 AI計算,為什么要用GPU?
AI計算,為什么要用GPU?
今天這篇文章,我們繼續來聊聊芯片。
在之前的文章里,小棗君說過,行業里通常會把半導體芯片分為數字芯片和模擬芯片。其中,數字芯片的市場規模占比較大,達到70%左右。
數字芯片,還可以進一步細分,分為:邏輯芯片、存儲芯片以及微控制單元(MCU)。
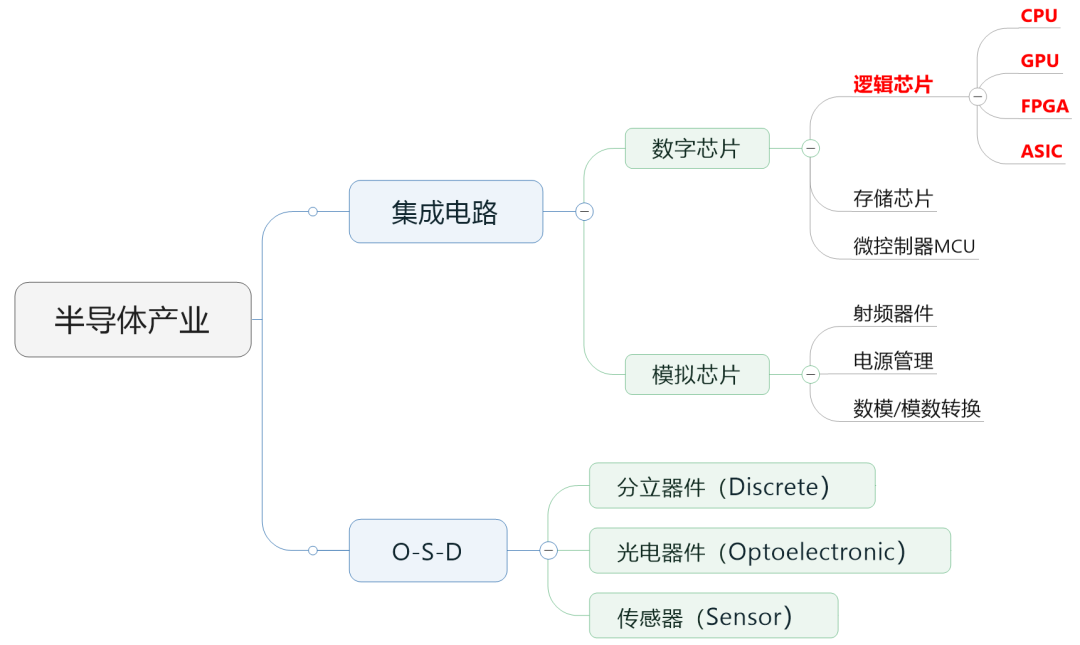
存儲芯片和MCU以后再介紹,今天小棗君重點講講邏輯芯片。
邏輯芯片,其實說白了就是計算芯片。它包含了各種邏輯門電路,可以實現運算與邏輯判斷功能,是最常見的芯片之一。
大家經常聽說的CPU、GPU、FPGA、ASIC,全部都屬于邏輯芯片。而現在特別火爆的AI,用到的所謂“AI芯片”,也主要是指它們。
CPU(中央處理器)
先說說大家最熟悉的CPU,英文全稱Central Processing Unit,中央處理器。
但凡是個人都知道,CPU是計算機的心臟。
現代計算機,都是基于1940年代誕生的馮·諾依曼架構。在這個架構中,包括了運算器(也叫邏輯運算單元,ALU)、控制器(CU)、存儲器、輸入設備、輸出設備等組成部分。
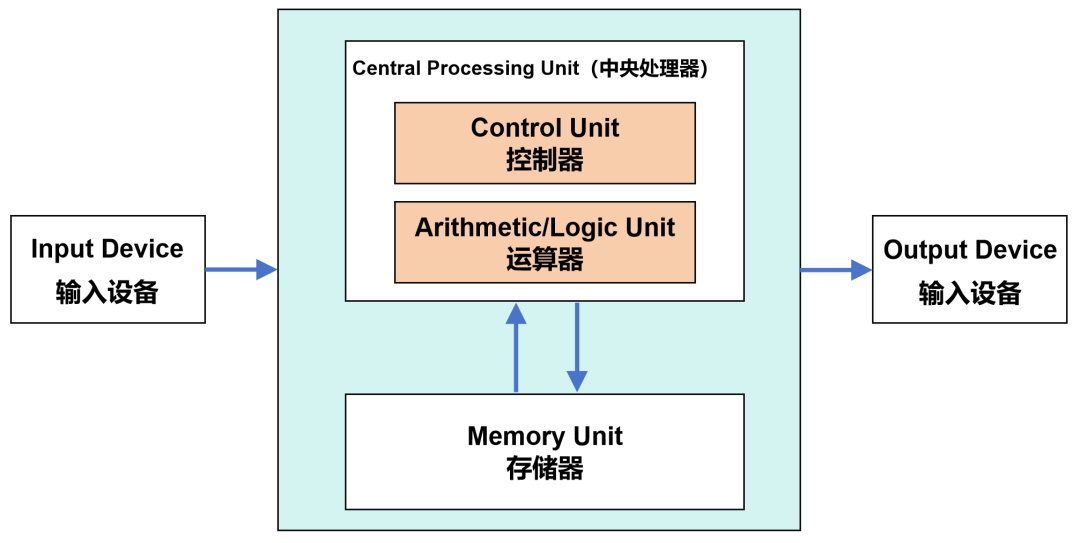
馮·諾依曼架構
數據來了,會先放到存儲器。然后,控制器會從存儲器拿到相應數據,再交給運算器進行運算。運算完成后,再把結果返回到存儲器。
這個流程,還有一個更有逼格的叫法:“Fetch(取指)-Decode(譯碼)- Execute(執行)-Memory Access(訪存)-Write Back(寫回)”。
大家看到了,運算器和控制器這兩個核心功能,都是由CPU負責承擔的。
具體來說,運算器(包括加法器、減法器、乘法器、除法器),負責執行算術和邏輯運算,是真正干活的。控制器,負責從內存中讀取指令、解碼指令、執行指令,是指手畫腳的。
除了運算器和控制器之外,CPU還包括時鐘模塊和寄存器(高速緩存)等組件。
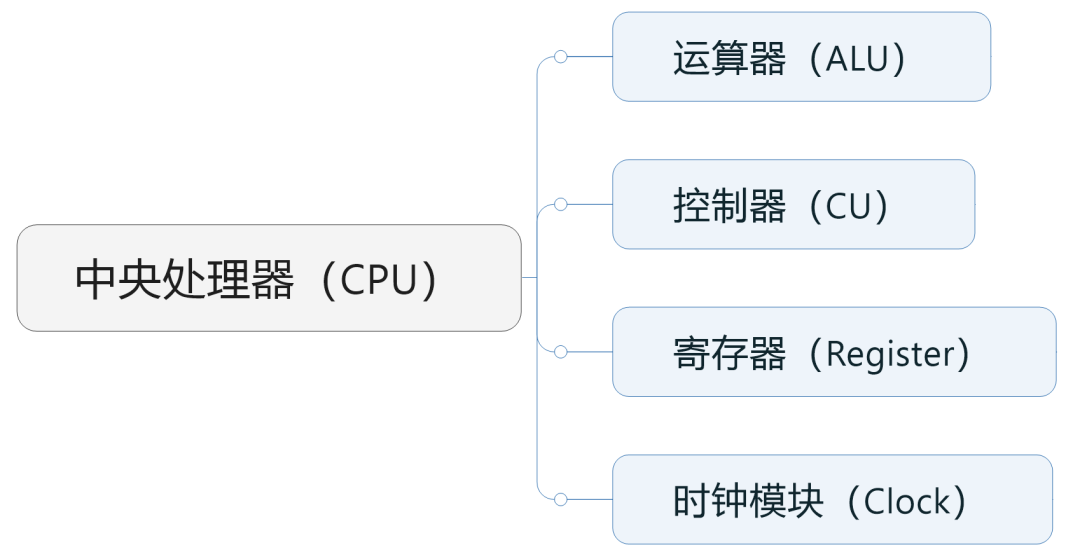
時鐘模塊負責管理CPU的時間,為CPU提供穩定的時基。它通過周期性地發出信號,驅動CPU中的所有操作,調度各個模塊的工作。
寄存器是CPU中的高速存儲器,用于暫時保存指令和數據。它的CPU與內存(RAM)之間的“緩沖”,速度比一般的內存更快,避免內存“拖累”CPU的工作。
寄存器的容量和存取性能,可以影響CPU到對內存的訪問次數,進而影響整個系統的效率。后面我們講存儲芯片的時候,還會提到它。
CPU一般會基于指令集架構進行分類,包括x86架構和非x86架構。x86基本上都是復雜指令集(CISC),而非x86基本為精簡指令集(RISC)。
PC和大部分服務器用的是x86架構,英特爾和AMD公司占據主導地位。非x86架構的類型比較多,這些年崛起速度很快,主要有ARM、MIPS、Power、RISC-V、Alpha等。以后會專門介紹。
GPU(圖形處理器)
再來看看GPU。
GPU是顯卡的核心部件,英文全名叫Graphics Processing Unit,圖形處理單元(圖形處理器)。
GPU并不能和顯卡劃等號。顯卡除了GPU之外,還包括顯存、VRM穩壓模塊、MRAM芯片、總線、風扇、外圍設備接口等。

顯卡
1999年,英偉達(NVIDIA)公司率先提出了GPU的概念。
之所以要提出GPU,是因為90年代游戲和多媒體業務高速發展。這些業務給計算機的3D圖形處理和渲染能力提出了更高的要求。傳統CPU搞不定,所以引入了GPU,分擔這方面的工作。
根據形態,GPU可分為獨立GPU(dGPU,discrete/dedicated GPU)和集成GPU(iGPU,integrated GPU),也就是常說的獨顯、集顯。
GPU也是計算芯片。所以,它和CPU一樣,包括了運算器、控制器和寄存器等組件。
但是,因為GPU主要負責圖形處理任務,所以,它的內部架構和CPU存在很大的不同。
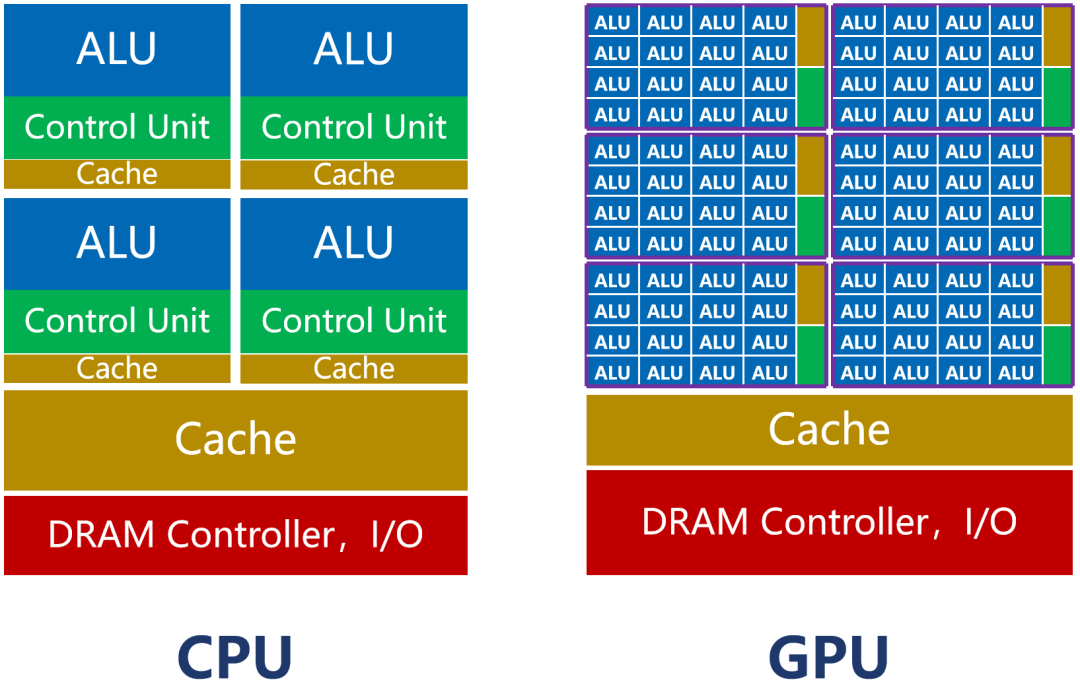
如上圖所示,CPU的內核(包括了ALU)數量比較少,最多只有幾十個。但是,CPU有大量的緩存(Cache)和復雜的控制器(CU)。
這樣設計的原因,是因為CPU是一個通用處理器。作為計算機的主核心,它的任務非常復雜,既要應對不同類型的數據計算,還要響應人機交互。
復雜的條件和分支,還有任務之間的同步協調,會帶來大量的分支跳轉和中斷處理工作。它需要更大的緩存,保存各種任務狀態,以降低任務切換時的時延。它也需要更復雜的控制器,進行邏輯控制和調度。
CPU的強項是管理和調度。真正干活的功能,反而不強(ALU占比大約5%~20%)。
如果我們把處理器看成是一個餐廳的話,CPU就像一個擁有幾十名高級廚師的全能型餐廳。這個餐廳什么菜系都能做,但是,因為菜系多,所以需要花費大量的時間協調、配菜,上菜的速度相對比較慢。
而GPU則完全不同。
GPU為圖形處理而生,任務非常明確且單一。它要做的,就是圖形渲染。圖形是由海量像素點組成的,屬于類型高度統一、相互無依賴的大規模數據。
所以,GPU的任務,是在最短的時間里,完成大量同質化數據的并行運算。所謂調度和協調的“雜活”,反而很少。
并行計算,當然需要更多的核啊。
如前圖所示,GPU的內核數,遠遠超過CPU,可以達到幾千個甚至上萬個(也因此被稱為“眾核”)。

RTX4090有16384個流處理器
GPU的核,稱為流式多處理器(Stream Multi-processor,SM),是一個獨立的任務處理單元。
在整個GPU中,會劃分為多個流式處理區。每個處理區,包含數百個內核。每個內核,相當于一顆簡化版的CPU,具備整數運算和浮點運算的功能,以及排隊和結果收集功能。
GPU的控制器功能簡單,緩存也比較少。它的ALU占比,可以達到80%以上。
雖然GPU單核的處理能力弱于CPU,但是數量龐大,非常適合高強度并行計算。同等晶體管規模條件下,它的算力,反而比CPU更強。
還是以餐廳為例。GPU就像一個擁有成千上萬名初級廚師的單一型餐廳。它只適合做某種指定菜系。但是,因為廚師多,配菜簡單,所以大家一起炒,上菜速度反而快。
GPU與AI計算
大家都知道,現在的AI計算,都在搶購GPU。英偉達也因此賺得盆滿缽滿。為什么會這樣呢?
原因很簡單,因為AI計算和圖形計算一樣,也包含了大量的高強度并行計算任務。
深度學習是目前最主流的人工智能算法。從過程來看,包括訓練(training)和推理(inference)兩個環節。
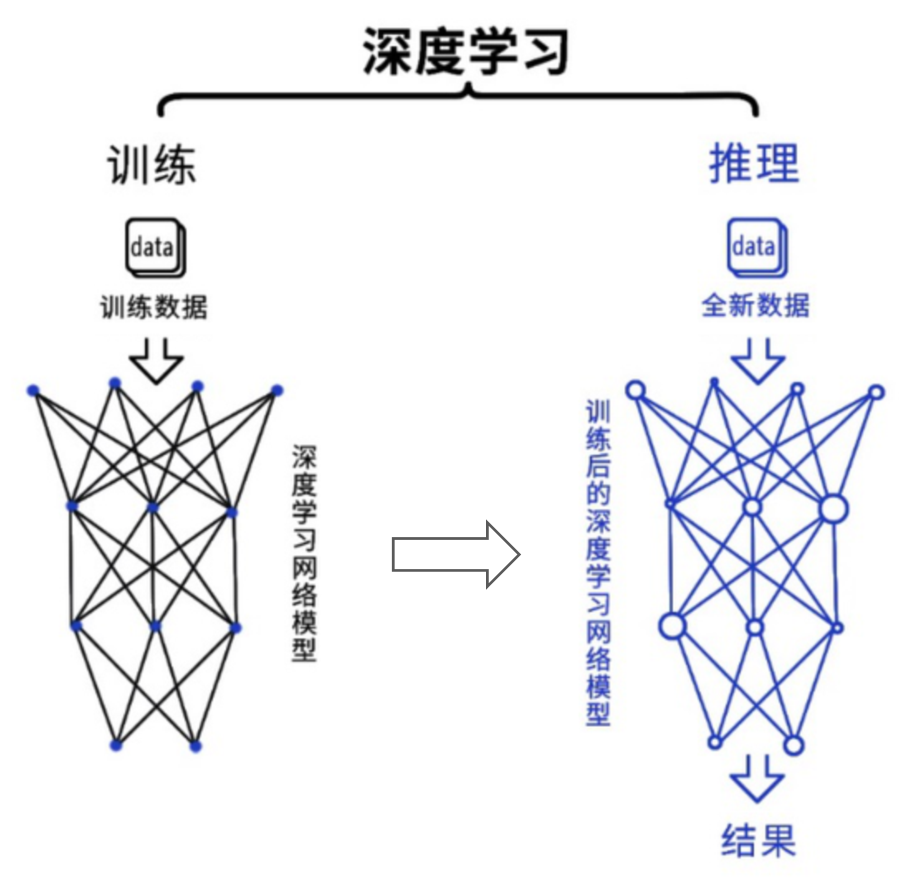
在訓練環節,通過投喂大量的數據,訓練出一個復雜的神經網絡模型。在推理環節,利用訓練好的模型,使用大量數據推理出各種結論。
訓練環節由于涉及海量的訓練數據,以及復雜的深度神經網絡結構,所以需要的計算規模非常龐大,對芯片的算力性能要求比較高。而推理環節,對簡單指定的重復計算和低延遲的要求很高。
它們所采用的具體算法,包括矩陣相乘、卷積、循環層、梯度運算等,分解為大量并行任務,可以有效縮短任務完成的時間。
GPU憑借自身強悍的并行計算能力以及內存帶寬,可以很好地應對訓練和推理任務,已經成為業界在深度學習領域的首選解決方案。
目前,大部分企業的AI訓練,采用的是英偉達的GPU集群。如果進行合理優化,一塊GPU卡,可以提供相當于數十其至上百臺CPU服務器的算力。
不過,在推理環節,GPU的市場份額占比并沒有那么高。具體原因我們后面會講。
將GPU應用于圖形之外的計算,最早源于2003年。
那一年,GPGPU(General Purpose computing on GPU,基于GPU的通用計算)的概念首次被提出。意指利用GPU的計算能力,在非圖形處理領域進行更通用、更廣泛的科學計算。
GPGPU在傳統GPU的基礎上,進行了進一步的優化設計,使之更適合高性能并行計算。
2009年,斯坦福的幾位學者,首次展示了利用GPU訓練深度神經網絡的成果,引起了轟動。
幾年后,2012年,神經網絡之父杰弗里·辛頓(Geoffrey Hinton)的兩個學生——亞歷克斯·克里切夫斯基(Alex Krizhevsky)、伊利亞·蘇茨克沃(Ilya Sutskever),利用“深度學習+GPU”的方案,提出了深度神經網絡AlexNet,將識別成功率從74%提升到85%,一舉贏得Image Net挑戰賽的冠軍。
這徹底引爆了“AI+GPU”的浪潮。英偉達公司迅速跟進,砸了大量的資源,在三年時間里,將GPU性能提升了65倍。
除了硬剛算力之外,他們還積極構建圍繞GPU的開發生態。他們建立了基于自家GPU的CUDA(Compute Unified Device Architecture)生態系統,提供完善的開發環境和方案,幫助開發人員更容易地使用GPU進行深度學習開發或高性能運算。
這些早期的精心布局,最終幫助英偉達在AIGC爆發時收獲了巨大的紅利。目前,他們市值高達1.22萬億美元(英特爾的近6倍),是名副其實的“AI無冕之王”。
-
gpu
+關注
關注
28文章
4703瀏覽量
128729 -
AI
+關注
關注
87文章
30239瀏覽量
268480 -
數字芯片
+關注
關注
1文章
108瀏覽量
18375
發布評論請先 登錄
相關推薦
AI計算,為什么要用GPU?
省成本還是省時間,AI計算上的GPU與ASIC之選

ASIC和GPU,誰才是AI計算的最優解?

NVIDIA火熱招聘GPU高性能計算架構師
【產品活動】阿里云GPU云服務器年付5折!阿里云異構計算助推行業發展!
深度學習推理和計算-通用AI核心
ai芯片和gpu的區別
GPU八大主流的應用場景
浪潮AIStation突破企業AI計算資源極限,高效共享GPU
未來的AI計算領域,將是CPU、GPU、IPU并行






 工商網監
工商網監
評論