 AMBA總線之AXI設計的關鍵問題講解
AMBA總線之AXI設計的關鍵問題講解
1、設計AXI接口IP的考慮
1.1、AXI Feature回顧
首先我們看一下針對AXI接口的IP設計,在介紹之前我們先回顧一下AXI所具有的一些feature。
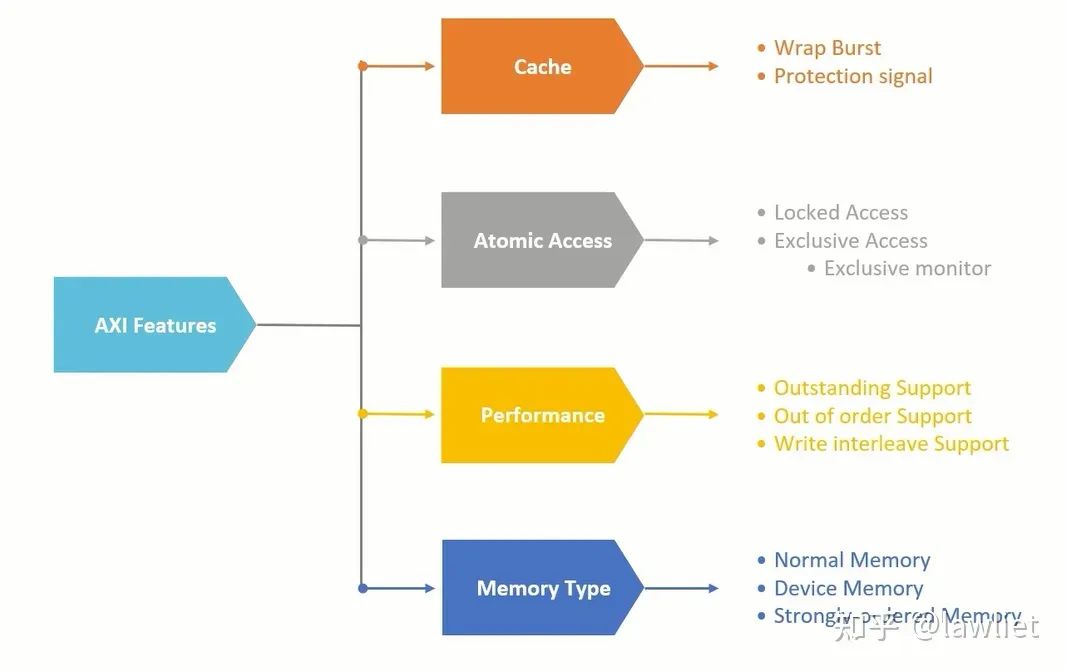
首先是Cache相關的問題,Cache是提高系統Performance的一種很好的方式,AXI通過AxCache信號來決定是否可以訪問Cache,是否可以分配Cache。
然后是原子操作,原子操作我專門花了一篇文章進行講解,大家使用的時候盡量只使用Exclusive Access,Locked Access會阻塞總線,導致帶寬無法充分利用,對系統性能影響較大。其實諸如此類的設計,對性能及吞吐量敏感的地方都應該避免使用,我們稱為阻塞性xxx。為了支持Exclusive Access,我們自然需要Exclusive Monitor,來滿足協議的要求,如何進行設計之前的文章也有提及,不再細說。
然后我們看一下AXI是如何提高性能的,這也是面試比較喜歡問的。如上面的圖所示,主要有三種方式,我稱之為提高AXI性能的三板斧,排名分先后。
Outstanding對性能影響最顯著,尤其是主從之間通訊需要多拍的時候,它充分利用了這段時間發起別的傳輸。其實就是通過這些操作去掩蓋原本的訪存延時。
然后是亂序(Out of Order),這個提高性能主要體現在Slave無法及時響應,就可以讓后發起的請求先完成。就比如你去超市買菜,你前面的人剛好手機沒電了,你是等他充好電還是先讓你付款?
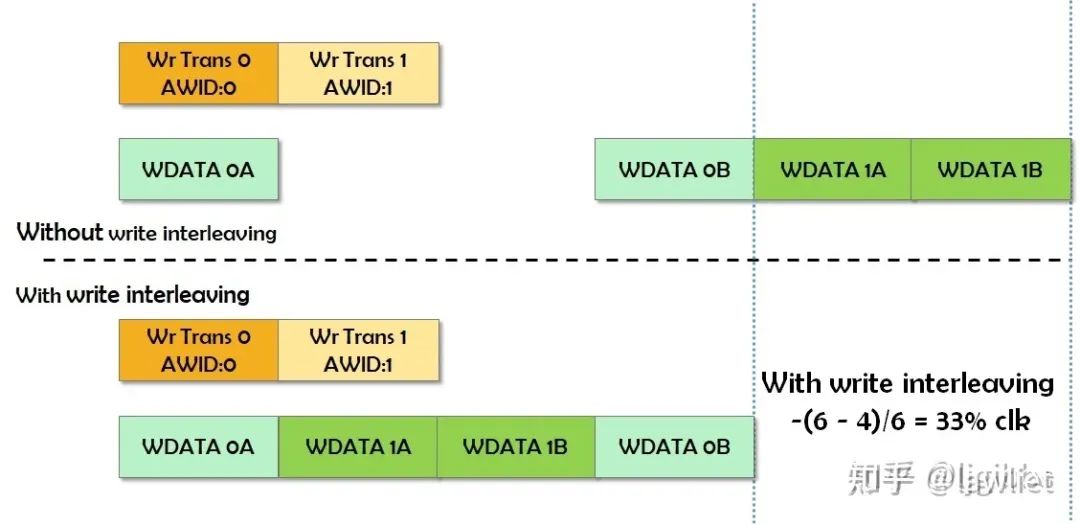
最后是Interleave,即交織讀寫,這個其實就是在空閑的Cycle中(氣泡Cycle)插入讀寫事務,其實有點像亂序,可以理解成更加細粒度的亂序。當然粒度這么細,導致設計很復雜,所以在AXI4中寫交織就被移除了
最后是Memory Type的不同,基于Memory類型的不同,可以決定你的讀寫是否可以Bufferable或者Cacheable。比如某些外設寄存器,你寫完是希望直接改變系統當前的運行狀態的,希望即刻生效,這種當然幾不可以Cacheable也不可以Bufferable。而有些外設寄存器,比如寫Flash Controller的寄存器,你寫完以后,稍微延遲一些Cycle或者有亂序是可以接受的,這種情況就可以Bufferable。

1.2、Ordering consideration
首先我們看一下Write Channel和Read Channel之間的一個Order,AXI協議并沒有對它們之間的Order有一個約束,如果想要實現該機制,就應該在之前的transaction收到最后的response以后才允許發起新的transaction。
你可以通過配置某個寄存器,來開啟該功能。這個設計起來不是很復雜。如果你使用的是ARM或者X86或者主流的商用CPU,你可以使用memory barrier指令來確保這個順序。

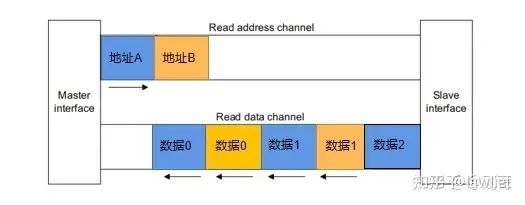
然后我們看一下對于Master而言,對于來自Slave的Response,是可以亂序的,通過ID來區分好就行。此外對于Read response而言,是可以Interleave的。讀交織如下圖所示。
而對于同一ID而言,即Master發出的同一AWID/ARID而言,相應的數據必須是順序的,如果不是順序的,怎么知道哪個數據對應于哪一個地址?
我們看一下Slave的實現,Slave想實現Order Model,比Master要復雜的多。我們想象一下這樣的一個例子,一個Master去訪問一個Slave,而這個Slave有很多不同的Memory Type,比如既有訪問較快的寄存器,也有相對慢一點的SRAM,甚至還有DDR/FLASH。比如你去寫一個DDR Controller,你去寫它的配置寄存器,很快,你去寫DDR,其實也要走這個DDR Controller,這樣一次訪問就非常非常的慢。
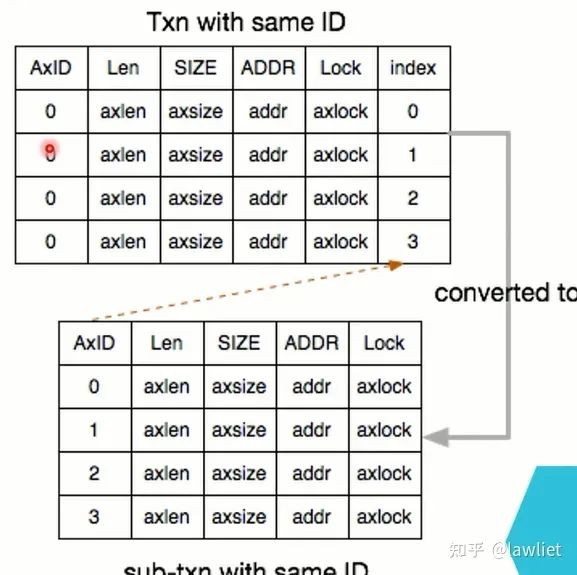
但是,由于是同一個Master的訪問,其ID是相同的,相同ID要保序,那難不成每次寫DDR,都要等著數據回來?顯然非常的不合理,那么在其內部就可以做一個轉換表,如下圖所示,來的時候是同樣的ID,但Slave可以將其轉換成不同的ID,這樣就可以Outstanding了,也可以亂序了,非常的Amazing啊。注意,Slave內部是可以Out of Order返回的,但你返回給Master還是得順序的。需要一塊額外的存儲空間來緩存這些需要返回的數據及相關信息,當來了,你就返回給Master。
我們再看一下Master的實現,當Master有多個Engine,比如DMA。每個DMA發出的ID是不一樣的,當發出多個Outstanding的請求,Slave也相應的根據請求把數據拿回來了。相應的準備若干個Queue,當ID為0的返回的時候送給Queue0,當ID為0的最后一筆返回的時候即RLAST拉高的時候,做相應的處理返回給發出請求的Engine。其實就是需要一定的緩沖機制,來避免接不到數據等情況。
Master需要數據queue來支持out of order;
Master需要buffer來支持outstading;
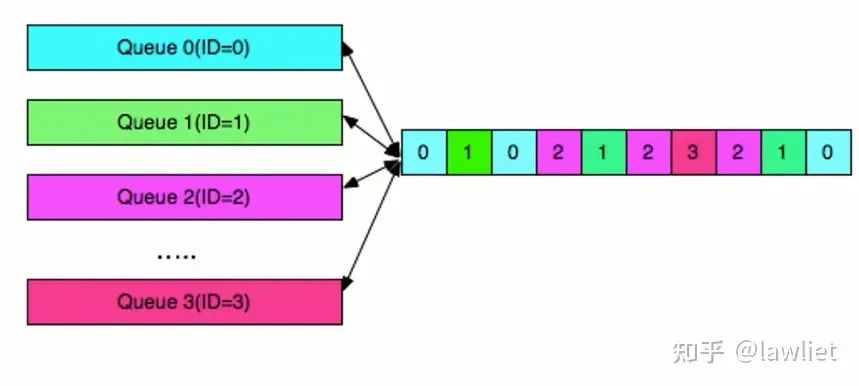
1.3、Debugging
大多數的時候,都認為各自是遵循總線協議的,但還是需要一定的能力,來做Debugging,畢竟某些IP會不遵守協議,會出錯。
使用counter來監視發起了多少次傳輸事務(transaction),以Master那邊為例,當發出一次outstading請求,相應的counter+1,當收到最后的response,counter-1。這樣系統掛死以后,發現某個Master的monitor記錄counter不為0,這樣就可以快速定位錯誤;
axvalid&axready=1,cnt+1
對于寫,當bvalid&bready=1,cnt-1
對于讀,當rvalid&rready&rlast,cnt-1
還可以記錄transfer數量
還可以記錄更多的信息,如axlen、axid、axsize等;
使用timeout機制;
2、Interconnect拓撲結構
假設基于AXI的Master和Slave已經設計好了,如何對它們進行連接呢?當多個Master和Slave進行通信的時候,就需要Interconnect。
Interconnect的拓撲結構多種多樣,基于AXI的Interconnect一般采用Crossbar,如ARM-NIC400,這里我們也只講這種方式。
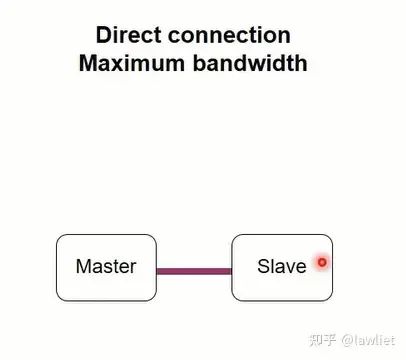
我們看一下基于Crossbar的方式,首先是最簡單的點對點方式,這種情況比較少見,比較典型的如ACP接口,Master需要直接訪問Slave的cache(此時CPU作為Slave,并且是唯一的Slave),這種情況就可以點對點,而不用走多對多的總線。
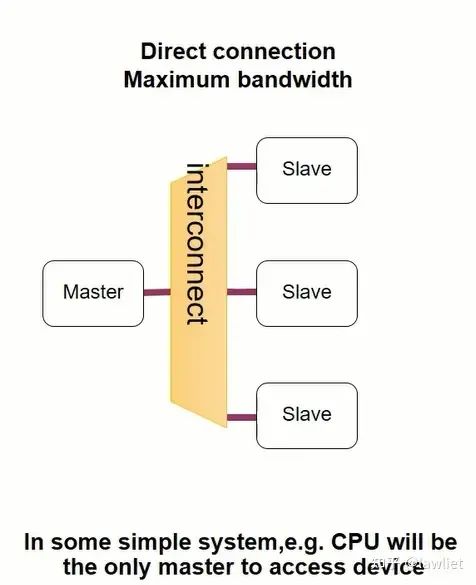
然后是一對多的情況,如下圖所示,這種情況也很常見,比如一個CPU要去訪問多個Slave外設。
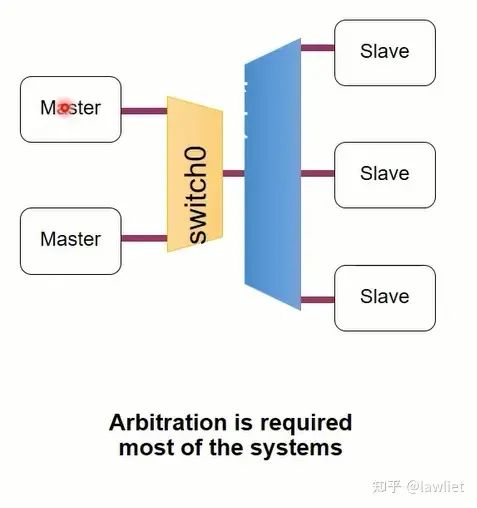
然后是多個Master訪問多個Slave,這種情況就需要引入仲裁邏輯了,相對的設計也會更加復雜,此時多個Master共享Interconnect,相應的會影響到帶寬。
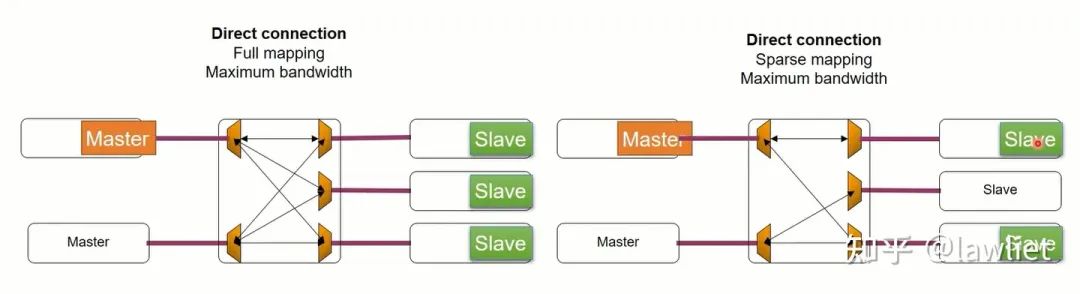
然后我們看一下下面的例子,左邊是完全映射,即Master可以訪問所有的Slave。右圖則是部分映射,可以看到一個Master只能訪問指定的Slave。部分映射可以簡化邏輯設計,節約面積,讓能跑的主頻更高一點。實際上也不需要每個Master都能訪問每個Slave。根據自己的需求來就行。
接下來我們看一下如果想設計一個好的互連,需要滿足以下的特點:
支持多個Master和多個Slave
擴展靈活,可復用性強
時序好,從Interconnect本身去解決timing violation的問題
3、仲裁和時序收斂問題
接下來我們看一下仲裁相關的問題。仲裁本身是個很復雜的問題,這里只簡單介紹。當多個Master需要訪問同一個Slave的時候,這個時候就需要選擇其中的一個。這里講兩種仲裁機制,Least Recently Granted和Round Robin仲裁機制。
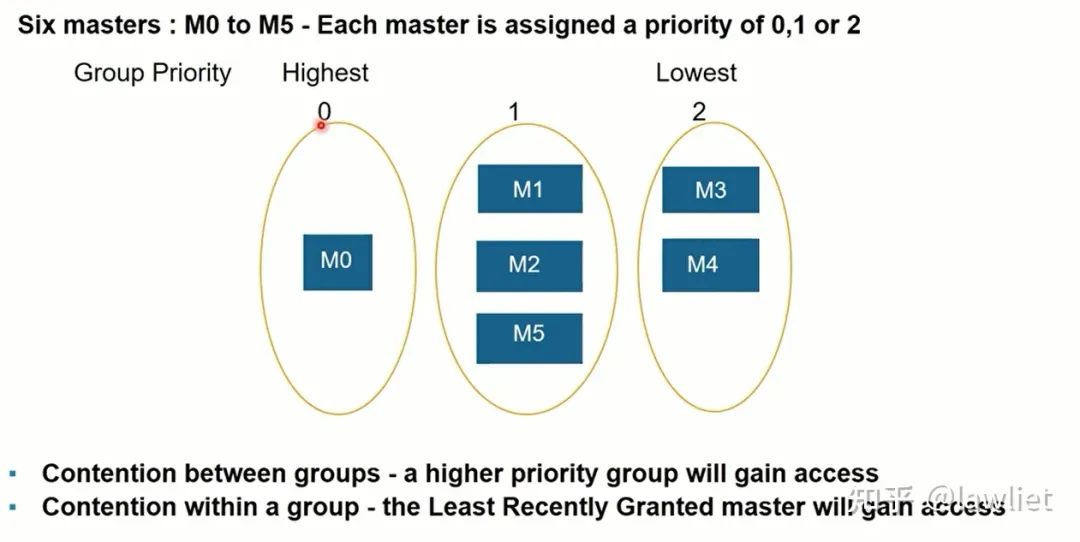
首先看一下Least Recently Granted仲裁:這個和Cache替換中的LRU差不多,我們一開始會分好組,組和組之間是有固定優先級區別的,高優先級的總是會獲得仲裁。對于同一個組的而言,我們會讓最近沒有被授權的Master獲得仲裁權,因此我們需要有一個寄存器去記錄歷史信息,也可以用狀態機實現。
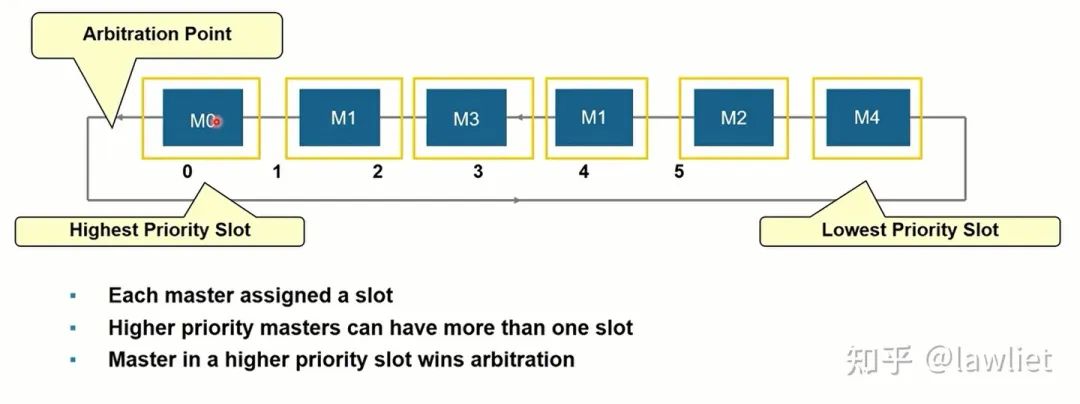
然后是Round Robin仲裁機制,這種仲裁機制下所有的Master的優先級都是相同的,采用輪詢的方式進行仲裁,相應的也要進行記錄歷史信息,以決定如何獲得仲裁。如下圖所示,我們甚至可以用移位寄存器實現,下圖是帶Weight的Round Robin,可以看到M1占據了2個SLOT。因此使用頻率是其它Master的兩倍。
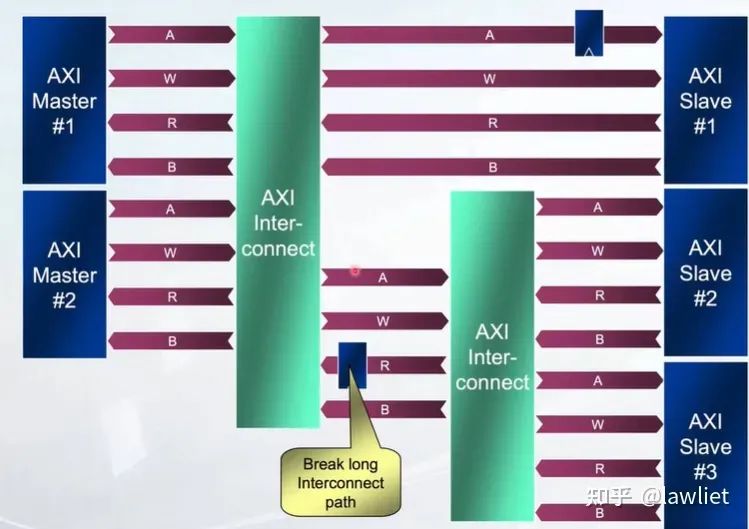
我們再看一下時序如何收斂,因為AXI本身采用握手機制,因此實際上非常靈活,晚了一個周期早了一個周期都無所謂,只要滿足基本的各通道間依賴關系即可。沒有AHB和APB那樣的硬性1T Cycle delay的要求。因此我們可以在critical path上插入寄存器,以優化時序。
一般是有三種方式,打斷Valid,打斷Ready或者都打斷。在IC設計中,無論使用的是否是AXI總線,只要用Valid和Ready握手機制來傳遞數據,都可以使用該方法讓時序收斂,不一定是局限于某個總線協議。大家完全可以將其用在模塊內部和模塊與模塊間的流傳輸。
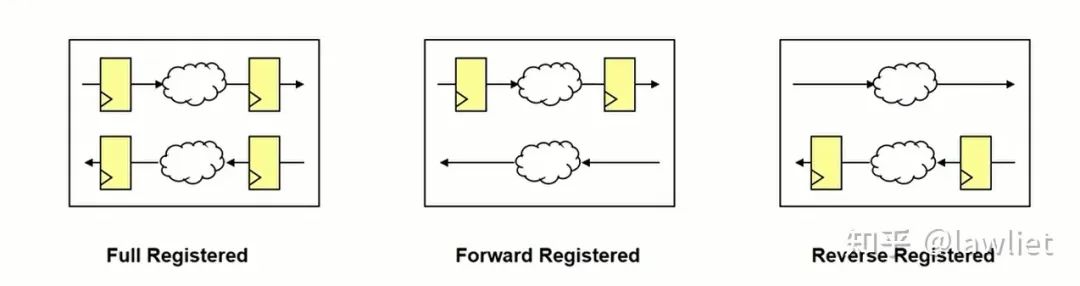
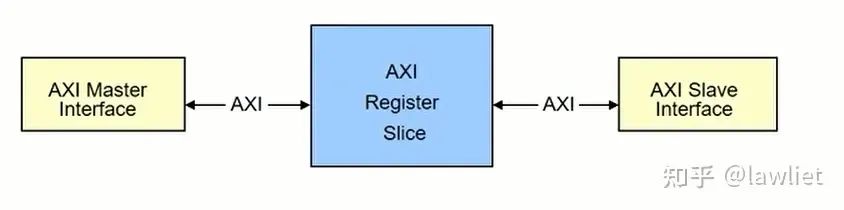
上面這種機制用在總線上,一般稱之為Register Slice。先說說Slice的作用,在SoC中,如果Master和Slave的距離比較遠,那么它們之間的bus信號要滿足timing就可能有點困難,比如AXI中的 ARADDR、ARVALID這些信號從Master出來,要去很遠的Slave,那么中間就要加很多的buffer,這引入的buffer delay就可能導致我們希望的timing不滿足。這個時候就需要插入slice,給每個控制信號在中間加一級寄存器,把較長的走線縮短。當然插入的slice依然要保持bus的協議標準。簡單來說,一個slice就是下面中間的那個模塊。
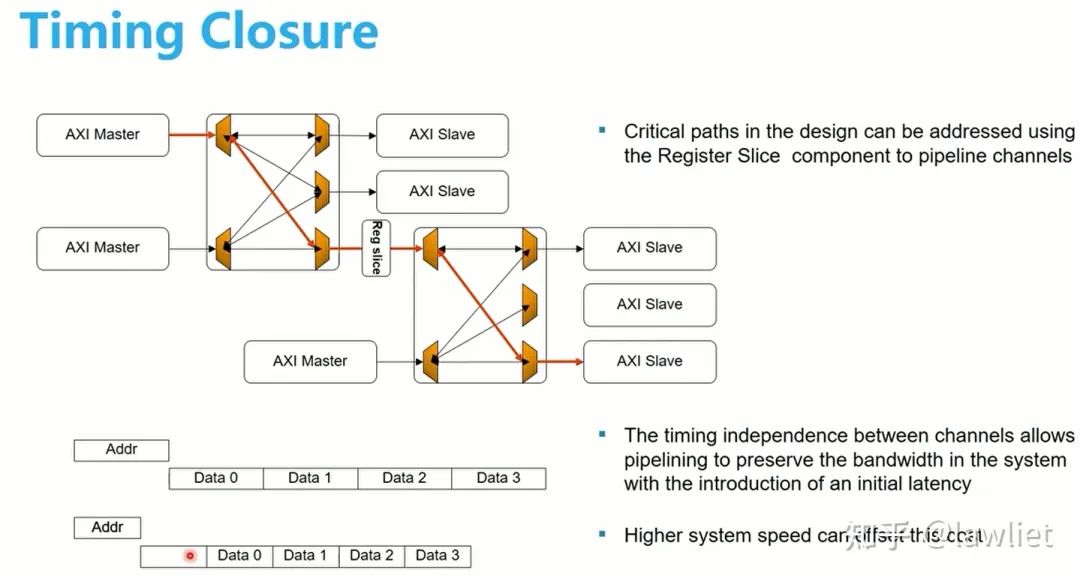
我們看一下在Register插入的位置,可以如下圖所示(其實有很多可以插入的位置)。一般AXI各個通道是分開的,我們在哪個通道加入register slice,相應的就會晚了一拍,實際上晚了一拍完全不影響邏輯功能。
審核編輯:劉清
-
寄存器
+關注
關注
31文章
5317瀏覽量
120002 -
DDR
+關注
關注
11文章
711瀏覽量
65225 -
Cache
+關注
關注
0文章
129瀏覽量
28297 -
ACP
+關注
關注
0文章
5瀏覽量
7825 -
AXI總線
+關注
關注
0文章
66瀏覽量
14250
原文標題:深入理解AMBA總線之AXI設計的關鍵問題
文章出處:【微信號:Rocker-IC,微信公眾號:路科驗證】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
AMBA總線概述
學習架構-AMBA AXI簡介
AMBA3.0 AXI總線接口協議的研究與應用
AXI 總線交互分為 Master / Slave 兩端
AMBA3.0 AXI總線接口協議的研究與應用
AMBA 3.0 AXI總線接口協議的研究與應用
基于AMBA總線介紹?
深度解讀AMBA、AHB、APB、AXI總線介紹及對比
Xilinx FPGA AXI4總線(一)介紹【AXI4】【AXI4-Lite】【AXI-Stream】

AXI IIC總線接口介紹
漫談AMBA總線-AXI4協議的基本介紹





 工商網監
工商網監
評論