 為什么深度學習的效果更好?
為什么深度學習的效果更好?
導讀
深度學習是機器學習的一個子集,已成為人工智能領域的一項變革性技術,在從計算機視覺、自然語言處理到自動駕駛汽車等廣泛的應用中取得了顯著的成功。深度學習的有效性并非偶然,而是植根于幾個基本原則和進步,這些原則和進步協同作用使這些模型異常強大。本文探討了深度學習成功背后的核心原因,包括其學習層次表示的能力、大型數據集的影響、計算能力的進步、算法創新、遷移學習的作用及其多功能性和可擴展性。
為什么深度學習的效果更好?
分層特征學習深度學習有效性的核心在于其分層特征學習的能力。由多層組成的深度神經網絡學習識別不同抽象級別的模式和特征。初始層可以檢測圖像中的簡單形狀或紋理,而更深的層可以識別復雜的對象或實體。這種多層方法使深度學習模型能夠建立對數據的細致入微的理解,就像人類認知如何處理從簡單到復雜的信息的方式一樣。這種分層學習范式特別擅長處理現實世界數據的復雜性和可變性,使模型能夠很好地從訓練數據泛化到新的情況。海量數據大數據的出現給深度學習帶來了福音。這些模型的性能通常與它們所訓練的數據集的大小相關,因為更多的數據為學習底層模式和減少過度擬合提供了更豐富的基礎。深度學習利用大量數據的能力對其成功至關重要,它使模型能夠在圖像識別和語言翻譯等任務中實現并超越人類水平的表現。深度學習模型對數據的需求得到了信息數字化以及數據生成設備和傳感器激增的支持,使得大型數據集越來越多地可用于培訓目的。計算能力增強GPU 和 TPU 等計算硬件的進步極大地實現了大規模訓練深度學習模型的可行性。這些技術提供的并行處理能力非常適合深度學習的計算需求,從而實現更快的迭代和實驗。訓練時間的減少不僅加快了深度學習模型的開發周期,而且使探索更復雜、更深的網絡架構成為可能,突破了這些模型所能實現的界限。 算法創新深度學習的進步也是由不斷的算法創新推動的。Dropout、批量歸一化和高級優化器等技術解決了深度網絡訓練中的一些初始挑戰,例如過度擬合和梯度消失問題。這些進步提高了深度學習模型的穩定性、速度和性能,使它們更加穩健且更易于訓練。遷移學習和預訓練模型
遷移學習在深度學習民主化方面發揮了關鍵作用,使深度學習模型能夠應用于無法獲得大型標記數據集的問題。
通過微調在大型數據集上預先訓練的模型,研究人員和從業者可以使用相對少量的數據實現高性能。這種方法在醫學成像等領域尤其具有變革性,在這些領域獲取大型標記數據集具有挑戰性。
標多功能性和可擴展性最后,深度學習模型的多功能性和可擴展性有助于其廣泛采用。這些模型可以應用于廣泛的任務,并根據數據和計算資源的可用性進行調整。這種靈活性使深度學習成為解決各種問題的首選解決方案,推動跨學科的創新和研究。
代碼
為了使用完整的 Python 代碼示例來演示深度學習的工作原理,讓我們創建一個簡單的合成數據集,設計一個基本的深度學習模型,對其進行訓練,并使用指標和圖表評估其性能。
我們將使用NumPy庫進行數據操作,使用 TensorFlow 和 Keras 構建和訓練神經網絡,并使用 Matplotlib 進行繪圖。
import numpy as npimport matplotlib.pyplot as plt.pyplot as pltfrom sklearn.datasets import make_moonsfrom tensorflow.keras.models import Sequentialfrom tensorflow.keras.layers import Densefrom tensorflow.keras.optimizers import Adamfrom sklearn.model_selection import train_test_splitfrom sklearn.metrics import accuracy_score
# 步驟 1:生成合成數據集X, y = make_moons(n_samples=1000, noise=0.1, random_state=42)X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
#步驟2:構建深度學習模型model = Sequential([ Dense(10, input_dim=2, activation='relu'), Dense(10, activation='relu'), Dense(1, activation='sigmoid')])
model.compile(optimizer=Adam(learning_rate=0.01), loss='binary_crossentropy', metrics=['accuracy'])
# 步驟 3:訓練模型history = model.fit(X_train, y_train, validation_data=(X_test, y_test), epochs=100, verbose=0)
# 步驟 4:評估模型predictions = model.predict(X_test) > 0.5print(f"Accuracy: {accuracy_score(y_test, predictions)}")
# 繪圖plt.figure(figsize=(14, 5))
# 繪制決策邊界plt.subplot(1, 2, 1)plt.title("Decision Boundary")x_span = np.linspace(min(X[:,0]) - 0.25, max(X[:,0]) + 0.25)y_span = np.linspace(min(X[:,1]) - 0.25, max(X[:,1]) + 0.25)xx, yy = np.meshgrid(x_span, y_span)grid = np.c_[xx.ravel(), yy.ravel()]pred_func = model.predict(grid) > 0.5z = pred_func.reshape(xx.shape)plt.contourf(xx, yy, z, alpha=0.5)plt.scatter(X[:,0], X[:,1], c=y, cmap='RdBu', lw=0)
# 繪制損失曲線plt.subplot(1, 2, 2)plt.title("Training and Validation Loss")plt.plot(history.history['loss'], label='Train Loss')plt.plot(history.history['val_loss'], label='Val Loss')plt.legend()
plt.tight_layout()plt.show()
該代碼執行以下操作:
make_moons使用 的函數生成合成數據集sklearn,該數據集適合展示深度學習在非線性可分離數據上的強大功能。
構建一個具有兩個隱藏層的簡單神經網絡,對隱藏層使用 ReLU 激活,對輸出層使用 sigmoid 激活,以執行二元分類。
使用二元交叉熵作為損失函數和 Adam 優化器在合成數據集上訓練模型。
評估模型在測試集上的準確性并打印它。
- 繪制模型學習的決策邊界,以直觀地檢查它區分兩個類的程度,并繪制歷元內的訓練和驗證損失以演示學習過程。
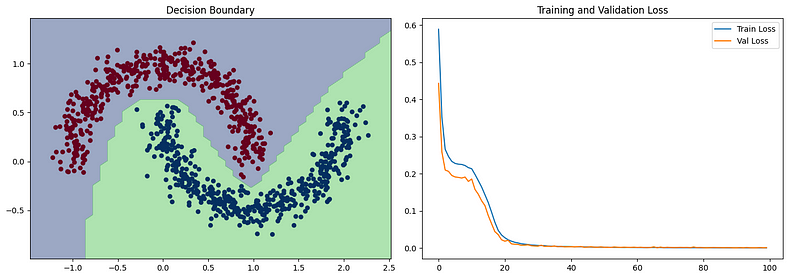
此示例說明了深度學習在從數據中學習復雜模式方面的有效性,即使使用相對簡單的網絡架構也是如此。決策邊界圖將顯示模型如何學習分離兩個類,損失圖將顯示模型隨時間的學習進度。
總結
深度學習的成功歸因于其復雜的特征學習方法、大型數據集的可用性、計算硬件的進步、算法創新、遷移學習的實用性及其固有的多功能性和可擴展性。隨著該領域的不斷發展,深度學習的進一步進步預計將釋放新的功能和應用,繼續其作為人工智能基石技術的發展軌跡。
本文來源:小Z的科研日常
-
人工智能
+關注
關注
1791文章
46845瀏覽量
237535 -
機器學習
+關注
關注
66文章
8377瀏覽量
132405 -
深度學習
+關注
關注
73文章
5492瀏覽量
120975
發布評論請先 登錄
相關推薦
NPU在深度學習中的應用
AI大模型與深度學習的關系
FPGA做深度學習能走多遠?
深度學習中的時間序列分類方法
深度學習中的無監督學習方法綜述
深度學習與nlp的區別在哪
深度學習常用的Python庫
深度學習模型訓練過程詳解
深度學習與傳統機器學習的對比
深度解析深度學習下的語義SLAM



詳解深度學習、神經網絡與卷積神經網絡的應用






 工商網監
工商網監
評論