") HBM究竟是什么呢?為何在AI時代如此火熱?
HBM究竟是什么呢?為何在AI時代如此火熱?
今天我們聊聊GPU背后的女人,不對,是背后的大贏家-HBM。
那么,HBM究竟是什么呢?為何在AI時代如此火熱?下面我們就一一道來。
***01. ***HBM到底為何方神圣?
HBM全稱為High Bandwidth Memory,直接翻譯即是高帶寬內存,是一款新型的CPU/GPU內存芯片。其實就是將很多個DDR芯片堆疊在一起后和GPU封裝在一起,實現(xiàn)大容量、高位寬的DDR組合陣列。
打個比喻,就是傳統(tǒng)的DDR就是采用的"平房設計"方式,HBM則是"樓房設計"方式,從而可實現(xiàn)了更高的性能和帶寬。
我們以AMD最新發(fā)布MI300X GPU芯片布局為例,中間的die是GPU,左右兩側的4個小die就是DDR顆粒的堆疊HBM。目前,在平面布局上,GPU現(xiàn)在一般常見有2/4/6/8四種數(shù)量的堆疊,立體上目前最多堆疊12層。
可能會說,HBM跟DDR不就是"平房"和"樓房"的區(qū)別嗎?這也叫創(chuàng)新?
其實想要實現(xiàn)HBM生產并沒有說起來這么簡單,大家想想,建一個樓房可要比建一個平房要困難很多,從底層地基到布線都需要重新設計。HBM的構建像樓房一樣,將傳輸信號、指令、電流都進行了重新設計,而且對封裝工藝的要求也高了很多。
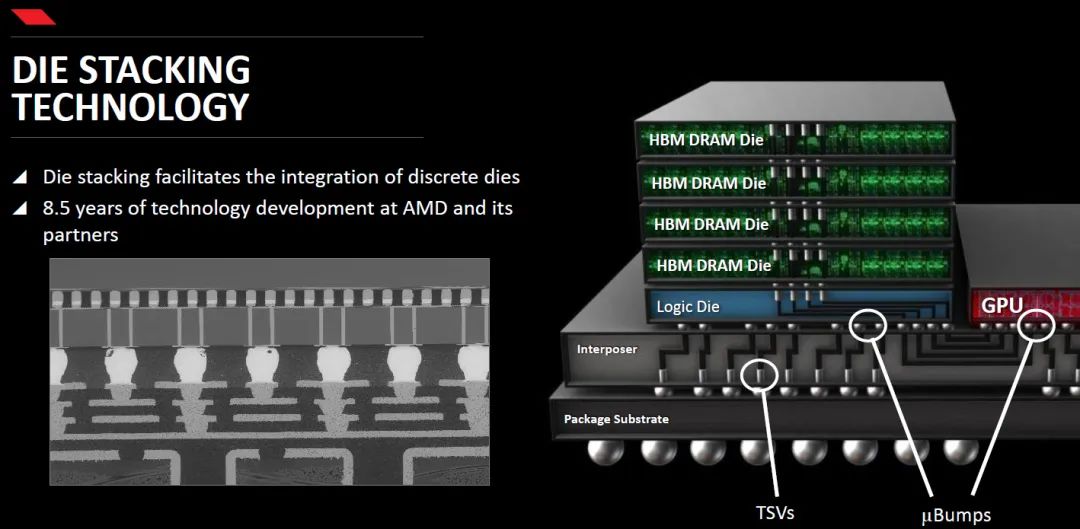
如上圖右側,DRAM通過堆疊的方式,疊在一起,Die之間用TVS方式連接;DRAM下面是DRAM邏輯控制單元, 對DRAM進行控制;GPU和DRAM通過uBump和Interposer(起互聯(lián)功能的硅片)連通;Interposer再通過Bump和 Substrate(封裝基板)連通到BALL;最后BGA BALL 連接到PCB上。
HBM堆棧通過中介層緊湊而快速地連接,HBM具備的特性幾乎和芯片集成的RAM一樣,可實現(xiàn)更多的IO數(shù)量。同時HBM重新調整了內存的功耗效率,使每瓦帶寬比GDDR5高出3倍還多。也即是功耗降低3倍多!另外,HBM 在節(jié)省產品空間方面也獨具匠心,HBM比GDDR5節(jié)省了 94% 的表面積!使游戲玩家可以擺脫笨重的GDDR5芯片,盡享高效。

鑒于技術上的復雜性,HBM是公認最能夠展示存儲廠商技術實力的旗艦產品。
***02. ***為什么需要HBM?
HBM的初衷,就是為了向GPU和其他處理器提供更多的內存。
這主要是因為隨著GPU 的功能越來越強大,需要更快地從內存中訪問數(shù)據(jù),以縮短應用處理時間。例如,AI和視覺,具有巨大內存和計算和帶寬要求。
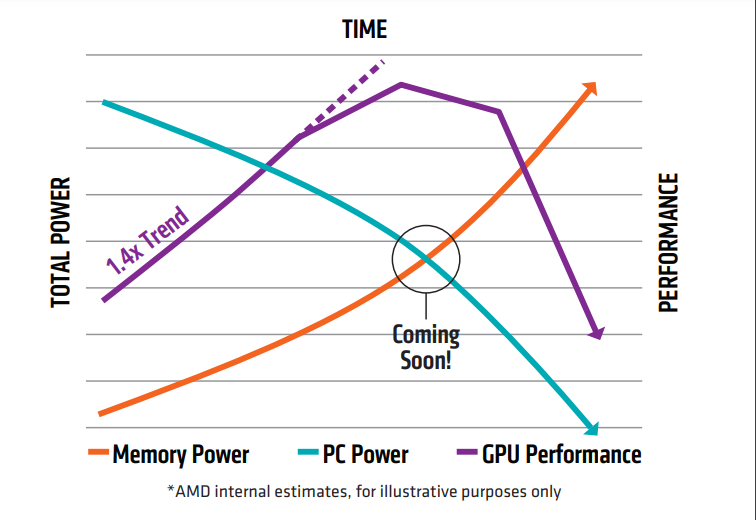
為了減小“內存墻”的影響,提升內存帶寬一直是存儲芯片聚焦的關鍵問題。
半導體的先進封裝為克服阻礙高性能計算應用程序的內存訪問障礙提供了機會,內存的延遲和密度都是可以在封裝級別解決的挑戰(zhàn)。基于對先進技術和解決方案開展的研究,內存行業(yè)在新領域進行了更深入的探索。
為了克服這些挑戰(zhàn),半導體封裝設計人員采用了異構集成路線,以在更靠近處理器的位置包含更多內存。而HBM就為現(xiàn)代處理器和嵌入式系統(tǒng)當前面臨的內存障礙問題提供了解決方案。這些存儲器為系統(tǒng)設計人員提供了兩個優(yōu)勢:一是減少組件占用空間和外部存儲器要求;二是更快的內存訪問時間和速率。
疊起來之后,直接結果就是接口變得更寬,其下方互聯(lián)的觸點數(shù)量遠遠多于DDR內存連接到CPU的線路數(shù)量。因此,與傳統(tǒng)內存技術相比,HBM具有更高帶寬、更多I/O數(shù)量、更低功耗、更小尺寸。
目前,HBM產品以HBM(第一代)、HBM2(第二代)、HBM2E(第三代)、HBM3(第四代)、HBM3E(第五代)的順序開發(fā),最新的HBM3E是HBM3的擴展版本。
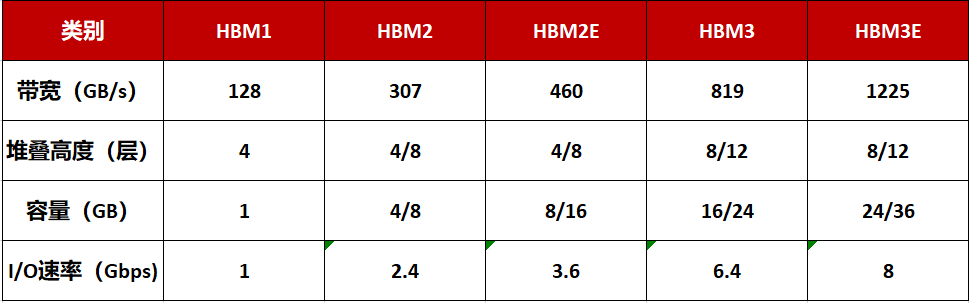
HBM每一次更新迭代都會伴隨著處理速度的提高。引腳(Pin)數(shù)據(jù)傳輸速率為1Gbps的第一代HBM,發(fā)展到其第五產品HBM3E,速率則提高到了8Gbps,即每秒可以處理1.225TB的數(shù)據(jù)。也就是說,下載一部長達163分鐘的全高清(Full-HD)電影(1TB)只需不到1秒鐘的時間。
當然,存儲器的容量也在不斷加大:HBM2E的最大容量為16GB,目前,三星正在利用其第四代基于EUV光刻機的10nm制程(14nm)節(jié)點來制造24GB容量的HBM3芯片,此外8層、12層堆疊可在HBM3E上實現(xiàn)36GB(業(yè)界最大)的容量,比HBM3高出50%。
此前SK海力士、美光均已宣布推出HBM3E芯片,皆可實現(xiàn)超過1TB/s的帶寬。
同時,三星也宣布HBM4內存將采用更先進的芯片制造和封裝技術,雖然HBM4的規(guī)格尚未確定,但有消息稱業(yè)界正尋求使用2048位內存接口,并使用FinFET晶體管架構來降低功耗。三星希望升級晶圓級鍵合技術,從有凸塊的方式轉為無凸塊直接鍵合。因此,HBM4的成本可能會更高。
***03. ***HBM的發(fā)展史
如同閃存從2D NAND向3D NAND發(fā)展一樣,DRAM也是從2D向3D技術發(fā)展,HBM也由此誕生。
在最初, HBM是通過硅通孔(Through Silicon Via, 簡稱"TSV")技術進行芯片堆疊,以增加吞吐量并克服單一封裝內帶寬的限制,將數(shù)個DRAM裸片像摩天大廈中的樓層一樣垂直堆疊,裸片之間用TVS技術連接。
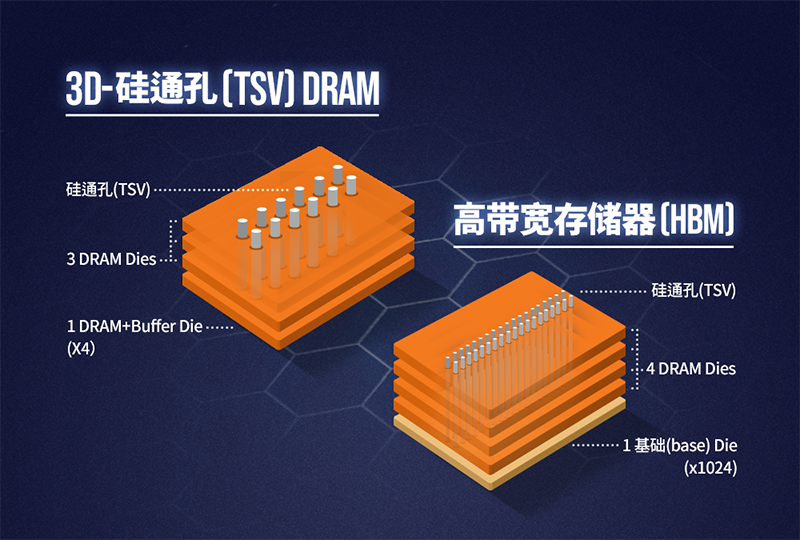
從技術角度看,HBM使得DRAM從傳統(tǒng)2D轉變?yōu)榱Ⅲw3D,充分利用空間、縮小面積,正契合半導體行業(yè)小型化、集成化的發(fā)展趨勢。HBM突破了內存容量與帶寬瓶頸,被視為新一代DRAM解決方案,業(yè)界認為這是DRAM通過存儲器層次結構的多樣化開辟一條新的道路,革命性提升DRAM的性能。
在HBM的誕生與發(fā)展過程中,AMD和SK海力士可謂功不可沒。據(jù)了解,AMD在2009年就意識到DDR的局限性并產生開發(fā)堆疊內存的想法,后來其與SK海力士聯(lián)手研發(fā)HBM。
2013年,經過多年研發(fā)后,AMD和SK海力士終于推出了HBM這項全新技術,還被定為了JESD235行業(yè)標準,HBM1的工作頻率約為1600 Mbps,漏極電源電壓為1.2V,芯片密度為2Gb(4-hi),其帶寬為4096bit,遠超GDDR5的512bit。
除了帶寬外,HBM對DRAM能耗的影響同樣重要。此外,由于GPU核心和顯存封裝在了一起,還能一定程度上減輕散熱的壓力,原本是一大片的散熱區(qū)域,濃縮至一小塊,散熱僅需針對這部分區(qū)域,原本動輒三風扇的設計,可以精簡為雙風扇甚至是單風扇,變相縮小了顯卡的體積。
在當時,無論是AMD和SK海力士,還是媒體和眾多玩家,都認定了這才是未來的顯存。第一代HBM面世商用后,SK海力士與三星即開始了一場你追我趕的競賽。
2016年1月,三星宣布開始量產4GB HBM2 DRAM,并在同一年內生產8GB HBM2 DRAM;2017年下半年,被三星趕超的SK海力士開始量產HBM2;2018年1月,三星宣布開始量產第二代8GB HBM2"Aquabolt"。
2018年末,JEDEC推出HBM2E規(guī)范,以支持增加的帶寬和容量。當傳輸速率上升到每管腳3.6Gbps時,HBM2E可以實現(xiàn)每堆棧461GB/s的內存帶寬。此外,HBM2E支持最多12個DRAM的堆棧,內存容量高達每堆棧24GB。與HBM2相比,HBM2E具有技術更先進、應用范圍更廣泛、速度更快、容量更大等特點。
2019年8月,SK海力士宣布成功研發(fā)出新一代"HBM2E";2020年2月,三星也正式宣布推出其16GB HBM2E產品"Flashbolt",于2020年上半年開始量產。
2020年,另一家存儲巨頭美光宣布加入到這一賽場中來。
美光在當時的財報會議上表示,將開始提供HBM2內存/顯存,用于高性能顯卡,服務器處理器產品,并預計下一代HBMNext將在2022年底面世。但截至目前尚未看到美光相關產品動態(tài)。
2022年1月,JEDEC組織正式發(fā)布了新一代高帶寬內存HBM3的標準規(guī)范,繼續(xù)在存儲密度、帶寬、通道、可靠性、能效等各個層面進行擴充升級。JEDEC表示,HBM3是一種創(chuàng)新的方法,是更高帶寬、更低功耗和單位面積容量的解決方案,對于高數(shù)據(jù)處理速率要求的應用場景來說至關重要,比如圖形處理和高性能計算的服務器。
2022年6月量產了HBM3 DRAM芯片,并將供貨英偉達,持續(xù)鞏固其市場領先地位。隨著英偉達使用HBM3 DRAM,數(shù)據(jù)中心或將迎來新一輪的性能革命。
2023年,NVIDIA 發(fā)布H200芯片,是首款提供HBM3e內存的GPU,HBM3e是目前全球最高規(guī)格的HBM內存,由SK海力士開發(fā),將于明年上半年開始量產。
2023年12月,AMD發(fā)布最新MI300X GPU芯片,2.5D硅中介層、3D混合鍵合集一身的3.5D封裝,集成八個5nm工藝的XCD模塊,內置304個CU計算單元,又可分為1216個矩陣核心,同時還有四個6nm工藝的IOD模塊和256MB無限緩存,以及八顆共192GB HBM3高帶寬內存。
從HBM1到HBM3,SK海力士和三星一直是HBM行業(yè)的領軍企業(yè)。但比較可惜的是,AMD卻在2016年發(fā)布完產品后完全轉向,近乎放棄了HBM。唯一仍然保留HBM技術的是用于AI計算的加速卡。
起了個大早,趕了個晚集,是對AMD在HBM上的最好概括。既沒有憑借HBM在游戲顯卡市場中反殺英偉達,反而被英偉達利用HBM鞏固了AI計算領域的地位,白白被別人摘了熟透甜美的桃子。
***04. ***HBM的競爭格局?
由生成式AI引發(fā)對HBM及相關高傳輸能力存儲技術的需求,HBM成為存儲巨頭在下行行情中對業(yè)績的重要扭轉力量,這也是近期業(yè)績會上的高頻詞。
調研機構TrendForce集邦咨詢也指出,預估2023年全球HBM需求量將年增近六成,來到2.9億GB,2024年將再增長三成。2023年HBM將處于供不應求態(tài)勢,到2024年供需比有望改善。
但是HBM在整體存儲市場占比較低,目前還不是普及性應用的產品。目前似乎競爭都局限在SK海力士、三星和美光這三家企業(yè)之間。
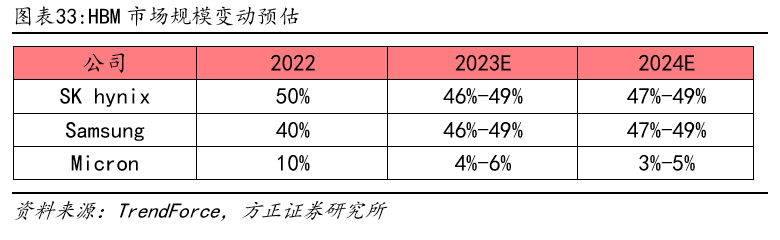
目前,在HBM的競爭格局中,SK海力士是技術領先并擁有最高市場份額的公司,其市占率為50%。緊隨其后的是三星,市占率約為40%,而美光占據(jù)了大約10%的市場份額。
根據(jù)預測,到23年,海力士的市場份額有望提升至53%,而三星和美光的市場份額將分別為38%和9%。
在下游廠商主要包括CPU/GPU制造商,例如英特爾、英偉達和AMD。由于HBM是與GPU封裝在一起的,因此HBM的封裝通常由晶圓代工廠完成。
反觀到我們國內,由于起步較晚,目前HBM相關產業(yè)鏈布局相對較小,只有一些企業(yè)涉及封測領域。但是這也意味著,在信息安全的今天,HBM具有更大的成長空間。
目前,在國內涉及HBM產業(yè)鏈的公司主要包括雅克科技、中微公司、和拓荊科技等公司。其中,雅克的子公司UP Chemical是SK海力士的核心供應商,為其提供HBM前驅體。
在HBM工藝中,ALD沉積(單原子層沉積)起著重要作用。拓荊科技就是國內主要的ALD供應商之一,公司的PEALD產品用于沉積SiO2、SiN等介質薄膜,在客戶端驗證中都取得了令人滿意的結果。
而TSV技術(硅通孔技術)也是HBM的核心技術之一,中微公司是TSV設備的主要供應商。硅通孔技術用于連接硅晶圓兩面,并與硅襯底和其他通孔絕緣的電互連結構。它能夠通過硅基板實現(xiàn)硅片內部的垂直電互聯(lián),是實現(xiàn)2.5D和3D先進封裝的關鍵。
隨著HBM堆疊DRAM裸片數(shù)量逐步增加到8層和12層,HBM對DRAM材料的需求將呈倍數(shù)級增長。同時,HBM前驅體的單位價值也將出現(xiàn)倍數(shù)級增長,這為前驅體市場帶來了全新的發(fā)展機遇。
***05. ***HBM的未來應用前景
隨著AI大模型、智能駕駛等新技術的崛起,人們對高帶寬的內存的需求越來越多。
首先,AI服務器的需求會在近兩年爆增,如今在市場上已經出現(xiàn)了快速的增長。AI服務器可以在短時間內處理大量數(shù)據(jù),GPU可以讓數(shù)據(jù)處理量和傳輸速率的大幅提升,讓AI服務器對帶寬提出了更高的要求,而HBM基本是AI服務器的標配。
除了AI服務器,汽車也是HBM值得關注的應用領域。汽車中的攝像頭數(shù)量,所有這些攝像頭的數(shù)據(jù)速率和處理所有信息的速度都是天文數(shù)字,想要在車輛周圍快速傳輸大量數(shù)據(jù),HBM具有很大的帶寬優(yōu)勢。
另外,AR和VR也是HBM未來將發(fā)力的領域。因為VR和AR系統(tǒng)需要高分辨率的顯示器,這些顯示器需要更多的帶寬來在 GPU 和內存之間傳輸數(shù)據(jù)。而且,VR和AR也需要實時處理大量數(shù)據(jù),這都需要HBM的超強帶寬來助力。
此外,智能手機、平板電腦、游戲機和可穿戴設備的需求也在不斷增長,這些設備需要更先進的內存解決方案來支持其不斷增長的計算需求,HBM也有望在這些領域得到增長。并且,5G 和物聯(lián)網 (IoT) 等新技術的出現(xiàn)也進一步推動了對 HBM 的需求。
并且,AI的浪潮還在愈演愈烈,HBM今后的存在感或許會越來越強。據(jù)semiconductor-digest預測,到2031年,全球高帶寬存儲器市場預計將從2022年的2.93億美元增長到34.34億美元,在2023-2031年的預測期內復合年增長率為31.3%。
***06. ***HBM需要克服的問題
1:HBM需要較高的工藝從而導致大幅度提升了成本。
針對更大數(shù)據(jù)集、訓練工作負載所需的更高內存密度要求,存儲廠商開始著手研究擴展Die堆疊層數(shù)和物理堆疊高度,以及增加核心Die密度以優(yōu)化堆疊密度。
但就像處理器芯片摩爾定律發(fā)展一樣,當技術發(fā)展到一個階段,想要提升更大的性能,那么成本反而會大幅提升,導致創(chuàng)新放緩。
2:產生大量的熱,如何散熱是GPU極大的挑戰(zhàn)。
行業(yè)廠商需要在不擴大現(xiàn)有物理尺寸的情況下增加存儲單元數(shù)量和功能,從而實現(xiàn)整體性能的飛躍。但更多存儲單元的數(shù)量讓GPU的功耗大幅提升。新型的內存需要盡量減輕內存和處理器之間搬運數(shù)據(jù)的負擔。
***07. ***最后總結
隨著人工智能、機器學習、高性能計算、數(shù)據(jù)中心等應用市場的興起,內存產品設計的復雜性正在快速上升,并對帶寬提出了更高的要求,不斷上升的寬帶需求持續(xù)驅動HBM發(fā)展。相信未來,存儲巨頭們將會持續(xù)發(fā)力、上下游廠商相繼入局,讓HBM得到更快的發(fā)展和更多的關注。
審核編輯:劉清
-
處理器
+關注
關注
68文章
19178瀏覽量
229201 -
嵌入式系統(tǒng)
+關注
關注
41文章
3570瀏覽量
129253 -
TVS
+關注
關注
8文章
775瀏覽量
60519 -
HBM
+關注
關注
0文章
374瀏覽量
14708 -
DDR芯片
+關注
關注
0文章
5瀏覽量
1763
原文標題:一文讀懂GPU最強"輔助"HBM
文章出處:【微信號:算力基建,微信公眾號:算力基建】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
相關推薦
PCM1861 INT腳究竟是輸出還是輸入?
超高頻讀寫器究竟是什么,能做什么?一文讀懂!

請問cH340G的TX引腳電平究竟是3v還是5v?
工業(yè)物聯(lián)網究竟是什么呢?它又有哪些作用呢?
STM32擦除后數(shù)據(jù)究竟是0x00還是0xff ?
MOSFET的柵源振蕩究竟是怎么來的?柵源振蕩的危害什么?如何抑制
吸塵器究竟是如何替你“吃灰”的【其利天下技術】






 工商網監(jiān)
工商網監(jiān)
評論