 【技術科普】主流的深度學習模型有哪些?AI開發工程師必備!
【技術科普】主流的深度學習模型有哪些?AI開發工程師必備!
深度學習在科學計算中獲得了廣泛的普及,其算法被廣泛用于解決復雜問題的行業。所有深度學習算法都使用不同類型的神經網絡來執行特定任務。
什么是深度學習
深度學習是機器學習領域的新研究方向,旨在使機器更接近于人工智能。它通過學習樣本數據的內在規律和表示層次,對文字、圖像和聲音等數據進行解釋。深度學習的目標是讓機器像人一樣具有分析學習能力,能夠識別文字、圖像和聲音等數據。深度學習模仿人類視聽和思考等活動,解決了很多復雜的模式識別難題,使得人工智能相關技術取得了很大進步。
雖然深度學習算法具有自學習表示,但它們依賴于反映大腦計算信息方式的人工神經網絡。在訓練過程中,算法使用輸入分布中的未知元素來提取特征、對對象進行分組并發現有用的數據模式。就像訓練機器進行自學一樣,這發生在多個層次上,使用算法來構建模型。
下面介紹一下目前主流的深度學習算法模型和應用案例。
目前主流的深度學習算法模型
01 RNN(循環神經網絡)
循環神經網絡(Recurrent Neural Network,RNN)它模擬了神經網絡中的記憶能力,并能夠處理具有時間序列特性的數據。它可以在給定序列數據上進行序列預測,具有一定的記憶能力,這得益于其隱藏層間的節點的連接。這種結構使其能夠處理時間序列數據,記憶過去的輸入,并通過時間反向傳播訓練。此外,RNN可以使用不同的架構變體來解決特定的問題。比如,LSTM(長短期記憶)和GRU(門控循環單元)是改進的算法,能夠解決RNN中常見的梯度消失或爆炸問題。在處理時間序列數據上,RNN具有強大的優勢,能夠有效捕捉數據中復雜的時間依賴關系,準確預測未來,因此它被廣泛應用于自然語言處理、語音識別、股票價格預測等領域。
關鍵技術:循環結構和記憶單元
處理數據:適合處理時間序列數據
應用場景:自然語言處理、語音識別、時間序列預測等

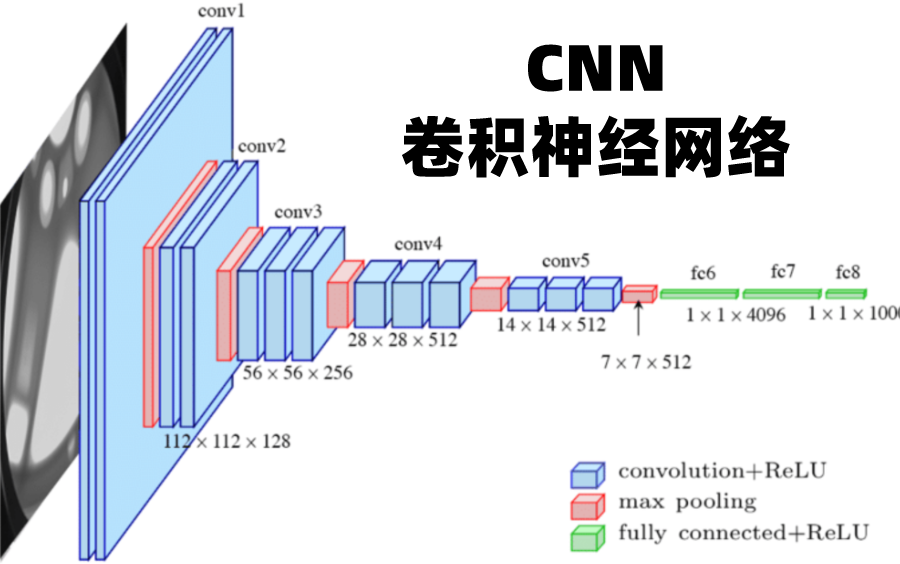
02 CNN(卷積神經網絡)
CNN基本原理是利用卷積運算,提取數據的局部特征。這種網絡架構由一個輸入層、一個輸出層和中間的多個隱藏層組成,使用卷積層、ReLU層和池化層來學習特定于數據的特征。其中,卷積層用于提取圖像中不同位置的特征,ReLU層用于將數值化的特征轉換為非線性形式,池化層用于減少特征的數量,同時保持特征的整體特征。在訓練過程中,CNN會通過反向傳播算法計算模型參數的梯度,并通過優化算法更新模型參數,使得損失函數達到最小值。CNN在圖像識別、人臉識別、自動駕駛、語音處理、自然語言處理等領域有廣泛的應用。
關鍵技術:卷積運算和池化操作
處理數據:適合處理圖像數據
03 Transformer
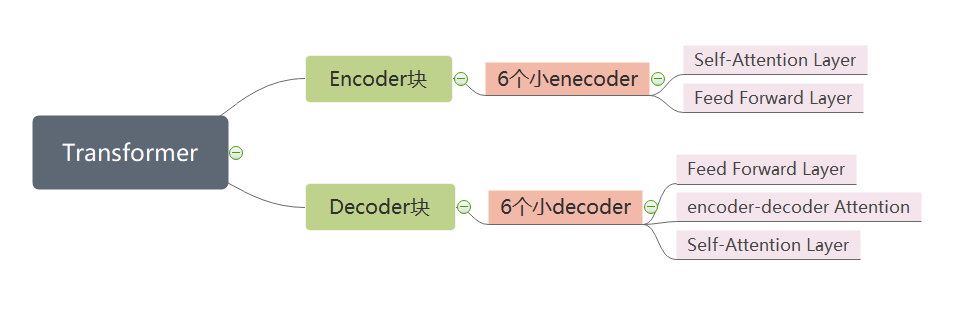
Transformer是一種基于自注意力機制的神經網絡模型,由Google在2017年提出,具有高效的并行計算能力和強大的表示能力。它是一種基于自注意力機制的神經網絡模型,使用注意力機制處理輸入序列和輸出序列之間的關系,因此可以實現長序列的并行處理。它的核心部分是注意力模塊,用于對輸入序列中的每個元素與輸出序列中的每個元素之間的相似性進行量化。這種模式在處理序列數據時表現出強大的性能,特別是在處理自然語言處理等序列數據任務時。因此,Transformer模型在自然語言處理領域得到了廣泛的應用,比如BERT、GPT和Transformer-XL等著名模型。但是,也存在一些限制,例如數據要求高、解釋性差和學習長距離依賴關系的能力有限等缺點,因此在應用時需要根據任務需求和數據特點進行選擇和優化。
關鍵技術:自注意力機制和多頭注意力機制
處理數據:適合處理長序列數據
應用場景:自然語言處理、機器翻譯、文本生成
04 BERT
BERT(Bidirectional Encoder Representations from Transformers)
是一種基于Transformer雙向編碼器的預訓練語言表征模型,BERT模型的目標是利用大規模無標注語料訓練、獲得文本的包含豐富語義信息的Representation,即文本的語義表示,然后將文本的語義表示在特定NLP任務中作微調,最終應用于該NLP任務。BERT模型強調不再采用傳統的單向語言模型或者把兩個單向語言模型進行淺層拼接的方法進行預訓練,而是采用新的masked language model(MLM),以致能生成深度的雙向語言表征。
關鍵技術:雙向Transformer編碼器和預訓練微調
處理數據:適合處理雙向上下文信息
應用場景:自然語言處理、文本分類、情感分析等
05 GPT(生成式預訓練Transformer模型)
GPT(Generative Pre-trained Transformer)是一種基于互聯網的、可用數據來訓練的、文本生成的深度學習模型。GPT模型的設計也是基于Transformer模型,這是一種用于序列建模的神經網絡結構。與傳統的循環神經網絡(RNN)不同,Transformer模型使用了自注意力機制,可以更好地處理長序列和并行計算,因此具有更好的效率和性能。GPT模型通過在大規模文本語料庫上進行無監督的預訓練來學習自然語言的語法、語義和語用等知識。
預訓練過程分為兩個階段:在第一個階段,模型需要學習填充掩碼語言模型(Masked Language Modeling,MLM)任務,即在輸入的句子中隨機掩蓋一些單詞,然后讓模型預測這些單詞;在第二個階段,模型需要學習連續文本預測(Next Sentence Prediction,NSP)任務,即輸入一對句子,模型需要判斷它們是否是相鄰的。GPT模型的性能已經接近或超越了一些人類專業領域的表現。
關鍵技術:單向Transformer編碼器和預訓練微調
處理數據:適合生成連貫的文本
應用場景:自然語言處理、文本生成、摘要等
以上是本期的技術科普內容,歡迎一起來討論~
審核編輯 黃宇
-
算法
+關注
關注
23文章
4599瀏覽量
92639 -
AI
+關注
關注
87文章
30106瀏覽量
268401 -
GPT
+關注
關注
0文章
351瀏覽量
15313 -
深度學習
+關注
關注
73文章
5492瀏覽量
120975
發布評論請先 登錄
相關推薦

圖像算法工程師的利器——SpeedDP深度學習算法開發平臺



AI真·煉丹:整整14天,無需人類參與
嵌入式軟件工程師和硬件工程師的區別?
芯片封裝工程師必備知識和學習指南

FPGA在深度學習應用中或將取代GPU
技術科普 | 機器視覺5大關鍵技術及其常見應用

優秀電源工程師需要哪些必備技能?






 工商網監
工商網監
評論