") Redis流與Kafka相比如何?
Redis流與Kafka相比如何?
Redis流 VS Kafka
Kafka以解決大規(guī)模數(shù)據(jù)處理問題而聞名,并被廣泛部署在許多知名公司的基礎(chǔ)設(shè)施中。早在2015年,LinkedIn有60個(gè)集群,總共有1100個(gè)Broker,每秒處理1300萬條信息。
但事實(shí)證明,規(guī)模并不是Kafka唯一擅長的事情。它所提倡的編程范式--分區(qū)、有序、事件處理--對(duì)于你可能面臨的許多問題都是一個(gè)很好的解決方案。例如,如果事件代表的是要被索引到搜索數(shù)據(jù)庫的行,那么最后的修改就是最后的索引,這一點(diǎn)很重要,否則搜索將無限期地返回陳舊的數(shù)據(jù)。同樣,如果事件代表用戶行為,處理第二個(gè)事件("用戶升級(jí)賬戶")可能依賴于第一個(gè)("用戶創(chuàng)建賬戶")。這種范式與傳統(tǒng)的作業(yè)隊(duì)列系統(tǒng)不同,在傳統(tǒng)的作業(yè)隊(duì)列中,事件是由許多工作者同時(shí)從隊(duì)列中彈出的,這很簡(jiǎn)單,可擴(kuò)展,但它破壞了任何排序保證。假設(shè)你想要有序的處理,但也許你不想使用Kafka,因?yàn)樗且粋€(gè)難以操作或昂貴的重型系統(tǒng)的聲譽(yù)。Redis現(xiàn)在有了5.0版本發(fā)布的"流 "數(shù)據(jù)結(jié)構(gòu),與之相比如何?它是否解決了同樣的問題?
Kafka的架構(gòu)
我們先來看看Kafka的基本架構(gòu)。基本的數(shù)據(jù)結(jié)構(gòu)是主題。它是一個(gè)按時(shí)間排序的記錄序列,只需追加。使用這種數(shù)據(jù)結(jié)構(gòu)的好處在Jay Kreps的經(jīng)典博文The Log中得到了很好的描述。
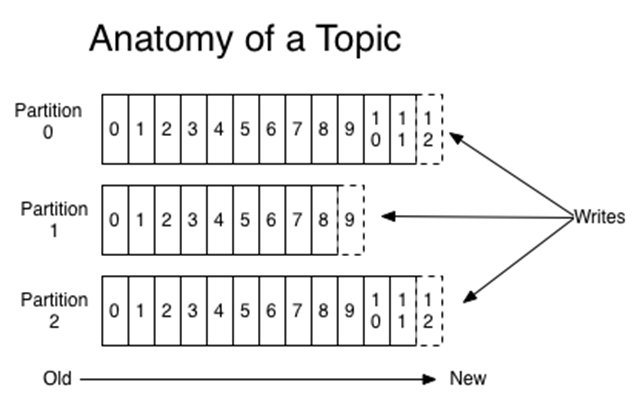
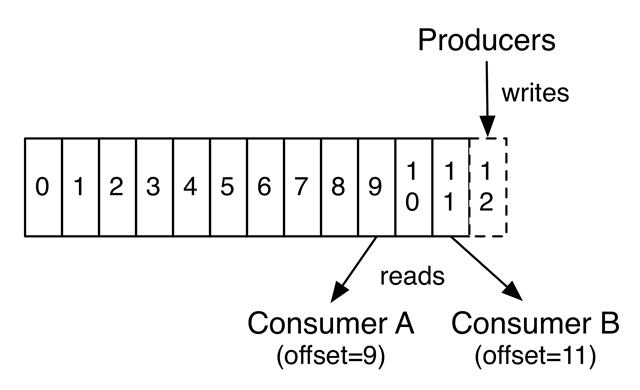
主題Topic被分區(qū),以使它們能夠擴(kuò)展:每個(gè)主題可以被托管在單獨(dú)的Kafka實(shí)例上。每個(gè)分區(qū)中的記錄都被分配了連續(xù)的ID,稱為偏移量,它可以唯一地識(shí)別分區(qū)中的每個(gè)記錄。消費(fèi)者按順序處理記錄,保持跟蹤其最后看到的偏移量。由于記錄被持久化在一個(gè)主題中,多個(gè)消費(fèi)者可以相互獨(dú)立地處理記錄。
在實(shí)踐中,你可能會(huì)將你的處理分布在許多機(jī)器上。為了實(shí)現(xiàn)這一點(diǎn),Kafka提供了一個(gè) "消費(fèi)者組 "的抽象,它是一組合作的進(jìn)程,從一個(gè)主題消費(fèi)數(shù)據(jù)。一個(gè)主題的分區(qū)被劃分給組內(nèi)的成員。然后,當(dāng)成員加入或離開該組時(shí),必須重新分配分區(qū),以便每個(gè)成員都能獲得公平的分區(qū)份額。這就是所謂的再平衡算法。
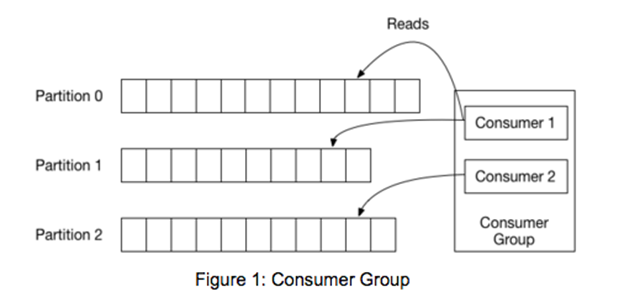
請(qǐng)注意,一個(gè)分區(qū)只能由消費(fèi)者組的一個(gè)成員來處理。(但一個(gè)成員可能負(fù)責(zé)多個(gè)分區(qū))這使得嚴(yán)格有序的處理得到保證。
這套工具是非常有用的。你可以通過添加更多的工作者來輕松地?cái)U(kuò)展你的處理,而Kafka則負(fù)責(zé)處理分布式協(xié)調(diào)問題。
Redis的流數(shù)據(jù)結(jié)構(gòu)
Redis的 "流 "數(shù)據(jù)結(jié)構(gòu)是如何比較的?Redis流在概念上等同于上面描述的Kafka主題的一個(gè)分區(qū),但有一些小的區(qū)別。
它是一個(gè)持久的、有序的事件存儲(chǔ)(與Kafka中相同)
它有一個(gè)可配置的最大長度(與Kafka中的保留期相比)。
事件存儲(chǔ)鍵和值,就像Redis Hash(相對(duì)于Kafka中的單個(gè)鍵和值)。
最主要的區(qū)別是,Redis中的消費(fèi)者組與Kafka中的消費(fèi)者組完全不同。
在Redis中,一個(gè)消費(fèi)者組是一組全部從同一流讀取的進(jìn)程。Redis確保事件只會(huì)被傳遞給組內(nèi)的一個(gè)消費(fèi)者。例如,在下圖中,消費(fèi)者1不會(huì)處理'9',它會(huì)跳過它,因?yàn)橄M(fèi)者2已經(jīng)看到它了。消費(fèi)者1將得到下一個(gè)未被任何其他組成員看到的事件。
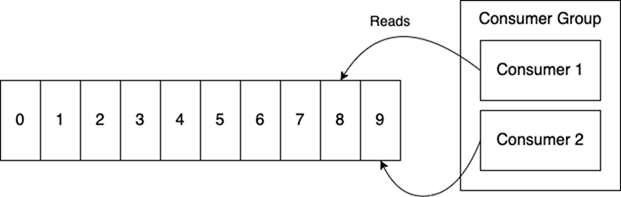
組的作用是將單個(gè)流的處理并行化。這看起來很像一個(gè)傳統(tǒng)的作業(yè)隊(duì)列結(jié)構(gòu)。因此,它失去了作為流處理核心的排序保證,這是很不幸的。
流處理作為一個(gè)客戶端庫
那么,如果Redis只提供有效的具有作業(yè)隊(duì)列語義的主題的單一分區(qū),我們?cè)趺茨茉赗edis之上建立一個(gè)流處理引擎?好吧,如果你想要Kafka的功能,你需要自己構(gòu)建它們。這意味著要實(shí)現(xiàn)。
1. 事件分區(qū)。你需要?jiǎng)?chuàng)建N個(gè)流,并將每個(gè)流視為一個(gè)分區(qū)。然后,在發(fā)送時(shí),你需要決定哪個(gè)分區(qū)應(yīng)該接收它,大概是基于事件的哈希值或其中的一個(gè)字段。
2. 一個(gè)工人分區(qū)分配系統(tǒng)。為了擴(kuò)展和支持多個(gè)工作者,你需要?jiǎng)?chuàng)建一個(gè)算法,在他們之間分配分區(qū),確保每個(gè)工作者擁有一個(gè)相互排斥的子集,也就是相當(dāng)于Kafka的 "再平衡 "系統(tǒng)。
3. 有確認(rèn)的順序處理。每個(gè)工作者都需要迭代其每個(gè)分區(qū),跟蹤其偏移量。盡管Redis消費(fèi)者組有作業(yè)隊(duì)列語義,但它們?cè)谶@里可以提供幫助。訣竅是每個(gè)組使用一個(gè)消費(fèi)者,然后為每個(gè)分區(qū)創(chuàng)建一個(gè)組。然后每個(gè)分區(qū)將被按順序處理,你可以利用內(nèi)置的消費(fèi)者組狀態(tài)跟蹤。Redis不僅可以跟蹤偏移量,還可以跟蹤每個(gè)事件的確認(rèn),這是很強(qiáng)大的。
這是絕對(duì)的最低要求。如果你希望你的解決方案是健壯的,你可能還想考慮錯(cuò)誤處理:除了崩潰你的工作者,也許你會(huì)想要一個(gè)機(jī)制,將錯(cuò)誤轉(zhuǎn)發(fā)到一個(gè) "死信 "流并繼續(xù)處理。
好消息是--如果你喜歡Python的話--已經(jīng)解決了這些問題,并且在一個(gè)新發(fā)布的名為Runnel的庫中解決了更多問題。如果你想從Redis上類似Kafka的語義中獲益,歡迎你來看看。下面是它的外觀,基本上與上面的Kafka圖之一相同。
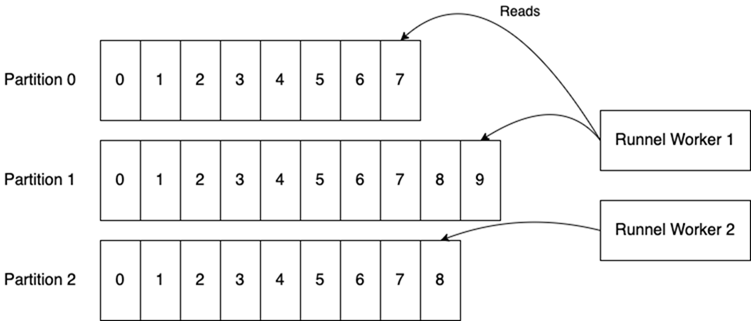
工作者通過Redis中實(shí)現(xiàn)的鎖來協(xié)調(diào)他們對(duì)分區(qū)的所有權(quán)。他們通過一個(gè)特殊的 "控制 "流相互溝通。更多信息,包括架構(gòu)和再平衡算法的詳細(xì)分解,請(qǐng)參閱Runnel文檔。
權(quán)衡
Redis是大規(guī)模事件處理的好選擇嗎?有一個(gè)基本的權(quán)衡:因?yàn)橐磺卸荚趦?nèi)存中,獲得了無與倫比的處理速度,但它不適合存儲(chǔ)無限制的數(shù)據(jù)量。使用Kafka,你可能愿意無限期地保存你的所有事件,但使用Redis,你肯定要存儲(chǔ)最近的事件的固定窗口--只夠你的處理器有一個(gè)舒適的緩沖區(qū),以防止它們變慢或崩潰。這意味著你可能還想使用一個(gè)外部的長期事件存儲(chǔ),例如S3,以便能夠重放它們,這增加了你的架構(gòu)的復(fù)雜性,但降低了成本。
研究這個(gè)問題的主要?jiǎng)訖C(jī)是在部署和操作Redis時(shí)涉及的易用性和低成本。這就是為什么它對(duì)Kafka有吸引力。它也是一套神奇的工具,經(jīng)受住了時(shí)間的考驗(yàn),非常了不起。事實(shí)證明,經(jīng)過努力,它也可以支持分布式流處理范式.
審核編輯:黃飛
-
Redis
+關(guān)注
關(guān)注
0文章
371瀏覽量
10846 -
kafka
+關(guān)注
關(guān)注
0文章
50瀏覽量
5211
原文標(biāo)題:Redis流對(duì)比Kafka
文章出處:【微信號(hào):magedu-Linux,微信公眾號(hào):馬哥Linux運(yùn)維】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
Redis Stream應(yīng)用案例
Kafka集群環(huán)境的搭建
一文讀懂什么是分布式流處理系統(tǒng)Kafka
Kafka的概念及Kafka的宕機(jī)
Kafka的核心概念
什么是Redis?各種Redis部署及其權(quán)衡取舍
什么是 Redis
Kafka 的簡(jiǎn)介
物通博聯(lián)5G-kafka工業(yè)網(wǎng)關(guān)實(shí)現(xiàn)kafka協(xié)議對(duì)接到云平臺(tái)
Kafka架構(gòu)技術(shù):Kafka的架構(gòu)和客戶端API設(shè)計(jì)
如何將Kafka使用到我們的后端設(shè)計(jì)中





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論