 什么是超標量處理器的流水線?超標量處理器的特點有哪些?
什么是超標量處理器的流水線?超標量處理器的特點有哪些?
1.3 超標量處理器的流水線
1.3.0 超標量處理器的概述
A. 什么是超標量處理器?
如果每周期可取出多條指令(eg: 超過一條)送到流水線中執行,并使用硬件來對指令進行調度(eg: 靠硬件自身來決定哪些指令可以并行執行)的處理器,就可稱為超標量處理器;
B. 超標量處理器與VLIW處理器
不是每周期可執行多條指令的處理器都是超標量處理器,在 VLIW(超長指令字,Very Long Instruction Word)結構的處理器中,每周期也可執行多條指令,但VLIW處理器與超標量處理器有本質上的有差別:
| VLIW處理器 | 超標量處理器 | |
|---|---|---|
| 使用什么來對指令進行調度? | 靠硬件自身來決定哪些指令可以并行地執行; | 靠編譯器和程序員自身來決定哪些指令可以并行執行; |
| 通用處理器所必須具有的特性之一:程序員可以拋開底層硬件的實現細節,專注于軟件本身的功能,而且這個程序可以運行在任何支持該指令集的處理器上; | 對于通用處理器來說,超標量結構是必需的 | VLIW處理器無法實現這個功能,但是由于需要編譯器和程序員自身來調度指令的執行順序,這種處理器在硬件實現上是很簡單的,在功能比較專一的專用處理器領域可以大有一番作為,例如: DSP處理器; |
C. 超量與超標量、順序與亂序
| 標量 | 超標量 | |
|---|---|---|
| 順序(in-order) | 3 | 2 |
| 亂序(out-of-order) | x | 1 |
標量與超標量
標量:指處理器在一個時鐘周期內獲取、執行和提交一條指令;
超標量:指處理器在一個時鐘周期內獲取、執行和提交多條指令,與標量對應;
順序與亂序
順序:"順序發射、順序執行",指處理器按照指令原始順序逐條發射、逐條執行;
亂序:"亂序發射、亂序執行",與順序對應;
"超標量"一般和"亂序"搭配,"標量"一般和"順序"搭配;
D. 順序執行和亂序執行的超標量處理器的特點
| Fetch(取指) | Decode(譯碼) | Issue(發射) | Execute & Memory(執行 & 訪存) | Write Back(寫回) | Commit(提交) | ||
|---|---|---|---|---|---|---|---|
| 順序執行 | in-order | in-order | in-order | - | in-order | in-order | |
| 亂序執行 | in-order | in-order | out-of-order | - | out-of-order | in-order | |
Fetch 和 Decode 階段很難實現亂序,事實上就算實現了也沒意義;
Issue 表示將指令送到對應的功能單元(Function Unit,FU)中執行;
這里可亂序執行(out-of-order),因只要指令的源操作數準備好了,就可以將其先于其他指令而執行;
Write back 表示將指令的結果寫到目的寄存器中,
可在處理器內使用寄存器重命名(Register Renaming)將指令集(Instruction Set,IS)中定義的邏輯寄存器(Architecture Register File,ARF)動態地轉化為處理器內部實際使用的物理寄存器(Physical Register File,PRF),從而實現亂序方式(out-of-order)的寫回寄存器;
Commit 表示一條指令被允許更改處理器的狀態(Architecture state,例如D-Cache等),為了保證程序按照原來的意圖得到執行,并實現精確異常,這個階段需要順序執行,這樣才能夠保證從處理器外部看起來,程序是串行執行的;
精確異常:因為不希望異常處理進程破壞掉原程序的正常執行,所以流水線上沒有執行完的指令必須記住它處于流水線的哪一階段,且必須知道哪條指令發生的異常,當發生異常指令之后,所有指令都不能改變處理器狀態所以處理完異以便異常處理結束后能精確恢復執行,這便是精確異常。
1.3.1 順序執行(in-order)
A. 順序執行的超標量處理器的流水線
在順序執行(in-order)的超標量處理器中,指令的執行必須遵循程序中指定的順序;
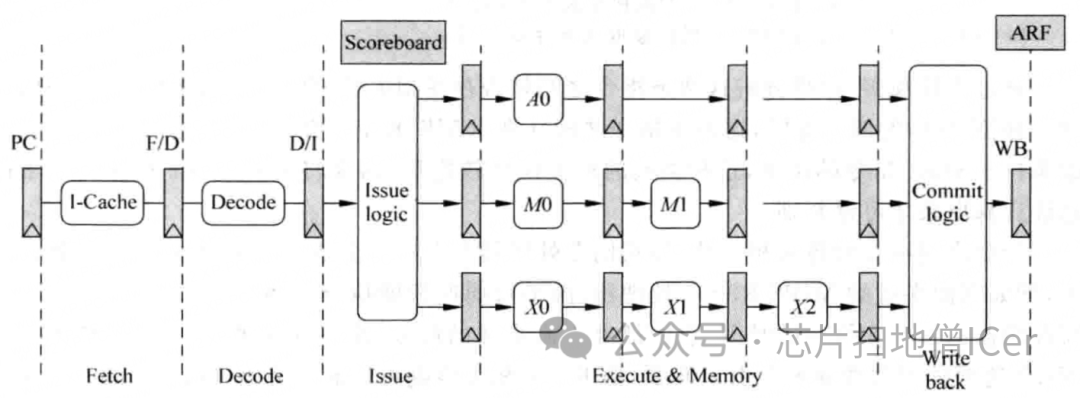
B. 粗略介紹 "順序執行的超標量處理器" 的流水線中關鍵階段
假設上圖的流水線是2-way超標量處理器的,則每周期可以從I-Cache中取出兩條指令來執行:
對于執行乘法操作指令的第三個FU來說,只有當指令到達1時,才可將它的結果進行旁路(by-pass);
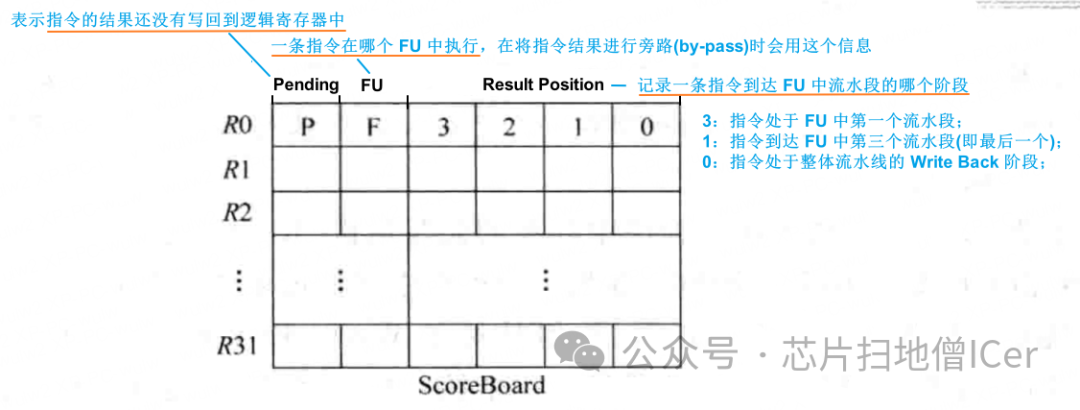
舉例一個典型的 Scoreboard (如下圖),記錄了指令集中定義的每個邏輯寄存器(R0~R31)的執行情況;
在流水線的 Issue 階段,會將指令的信息寫到 ScoreBoard 中,同時,這條指令會查詢 ScoreBoard 來獲知自己的源操作數是否都準備好了,在這條指令被送到 FU 中執行之后的每個周期,都會將這個值右移一位,這樣使用這個值就可以表達出指令在FU中執行到哪個階段;
對于執行ALU類型指令的第一個FU來說,當指令到達3時,就可將它的結果進行旁路(by-pass),而
在更復雜的處理器中,ScoreBoard 中還會有其他的內容;
第一個FU用來執行ALU類型的指令;
第二個FU用來執行訪問存儲器類型的指令;
第三個FU用來執行乘法操作的指令
Issue:在指令經過 Decode 階段之后,處理器會根據指令的類型,從 Issue Queue (發射隊列) 中選擇合適的指令發送到對應的 FU (Function Unit) 中執行,這個過程稱為 lssue,若將 Issue 的過程放到指令的 Decode 階段,會嚴重影響處理器的周期時間,因此將發射的過程單獨使用一個流水段;
Execute:如上圖,Execute 階段是使用了三個 FU (如下),因為要保證流水線的 Write Back 階段是順序執行的,因此所有 FU 都需要經歷同樣周期數的流水線 —— 此例子中,乘法運算需要的時間最長,因此第三個FU使用了三級流水線,其他的FU也需要跟隨著使用三級流水線,即使它們在有些流水段啥事情都沒有做;
Scoreboard:是用來記錄流水線中每條指令的執行情況,例如一條指令在哪個FU中執行,在什么時候這條指令可以將結果計算出來等,并可協助流水線的旁路(by-pass)工作;
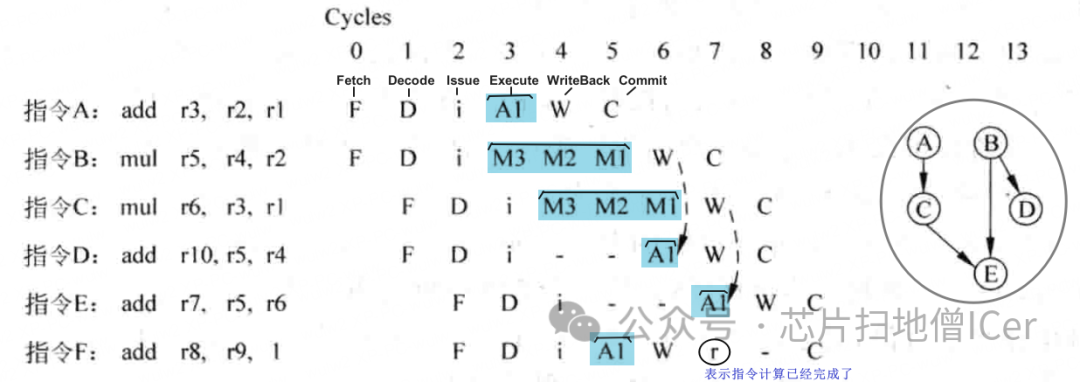
C. 粗略介紹 "順序執行的超標量處理器" 的流水線中的執行情況
下圖為上面流水線中的執行情況(情況有一定簡化)
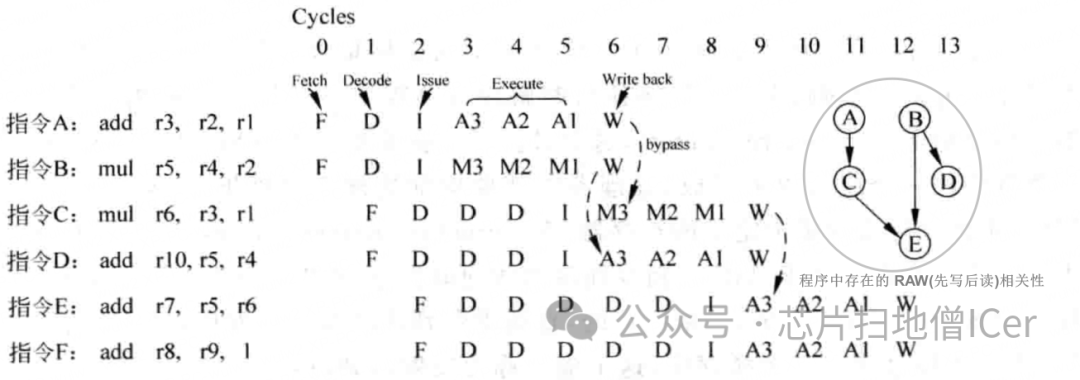
RAW (先寫后讀):
WAR (先讀后寫) 和 WAW (先寫后寫):
在所有的處理器中(不論順序執行還是亂序執行的處理器),RAW (先寫后讀) 相關性都是不可以繞開的,如果一個程序中存在過多的RAW相關性,那么這個程序就不能夠在處理器中被有效地執行;
處理器需要在先前的寫操作完成之后才能保證正確的讀取數據,因此不論處理器是順序執行還是亂序執行,都需要考慮和處理RAW相關性;
由于上圖例子中順序執行的處理器只有一個統一的 Write Back 階段,而且這個階段位于流水線的最后一級,因此WAR和WAW這兩種相關性都不會對流水線產生影響;
假設在流水線的 Write Back 階段才可以對計算結果進行 by-pass,由于這是一個順序執行(in-order)的處理器,很多指令在流水線都會由于前面指令的阻塞而不能夠繼續執行;
指令F,它和前面的指令都是不相關的,但由于這是一個順序執行(in-order)的處理器,所以這條指令只有等到前面所有的指令都已經發射(issue)了,它才可以送到FU中執行 —— 降低了處理器性能;
每條指令都可以從旁路網絡(bypassing network)獲得操作數,不需要等待源寄存器的值被 Write Back 到通用寄存器中,由于指令需要按照順序的方式執行,所以指令在很多時候都處于等待的狀態 —— 按照圖中例子,程序在一個2-way順序執行的超標量處理器中需要12個周期才可以執行完畢 —— 降低了處理器性能;
指令之間的相關性:
1.3.2 亂序執行(out-of-order)
A. 亂序執行的超標量處理器的流水線
在亂序執行(out-of-order)的超標量處理器中,指令的執行不再遵循程序中指定的順序 —— 某條指令的操作數一旦準備好,就可以將其送到 FU 中執行;
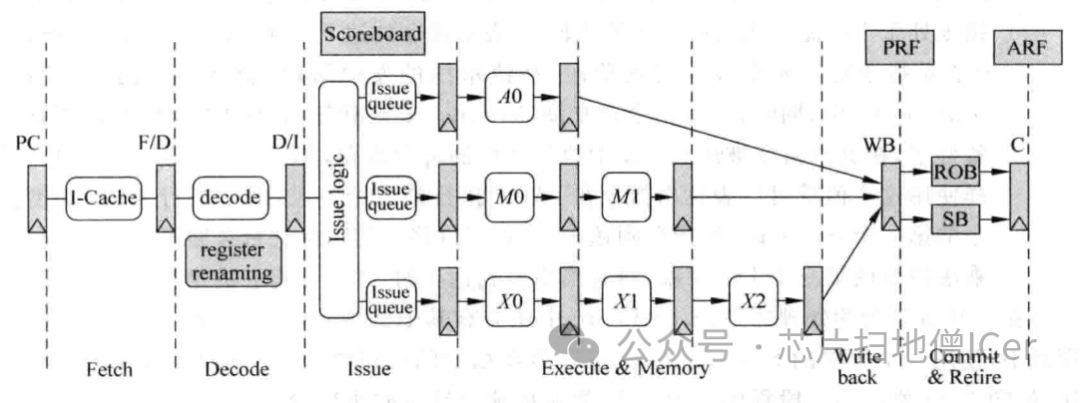
B. 粗略介紹 "亂序執行的超標量處理器" 的流水線中各個階段
Fetch(取指)
I-Cache:負責存儲最近常用的指令;
分支預測器:用來決定下條指令的PC值;
負責從 I-Cache 中取指令,主要由兩個部件構成:
Decode(解碼)
Decode 這部分的設計和指令集是息息相關的:
對于RISC指令集來說,例如MIPS, 由于比較簡潔,所以Decode部分也就相對比較簡單 —— 但在超標量處理器中,仍舊需要對一些特殊的指令進行處理,這些內容額外增加了Decode部分的設計復雜度。
對于CISC指令集來說,例如x86,由于比較復雜,所以Decode部分需要更多的邏輯電路來對這些指令進行識別;
用來識別出指令的類型、指令需要的操作數、指令的一些控制信號等;
Register Renaming(寄存器重命名)
在進行寄存器重命名時,通常使用一個表格來存儲當前邏輯寄存器到物理寄存器之間的對應關系,同時在該表格中還存儲著哪些物理寄存器還沒有被使用等信息,使用一些電路來分析當前周期被重命名的指令之間的RAW相關性,將那些存在RAW相關性的指令加以標記,這些指令會通過后續的旁路網絡(bypassing network)來解決它們之間存在的“真相關性”。
由于寄存器重命名階段需要的時間比較長, 現實當中的處理器都會將其單獨使用一級流水線,而不是和Decode階段放在一起(當然頭鐵也可以放一起^^)。
在流水線的 Decode 階段,可以得到指令的源寄存器和目的寄存器,這些寄存器都是邏輯寄存器,是在指令集中定義好的寄存器(ARF),為了解決WAR和WAW這兩種“偽相關性”,需要使用寄存器重命名的方法,將指令集中定義好的邏輯寄存器(ARF,Architecture Register File)重命名為處理器內部使用的物理寄存器(PRF,Physical Register File),物理寄存器(PRF)的個數需要多于邏輯寄存器(ARF)的個數,通過寄存器重命名,處理器可以調度更多可并行執行的指令。
Dispatch(分發)
如果在這些部件中沒有空閑的空間可以容納當前的指令,那么這些指令就需要在流水線的寄存器重命名階段進行等待,這就相當于暫停了寄存器重命名以及之前的所有流水線,直到這些部件中有空閑的空間為止;
Dispatch階段可以和寄存器重命名階段放在一起,在一些對周期時間要求比較緊的處理器中,也可以將這個部分單獨使用一個流水段;
經過流水線的 Dispatch階段后,指令會被寫到了 Issue Queue (發射隊列) 部件中;
在這個階段,被重命名之后的指令會按照程序中規定的順序,寫到發射隊列(lssue Queue)、重排序緩存(ROB)和 Store Buffer 等部件中;
Issue(發射) —— 是流水線從 in-order 到 out-of-order 的分界點
這個仲裁(select)電路可繁可簡:
對于亂序執行的處理器,Issue 階段是順序執行(in-order)到亂序執行(out-of-order)的分界點,指令在 Issue 階段后,都是按照亂序執行(out-of-order)的,直到流水線的 Commit 階段,才會重新變為順序執行(in-order)的狀態。
在lssue Queue中還存在喚醒(wake-up)電路,它可將 lssue Queue 中對應的源操作數置為有效的狀態;
仲裁電路和喚醒電路互相配合進行工作,是超標量處理器中的關鍵路徑;
對于順序發射(in-order issue)的情況,只需要判斷發射隊列中最舊的那條指令是否準備好就可以了;
對于亂序發射(out-of-order issue)的情況,則仲裁電路會變得比較復雜,它需要對lssue Queue中所有的指令進行判斷,并從所有準備好的指令中找出最合適的那條指令,送到FU中執行;
仲裁(select)電路會從這個 Issue Queue (發射隊列) 部件中選擇合適的指令發送到對應的 FU (Function Unit) 中執行,這個過程稱為 lssue;
Register File Read(讀取寄存器)
分情況,能不能從PRF中得到操作數:
事實上很大一部分指令都是通過旁路網絡(bypassing network)獲得操作數的,這也為減少PRF的讀端口提供了可能;
由于超標量處理器每周期需要執行好幾條指令,PRF所需要的端口個數也是比較多的,多端口寄存器堆的訪問速度一般都不會很快,因此在現實世界的處理器中,這個階段都會單獨使用一個流水段。
一般情況下,被仲裁電路選中的指令可以從PRF中得到源操作數;
不一般情況下,被仲裁電路選中的指令不能從PRF中得到操作數, 但卻可在送到FU中執行之前,從旁路網絡(bypassing network)中得到操作數;
被仲裁電路選中的指令需要從 PRF (物理寄存器堆,Physical Register File) 中讀取操作數 —— 指令得到它所需要的操作數:
Source Drive
Execute(執行)
在超標量處理器中,Execute 階段通常有很多個不同類型的 FU,例如負責普通運算的 FU、負責乘累加運算的FU、負責分支指令運算的FU、負責load/store指令執行的 FU 等;
現代的處理器還會加入一些多媒體運算的 FU,例如進行單指令多數據(SIMD)運算的 FU;
每個FU都有自己的流水線級數,如執行ALU類型指令的FU需要一個周期就可以計算出結果,則不再需要像順序執行的處理器那樣被拉長到和乘法FU一樣的周期數;
為什么PRF中的結果需要寫到ARF中?
PRF(Processing Register File)是用于保存指令執行的臨時結果的寄存器文件;
ARF(Architectural Register File)是用于在程序執行期間保存程序狀態的寄存器文件;
因為PRF中的結果是臨時保存的,在程序的不同階段可能會被覆蓋或者丟失,所以需要將其寫入到ARF中,以便長期保存和使用。
當PRF中的結果寫入ARF時,它們就成為了程序執行的一部分,可以被其他指令訪問和使用,從而更新程序執行的當前狀態。
因此,將PRF中的結果寫入ARF中是程序正確執行所必需的步驟。
在這種流水線中,由于每個FU的執行周期數都不相同,所以指令在流水線的Write Back 階段是亂序的,在 Write Back 階段,一條指令只要計算完畢, 就會將結果寫到PRF中;
由于分支預測失敗(mis-prediction)或者異常(exception)的存在,PRF中的結果未必都會寫到ARF中,因此也將PRF稱為Future File;
指令得到它所需要的操作數后,馬上就可以送到對應的FU中執行了:
Write Back(寫回)
在現代的處理器中,旁路網絡是影響速度的關鍵因素,因為這部分電路需要大量的布線,而隨著硅工藝尺寸的減少,連線的延遲甚至超過了門電路的延遲,因此旁路網絡會嚴重影響處理器的周期時間;
為了解決上述的問題,很多處理器都使用了Cluster的結構,將 FU 分成不同的組:
在一個組內的FU,布局布線時會被緊挨在一起,這樣在這個組內的旁路網絡,由于經過的路徑比較短,一般都可以在一個周期內完成;
當旁路網絡跨越不同的組時,就需要兩個甚至多個周期了,這種Cluster的結構是一種的折中方案。
Write Back 階段:1. 會將FU計算的結果寫到PRF(物理寄存器堆)中;2. 同時也可通過旁路網絡(bypassing network)將這個FU計算的結果送到需要的地方,一般都是送到所有FU的輸入端,由FU輸入端的控制電路來決定最終需要的數據;
Commit(提交)
精確異常:因為不希望異常處理進程破壞掉原程序的正常執行,所以流水線上沒有執行完的指令必須記住它處于流水線的哪一階段,且必須知道哪條指令發生的異常,當發生異常指令之后,所有指令都不能改變處理器狀態所以處理完異以便異常處理結束后能精確恢復執行,這便是精確異常。
一條指令在 Retire 之前,都可以從流水線中被清除,但是一旦它順利地 Retire 而離開流水線,它的生命周期也就結束了,不能夠再返回到以前的狀態 —— 這對于store指令會帶來額外的麻煩:因為store指令需要寫存儲器,如果在流水線的 Write Back 階段就將store指令的結果寫入到存儲器中,那么一旦由于分支預測失敗或者異常等原因,需要將這條store指令從流水線中抹掉時,就沒有辦法將存儲器的狀態進行恢復了,因為存儲器中原來的值已經被覆蓋了 —— 于是需使用一個緩存,稱為 Store Buffer (SB),來存儲store指令沒有 Retire 之前的結果;
store指令在流水線的 Write Back 階段,會將它的結果寫入到SB中,只有一條 store 指令真的從流水線中 Retire 時,才可以將它的值從SB寫到存儲器中。
使用 SB 這個部件之后,Load指令此時除了從D-Cache中尋找數據,還需要從Store Buffer中進行查找,這樣在一定程度上增加了設計的復雜度。
一條指令在 Commit 階段,會將它的結果從PRF搬移到ARF中,同時ROB也會配合完成對exception(異常)的處理,如果不存在異常,那么這條指令就可以順利地離開流水線, 并對處理器的狀態進行更改,此時稱這條指令退休 (Retire) 了,一條指令一旦退休,它就再也不可能回到之前的狀態了。
在ROB中,如果一條指令之前的指令還沒有執行完,那么即使這條指令已經執行完了,它也不能離開ROB,必須等待它之前的所有指令都執行完成這條指令才能離開ROB —— 一條指令一旦從 ROB 中離開而 Retire(退休),那么就對處理器的狀態進行了修改,再也無法返回到之前的狀態了;
之所以能夠完成這樣的任務,是因為:指令在流水線的 dispatch 階段,按照程序中規定的順序(in-order)寫到了 ROB 中;
程序在處理器中表現出來的結果總是串行的,如果在程序中先向寄存器R1寫數據,然后向寄存器R2寫數據,那么處理器表現出來的執行結果一定是先寫R1再寫R2,也就是說,處理器執行的結果要和程序中原始的順序是一樣的;
在超標量處理器中,雖然指令可按照亂序執行(out-of-order),但是最后需要這樣一個階段(Commit 階段),將這些亂序執行的指令變回到程序規定的原始順序;
程序在處理器中表現出來的結果總是串行的,為了保證程序的串行結果,指令需要按照程序中規定的順序更新處理器的狀態,這需要使用一個稱為 ROB (重排序緩存) 的部件來配合,流水線中的所有指令都按照程序中規定的順序存儲在 ROB (重排序緩存) 中,使用 ROB 來實現程序對處理器狀態的順序更新,這階段稱為Commit;
Commit 階段起主要作用的部件是 ROB (重排序緩存),它會將亂序執行的指令拉回到程序中規定的順序;
指令退休 (Retire) :
Store Buffer (SB) :
在 Commit 階段也會對指令產生的exception(異常)進行處理,指令在流水線的很多階段都可能發生exception(異常),但是所有的exception(異常)都必須等到指令到達流水線的 Commit 階段時才能進行處理,這樣可以保證異常處理是按照程序中規定的順序進行,并且能夠實現精確異常;
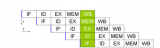
C. 粗略介紹 "亂序執行的超標量處理器" 的流水線中的執行情況
下圖為上面流水線中的執行情況(情況有一定簡化)
D將"Decode"和"寄存器重命名"這兩個過程放到了同一個流水段;
r 表示指令已經計算完成,在 ROB 中等待 Retire;
C表示一條指令經過了流水線的 Commit 階段,離開流水線而 Retire了,這個過程是按照程序中規定的順序執行(in-order)的;
D、r、C:
一條指令只有等到它之前的所有指令都離開 ROB 了,才允許它離開ROB而從流水線中 Retire;
該程序只要9個周期就可以完成,快于之前順序執行程序的處理器(12個周期),這是由于亂序執行提高了流水線的執行效率 —— 當需要執行的指令個數更多時,亂序執行的優勢就會更加明顯。
1.3.3 處理器的狀態恢復
現代的處理器在很多地方使用了預測技術,因為超標量處理器的流水線一般比較深,所以不使用預測技術是沒有辦法獲得高性能的;
一般情況下,預測能夠有效工作的前提就是:有規律可循,一個很明顯的例子就是分支預測,分支指令在執行過程中表現出的規律性,使分支預測成為了可能。
但是,只要是預測,就會存在失敗的可能,這時候就需要一種方法,將處理器恢復到正確的狀態,這就是恢復電路的工作,它不但要將錯誤的指令從流水線中抹掉,還需要將這些錯誤指令在流水線中造成的“痕跡”進行消除,例如這些錯誤的指令可能已經修改了重命名映射表, 或者已經將結果寫到了物理寄存器中等,這都需要被修正過來。
恢復電路和預測技術是天生的一對,只要有預測,就必然有狀態恢復,激進的預測技術會提高處理器的性能,但是代價就是更復雜的恢復電路。
在超標量處理器中,對異常的處理由于需要抹掉流水線中的指令, 因此也需要使用恢復電路來使處理器恢復到正確的狀態,這些內容將在本書詳細地展開介紹。
審核編輯:劉清
-
處理器
+關注
關注
68文章
19178瀏覽量
229200 -
dsp
+關注
關注
552文章
7962瀏覽量
348308 -
寄存器
+關注
關注
31文章
5325瀏覽量
120052 -
Cache
+關注
關注
0文章
129瀏覽量
28304 -
ArF
+關注
關注
0文章
3瀏覽量
1052
原文標題:一文入門 | 什么是超標量處理器的流水線?
文章出處:【微信號:處芯積律,微信公眾號:處芯積律】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
一文詳解高效能x86處理器
ARM Cortex-A8 處理器的介紹
現代RISC中的流水線技術
ARM Cortex-M7處理器參考手冊
什么是超標量技術/FADD?
流水線操作,應用處理器,應用處理器的結構和原理是什么?
PowerPC芯片特點及超標量體系CPU優化技術
亂序超標量處理器核的功耗優化
新思科技推出全新ARC處理器,采用超標量ARCv3指令集架構
超標量處理器的指令亂序提交機制綜述
H7的特點 什么是超標量流水線






 工商網監
工商網監
評論