 基于Transformer模型的壓縮方法
基于Transformer模型的壓縮方法
0. 這篇文章干了啥?
基于Transformer的模型已經成為各個領域的主流選擇,包括自然語言處理(NLP)和計算機視覺(CV)領域。大部分擁有數十億參數的大型模型都基于Transformer架構,但其異常龐大的規模給實際開發帶來了挑戰。例如,GPT-3模型有1750億個參數,需要約350GB的存儲空間(float16)。參數的數量龐大以及相關的計算開銷要求設備具有極高的存儲和計算能力。直接部署這樣的模型會產生巨大的資源成本,特別是在手機這樣的邊緣設備上的模型部署變得不切實際。
模型壓縮是減少Transformer模型開發成本的有效策略,包括修剪、量化、知識蒸餾、高效架構設計等各種類別。網絡修剪直接刪除冗余組件,如塊、注意力頭、FFN層或個別參數。通過采用不同的修剪粒度和修剪標準,可以派生出不同的子模型。量化通過用較低位表示模型權重和中間特征來減少開發成本。例如,當將一個全精度模型(float32)量化為8位整數時,存儲成本可以減少四分之一。根據計算過程,可以分為后訓練量化(PTQ)或量化感知訓練(QAT),其中前者只產生有限的訓練成本,對于大型模型更有效。知識蒸餾作為一種訓練策略,將知識從大模型(教師)轉移到較小模型(學生)。學生通過模擬模型的輸出和中間特征來模仿教師的行為。還可以直接降低注意力模塊或FFN模塊的計算復雜性來產生高效的架構。
因此,這篇文章全面調查了如何壓縮Transformer模型,并根據量化、知識蒸餾、修剪、高效架構設計等對方法進行分類。在每個類別中,分別研究了NLP和CV領域的壓縮方法。
下面一起來閱讀一下這項工作~
作者:Yehui Tang, Yunhe Wang, Jianyuan Guo, Zhijun Tu, Kai Han, Hailin Hu, Dacheng Tao
2. 摘要
基于Transformer架構的大型模型在人工智能領域中發揮著日益重要的作用,特別是在自然語言處理(NLP)和計算機視覺(CV)領域。模型壓縮方法降低了它們的內存和計算成本,這是在實際設備上實現Transformer模型的必要步驟。鑒于Transformer的獨特架構,具有替代注意力和前饋神經網絡(FFN)模塊,需要特定的壓縮技術。這些壓縮方法的效率也至關重要,因為通常不現實在整個訓練數據集上重新訓練大型模型。這項調查全面審查了最近的壓縮方法,重點關注它們在Transformer模型中的應用。壓縮方法主要分為剪枝、量化、知識蒸餾和高效架構設計。在每個類別中,我們討論了CV和NLP任務的壓縮方法,突出了共同的基本原理。最后,我們深入探討了各種壓縮方法之間的關系,并討論了該領域的進一步發展方向。
3. 壓縮方法總結
Transformer模型的代表性壓縮方法總結。
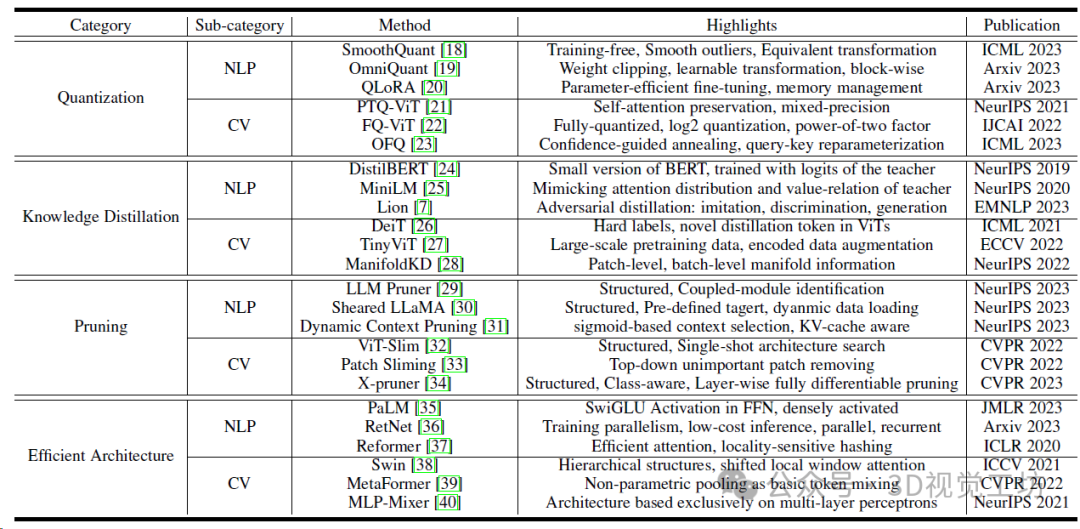
基于Transformer的視覺模型的不同PTQ(Post-training quantization)和QAT(Quantization-aware training)方法的比較。W/A表示權重和激活度的位寬,結果顯示在ImageNet-1k驗證集上的精確度最高。*代表混合精度。
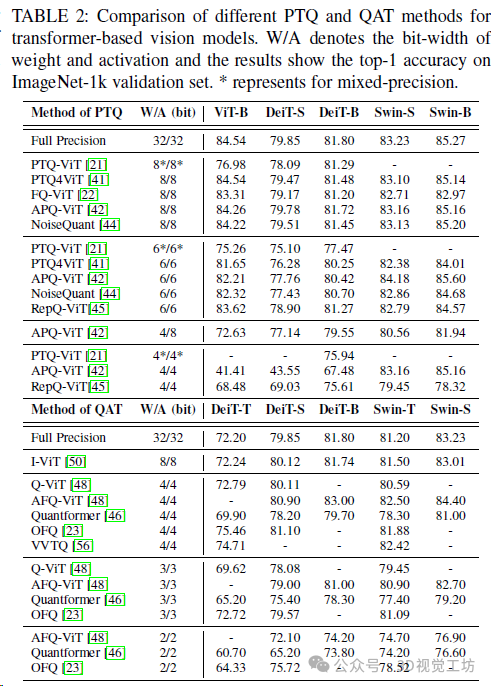
4. 模型量化
量化(Quantization)是在各種設備上部署 Transformer 的關鍵步驟,特別是在為低精度算術設計專用電路的 GPU和 NPU 上。在量化過程中,浮點張量被轉換為具有相應量化參數(比例因子 s和零點 z)的整數張量,然后整數張量可以被量化回浮點數,但與原始相比會導致一定的精度誤差。
Transformer量化總結。頂部展示了計算機視覺和自然語言處理現有作品中解決的不同問題,底部顯示了標準transformer塊的正常INT8推理過程。
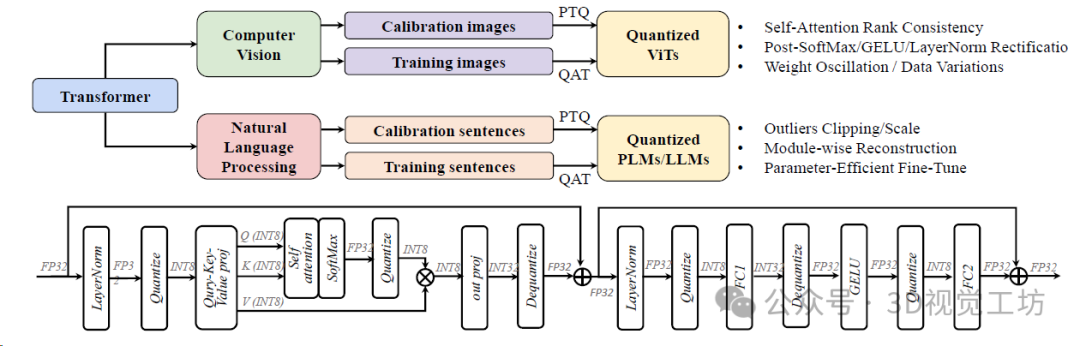
在NVIDIA A100-80GB GPU上使用Faster Transformer時ViT和OPT的推理延遲。
5. 知識蒸餾
知識蒸餾(Knowledge distillation,KD)旨在通過從教師網絡中蒸餾或傳遞知識來訓練學生網絡。這篇文章主要關注的蒸餾方法是:實現緊湊學生模型的,同時與繁重的教師模型相比保持令人滿意的性能。學生模型通常具有較窄且較淺的架構,使它們更適合部署在資源有限的系統上。并主要介紹基于 logits 的方法(在 logits 級別傳遞知識)以及基于 hint 的方法(通過中間特征傳遞知識)。
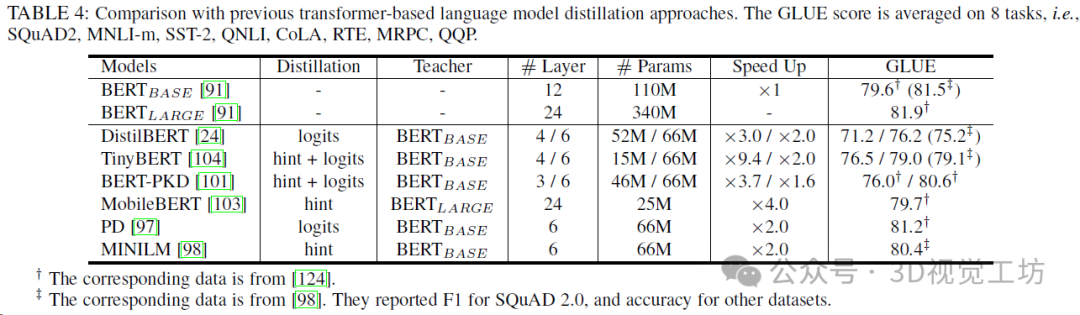
用于大型Transformer模型的知識蒸餾分類。
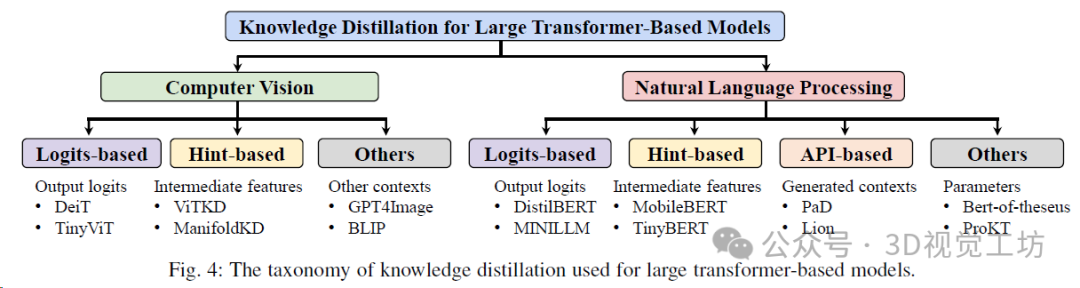
與以前基于transformer的語言模型蒸餾方法的比較,GLUE得分是8個任務的平均值。
6. 模型剪枝
模型剪枝包括修剪和模型訓練的順序,結構規范以及確定修剪參數的方式。下面總結了Transformer模型剪枝方法的分類。
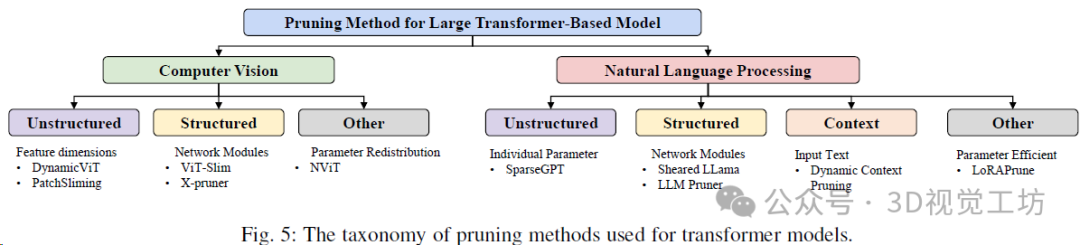
視覺轉換庫典型剪枝方法的比較。
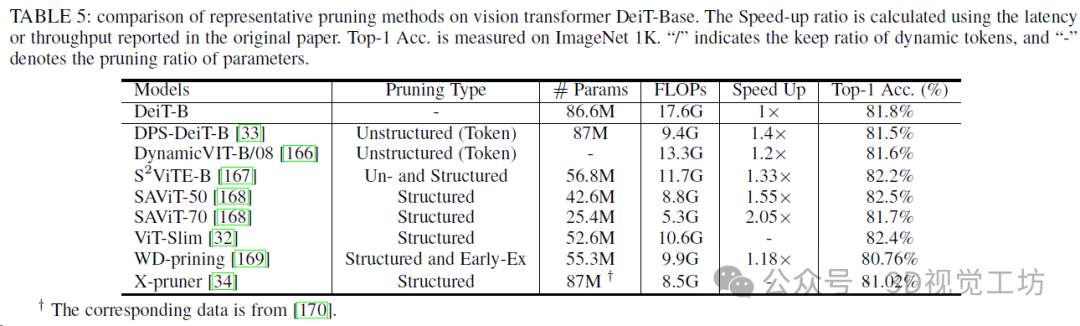
大型語言Transformer上典型剪枝方法的比較。
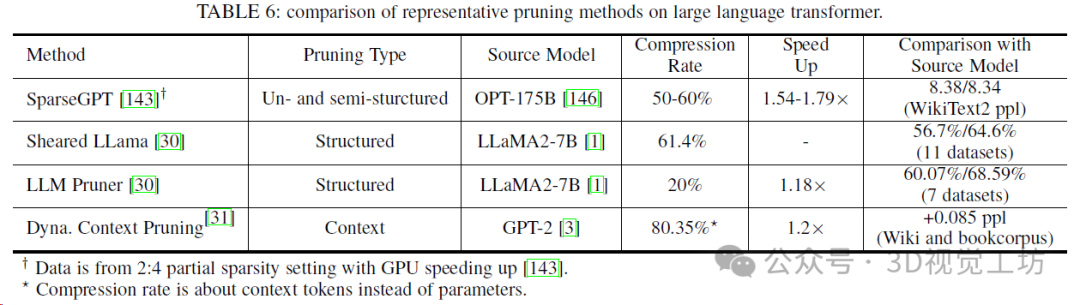
幾種具有代表性的基于Transformer的LLM和LVM的模型卡,帶有公開的配置詳細信息。
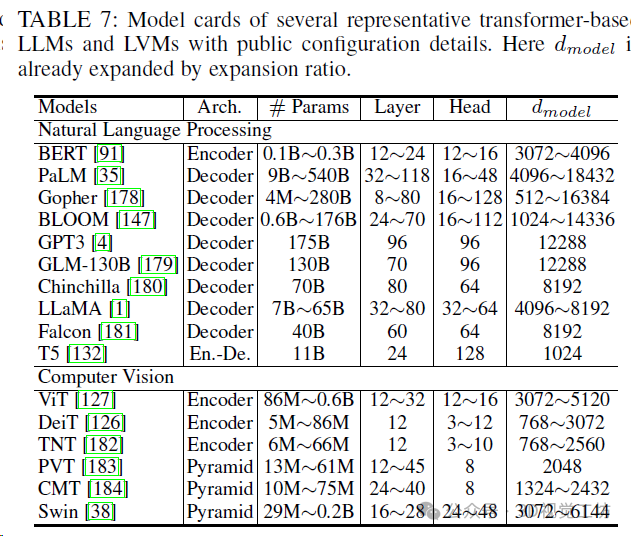
從訓練并行化(TP)、推理成本(時間)和內存復雜性(內存)進行模型比較。N和d分別表示序列長度和特征維數。
7. 其他壓縮方法
除了量化、蒸餾、修剪和新穎的網絡架構之外,還有幾種其他模型壓縮和加速方法。
張量分解。 張量或矩陣分解旨在將大張量或矩陣分解為較小的張量或矩陣,以節省參數數量和計算成本。這種方法首先被引入到全連接層和卷積網絡的壓縮中。至于大型語言模型,張量分解被用于簡化模型的權重或嵌入層。
早期退出。 早期退出可以動態為每個輸入樣本分配不同的資源并保持原始性能,這在信息檢索系統和卷積網絡中已經成功使用。許多早期退出技術已被提出用于僅編碼器的變壓器。早期退出的關鍵問題是確定何時退出。現有的作品主要利用內在的置信度度量、提前路由或訓練一個早期退出分類器。
猜測采樣。 猜測采樣是一種特殊的Transformer解碼加速方法,通過并行計算幾個令牌來進行。在大型語言模型中,解碼K個令牌需要模型的K次運行,這是緩慢的。利用從較小模型生成的參考令牌,猜測采樣并行運行這些令牌可以顯著加快解碼過程。此外,拒絕方案可以保持原始LLM的分布,從而理論上實現猜測采樣的無損。
8. 總結 & 未來趨勢
這篇綜述系統地調查了Transformer模型的壓縮方法。與其他架構(如CNN或RNN)不同,Transformer具有獨特的架構設計,具有替代注意力和FFN模塊,因此需要專門定制的壓縮方法以獲得最佳的壓縮率。此外,對于這些大型模型,壓縮方法的效率變得特別關鍵。某些模型壓縮技術需要大量的計算資源,這可能對這些龐大的模型來說是不可行的。本調查旨在涵蓋與Transformer相關的大部分最近的工作,并闡述其壓縮的全面路線圖。隨后,深入探討了各種方法之間的相互關系,解決了后期挑戰,并概述了未來研究的方向。
不同壓縮方法之間的關系。 不同的壓縮方法可以一起使用,以獲得極其高效的架構。常見的順序是首先定義一個具有高效操作的新架構。然后刪除多余的組件(例如注意力頭、層),以獲得一個較小的模型。對于實際硬件實現,將權重或激活量量化為較低的位數是必不可少的。所需位數的選擇不僅取決于誤差的容忍度,還取決于硬件設計。例如,
訓練高效的壓縮策略。 與壓縮傳統模型不同,對壓縮方法的計算成本的重視程度增加了。目前,大型Transformer正在使用大量的計算資源在龐大的數據集上進行訓練。例如,Llama2在數千個GPU上訓練了2萬億個令牌,持續了幾個月。在預訓練期間使用相當的計算資源進行微調是不切實際的,特別是當原始數據通常是不可訪問的。因此,訓練后的高效壓縮方法的可行性變得更加可行。然而,對于較低的位數(例如4位),量化模型仍然會遭受顯著的性能降低。值得注意的是,極低位模型,例如二進制Transformer,在傳統的小型模型中已經得到了廣泛的探索,但在大型模型的背景下仍然相對未知。
對于修剪來說, 后期訓練的挑戰與修剪粒度緊密相關。盡管非結構化的稀疏性可以在最小微調要求下實現高壓縮率,但類似的策略難以轉移到結構性修剪中。直接刪除整個注意力頭或層將導致模型架構的重大改變和因此準確性的顯著降低。如何識別有效權重以及如何有效地恢復性能都是洞察力方向。識別有效權重和恢復表示能力的有效策略是解決這些挑戰的關鍵研究方向。
超越Transformer的高效架構。 在現實世界的應用中,Transformer架構的輸入上下文可以延伸到極長的長度,包括NLP中的序列文本(例如,一本擁有數十萬字的書)或CV中的高分辨率圖像。基礎注意力機制對輸入序列長度的復雜度呈二次復雜度,對于長序列輸入構成了重大的計算挑戰。許多研究通過減少注意力的計算成本來解決這個問題,采用了稀疏注意力、局部注意力等技術。然而,這些注意力壓縮策略通常會損害表示能力,導致性能下降。
新興的架構, 如RWKV和RetNet采用了類似于RNN的遞歸輸出生成,有效地將計算復雜度降低到O(N)。這一發展有望在探索更高效模型的過程中進一步發展。對于計算機視覺任務,即使是沒有注意力模塊的純MLP架構也可以實現SOTA性能。過仔細研究它們的效率、泛化性和擴展能力,探索新的高效架構是有希望的。
審核編輯:黃飛
-
變壓器
+關注
關注
159文章
7328瀏覽量
134886 -
編碼器
+關注
關注
45文章
3595瀏覽量
134161 -
gpu
+關注
關注
28文章
4701瀏覽量
128707 -
人工智能
+關注
關注
1791文章
46859瀏覽量
237580 -
自然語言處理
+關注
關注
1文章
612瀏覽量
13506
原文標題:GPU不夠用?網絡不夠快?一文看懂Transformer壓縮技巧!
文章出處:【微信號:3D視覺工坊,微信公眾號:3D視覺工坊】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
大語言模型背后的Transformer,與CNN和RNN有何不同

【大語言模型:原理與工程實踐】大語言模型的基礎技術
詳解ABBYY PDF Transformer+從文件創建PDF文檔
你了解在單GPU上就可以運行的Transformer模型嗎
壓縮模型會加速推理嗎?
Transformer模型的多模態學習應用
使用跨界模型Transformer來做物體檢測!

Microsoft使用NVIDIA Triton加速AI Transformer模型應用
Transformer常用的輕量化方法
基于Transformer的大型語言模型(LLM)的內部機制

基于 Transformer 的分割與檢測方法

transformer模型詳解:Transformer 模型的壓縮方法





 工商網監
工商網監
評論