 深度學習中的不同Normalization方法小結
深度學習中的不同Normalization方法小結
1為什么要 Normalization
在深度神經網絡中,存在一種內部協變偏移(internal covariate shift)現象,它是由于訓練過程中不斷變化的網絡參數導致網絡各層的輸入分布發生變化。
例如,輸入層中某些具有較高數值的特征可能會起到主導作用,從而在網絡中產生偏差,即只有這些特征對訓練結果有貢獻。
例如,假設特征 1 的值介于 1 和 5 之間,特征 2 的值介于 100 和 10000 之間。在訓練期間,由于兩個特征的規模不同,特征 2 將主導網絡,只有該特征對模型作出貢獻。
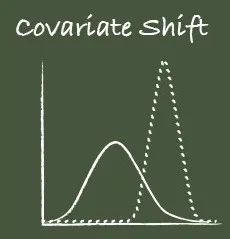
這僅僅是一層的情況,如果從整個深度神經網絡來看,那就更加復雜了。Google 在其論文中將這一現象總結為,
Internal Covariate Shift簡稱 ICS,是由于訓練過程中網絡參數的變化引起的網絡激活分布的變化。
網絡中的每一層的參數更新會導致本層的激活輸出的分布發生變化,也就是后面層的輸入的分布發生變化。而深度神經網絡往往涉及到很多層的疊加,通過層層疊加,會引發后面層非常劇烈的變化,這就給深度模型的訓練帶來了巨大挑戰。
由于上述原因,引入了稱為 normalization 的概念來解決這些問題。
Normalization 有很多優點,包括
減少內部協變偏移以改善訓練;
將每個特征縮放到相似的范圍以防止或減少網絡中的偏差;
通過防止權重在整個地方爆炸并將它們限制在特定范圍內來加速優化過程;
通過輔助正則化減少網絡中的過擬合。
Normalization 也可以結合概率論來解釋。一般來說,機器學習中的方法比較偏愛獨立同分布的數據。當然并不是所有算法都有這個要求,但獨立同分布的數據往往可以簡化一般模型的訓練,提升模型的預測能力。
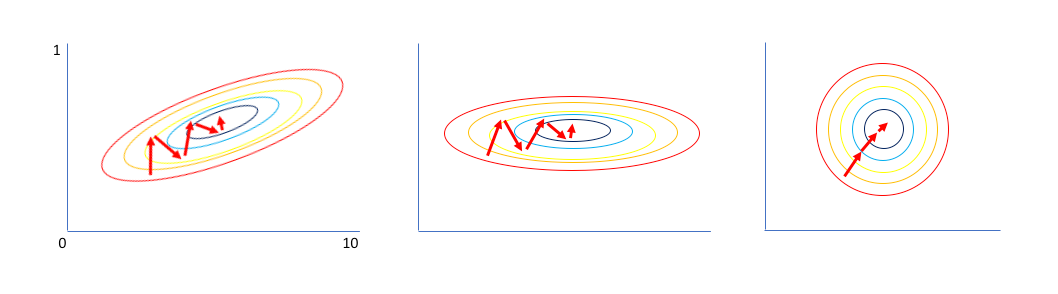
在把數據輸入模型之前,對其經過白化(whitening)處理是一個不錯的預處理步驟。
比如上圖(左)的數據,先經過零均值化以及去相關性操作,得到中間的形式,各個特征相互獨立;再讓所有特征具有單位標準差,最終得到獨立同分布的數據。
但深度學習中往往不直接使用白化操作,白化中間需要用到 PCA。如果對輸入數據作一次 PCA,那也僅僅是針對線性模型,但如果針對神經網絡中的中間每一層在激活后再使用白化,那計算代價太過高昂。
那怎么辦呢?不妨模仿白化,但可以作一些簡化,比如不考慮去相關性,而是對各層的激活輸出在一定范圍內作標準化處理,再加一定的縮放和偏移。這里的操作范圍可以不同,于是就有了一堆 Normalization 方法。
2Batch Normalization
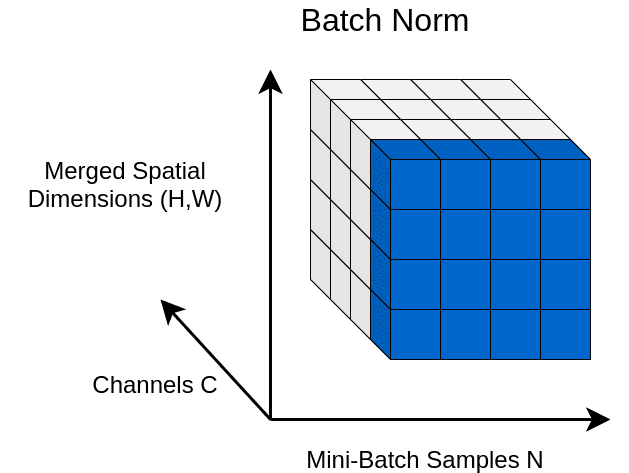
Batch Normalization 側重于標準化任何特定層的輸入(即來自前一層的激活)。
下圖左邊網絡中沒有 BN 層,右邊網絡中在隱藏層前加入了 BN 層,即對輸入層在小批次上作了 Normalization。
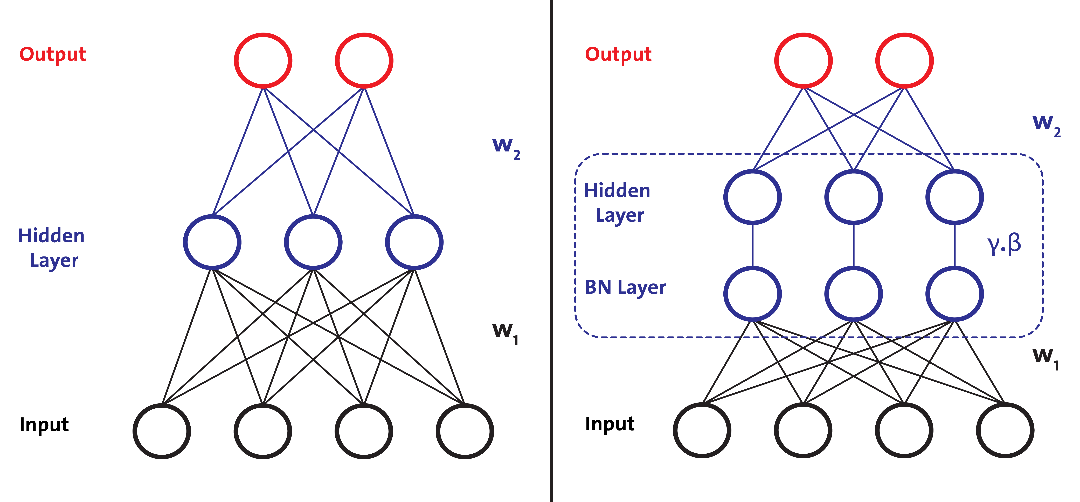
標準化輸入意味著網絡中任何層的輸入都應該近似零均值以及單位方差。簡單來說,BN 層通過減去當前小批量中的輸入均值并除以標準差來變換當前小批量中的每個輸入。

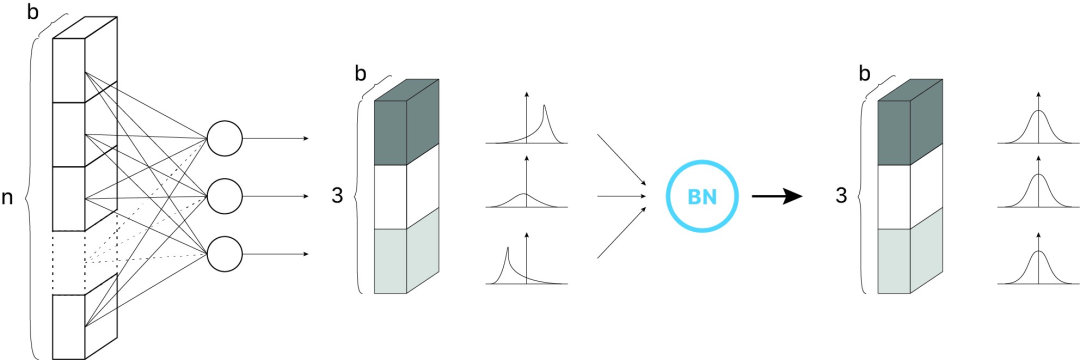
總結一下:簡而言之,BN 使得梯度更具預測性,從而有效改善網絡訓練。
下面,讓我們看看 BN 的一些優點:
BN 加速深度神經網絡的訓練。
對于每個輸入小批量,我們計算不同的統計量,這引入了某種正則化。正則化技術起到在訓練期間限制深度神經網絡復雜度的作用。
每個小批量都有不同的小分布,這些小分布之間的變化稱為內部協變偏移,BN 被認為消除了這種現象。
BN 對通過網絡的梯度流也提供了有利影響:它減少了梯度對參數尺度或其初始值的依賴性,從而使我們能夠使用更高的學習率。
然而,下面是批量標準化的幾個缺點:
BN 在每次訓練迭代中計算批次數據的統計量(Mini-batch 均值和方差),因此在訓練時需要更大的批次大小,以便它可以有效地逼近來自 mini-batch 的總體均值和方差。這使得 BN 更難訓練用于對象檢測、語義分割等應用的網絡,因為它們通常涉及高分辨率(通常高達 1024,2048 等)的輸入數據,使用大批量進行訓練在計算上往往是不可行的。
BN 不適用于 RNN。問題是 RNN 與之前的時間戳具有循環連接,并且在 BN 層中的每個時間步長都需要單獨的 和 ,這反而增加了額外的復雜性并使 BN 與 RNN 一起使用變得更加困難。
不同的訓練和測試計算:在測試(或推理)期間,BN 層不會從測試數據 mini-batch(上面算法表中的步驟 1 和 2)計算均值和方差,而是使用固定均值和從訓練數據計算的方差。這在使用 BN 時需要謹慎,并引入了額外的復雜性。在 pytorch 中,model.eval()確保在評估模型中設置模型,因此 BN 層利用它來使用從訓練數據預先計算的固定均值和方差。
3Weight Normalization
針對 BN 的缺點,Saliman 等人提出了 WN。他們的想法是將權重向量的大小與方向解耦,從而重新參數化網絡以加快訓練速度。
重新參數化是什么意思呢?
WN 加速了類似于 BN 的訓練,與 BN 不同的是,它也適用于 RNN。但是與 BN 相比,使用 WN 訓練深度網絡的穩定性較差,因此在實踐中并未得到廣泛應用。
4Layer Normalization
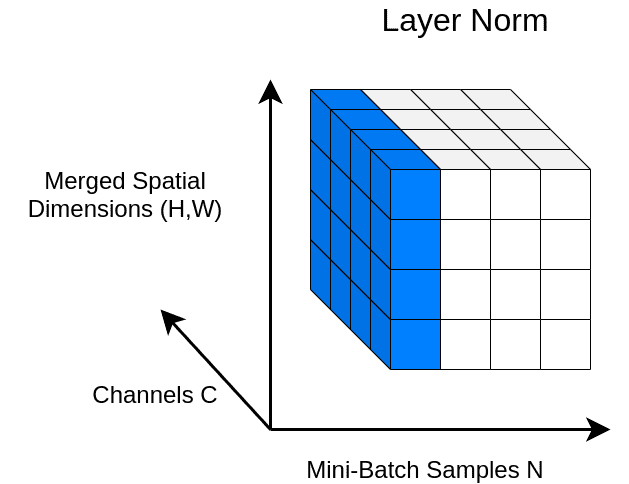
受 BN 的啟發,Hinton 等人提出的 Layer Normalization 沿特征方向而不是小批量方向對激活進行 normalization。這通過消除對批次的依賴來克服 BN 的缺點,也使得 RNN 更容易應用 BN。
與 BN 不同,LN 直接從整個隱藏層的神經元的總輸入估計統計量,因此 normalization 不會在訓練數據之間引入任何新的依賴關系。它適用于 RNN,并提高了幾個現有 RNN 模型的訓練時間和泛化性能。最近,它還與 Transformer 模型一起配合使用。
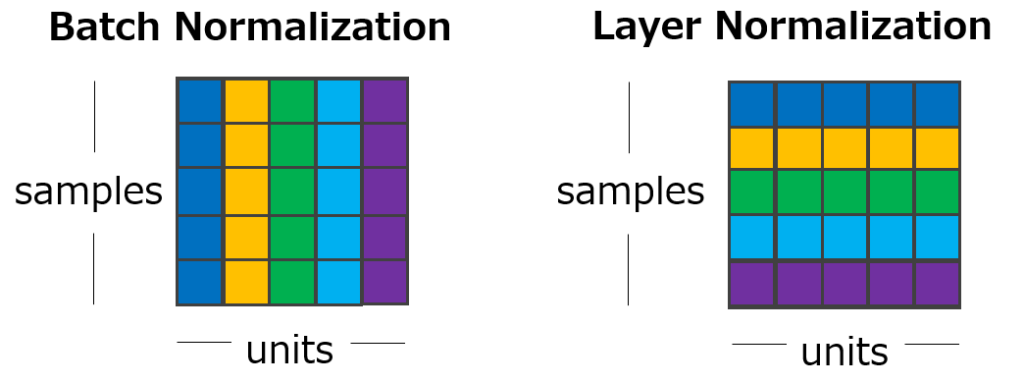
注意上圖中的顏色走向,與 BN 有所不同,LN 對某一個層中所有特征進行歸一化,而不是在小批量中對輸入特征進行歸一化。
5Group Normalization
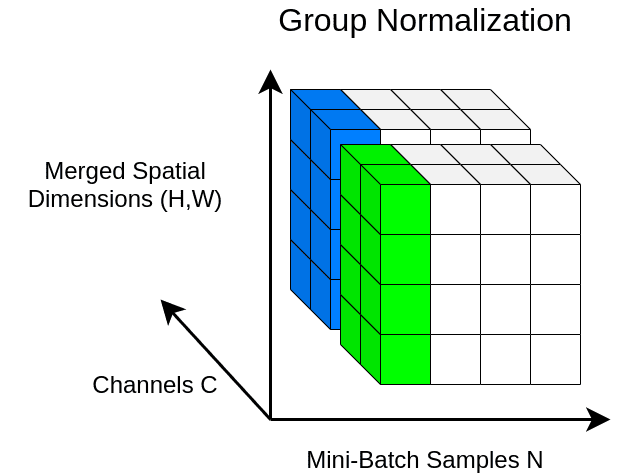
與 LN 類似,GN 也沿特征方向進行操作,但與 LN 不同的是,它將特征劃分為若干組并分別對每個組進行 normalization。在實踐中,GN 比 LN 常常表現得更好,它的參數 num_groups 可以設為超參數。
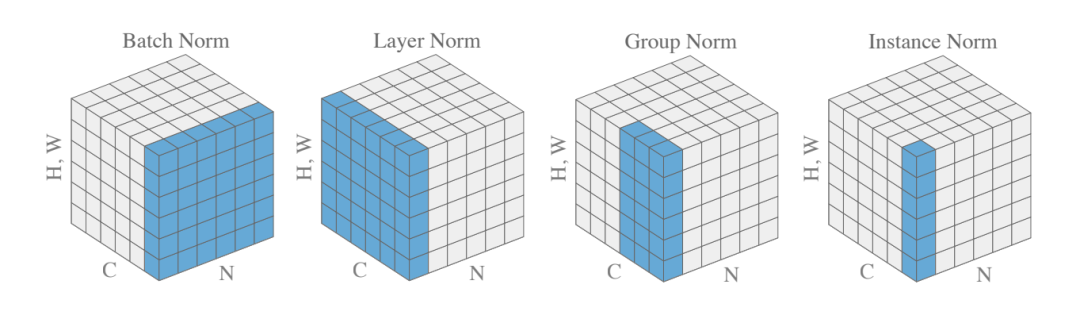
如果覺得 BN、LN、GN 有點令人困惑,下圖給出了一個總結。給定形狀 (N, C, H, W) 的激活,BN 歸一化 N 方向,LN 和 GN 歸一化 C 方向,但 GN 額外地將 C 通道分組并單獨 normalize 各個組。

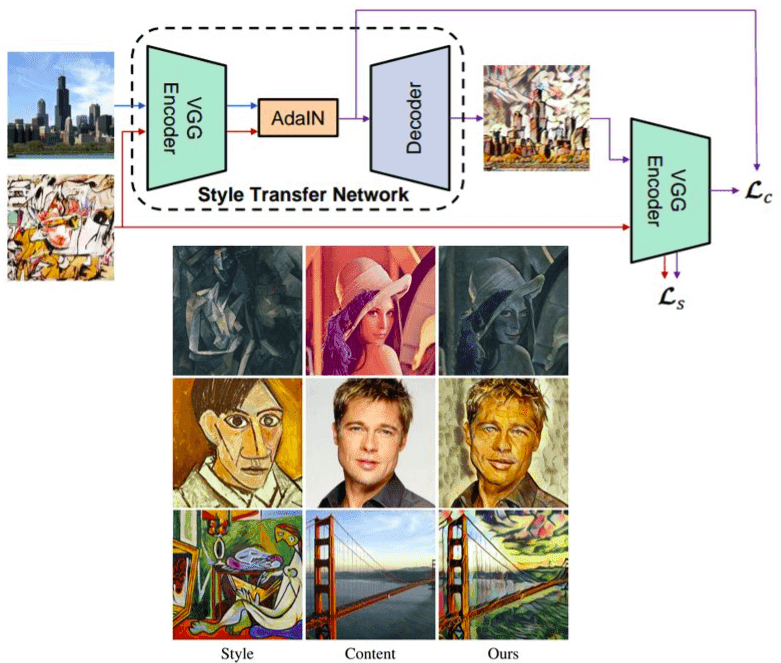
下圖中可以看到一個簡單的編碼器-解碼器網絡架構,帶有額外的 AdaIN 層用于樣式對齊。

其中,
分別計算每個輸出通道的均值和標準差,可以結合下圖來理解。
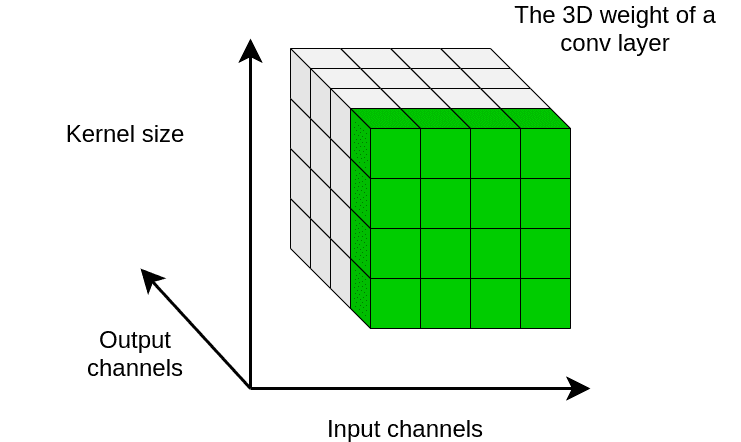
本質上,WS 旨在單獨調控每個輸出通道的權重的一階統計量。通過這種方式,WS 在反向傳播期間對梯度進行 normalization。
從理論上和實驗上都驗證了它通過標準化卷積層中的權重來平滑損失情況。
理論上,WS 減少了損失和梯度的 Lipschitz 常數。核心思想是將卷積權重保持在一個緊湊的空間中,從而平滑了損失并改進了訓練。
論文作者將 WS 與 GN 結合使用,取得了不錯效果。
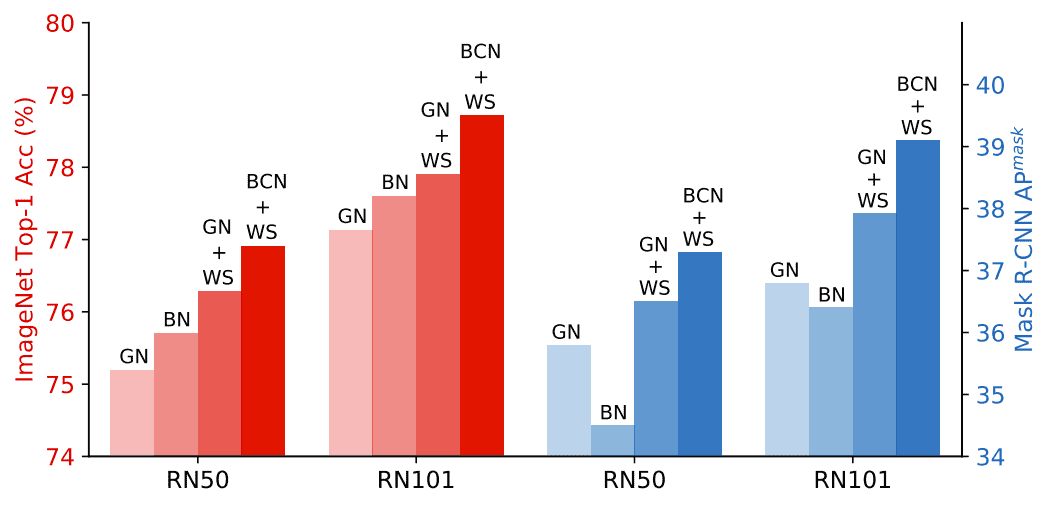
在 ImageNet 和 COCO 上比較normalization方法,GN+WS 大大優于單獨使用 BN 和 GN。
8小結
最后,為了便于比較和分析它們的工作原理,我們將上述幾種主要normalization方法匯聚在一個圖中。
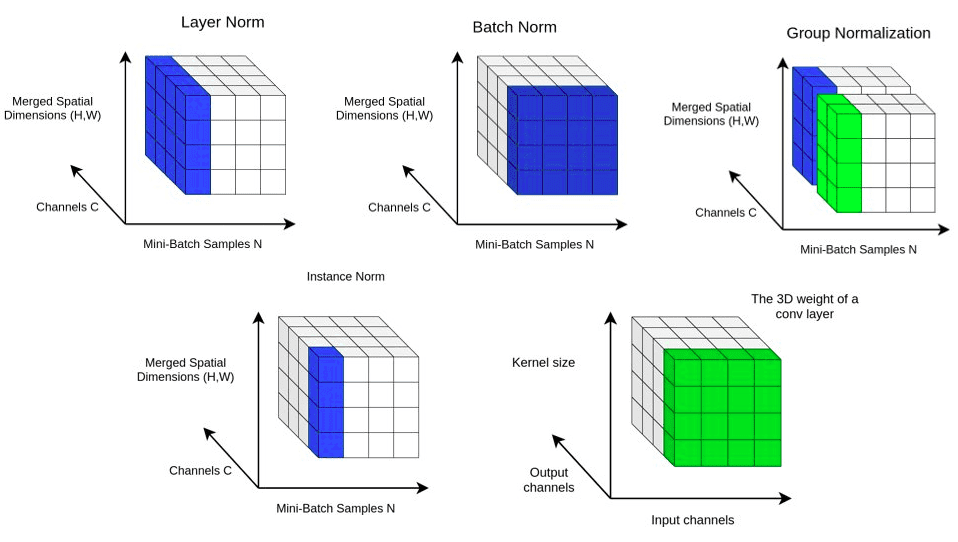
當在論文或具體網絡架構中遇到這些名詞時,腦子中可以浮現出對應的圖來輔助理解。
審核編輯:劉清
-
PCA
+關注
關注
0文章
89瀏覽量
29553 -
機器學習
+關注
關注
66文章
8377瀏覽量
132407 -
深度學習
+關注
關注
73文章
5492瀏覽量
120975 -
深度神經網絡
+關注
關注
0文章
61瀏覽量
4518
原文標題:深度學習各種 Normalization 方法小結
文章出處:【微信號:可靠性雜壇,微信公眾號:可靠性雜壇】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
深度學習在汽車中的應用
基于深度學習的異常檢測的研究方法
深度學習在預測和健康管理中的應用
基于深度學習的異常檢測的研究方法
什么是深度學習?使用FPGA進行深度學習的好處?
batch normalization時的一些缺陷
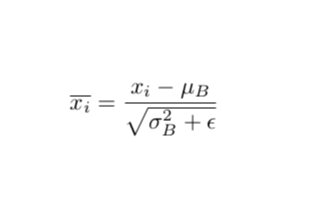
深度學習:搜索和推薦中的深度匹配問題
STM32串口學習小結







 工商網監
工商網監
評論