測試下,調整gamma值從1到100:
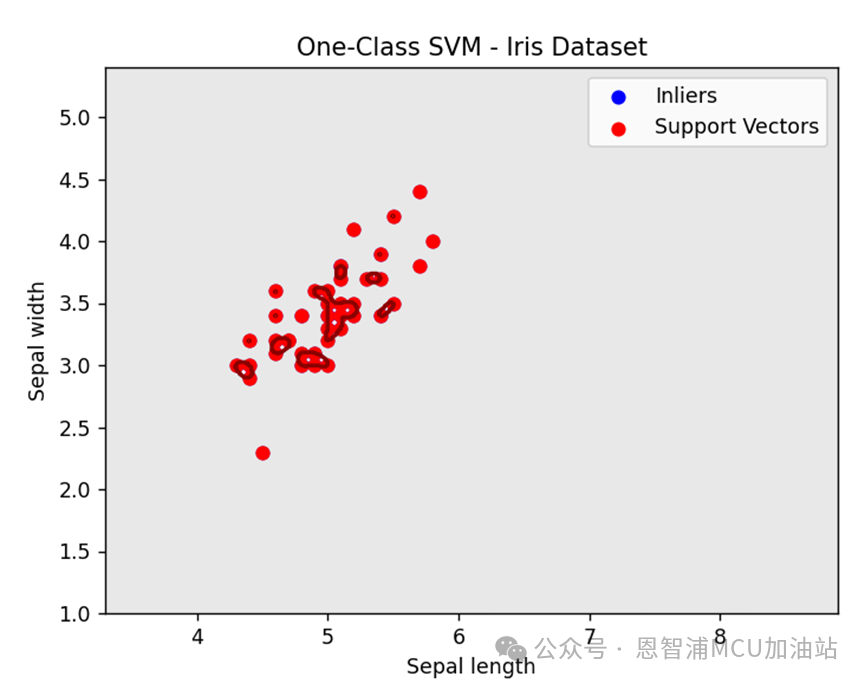
正如上面所述,gamma值變大使得決策區域變得復雜,并且似乎每一個訓練數據都變成了支持向量。
接下來我們看看調整nu的情況,nu從0.05->0.5:
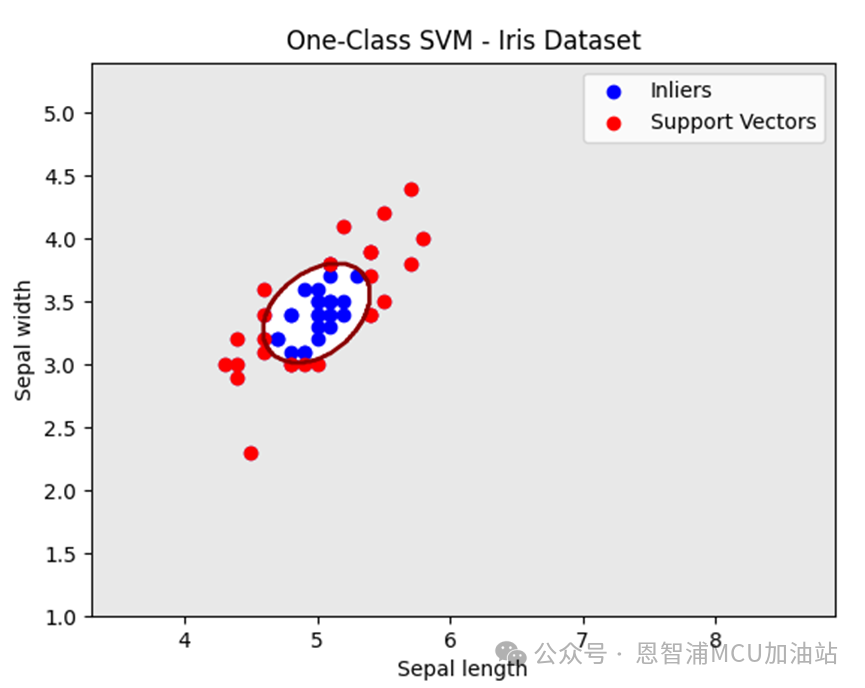
決策邊界正如上文所講,變得更加保守了。不過,在實際使用中,我們需要聯合調整nu和gamma參數,以獲取最佳的模型擬合效果,當然這就是經驗之談了。所謂:煉丹的過程,沒錯,即便我們回歸傳統,煉丹的過程也依舊還是存在的。
好了,那本期小編就給大家先分享到這里,下期將為大家帶來一個實打實的,將單分類svm用作異常檢測的實際項目,敬請期待!!
審核編輯:湯梓紅
-
SVM
+關注
關注
0文章
154瀏覽量
32337 -
模型
+關注
關注
1文章
3029瀏覽量
48345 -
機器學習
+關注
關注
66文章
8306瀏覽量
131834 -
深度學習
+關注
關注
73文章
5422瀏覽量
120583
原文標題:讓機器學習回歸傳統之SVM使用方法
文章出處:【微信號:NXP_SMART_HARDWARE,微信公眾號:恩智浦MCU加油站】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
逆變器的調制方法進階篇—空間矢量調制SVM

一種基于凸殼算法的SVM集成方法

采用SVM的網頁分類方法研究
淺析SVM多核學習方法






 工商網監
工商網監
評論