") 小紅書搜索團(tuán)隊(duì)研究新框架:負(fù)樣本在大模型蒸餾中的重要性
小紅書搜索團(tuán)隊(duì)研究新框架:負(fù)樣本在大模型蒸餾中的重要性
大語言模型(LLMs)在各種推理任務(wù)上表現(xiàn)優(yōu)異,但其黑盒屬性和龐大參數(shù)量阻礙了它在實(shí)踐中的廣泛應(yīng)用。特別是在處理復(fù)雜的數(shù)學(xué)問題時(shí),LLMs 有時(shí)會(huì)產(chǎn)生錯(cuò)誤的推理鏈。傳統(tǒng)研究方法僅從正樣本中遷移知識(shí),而忽略了那些帶有錯(cuò)誤答案的合成數(shù)據(jù)。
在 AAAI 2024 上,小紅書搜索算法團(tuán)隊(duì)提出了一個(gè)創(chuàng)新框架,在蒸餾大模型推理能力的過程中充分利用負(fù)樣本知識(shí)。負(fù)樣本,即那些在推理過程中未能得出正確答案的數(shù)據(jù),雖常被視為無用,實(shí)則蘊(yùn)含著寶貴的信息。
論文提出并驗(yàn)證了負(fù)樣本在大模型蒸餾過程中的價(jià)值,構(gòu)建一個(gè)模型專業(yè)化框架:除了使用正樣本外,還充分利用負(fù)樣本來提煉 LLM 的知識(shí)。該框架包括三個(gè)序列化步驟,包括負(fù)向協(xié)助訓(xùn)練(NAT)、負(fù)向校準(zhǔn)增強(qiáng)(NCE)和動(dòng)態(tài)自洽性(ASC),涵蓋從訓(xùn)練到推理的全階段過程。通過一系列廣泛的實(shí)驗(yàn),我們展示了負(fù)向數(shù)據(jù)在 LLM 知識(shí)蒸餾中的關(guān)鍵作用。
如今,在思維鏈(CoT)提示的幫助下,大語言模型(LLMs)展現(xiàn)出強(qiáng)大的推理能力。然而,思維鏈已被證明是千億級(jí)參數(shù)模型才具有的涌現(xiàn)能力。這些模型的繁重計(jì)算需求和高推理成本,阻礙了它們在資源受限場景中的應(yīng)用。因此,我們研究的目標(biāo)是使小模型能夠進(jìn)行復(fù)雜的算術(shù)推理,以便在實(shí)際應(yīng)用中進(jìn)行大規(guī)模部署。
知識(shí)蒸餾提供了一種有效的方法,可以將 LLMs 的特定能力遷移到更小的模型中。這個(gè)過程也被稱為模型專業(yè)化(model specialization),它強(qiáng)制小模型專注于某些能力。先前的研究利用 LLMs 的上下文學(xué)習(xí)(ICL)來生成數(shù)學(xué)問題的推理路徑,將其作為訓(xùn)練數(shù)據(jù),有助于小模型獲得復(fù)雜推理能力。然而,這些研究只使用了生成的具有正確答案的推理路徑(即正樣本)作為訓(xùn)練樣本,忽略了在錯(cuò)誤答案(即負(fù)樣本)的推理步驟中有價(jià)值的知識(shí)。
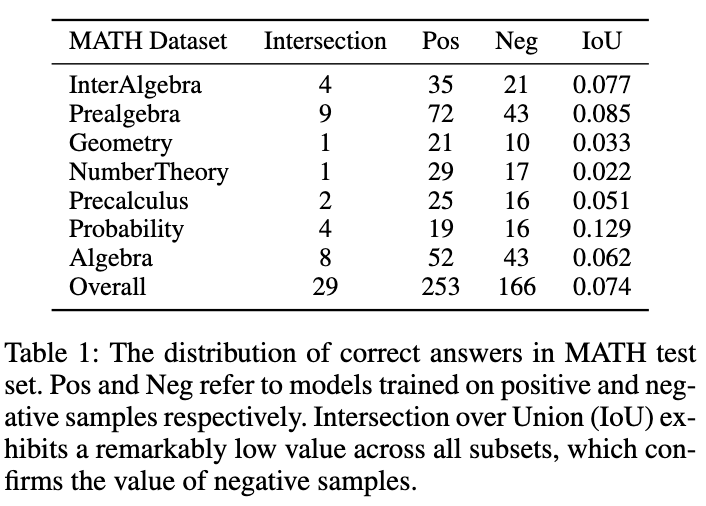
如圖所示,表 1 展示了一個(gè)有趣的現(xiàn)象:分別在正、負(fù)樣本數(shù)據(jù)上訓(xùn)練的模型,在 MATH 測試集上的準(zhǔn)確答案重疊非常小。盡管負(fù)樣本訓(xùn)練的模型準(zhǔn)確性較低,但它能夠解決一些正樣本模型無法正確回答的問題,這證實(shí)了負(fù)樣本中包含著寶貴的知識(shí)。此外,負(fù)樣本中的錯(cuò)誤鏈路能夠幫助模型避免犯類似錯(cuò)誤。另一個(gè)我們應(yīng)該利用負(fù)樣本的原因是 OpenAI 基于 token 的定價(jià)策略。即使是 GPT-4,在 MATH 數(shù)據(jù)集上的準(zhǔn)確性也低于 50%,這意味著如果僅利用正樣本知識(shí),大量的 token 會(huì)被浪費(fèi)。因此,我們提出:相比于直接丟棄負(fù)樣本,更好的方式是從中提取和利用有價(jià)值的知識(shí),以增強(qiáng)小模型的專業(yè)化。
模型專業(yè)化過程一般可以概括為三個(gè)步驟:
1)思維鏈蒸餾(Chain-of-Thought Distillation),使用 LLMs 生成的推理鏈訓(xùn)練小模型。
2)自我增強(qiáng)(Self-Enhancement),進(jìn)行自蒸餾或數(shù)據(jù)自擴(kuò)充,以進(jìn)一步優(yōu)化模型。
3)自洽性(Self-Consistency)被廣泛用作一種有效的解碼策略,以提高推理任務(wù)中的模型性能。
在這項(xiàng)工作中,我們提出了一種新的模型專業(yè)化框架,該框架可以全方位利用負(fù)樣本,促進(jìn)從 LLMs 提取復(fù)雜推理能力。
我們首先設(shè)計(jì)了負(fù)向協(xié)助訓(xùn)練(NAT)方法,其中 dual-LoRA 結(jié)構(gòu)被設(shè)計(jì)用于從正向、負(fù)向兩方面獲取知識(shí)。作為一個(gè)輔助模塊,負(fù)向 LoRA 的知識(shí)可以通過校正注意力機(jī)制,動(dòng)態(tài)地整合到正向 LoRA 的訓(xùn)練過程中。
對(duì)于自我增強(qiáng),我們設(shè)計(jì)了負(fù)向校準(zhǔn)增強(qiáng)(NCE),它將負(fù)向輸出作為基線,以加強(qiáng)關(guān)鍵正向推理鏈路的蒸餾。
除了訓(xùn)練階段,我們還在推理過程中利用負(fù)向信息。傳統(tǒng)的自洽性方法將相等或基于概率的權(quán)重分配給所有候選輸出,導(dǎo)致投票出一些不可靠的答案。為了緩解該問題,提出了動(dòng)態(tài)自洽性(ASC)方法,在投票前進(jìn)行排序,其中排序模型在正負(fù)樣本上進(jìn)行訓(xùn)練的。
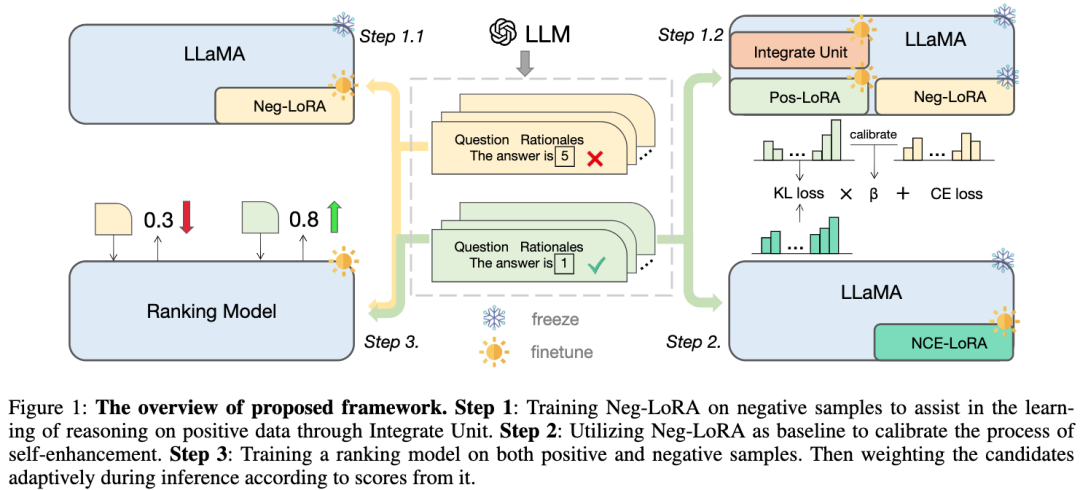
我們提出的框架以 LLaMA 為基礎(chǔ)模型,主要包含三個(gè)部分,如圖所示:
步驟 1 :對(duì)負(fù)向 LoRA 進(jìn)行訓(xùn)練,通過合并單元幫助學(xué)習(xí)正樣本的推理知識(shí);
步驟 2 :利用負(fù)向 LoRA 作為基線來校準(zhǔn)自我增強(qiáng)的過程;
步驟 3 :在正樣本和負(fù)樣本上訓(xùn)練排名模型,在推理過程中根據(jù)其得分,自適應(yīng)地對(duì)候選推理鏈路進(jìn)行加權(quán)。
2.1負(fù)向協(xié)助訓(xùn)練(NAT)
我們提出了一個(gè)兩階段的負(fù)向協(xié)助訓(xùn)練(NAT)范式,分為負(fù)向知識(shí)吸收與動(dòng)態(tài)集成單元兩部分:
2.1.1負(fù)向知識(shí)吸收
通過在負(fù)數(shù)據(jù)上最大化以下期望,負(fù)樣本的知識(shí)被 LoRA 吸收。在這個(gè)過程中,LLaMA 的參數(shù)保持凍結(jié)。
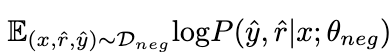
2.1.2 動(dòng)態(tài)集成單元
由于無法預(yù)先確定擅長哪些數(shù)學(xué)問題,我們設(shè)計(jì)了如下圖所示的動(dòng)態(tài)集成單元,以便在學(xué)習(xí)正樣本知識(shí)的過程中,動(dòng)態(tài)集成來自的知識(shí):
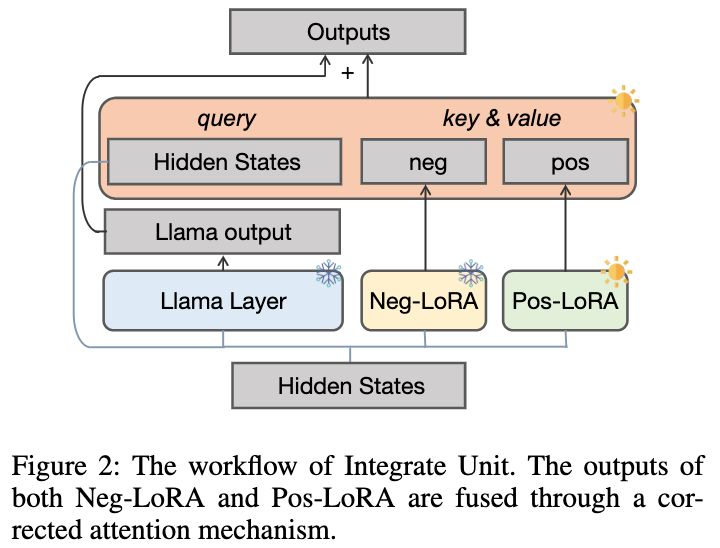
我們凍結(jié)以防止內(nèi)部知識(shí)被遺忘,并額外引入正 LoRA 模塊。理想情況下,我們應(yīng)該正向集成正負(fù) LoRA 模塊(在每個(gè) LLaMA 層中輸出表示為與),以補(bǔ)充正樣本中所缺乏但對(duì)應(yīng)所具有的有益知識(shí)。當(dāng) 包含有害知識(shí)時(shí),我們應(yīng)該對(duì)正負(fù) LoRA 模塊進(jìn)行負(fù)向集成,以幫助減少正樣本中可能的不良行為。
我們提出了一種糾正注意力機(jī)制來實(shí)現(xiàn)這一目標(biāo),如下所示:
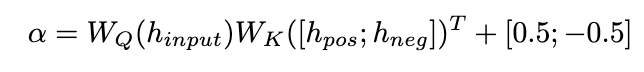
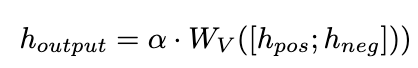
我們使用作為查詢來計(jì)算和的注意力權(quán)重。通過在添加校正項(xiàng) [0.5;-0.5],的注意力權(quán)重被限制在 [-0.5,0.5] 的范圍內(nèi),從而實(shí)現(xiàn)了在正、負(fù)兩個(gè)方向上自適應(yīng)地集成來自的知識(shí)的效果。最終,和 LLaMA 層輸出的總和形成了動(dòng)態(tài)集成單元的輸出。
2.2負(fù)向校準(zhǔn)增強(qiáng)(NCE)
為了進(jìn)一步增強(qiáng)模型的推理能力,我們提出了負(fù)校準(zhǔn)增強(qiáng)(NCE),它使用負(fù)知識(shí)來幫助自我增強(qiáng)過程。我們首先使用 NAT 為中的每個(gè)問題生成對(duì)作為擴(kuò)充樣本,并將它們補(bǔ)充到訓(xùn)練數(shù)據(jù)集中。對(duì)于自蒸餾部分,我們注意到一些樣本可能包含更關(guān)鍵的推理步驟,對(duì)提升模型的推理能力至關(guān)重要。我們的主要目標(biāo)是確定這些關(guān)鍵的推理步驟,并在自蒸餾過程中加強(qiáng)對(duì)它們的學(xué)習(xí)。
考慮到 NAT 已經(jīng)包含了的有用知識(shí),使得 NAT 比推理能力更強(qiáng)的因素,隱含在兩者之間不一致的推理鏈路中。因此,我們使用 KL 散度來測量這種不一致性,并最大化該公式的期望:
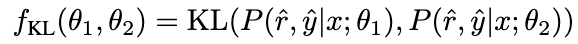
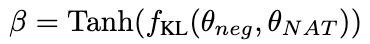
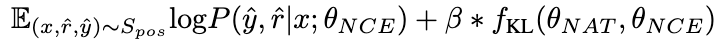
β 值越大,表示兩者之間的差異越大,意味著該樣本包含更多關(guān)鍵知識(shí)。通過引入 β 來調(diào)整不同樣本的損失權(quán)重,NCE 將能夠選擇性地學(xué)習(xí)并增強(qiáng) NAT 中嵌入的知識(shí)。
2.3動(dòng)態(tài)自洽性(ASC)
自洽性(SC)對(duì)于進(jìn)一步提高模型在復(fù)雜推理中的表現(xiàn)是有效的。然而,當(dāng)前的方法要么為每個(gè)候選者分配相等的權(quán)重,要么簡單地基于生成概率分配權(quán)重。這些策略無法在投票階段根據(jù) (r?, y?) 的質(zhì)量調(diào)整候選權(quán)重,這可能會(huì)使正確候選項(xiàng)不易被選出。為此,我們提出了動(dòng)態(tài)自洽性方法(ASC),它利用正負(fù)數(shù)據(jù)來訓(xùn)練排序模型,可以自適應(yīng)地重新配權(quán)候選推理鏈路。
2.3.1排序模型訓(xùn)練
理想情況下,我們希望排序模型為得出正確答案的推理鏈路分配更高的權(quán)重,反之亦然。因此,我們用以下方式構(gòu)造訓(xùn)練樣本:
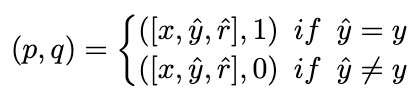
并使用 MSE loss 去訓(xùn)練排序模型:
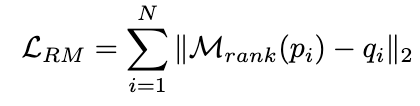
2.3.2加權(quán)策略
我們將投票策略修改為以下公式,以實(shí)現(xiàn)自適應(yīng)地重新加權(quán)候選推理鏈路的目標(biāo):
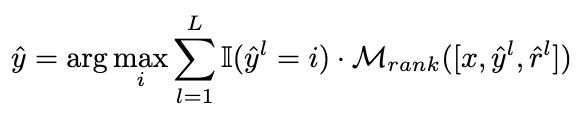
下圖展示了 ASC 策略的流程:

從知識(shí)遷移的角度來看,ASC 實(shí)現(xiàn)了對(duì)來自 LLMs 的知識(shí)(正向和負(fù)向)的進(jìn)一步利用,以幫助小模型獲得更好的性能。
本研究專注于具有挑戰(zhàn)性的數(shù)學(xué)推理數(shù)據(jù)集 MATH,該數(shù)據(jù)集共有 12500 個(gè)問題,涉及七個(gè)不同的科目。此外,我們還引入了以下四個(gè)數(shù)據(jù)集來評(píng)估所提出的框架對(duì)分布外(OOD)數(shù)據(jù)的泛化能力:GSM8K、ASDiv、MultiArith和SVAMP。
對(duì)于教師模型,我們使用 Open AI 的 gpt-3.5-turbo 和 gpt-4 API來生成推理鏈。對(duì)于學(xué)生模型,我們選擇 LLaMA-7b。
在我們的研究中有兩種主要類型的基線:一種為大語言模型(LLMs),另一種則基于 LLaMA-7b。對(duì)于 LLMs,我們將其與兩種流行的模型進(jìn)行比較:GPT3 和 PaLM。對(duì)于 LLaMA-7b,我們首先提供我們的方法與三種設(shè)置進(jìn)行比較:Few-shot、Fine-tune(在原始訓(xùn)練樣本上)、CoT KD(思維鏈蒸餾)。在從負(fù)向角度學(xué)習(xí)方面,還將包括四種基線方法:MIX(直接用正向和負(fù)向數(shù)據(jù)的混合物訓(xùn)練 LLaMA)、CL(對(duì)比學(xué)習(xí))、NT(負(fù)訓(xùn)練)和 UL(非似然損失)。
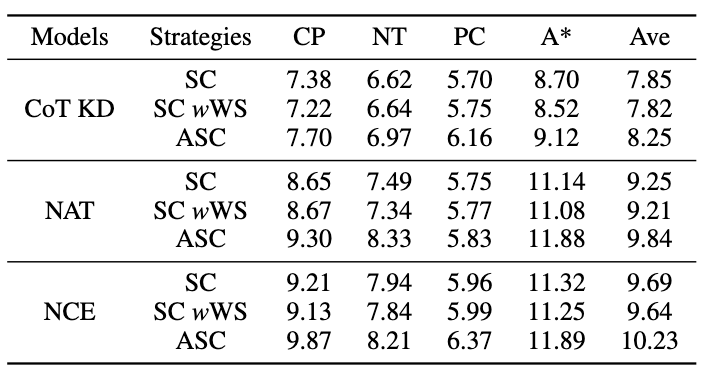
3.1 NAT 實(shí)驗(yàn)結(jié)果
所有的方法都使用了貪婪搜索(即溫度 = 0),NAT 的實(shí)驗(yàn)結(jié)果如圖所示,表明所提出的 NAT 方法在所有基線上都提高了任務(wù)準(zhǔn)確性。
從 GPT3 和 PaLM 的低值可以看出,MATH 是一個(gè)非常困難的數(shù)學(xué)數(shù)據(jù)集,但 NAT 仍然能夠在參數(shù)極少的情況下表現(xiàn)突出。與在原始數(shù)據(jù)上進(jìn)行微調(diào)相比,NAT 在兩種不同的 CoT 來源下實(shí)現(xiàn)了約 75.75% 的提升。與 CoT KD 在正樣本上的比較,NAT 也顯著提高了準(zhǔn)確性,展示了負(fù)樣本的價(jià)值。
對(duì)于利用負(fù)向信息基線,MIX 的低性能表明直接訓(xùn)練負(fù)樣本會(huì)使模型效果很差。其他方法也大多不如 NAT,這表明在復(fù)雜推理任務(wù)中僅在負(fù)方向上使用負(fù)樣本是不夠的。
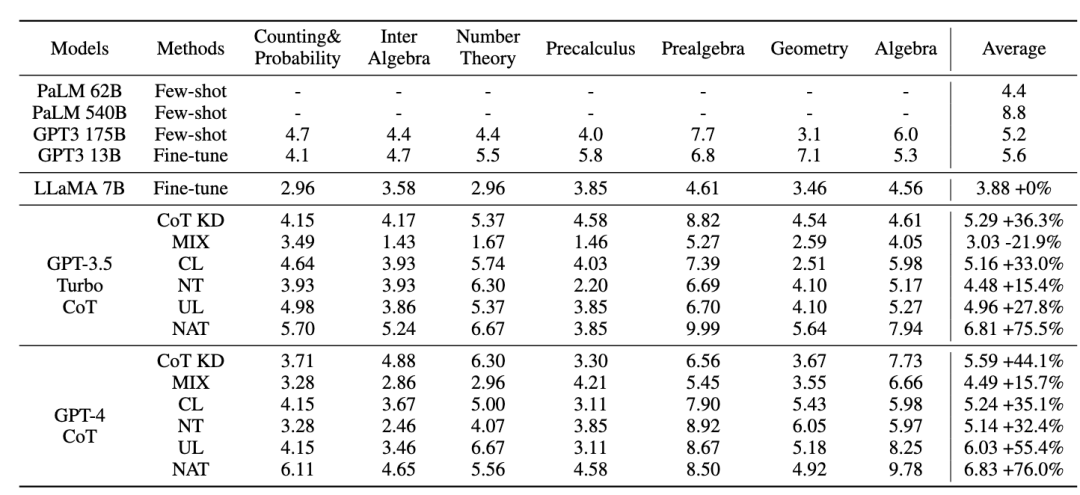
3.2 NCE 實(shí)驗(yàn)結(jié)果
如圖所示,與知識(shí)蒸餾(KD)相比,NCE 實(shí)現(xiàn)了平均 10%(0.66) 的進(jìn)步,這證明了利用負(fù)樣本提供的校準(zhǔn)信息進(jìn)行蒸餾的有效性。與 NAT 相比,盡管 NCE 減少了一些參數(shù),但它依然有 6.5% 的進(jìn)步,實(shí)現(xiàn)壓縮模型并提高性能的目的。
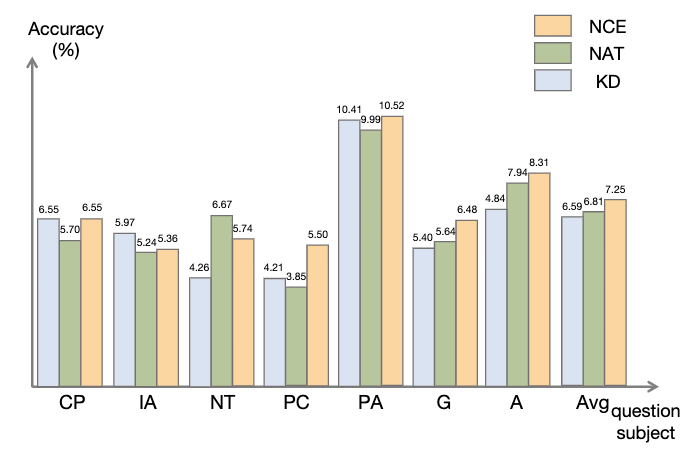
3.3 ASC 實(shí)驗(yàn)結(jié)果
為了評(píng)估 ASC,我們將其與基礎(chǔ) SC 和 加權(quán)(WS)SC 進(jìn)行比較,使用采樣溫度 T = 1 生成了 16 個(gè)樣本。如圖所示,結(jié)果表明,ASC 從不同樣本聚合答案,是一種更有前景的策略。
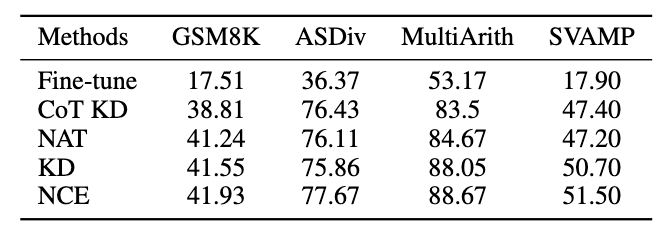
3.4 泛化性實(shí)驗(yàn)結(jié)果
除了 MATH 數(shù)據(jù)集,我們評(píng)估了框架在其他數(shù)學(xué)推理任務(wù)上的泛化能力,實(shí)驗(yàn)結(jié)果如下。
本項(xiàng)工作探討了利用負(fù)樣本從大語言模型中提煉復(fù)雜推理能力,遷移到專業(yè)化小模型的有效性。小紅書搜索算法團(tuán)隊(duì)提出了一個(gè)全新的框架,由三個(gè)序列化步驟組成,并在模型專業(yè)化的整個(gè)過程中充分利用負(fù)向信息。負(fù)向協(xié)助訓(xùn)練(NAT)可以從兩個(gè)角度提供更全面地利用負(fù)向信息的方法。負(fù)向校準(zhǔn)增強(qiáng)(NCE)能夠校準(zhǔn)自蒸餾過程,使其更有針對(duì)性地掌握關(guān)鍵知識(shí)。基于兩種觀點(diǎn)訓(xùn)練的排序模型可以為答案聚合分配更適當(dāng)?shù)臋?quán)重,以實(shí)現(xiàn)動(dòng)態(tài)自洽性(ASC)。大量實(shí)驗(yàn)表明,我們的框架可以通過生成的負(fù)樣本來提高提煉推理能力的有效性。
作者:
李易為:
現(xiàn)博士就讀于北京理工大學(xué),小紅書社區(qū)搜索實(shí)習(xí)生,在 AAAI、ACL、EMNLP、NAACL、NeurIPS、KBS 等機(jī)器學(xué)習(xí)、自然語言處理領(lǐng)域頂級(jí)會(huì)議/期刊上發(fā)表數(shù)篇論文,主要研究方向?yàn)榇笳Z言模型蒸餾與推理、開放域?qū)υ捝傻取?/p>
袁沛文:
現(xiàn)博士就讀于北京理工大學(xué),小紅書社區(qū)搜索實(shí)習(xí)生,在 NeurIPS、AAAI 等發(fā)表多篇一作論文,曾獲 DSTC11 Track 4 第二名。主要研究方向?yàn)榇笳Z言模型推理與評(píng)測。
馮少雄:
負(fù)責(zé)小紅書社區(qū)搜索向量召回。在 AAAI、EMNLP、ACL、NAACL、KBS 等機(jī)器學(xué)習(xí)、自然語言處理領(lǐng)域頂級(jí)會(huì)議/期刊上發(fā)表數(shù)篇論文。
道玄(潘博遠(yuǎn)):
小紅書交易搜索負(fù)責(zé)人。在NeurIPS、ICML、ACL 等機(jī)器學(xué)習(xí)和自然語言處理領(lǐng)域頂級(jí)會(huì)議上發(fā)表數(shù)篇一作論文,在斯坦福機(jī)器閱讀競賽 SQuAD 排行榜上獲得第二名,在斯坦福自然語言推理排行榜上獲得第一名。
曾書(曾書書):
小紅書社區(qū)搜索語義理解與召回方向負(fù)責(zé)人。碩士畢業(yè)于清華大學(xué)電子系,在互聯(lián)網(wǎng)領(lǐng)域先后從事自然語言處理、推薦、搜索等相關(guān)方向的算法工作。
審核編輯:黃飛
-
算法
+關(guān)注
關(guān)注
23文章
4600瀏覽量
92647 -
OpenAI
+關(guān)注
關(guān)注
9文章
1044瀏覽量
6408 -
大模型
+關(guān)注
關(guān)注
2文章
2333瀏覽量
2489 -
LLM
+關(guān)注
關(guān)注
0文章
274瀏覽量
306
原文標(biāo)題:小紅書搜索團(tuán)隊(duì)提出全新框架:驗(yàn)證負(fù)樣本對(duì)大模型蒸餾的價(jià)值
文章出處:【微信號(hào):zenRRan,微信公眾號(hào):深度學(xué)習(xí)自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
傳感器EMC的重要性與研究進(jìn)展
電機(jī)位置信號(hào)的重要性
論調(diào)節(jié)閥的重要性
討論紋理分析在圖像分類中的重要性及其在深度學(xué)習(xí)中使用紋理分析
電磁勢在量子理論中的重要性
ESD標(biāo)準(zhǔn)在汽車電子設(shè)計(jì)中的重要性
知乎搜索中文本相關(guān)性和知識(shí)蒸餾的工作實(shí)踐





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論