 云原生是大模型“降本增效”的解藥嗎?
云原生是大模型“降本增效”的解藥嗎?
在過去一兩年里,以GPT和Diffusion model為代表的大語言模型和生成式AI,將人們對AI的期待推向了一個新高峰,并吸引了千行百業嘗試在業務中利用大模型。
國內各家大廠在大模型領域展開了激烈的軍備競賽,如:文心大模型、通義千問、混元大模型、盤古大模型等等,這些超大規模的模型訓練參數都在千億以上,有的甚至超過萬億級。
即便訓練一次千億參數量模型的成本可能就高達數百萬美元,但大廠們依然拼盡全力,除此之外也有很多行業企業希望擁有自己的專屬大模型。
對于企業來說,要想在大模型的競爭中勝出,就必須充分利用算力,并且構建高效穩定的服務運行環境,這就對IT基礎設施能力提出了更高的要求。
而云原生正是比拼的重要一環。云原生技術的自動化部署和管理、彈性伸縮等功能,能夠有效提高大模型應用效率并降低成本。
據Gartner預測,2023年70%的AI應用會基于容器和Serverless技術開發。在實際生產中,越來越多的AI業務,比如自動駕駛、NLP等,也正在轉向容器化部署。
那么,云原生是如何幫助大模型降本增效,在這個過程中又遇到了哪些挑戰?
云原生成為大模型的標配
近年來,容器和Kubernetes已經成為越來越多AI應用首選的運行環境和平臺。
一方面,Kubernetes幫助用戶標準化異構資源和運行時環境、簡化運維流程;另一方面,AI這種重度依賴GPU的場景可以利用K8s的彈性優勢節省資源成本。
隨著大模型浪潮的到來,以云原生環境運行AI應用正在變成一種事實標準。
彈性伸縮與資源管理
大模型訓練往往需要大量的計算資源,而云原生環境通過容器化和編排工具可以實現資源的彈性調度與自動擴縮容。
這意味著在大模型訓練過程中可以迅速獲取所需資源,并在任務完成后釋放資源,降低閑置成本。
分布式計算支持
云原生架構天然支持分布式系統,大模型訓練過程中的并行計算需求可以通過云上的分布式集群輕松實現,從而加速模型收斂速度。
微服務架構與模塊化設計
大模型推理服務可以被分解為多個微服務,比如預處理服務、模型加載服務和后處理服務等,這些服務能夠在云原生環境中獨立部署、升級和擴展,提高系統的可維護性和迭代效率。
持續集成/持續部署(CI/CD)
云原生理念強調快速迭代和自動化運維,借助CI/CD流程,大模型的研發團隊能夠以更高效的方式構建、測試和部署模型版本,確保模型更新的敏捷性。
存儲與數據處理
云原生提供了多種數據持久化和臨時存儲解決方案,有助于解決大模型所需的大量數據讀取和寫入問題。
同時,利用云上大數據處理和流式計算能力可以對大規模數據進行有效預處理和后處理。
可觀測性和故障恢復
在云原生環境下,監控、日志和追蹤功能完善,使得大模型服務的狀態更加透明,遇到問題時能更快地定位和修復,保證服務高可用性。
總體而言,云原生架構的諸多優勢契合了大模型在計算密集、數據驅動、迭代頻繁等方面的需求,能夠為大模型帶來成本、性能、效率等多方面的價值,因而成為大模型發展的標配。
大模型對云原生能力提出新挑戰
盡管云原生對于大模型有著天然的優勢,但是面對LLM、AIGC這樣的新領域,依然對云原生能力提出了更多挑戰。
在訓練階段,大模型對計算、存儲、網絡等基礎架構的要求都更高。
規模上,要訓練出具有廣泛知識和專業領域理解及推理能力的大語言模型,往往需要高達萬卡級別的GPU集群和PB級的數據存儲以及TB級的數據吞吐。
此外,高性能網絡也將達到單機800Gbps甚至3.2Tbps的RDMA互聯。
性能方面,隨著模型體積和參數量的增長,單張顯卡已無法承載完整的模型。因此需要使用多張顯卡進行分布式訓練,并采用各種混合并行策略進行加速。
這些策略包括數據并行、模型并行、流水線并行以及針對語言模型的序列并行等,以及各種復雜的組合策略。
在推理階段,大模型需要提供高效且穩定的推理服務,這需要不斷優化其性能,并確保服務質量(QoS)得到保證。
在此基礎上,最重要的目標是提高資源效率和工程效率。一方面,持續提高資源利用效率,并通過彈性擴展資源規模,以應對突發的計算需求。
另一方面,要最優化算法人員的工作效率,提高模型迭代速度和質量。
由此可見,大模型對云原生技術提出了新的能力要求:
一是,統一管理異構資源,提升資源利用率。
從異構資源管理的角度,對IaaS云服務或者IDC內的各種異構計算(如 CPU,GPU,NPU,VPU,FPGA,ASIC)、存儲(OSS,NAS, CPFS,HDFS)、網絡(TCP, RDMA)資源進行抽象,統一管理、運維和分配,通過彈性和軟硬協同優化,持續提升資源利用率。
在運維過程中,需要多維度的異構資源可觀測性,包括監控、健康檢查、告警、自愈等自動化運維能力。
對于寶貴的計算資源,如GPU和NPU等加速器,需要通過各種調度、隔離和共享的方法,最大限度地提高其利用率。
在此過程中,還需要持續利用云資源的彈性特征,持續提高資源的交付和使用效率。
二是,通過統一工作流和調度,實現 AI、大數據等多類復雜任務的高效管理。
對于大規模分布式AI任務,需要提供豐富的任務調度策略,如Gang scheduling、Capacity scheduling、Topology aware scheduling、優先級隊列等,并使用工作流或數據流的方式串聯起整個任務流水線。
同時,需兼容Tensorflow,Pytorch,Horovod,ONNX,Spark,Flink等各種計算引擎和運行時,統一運行各類異構工作負載流程,統一管理作業生命周期,統一調度任務工作流,保證任務規模和性能。
一方面不斷提升運行任務的性價比,另一方面持續改善開發運維體驗和工程效率。
此外,在計算框架與算法層面適配資源彈性能力,提供彈性訓練和彈性推理服務,優化任務整體運行成本。
除了計算任務優化,還應關注數據使用效率的優化。為此,需要統一的數據集管理、模型管理和訪問性能優化等功能,并通過標準API和開放式架構使其易于被業務應用程序集成。
對于大模型還有一個主要能力,就是能夠在分鐘級內準備好開發環境和集群測試環境,幫助算法工程師開始執行深度學習任務。
把端到端的 AI 生產過程通過相同的編程模型、運維方式進行交付。
結語
隨著大模型等AI技術的不斷發展,云原生技術將面臨一些新的挑戰和需求。例如,如何快速適應新的開源大模型訓練方法,以及如何提高大模型推理性能并確保其質量和穩定性。
同時,也需要關注一些前沿技術和創新能力,通過標準化和可編程的方式來集成,不斷迭代業務應用,形成 AI+ 或 LLM+ 的新應用開發模式和編程模型。
但無論技術如何發展,為大模型提供快速、準確、穩定且成本可控的服務,保證大模型訓練和推理的成本、性能和效率,都將成為企業為其價值買單的根本。
【關于科技云報道】
專注于原創的企業級內容行家——科技云報道。成立于2015年,是前沿企業級IT領域Top10媒體。獲工信部權威認可,可信云、全球云計算大會官方指定傳播媒體之一。深入原創報道云計算、大數據、人工智能、區塊鏈等領域。
審核編輯 黃宇
-
AI
+關注
關注
87文章
30106瀏覽量
268398 -
云原生
+關注
關注
0文章
241瀏覽量
7937 -
大模型
+關注
關注
2文章
2322瀏覽量
2479
發布評論請先 登錄
相關推薦
戴爾科技助力企業實現科學的降本增效
云原生和非云原生哪個好?六大區別詳細對比
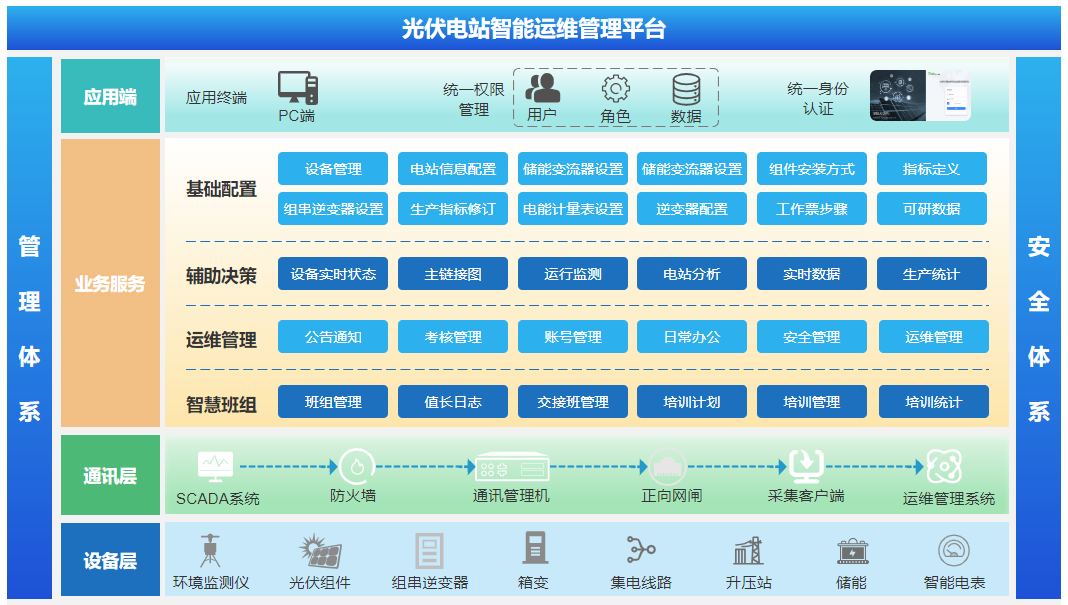
光伏電站智慧運維系統助力光伏電站降本增效
市場解讀 對話展商 磁元件峰會揭秘新能源降本增效秘籍

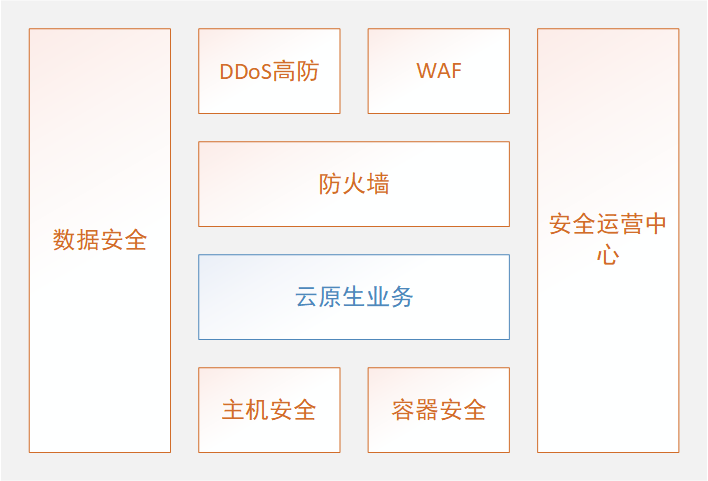
京東云原生安全產品重磅發布
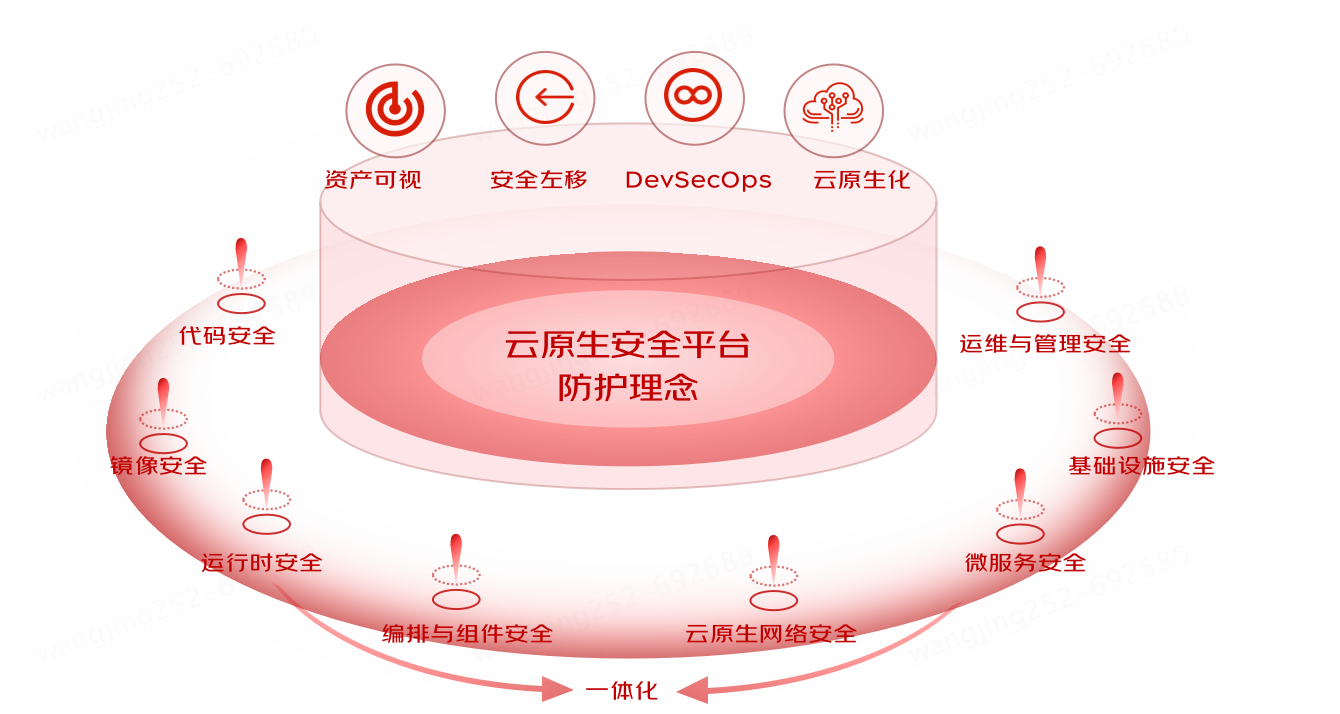
從積木式到裝配式云原生安全
AR眼鏡:醫藥廠商降本增效新利器
直線電機模組:米思米如何以“磁”之力,引領降本增效新風尚?
隆基分布式光伏電站助力鑄造企業降本增效
原邊控制充電器芯片U6776D有利降本增效

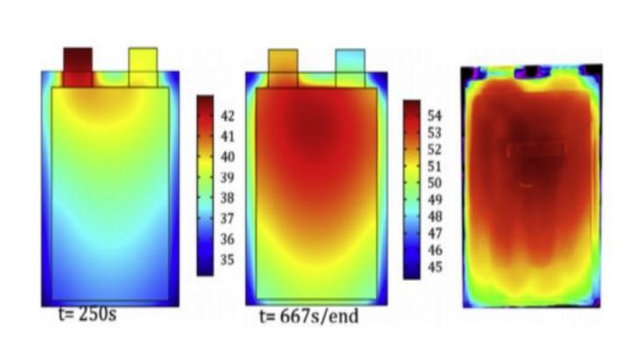
降本增效,智能制造,離不開儲能散熱管理






 工商網監
工商網監
評論