 gprofng如何幫助我們深入研究Java應用程序的動態行為?
gprofng如何幫助我們深入研究Java應用程序的動態行為?
首先,編寫一個矩陣乘法程序(matrix multiplication program)。我寫了一個完整的矩陣乘法程序,這比矩陣向量乘法(matrix-times-vector)要簡單。主要有三種操作:
1
計算最內層乘加操作(the inner-most multiply-add)
2
將乘加操作合并為結果中的單個元素
3
對最終結果的每個元素進行迭代計算
我將矩陣乘法的計算過程放入一個簡單的框架中,以便能夠重復地計算矩陣乘積,從而確保測量是可多次重復的(見附注 1)。該程序會在每次矩陣相乘開始時(相對于 Java 虛擬機的啟動時間)打印出信息,包括每次矩陣相乘所需的時間。我還運行了一個測試,將兩個 8000x8000 的矩陣相乘,該框架會重復計算 11 次,并為了使后續不同行為的特征更突出,在每次重復之間設置休眠 920 毫秒:
$ numactl --cpunodebind=0 --membind=0 -- java -XX:+UseParallelGC -Xms31g -Xmx31g -Xlog:gc -XX:-UsePerfData MxV -m 8000 -n 8000 -r 11 -s 920
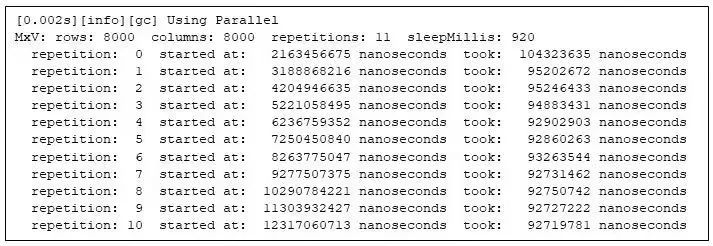
圖 1:矩陣乘法程序的運行情況
第二次重復運行的用時是第一次的 92%;到最后一次重復運行時,用時僅為第一次的 89%。執行時間的變化證明了Java 程序需要一段預熱的時間。
那么問題來了:能否用 gprofng 來分析第一次與最后一次重復運行之間的差異,從而促進性能提升?
為了回答這個問題,我們可以運行程序并讓 gprofng 收集有關運行的信息。方法非常簡單,只需在命令行中添加 gprofng 命令前綴,即可收集 gprofng 稱之為 “experiment” 的信息。
$ numactl --cpunodebind=0 --membind=0 --
gprofng collect app
java -XX:+UseParallelGC -Xms31g -Xmx31g -Xlog:gc --XX:-UsePerfData
MxV -m 8000 -n 8000 -r 11 -s 920
圖 2:在 gprofng 下運行矩陣乘法程序
首先需要注意的是,與其它 profiling 工具一樣,gprofng 在收集 profiling 信息時也會為應用程序帶來開銷(overhead),好消息是,與不加 profiling 信息運行相比,gprofng 所帶來的開銷看起來并不顯著。
隨后,可以通過 gprofng 深入了解整個應用程序的時間消耗情況(見附注 2)。對于整個運行過程,gprofng 顯示了24 個最耗時的函數調用,具體如下:
$ gprofng display text test.1.er -viewmode expert -limit 24 -functions
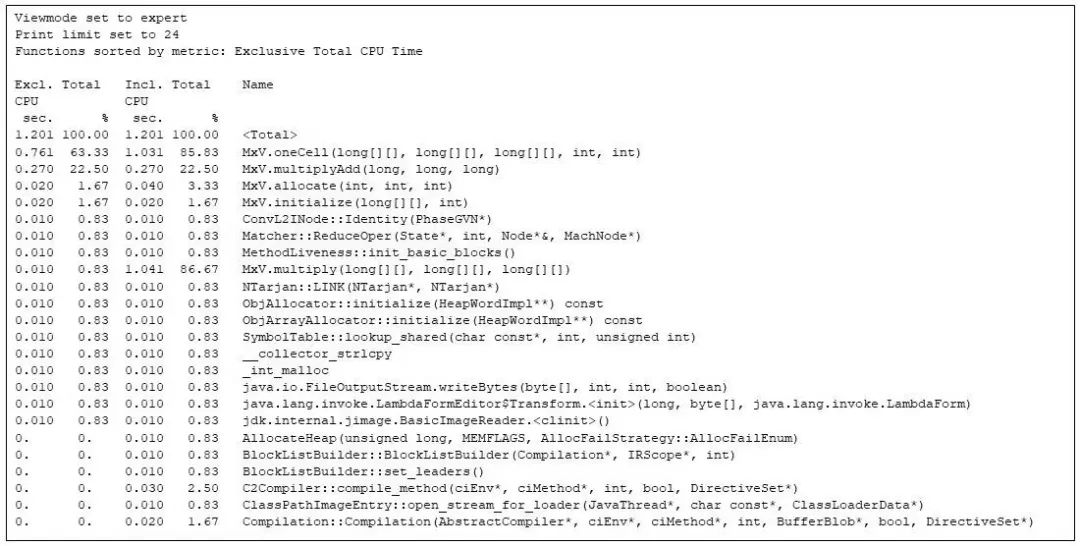
圖 3:Gprofng 展示了 24 個最耗時的函數調用
上面的函數視圖展示了每種方法的獨占 CPU 時間和總體 CPU 時間,均以秒為單位,并以總 CPU 時間的百分比表示。被命名的的函數是由 gprofng 生成的偽函數(pseudo function),其值為各種指標的總和。從數據中可以看出,整個應用程序消耗的總 CPU 時間為 1.201 秒。
其中,應用程序中屬于 Matrix times Vector(MxV)類的方法占用了大部分 CPU 時間,但除此之外還有其它方法,如 JVM 的運行時編譯器(Compilation::Compilation)和不屬于矩陣乘法的其他函數。此外,圖表在展示整體程序執行情況的同時,還捕捉到了分配(MxV.allocate)和初始化(MxV.initialize)的代碼。不過,我對這些代碼不太感興趣,因為它們是測試框架的一部分,僅在啟動期間使用,與矩陣乘法本身關聯不大。
gprofng 可以讓我專注在感興趣的應用程序部分上。它有一個奇妙之處是,在收集實驗之后,我可以使用過濾器來處理收集到的數據。例如,查看在特定時間間隔內發生了什么,或者查看特定方法在調用棧(call stack)上的情況。為了演示和方便進行過濾,我在程序中添加了 Thread.sleep(ms)的策略性調用,這樣可以更容易地基于相隔一秒的程序階段編寫過濾器。這就是為什么在圖 1 的程序輸出中,即使每個矩陣相乘只花費約 0.1 秒,但每次重復之間仍相隔約 1 秒的原因。
gprofng 支持編寫腳本。我用它編寫了一個腳本,用于從 gprofng 實驗中提取不同秒數的數據。第一秒主要與 Java 虛擬機的啟動相關:
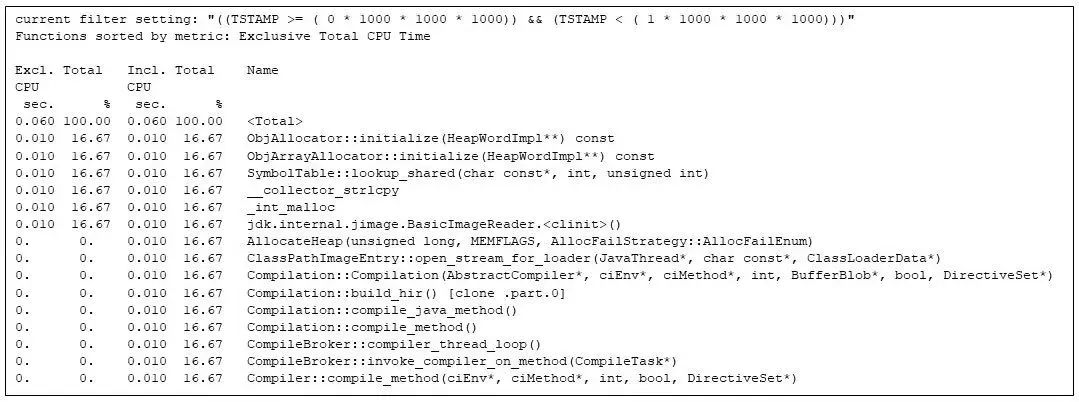
圖 4:篩選出第 1 秒內最耗時的函數調用。為了能夠清楚地展示 JVM 的啟動過程,我特意在矩陣乘法上制造了一些延遲。
即使應用程序中的所有函數調用都尚未開始運行,運行時編譯器(例如 Compilation::compile_java_method,占用了約 16% 的 CPU 時間)就已經啟動。(由于我插入了 sleep 調用,矩陣乘法調用被延遲了。)
第 1 秒之后,第 2 秒主要是分配函數和初始化函數的運行,以及各種 JVM 函數的執行。但此時,矩陣乘法的任何代碼都尚未開始執行:
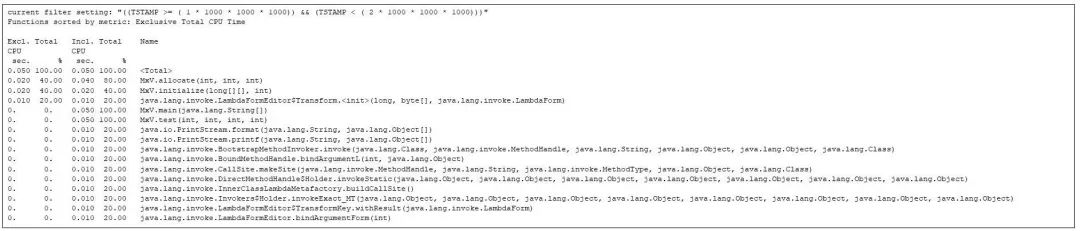
圖 5:展示了第 2 秒內最耗時的函數。矩陣的分配和初始化與 JVM 的啟動互相競爭。
此時 JVM 啟動以及數組的分配和初始化已完成。如圖 6 所示,第 3 秒是矩陣乘法代碼的第一次重復。但請注意,矩陣乘法代碼正在與 Java 運行時編譯器爭奪機器資源(例如,圖 6 中的CompileBroker::invoke_compiler_on_method 占比 8%),這是由于矩陣乘法代碼耗時較多,這時仍在進行編譯。
即便如此,矩陣乘法代碼(例如,在 MxV.main 方法中的“包含”時間占比 91%)占用了大部分 CPU 時間。包含時間顯示矩陣乘法(如 MxV.multiply)需要 0.100 CPU 秒,這與圖 2 中應用程序報告的墻上時鐘一致。(收集和報告墻上時鐘需要一定的時間,但這不包括 gprofng 計算 MxV.multiply 方法所占用的 CPU 時間)。
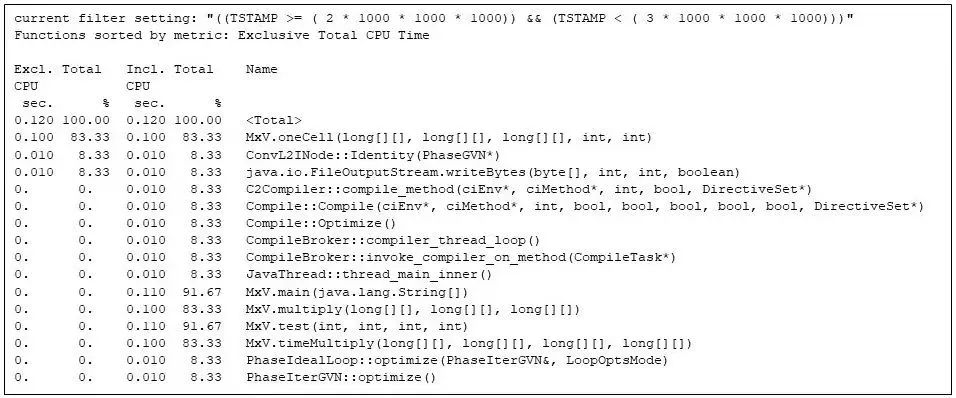
圖 6:第 3 秒內最耗時的函數,顯示了運行時編譯器與矩陣乘法方法之間的資源競爭。
在這個特定的示例中,矩陣乘法實際上并沒有參與爭奪 CPU 時間,因為測試是在具有大量空閑周期的多處理器系統上運行,而運行時編譯器則作為單獨的線程運行。在某些特定的、受到限制的情況下,例如在負載較重的共享機器上,運行時編譯器占用 8% 的時間可能會對整體性能造成影響。但另一方面,在運行時編譯器上花費時間會使得方法能夠更高效地執行,因此,如果要計算多個矩陣乘法,我比較傾向于采取這種方法。
到第 5 秒時,矩陣乘法代碼就獨占了 Java 虛擬機的執行時間:
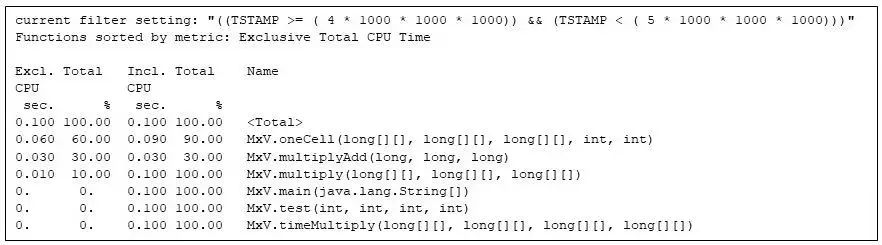
圖 7:在第 5 秒內運行的所有函數,只有矩陣乘法函數是活躍的。
請注意,MxV.oneCell、MxV.multiplyAdd 和 MxV.multiply 之間獨占 CPU 秒數的占比分別為60%、30% 和 10%。MxV.multiplyAdd 方法僅計算乘法和加法,但它是矩陣乘法中最內層的方法。MxV.oneCell 方法有一個調用 MxV.multiplyAdd 的循環,循環的開銷和調用(評估條件和控制轉移)比 MxV.multiplyAdd 中的直接算術更加繁重(這種差異反映在兩者的獨占時間中,MxV.oneCell 為 0.060 CPU 秒,而 MxV.multiplyAdd 為 0.030 CPU 秒)。MxV.multiply 中的外層循環執行頻率不夠高,以至于運行時編譯器尚未對其進行編譯,但該方法僅用了 0.010 CPU 秒。
矩陣乘法持續進行到第 9 秒,此時 JVM 運行時編譯器再次啟動,我們發現 MxV.multiply 已頻繁執行,占用了較多的執行時間:
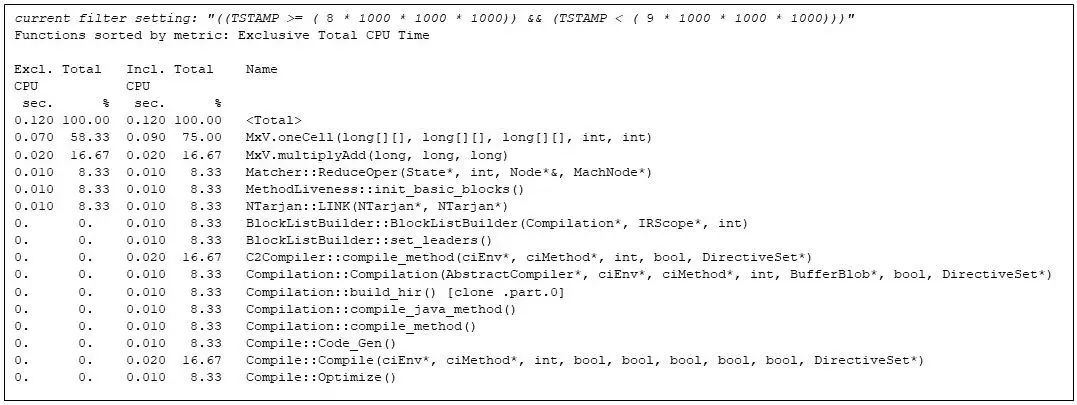
圖 8:第 9 秒內最耗時的函數,顯示運行時編譯器已再次啟動。
到最后一次重復之前,矩陣乘法代碼完全占用了Java 虛擬機的執行資源:
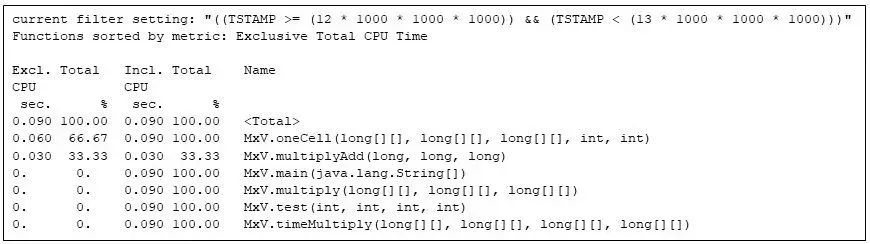
圖 9:矩陣相乘程序的最后一次重復,展示了代碼在整個程序執行結束時的最終配置。
結 論
我通過對運行時的 Java 程序使用 gprong 進行深入分析了解到了它的易用性。利用 gprofng 的過濾功能,我可以進行時間片段檢查實驗,從而專注于自己感興趣的程序階段。例如,通過排除應用程序的分配和初始化階段,并在運行時編譯器工作時僅顯示一次程序重復,我能夠清晰地觀察到熱代碼在編譯過程中性能不斷提升的情況。
附注
①程序命令行的各個組成部分的原因解釋:
(1) numactl --cpunodebind=0 --membind=0 --
將 Java 虛擬機使用的內存限制為一個 NUMA 節點的內核和內存。將 JVM 限制在一個節點,可以減少程序在運行過程中的變化,使程序在運行中的表現更加穩定。
(2) java
所使用的是適用于 aarch64 架構的 OpenJDK 版本 jdk-17.0.4.1。
(3)-XX:+UseParallelGC
啟用并行垃圾回收器(parallel garbage collector),它在所有可用回收器中執行的后臺工作最少。
(4)-Xms31g -Xmx31g
提供足夠的 Java 對象內存溢出(heap space),以確保不需要進行垃圾回收。
(5)-Xlog:gc
記錄 GC 活動,以核實確實不需要進行收集。(正如那句名言所說:“信任是必須的,但核實也是必要的。”)
(6)-XX:-UsePerfData
降低 Java 虛擬機的開銷。
②gprofng 選項的原因:
(1) limit 24
僅顯示占用 CPU 時間最多的 24 個函數(并按獨占 CPU 時間進行排序)。這使我能夠了解哪些函數幾乎不花費時間,從而集中關注那些在程序執行期間占用最多 CPU 時間的函數。后續,我還將在某些情況下使用 limit 16,以便掌握哪些函數占用極少 CPU 時間。有時 gprofng 工具本身也可能限制顯示的數量,因為并不是所有的函數都能累計出大量的時間。
(2) viewmode expert
顯示所有累計 CPU 時間的函數,而不僅僅是 Java 函數,還包括 JVM 本身固有的函數,使用此標記可以讓我查看運行時編譯器函數等。
審核編輯:劉清
-
多處理器
+關注
關注
0文章
22瀏覽量
8913 -
JAVA
+關注
關注
19文章
2960瀏覽量
104563 -
JVM
+關注
關注
0文章
157瀏覽量
12210 -
虛擬機
+關注
關注
1文章
908瀏覽量
28109
原文標題:技術文章 | Java 虛擬機的一天
文章出處:【微信號:AmpereComputing,微信公眾號:安晟培半導體】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
[分享]超級經典的JAVA基礎視頻推薦,還有很多牛人寫的學習感受!值得深入研究
【Landzo C1試用體驗】+第六篇 超聲波之深入研究
使用Eclipse WTP開發Java Web應用程序
深入研究USBType-C技術的細節
深入研究徹底掌握設備樹
你能用任何測試代碼或其他步驟來幫助我測試我的應用程序軟件嗎?
java小應用,java小應用程序下載
模式匹配算法的深入研究
深入研究Servlet線程安全性問題
如何用Java代碼來創建iOS和Android應用程序
1.6設備樹的引進與體驗——只想使用設備樹不想深入研究怎么辦






 工商網監
工商網監
評論