") OpenVINO? 賦能千元級(jí)『哪吒』AI開發(fā)套件大語言模型 | 開發(fā)者實(shí)戰(zhàn)
OpenVINO? 賦能千元級(jí)『哪吒』AI開發(fā)套件大語言模型 | 開發(fā)者實(shí)戰(zhàn)
以下文章來源于英特爾物聯(lián)網(wǎng) ,作者武卓
作者:英特爾AI軟件布道師 武卓 博士
在人工智能的飛速發(fā)展中,大語言模型,如Stable-Zephyr-3b,已成為研究和應(yīng)用的熱點(diǎn)。這些模型以其強(qiáng)大的文本理解和生成能力在多個(gè)領(lǐng)域大放異彩。然而,大多數(shù)高性能模型通常需要昂貴的計(jì)算資源,使得它們的應(yīng)用受限于有限的環(huán)境。本文將探討在OpenVINO的賦能下,如何在不足千元的AI開發(fā)板上部署Stable-Zephyr-3b模型,構(gòu)建聊天機(jī)器人,成為實(shí)現(xiàn)AI無處不在愿景的重要組成部分之一。
Stable Zephyr 3B是一個(gè)先進(jìn)的大語言模型,擁有30億參數(shù),它在多個(gè)語言處理任務(wù)上顯示出了優(yōu)異的性能。這個(gè)模型特別是在大小相對(duì)較小的情況下,比許多流行模型都要出色,這表明了它高效的參數(shù)使用和強(qiáng)大的學(xué)習(xí)能力。該模型的訓(xùn)練靈感來自于HugginFaceH4的Zephyr 7B訓(xùn)練管道,這是一個(gè)專注于高效訓(xùn)練和性能優(yōu)化的系統(tǒng)。Stable Zephyr 3B是在混合的數(shù)據(jù)集上進(jìn)行訓(xùn)練的,包括了公開可用的數(shù)據(jù)集和通過直接偏好優(yōu)化(DPO)技術(shù)生成的合成數(shù)據(jù)集。DPO是一種優(yōu)化技術(shù),它直接在模型的偏好上施加約束,以產(chǎn)生更高質(zhì)量的數(shù)據(jù)供模型學(xué)習(xí)。
該模型的性能評(píng)估是基于MT Bench和Alpaca Benchmark,這兩個(gè)基準(zhǔn)都是在業(yè)界公認(rèn)的,用以衡量語言模型在多種任務(wù)上的效能。通過這些嚴(yán)格的評(píng)估,Stable Zephyr 3B展現(xiàn)了其在理解和生成語言方面的卓越能力。更多關(guān)于模型的架構(gòu)、訓(xùn)練過程、使用的數(shù)據(jù)集以及在各項(xiàng)評(píng)估中的表現(xiàn)的信息可以在模型卡片中找到。
此文使用了研揚(yáng)科技針對(duì)邊緣AI行業(yè)開發(fā)者推出了哪吒(Nezha)開發(fā)套件以信用卡大小(85 x 56mm)的開發(fā)板-哪吒(Nezha)為核心,哪吒采用Intel N97處理器(Alder Lake-N),最大睿頻3.6GHz,IntelUHD Graphics內(nèi)核GPU,可實(shí)現(xiàn)高分辨率顯示;板載LPDDR5內(nèi)存、eMMC存儲(chǔ)及TPM 2.0,配備GPIO接口,支持Windows和Linux操作系統(tǒng),這些功能和無風(fēng)扇散熱方式相結(jié)合,為各種應(yīng)用程序構(gòu)建高效的解決方案,適用于如自動(dòng)化、物聯(lián)網(wǎng)網(wǎng)關(guān)、數(shù)字標(biāo)牌和機(jī)器人等應(yīng)用。
要在這些資源有限的設(shè)備上運(yùn)行如Stable-Zephyr-3b這樣的大型模型,模型的壓縮和優(yōu)化是關(guān)鍵。借助OpenVINO提供的模型優(yōu)化工具NNCF,可以將模型量化壓縮為INT4精度的模型,從而可以大幅度減少模型的大小和計(jì)算需求,而保持相對(duì)較高的性能。接下來,就讓我們通過我們常用的OpenVINO Notebooks倉庫中關(guān)于Stable Zephyr 3B模型的Jupyter Notebook代碼和拆解,來進(jìn)一步了解具體步驟吧。(Jupyter notebook代碼地址:
https://github.com/openvinotoolkit/openvino_notebooks/tree/main/notebooks/273-stable-zephyr-3b-chatbot )
第一步:安裝相應(yīng)工具包
為了方便模型轉(zhuǎn)換步驟和模型性能評(píng)估,我們將使用llm_bench(https://github.com/openvinotoolkit/openvino.genai/tree/master/llm_bench/python )工具,該工具提供了一種統(tǒng)一的方法來估計(jì)大語言模型(LLM)的性能。它基于由Optimum-Intel提供的管道,并允許使用幾乎相同的代碼來估計(jì)Pytorch和OpenVINO模型的性能。
首先git clone llm_bench所在的代碼倉庫:
from pathlibimport Path
import sys
genai_llm_bench = Path("openvino.genai/llm_bench/python")
ifnot genai_llm_bench.exists():
!git clone https://github.com/openvinotoolkit/openvino.genai.git
sys.path.append(str(genai_llm_bench))
并進(jìn)行相關(guān)Python包的安裝:
%pip uninstall -q -y optimum-intel optimum
%pip install -q --extra-index-url https://download.pytorch.org/whl/cpu -r ./openvino.genai/llm_bench/python/requirements.txt
%pip uninstall -q -y openvino openvino-dev openvino-nightly
%pip install -q openvino-nightly
第二步:將模型轉(zhuǎn)換為OpenVINO IR格式,并利用NNCF將模型權(quán)重壓縮為INT4精度
llm_bench提供了一個(gè)轉(zhuǎn)換腳本,用于將大語言模型轉(zhuǎn)換為與Optimum-Intel兼容的OpenVINO IR格式。它還允許使用NNCF將模型權(quán)重壓縮為INT8或INT4精度。要啟用INT4的權(quán)重壓縮,我們應(yīng)該使用--compress_weights 4BIT_DEFAULT 參數(shù)。權(quán)重壓縮算法旨在壓縮模型的權(quán)重,并可用于優(yōu)化大模型的占用空間和性能。與INT8壓縮相比,INT4壓縮進(jìn)一步提高了性能,但會(huì)引入輕微的預(yù)測質(zhì)量下降。
model_path = Path("stable-zephyr-3b/pytorch/dldt/compressed_weights/OV_FP16-4BIT_DEFAULT")
convert_script = genai_llm_bench / "convert.py"
!python $convert_script --model_id stabilityai/stable-zephyr-3b --precision FP16 --compress_weights 4BIT_DEFAULT --output stable-ze
第三步:評(píng)估模型性能
openvino.genai / llm_bench / python / benchmark.py腳本允許在特定輸入提示上估計(jì)文本生成管道的推理,給定最大生成分詞的數(shù)量。模型性能評(píng)估以時(shí)延為主。
benchmark_script = genai_llm_bench /"benchmark.py"
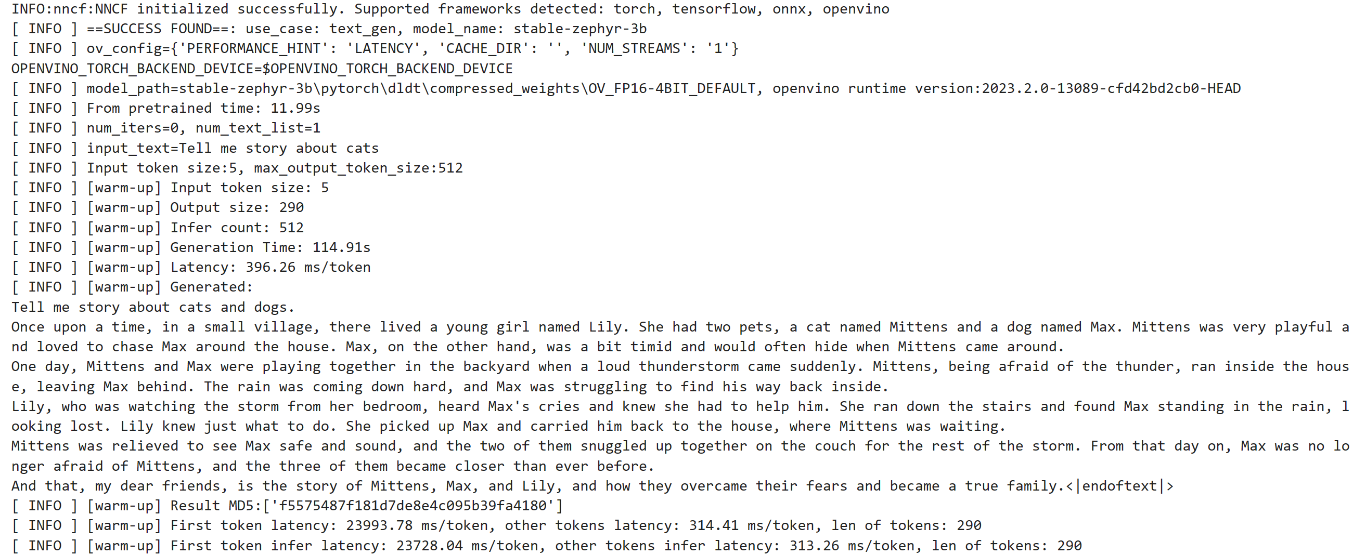
!python $benchmark_script -m $model_path -ic512 -p"Tell me story about cats"
運(yùn)行結(jié)果如下:
第四步:應(yīng)用狀態(tài)變換來自動(dòng)處理模型狀態(tài)
Stable Zephyr是一種自回歸的解碼器變換器模型,它通過緩存先前計(jì)算的隱藏狀態(tài)來優(yōu)化生成過程和內(nèi)存使用,避免每次生成新令牌時(shí)重復(fù)計(jì)算。隨著模型和注意力塊的增大,處理長序列的緩存策略可能對(duì)內(nèi)存系統(tǒng)構(gòu)成挑戰(zhàn)。因此,OpenVINO提出了一種轉(zhuǎn)換策略,將緩存邏輯內(nèi)置于模型中以降低內(nèi)存消耗并優(yōu)化性能。您可以通過在轉(zhuǎn)換步驟中使用--stateful標(biāo)志添加有狀態(tài)轉(zhuǎn)換來估計(jì)模型性能。
stateful_model_path = Path("stable-zephyr-3b-stateful/pytorch/dldt/compressed_weights/OV_FP16-4BIT_DEFAULT")
!python $convert_script --model_id stabilityai/stable-zephyr-3b --precision FP16 --compress_weights 4BIT_DEFAULT --output stable-zephyr-3b-stateful --force_convert --stateful
第五步:利用Optimum-Intel加載模型并在基于Gradio搭建的用戶界面上運(yùn)行模型
同樣地,這個(gè)模型也可以用Optimum-Intel工具包里定義的OVModelForCausalLM 流水線來加載模型和運(yùn)行推理,代碼如下:
from utils.ov_model_classesimport register_normalized_configs
from optimum.intel.openvinoimport OVModelForCausalLM
from transformers import AutoConfig
# Load model into Optimum Interface
register_normalized_configs()
ov_model = OVModelForCausalLM.from_pretrained(model_path, compile=False, config=AutoConfig.from_pretrained(stateful_model_path, trust_remote_code=True), stateful=True)
和我們的很多大預(yù)言模型和生成式AI的Notebook示例代碼一樣,在這個(gè)Notebook中,我們也提供了基于Gradio編寫的用戶友好的使用界面。最終在我們的哪吒開發(fā)板上運(yùn)行該模型的推理。
整個(gè)的步驟就是這樣!現(xiàn)在就開始跟著我們提供的代碼和步驟,動(dòng)手試試用OpenVINO在哪吒開發(fā)板上運(yùn)行基于大語言模型的聊天機(jī)器人吧。
-
AI
+關(guān)注
關(guān)注
87文章
30106瀏覽量
268399 -
人工智能
+關(guān)注
關(guān)注
1791文章
46845瀏覽量
237535 -
OpenVINO
+關(guān)注
關(guān)注
0文章
87瀏覽量
181
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
基于哪吒開發(fā)板部署YOLOv8模型

OpenVINO? C++ 在哪吒開發(fā)板上推理 Transformer 模型|開發(fā)者實(shí)戰(zhàn)

NVIDIA RTX AI套件簡化AI驅(qū)動(dòng)的應(yīng)用開發(fā)
【xG24 Matter開發(fā)套件試用體驗(yàn)】初識(shí)xG24 Matter開發(fā)套件
2024 TUYA全球開發(fā)者大會(huì)盛大啟幕,Cube AI大模型重磅首發(fā)!

2024 TUYA全球開發(fā)者大會(huì)盛大啟幕,Cube AI大模型重磅首發(fā)!

聯(lián)發(fā)科發(fā)布天璣AI開發(fā)套件,賦能終端生成式AI應(yīng)用
英特爾開發(fā)套件『哪吒』在Java環(huán)境實(shí)現(xiàn)ADAS道路識(shí)別演示 | 開發(fā)者實(shí)戰(zhàn)

傳智教育聯(lián)合科大訊飛舉辦“AI開發(fā)者TALK”活動(dòng)

香橙派全球開發(fā)者峰會(huì)發(fā)布多款AI賦能新品及全新AI戰(zhàn)略

【轉(zhuǎn)載】英特爾開發(fā)套件“哪吒”快速部署YoloV8 on Java | 開發(fā)者實(shí)戰(zhàn)

基于英特爾哪吒開發(fā)者套件平臺(tái)來快速部署OpenVINO Java實(shí)戰(zhàn)
英飛凌推出CYUSBS236 USB轉(zhuǎn)串行通信(雙通道)開發(fā)套件
如何快速下載OpenVINO Notebooks中的AI大模型






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論