") 字節(jié)跳動(dòng)推出一款顛覆性視頻模型—Boximator
字節(jié)跳動(dòng)推出一款顛覆性視頻模型—Boximator
來源|AIGC開放社區(qū)
在 Sora 引爆文生視頻賽道之前,國內(nèi)的字節(jié)跳動(dòng)也推出了一款顛覆性視頻模型——Boximator。
與 Gen-2、Pink1.0 等模型不同的是,Boximator 可以通過文本精準(zhǔn)控制生成視頻中人物或物體的動(dòng)作。
例如,下雨天,大風(fēng)把一位女生的雨傘吹走了。目前,很少有視頻模型能精準(zhǔn)做到這一點(diǎn)。
Boximator 案例賞析
我們先看一下 Boximator 與 Gen-2、Pink1.0,在使用相同的文本提示詞、圖像生成的視頻,所表現(xiàn)出來的不同動(dòng)作。
為了方便觀察,「AIGC 開放社區(qū)」將對(duì)比視頻整合在一起,最左邊的是 Boximator 生成的視頻。
一個(gè)可愛的 3D 男孩站著,然后走路
在這個(gè)案例中,Pika 1.0 生成的視頻男孩只是站著沒有走動(dòng),Gen-2 的視頻走動(dòng)了但不明顯,只有 Boximator 產(chǎn)生了明顯的走動(dòng)動(dòng)作。
一位英俊的男人用他的右手從口袋里拿出一朵玫瑰,并且在看著這朵玫瑰
這個(gè)案例 Pika 1.0 和 Gen-2 表現(xiàn)的都非常不好,男士沒有掏出玫瑰花的動(dòng)作。Boximator 再一次完美理解文本語義并做出了相應(yīng)的動(dòng)作。
往杯子里加紅酒
這個(gè)案例主要展示了控制物體動(dòng)作的能力,Pika 1.0 和 Gen-2 都做出了倒酒的動(dòng)作,但是杯子里的酒沒有明顯上升的動(dòng)作。只有 Boximator 做到了倒酒 + 上升兩個(gè)動(dòng)作。
看了這 3 個(gè)案例,能感受到 Boximator 對(duì)文本語義精準(zhǔn)理解,以及對(duì)動(dòng)作控制的強(qiáng)大功能了吧。
Boximator 模型介紹
為了實(shí)現(xiàn)對(duì)視頻中物體、人物的動(dòng)作控制,Boximator 使用了“軟框”和“硬框”兩種約束方法。
硬框:可精確定義目標(biāo)對(duì)象的邊界框。用戶可以在圖片中畫出感興趣的對(duì)象,Boximator 會(huì)將其視為硬框約束, 在之后的幀中精準(zhǔn)定位該對(duì)象的位置。
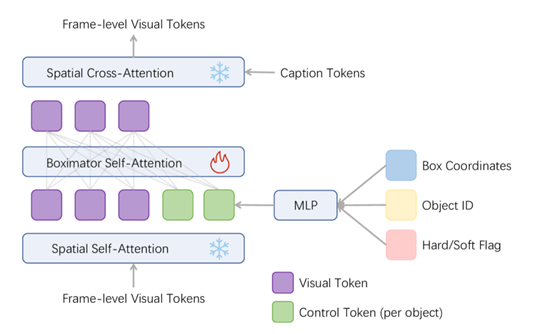
軟框:軟框定義一個(gè)對(duì)象可能存在的區(qū)域, 形成一個(gè)寬松的邊界框。對(duì)象需要停留在這個(gè)區(qū)域內(nèi), 但位置可以有一定變化,實(shí)現(xiàn)適度的隨機(jī)性。
兩類框都包含目標(biāo)對(duì)象的 ID, 用于在不同幀中跟蹤同一對(duì)象。此外, 框還包含坐標(biāo)、類型等信息的編碼。
控制模塊和訓(xùn)練策略
控制模塊可以將框約束的編碼與視頻幀的視覺編碼結(jié)合,用來指導(dǎo)視頻的精準(zhǔn)動(dòng)作生成。包含框編碼器和自注意力層兩大塊。
框編碼器:將框的坐標(biāo)、ID、類型等信息, 通過 Fourier 編碼和 MLP 映射為控制向量。
自注意力層:將框的控制向量與視頻幀的視覺向量通過自注意力建模其關(guān)系, 學(xué)習(xí)將框指導(dǎo)幀生成。
訓(xùn)練策略方面,Boximator 主要分為兩個(gè)階段: 自跟蹤階段,訓(xùn)練模型的同時(shí)生成視頻內(nèi)容和對(duì)應(yīng)的框,并簡(jiǎn)化框與對(duì)象的關(guān)系學(xué)習(xí)。
正常訓(xùn)練,訓(xùn)練模型只生成視頻內(nèi)容, 框的內(nèi)在表達(dá)已經(jīng)學(xué)會(huì)指導(dǎo)對(duì)象生成。此外, 訓(xùn)練還使用多階段策略,逐步過渡從硬框到軟框的約束, 以及適當(dāng)融合無框數(shù)據(jù)。
Boximator 實(shí)驗(yàn)數(shù)據(jù)
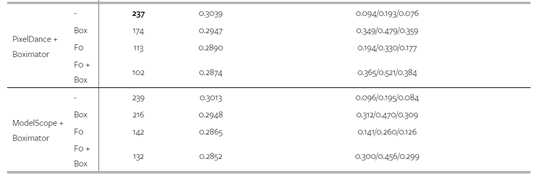
為獲得視頻訓(xùn)練數(shù)據(jù), 研究人員從 WebVid-10M 數(shù)據(jù)集中,過濾出 110 萬段動(dòng)態(tài)明顯的視頻片段, 并自動(dòng)為其注釋了 220 萬個(gè)對(duì)象的邊界框。并在 PixelDance 和 ModelScope 這兩個(gè)模型上訓(xùn)練了 Boximator。
實(shí)驗(yàn)數(shù)據(jù)顯示,Boximator 在保持原模型視頻質(zhì)量, 具有非常強(qiáng)大的動(dòng)作控制能力。同時(shí)可以作為一種插件,幫助現(xiàn)有視頻擴(kuò)散模型提升生成質(zhì)量。
在 MSR-VTT 數(shù)據(jù)集上, 無論是視頻質(zhì)量還是框與對(duì)象對(duì)齊精度方面,Boximator 都優(yōu)于原模型。在人類評(píng)估中,Boximator 生成的視頻也在質(zhì)量和運(yùn)動(dòng)控制上明顯超過原模型。
字節(jié)跳動(dòng)的研究人員表示,目前該模型處于研發(fā)階段,預(yù)計(jì) 2-3 個(gè)月內(nèi)發(fā)布測(cè)試網(wǎng)站。讓我們期待一下國內(nèi)挑戰(zhàn) Sora 的產(chǎn)品誕生吧!
審核編輯:劉清
-
字節(jié)跳動(dòng)
+關(guān)注
關(guān)注
0文章
311瀏覽量
8904 -
Sora
+關(guān)注
關(guān)注
0文章
76瀏覽量
190
原文標(biāo)題:字節(jié)跳動(dòng)推出顛覆性文生視頻模型,可自由控制動(dòng)作!
文章出處:【微信號(hào):AI前線,微信公眾號(hào):AI前線】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論