 如何在TorchServe上提供LLMs的分布式推理
如何在TorchServe上提供LLMs的分布式推理
這里是Hamid,我來自PyTorch合作伙伴工程部。我將跟隨Mark的討論,講解如何在TorchServe上提供LLMs的分布式推理和其他功能。首先,為什么需要分布式推理呢?簡單來說,大部分這些模型無法適應單個GPU。

通常,GPU的內存介于16到40GB之間,如果考慮一個30B模型,在半精度下需要60GB的內存,或者70B Lama模型在半精度下至少需要140GB的內存。這意味著至少需要8個GPU。因此,我們需要一種解決方案將這些模型分區到多個設備上。我們來看看在這個領域有哪些模型并行化的解決方案和方法。
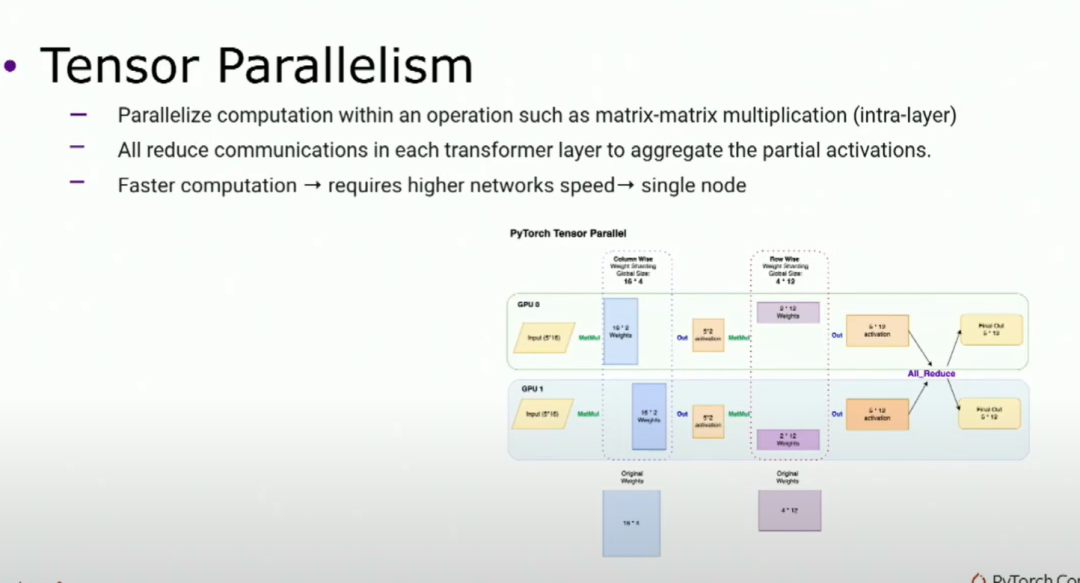
目前有兩種主要方法。一種是張量并行,你基本上在op內部(如矩陣乘法)上切割你的模型,從而并行化計算。這會引入一個通信,就像全歸約一樣,如果你有足夠的工作負載,使用流水線并行計算會更快,但需要更高速的網絡。原因是要保持GPU忙碌,因為它是在操作并行化中。所以它更適用于單節點計算。
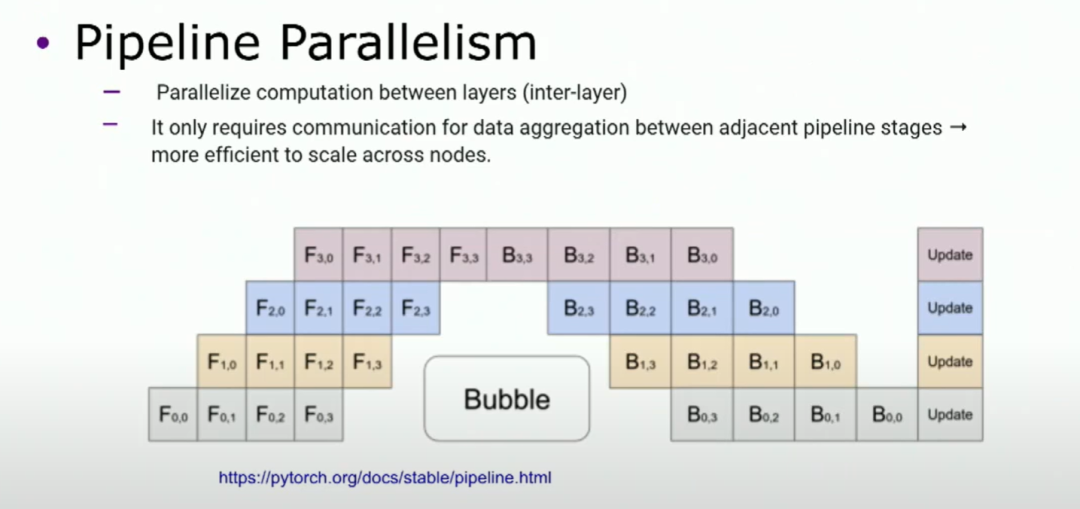
另一種主要方法是流水線并行,基本上將模型水平切分成多個階段,每個階段包含一組層。所以你將第一個階段的輸出作為第二個階段的輸入。在這里,我們需要將這種技術與micro批處理結合使用,否則無法有效利用GPU。由于通信的性質,流水線并行更適用于多節點的擴展。
·ModifyModelCode Megatron,TransformerNeuronx,Fairscale,etc. DefineParallellayers-buildthemodelwithparallellayers boundtospecifictrainers ·PyTorchAPIs WraptheoriginalmodelwithAPIs Automaticallypartitionthemodel Traineragnostic
那么,我們今天在OSS空間實際上如何實現這些模型呢?這里有兩種主要方法。一種是修改你的模型代碼。基本上,定義你的并行層,并在這些并行層之上構建你的模型。這非常像transformers的風格。我們在不同的repo中也看到了這一點,比如megatron,Transformer,Neuronics來自AWS。而且大多數這種并行性都限定在特定的訓練上。而另一方面,我們有PyTorch的API,它采用了一種不同的策略。它大多數情況下不需要改變或只需進行最小的改動來適應您的模型,它只需要檢查您的模型,并自動對其進行分割。它也可以在訓練過程中保持中立。

這里有一個修改模型代碼的例子,這是在Fairscale上構建的LLAMA2模型的例子。正如您在左側可以看到的那樣,我們實際上正在定義那些并行層,在注意層中,您可以看到我們正在在那些并行層之上構建模型。如我所說,這是Fairscale,但是Megatron,Transformer和AX都是相同的性質。另一方面,這是PyTorch的API,用于流水線并行。我們有一個名為PP的軟件包,它處于測試階段。它的作用是使用模型并行地進行計算

為了理解你的模型并將其分成多個階段,使用tracing方法是非常重要的。這個框架提供了一個非常簡單的API,只需要將你的模型輸入其中,就能得到一個已經在不同GPU上進行了分布的多個階段。它還支持延遲初始化,我們稍后會詳細討論。此外,我們還有適用于PyTorch的tensor并行API,與張量一起使用。

如果你看一下這些代碼,基本上,你可以將你的分片策略傳遞給并行模塊,它會簡單地將你的模塊并行化到不同的設備上。這又是相同的策略,你不需要改變你的模型代碼。它們都是訓練無關的,所以你可以在從不同庫中導入任意的檢查點時進行推理。接下來,我來強調一下我們在分布式推理中所面臨的一些挑戰。首先,大多數的開源解決方案都與特定的訓練器綁定。
1. Most of the OS solutions are bound to specific trainers or require model changes: -ExamplesincludeDeepSpeed,Accelerate,ParallelFormer,TGI,vLLM,etc. 2.Automaticpartitioningofarbitrarycheckpoints: -APIstoautomaticallypartitionyourmodelcheckpoints(trainer-agnostic) -Enablesautomaticpartitioningofarbitrarycheckpoints. 3.Deferredinitialization(loadingpretrainedweights): -AvoidloadingthewholemodelonCPUordevice. -Supportsdeferredinitializationtoloadpretrainedweightsondemand. 4.Checkpointconversion: -Convertcheckpointstrained/savedwithdifferentecosystemlibrariestoPyTorchDistributedcheckpoints.
正如我提到的,他們需要模型的改變,比如deepspeed、VLLM等。所以這需要一種解決方案,能自動對模型和任意檢查點進行分區。所以無論你用哪個訓練器訓練過你的模型,它實際上應該能夠將你的模型進行分區。這里還有另外兩個挑戰,就是延遲初始化,正如Mark所談的。它可以幫助你更快地加載模型,并在某些情況下避免在CPU和GPU上的開銷。而且,如果你必須將模型放在操作系統上,也可以使用這種方式。然后我們有一個檢查點轉換,我這里稍微談一下。這是今天的初始化方式。
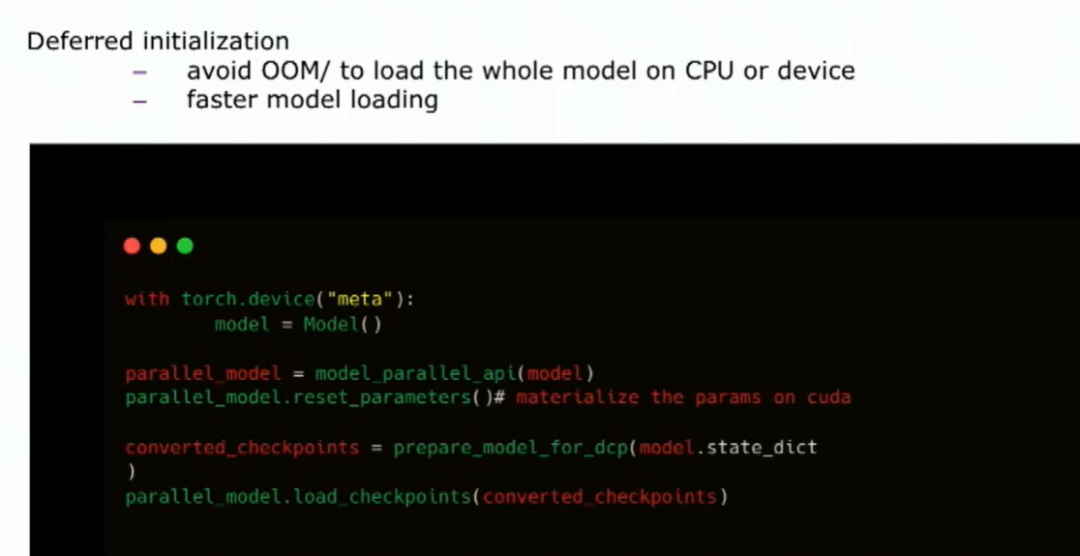
所以你可以使用元設備來初始化你的模型。然后你請求模型并行API并行化你的模型。你必須手動地實現你的參數。但是在這里還有一個額外的步驟,你必須將你的模型檢查點轉換為PyTorch分布式可以理解的張量形式。所以,在它們之間有一個檢查點轉換的過程。你可以使用PyTorch分布式檢查點API來加載模型。這樣,你實際上可以使用延遲初始化。這里有一個額外的步驟,我們正在研究如何在這里去除檢查點轉換。

好的,談論一下分布式推理和不同的模型并行化。現在讓我們轉向Torchserve,看看我們在Torchserve上支持什么。今天在Torchserve上,我們已經集成了分布式推理解決方案,我們與DeepSpeed、Hugging Face Accelerate、Neuron SDK與AWS自定義芯片都有集成。Torchserve原生API還具備PP和TP功能。我們還有微批處理、連續批處理和流式響應的API,這是我們團隊和AWS的Matias和Lee共同開發的。

現在讓我們來看一下PP。在這里,我們有高度流水線并行處理,我們已經初始化了這項工作,并啟用了路徑。我們的主要目標是專注于使用的便利性和功能。您可以看到,我們在這里提供了一個一行代碼的API,您可以輕松地將您的模型傳遞進去,特別是所有的Hugging Face模型,您實際上可以獲得階段并簡單地初始化您的模型。
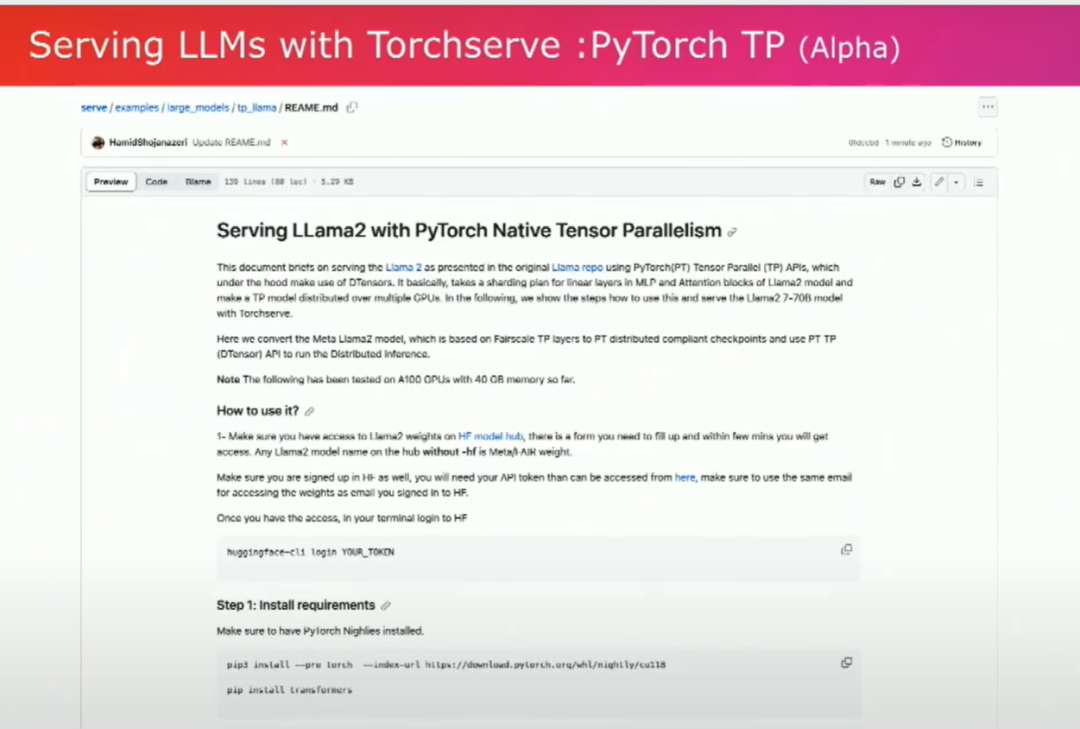
然后,我們最近還為Lama啟用了d-tensors來實現張量并行。這是初始的一步。我們已經啟用了這條路徑,但我們也正在努力優化推理路徑。所以請繼續關注這里,很快就會有新的更新。
關于微批處理,如果您想要使用管道并行處理,微批處理非常重要。我們有一些非常好的微批處理示例,可以幫助您輕松入門。它既有助于更好地利用GPU,也可以在某些情況下并行化預處理,比如處理一些您正在處理的視覺模型。所以可以有一個繁重的預處理任務,我們可以在這里實現并行化,使用多線程。我們還有連續批處理和其他供LLM服務配置使用的成分。這里的想法是當一個請求完成時,將隊列中的請求連續添加到當前批次中作為一個請求。所以你不需要等待整個批次完成再發送下一個請求。
正如馬克所說的,基本上就是動態批處理。因此,這將有助于提高吞吐量和用戶體驗。我們來看下一個功能,即流式響應API。

再次強調,當您向這些LLMs發送請求時,它們可能需要很長時間進行推理和生成令牌。因此,流式API將幫助您獲取每個令牌的生成,而無需等待整個序列的生成。您將逐個生成的令牌返回到客戶端。因此,這是一個很好的功能可以實現和集成到友好的環境中。在這里,您可以看到我們定義了兩個API。一個是發送中間預測響應的API,您可以使用該API。我們使用了HuggingFace文本迭代器來進行流式批處理。通過這兩個的組合,我們在這里實際上有LLAMA2的示例。
再說一次,正如我所談到的,我們與所有這些功能進行了集成,包括所有這些不同的庫,如HuggingFace、PP、DeepSpeed、DeepSpeedM2、Inferentia2。在這里,我們實際上已經發布了一個很新的推理示例,并且我們在此發布了一個使用案例。
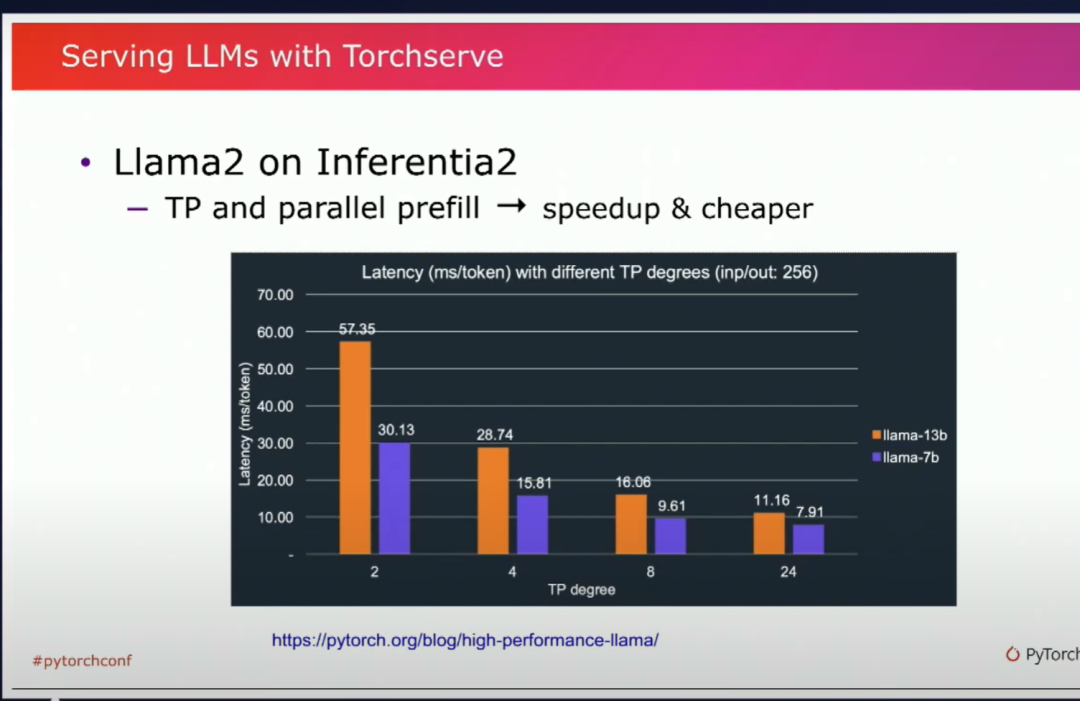
你可以看到我們在這里使用了張量并行和并行預填充。它實際上幫助大大加快了推理速度。與等效的GPU相比,它使得Inferentia 2的成本大幅降低了。我們獲得了3倍更便宜的性能點。因此,我強烈建議你也看一看這個示例。

Mark談了很多不同的優化,補充優化方法使模型更快。他談到了內存限制、CPU限制,對于特定的LLMs來說,還有兩個重要的事情,即KV緩存。這非常重要。它可能會占用非常多的內存,并且會受到內存限制的影響。因此,類似于pageattention的想法在這里可能有幫助。另一個要考慮的因素是量化。

到此結束,謝謝。
審核編輯:黃飛
-
gpu
+關注
關注
28文章
4702瀏覽量
128710 -
內存
+關注
關注
8文章
3002瀏覽量
73889 -
并行處理
+關注
關注
0文章
11瀏覽量
7736 -
pytorch
+關注
關注
2文章
803瀏覽量
13150 -
LLM
+關注
關注
0文章
274瀏覽量
306
原文標題:《PytorchConference2023 翻譯系列》18-如何在TorchServe上提供LLMs的分布式推理
文章出處:【微信號:GiantPandaCV,微信公眾號:GiantPandaCV】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
LED分布式恒流原理
分布式發電技術與微型電網
使用分布式I/O進行實時部署系統的設計
分布式光伏發電安全性
如何設計分布式干擾系統?
分布式系統的優勢是什么?
HarmonyOS應用開發-分布式設計
HarmonyOS分布式應用框架深入解讀
如何高效完成HarmonyOS分布式應用測試?
【學習打卡】OpenHarmony的分布式任務調度
常見的分布式供電技術有哪些?
tldb提供分布式鎖使用方法





 工商網監
工商網監
評論