") 如何利用chiplet技術(shù)構(gòu)建大芯片?
如何利用chiplet技術(shù)構(gòu)建大芯片?
大芯片的架構(gòu)設(shè)計(jì)對(duì)性能有重大影響,與存儲(chǔ)器訪問(wèn)模式密切相關(guān)。在內(nèi)存訪問(wèn)模式方面,與傳統(tǒng)的多核處理器設(shè)計(jì)考慮將多核集成在單個(gè)裸片上訪問(wèn)內(nèi)存不同,大芯片設(shè)計(jì)側(cè)重于多個(gè)多核裸片訪問(wèn)內(nèi)存系統(tǒng)。根據(jù)內(nèi)存訪問(wèn)模式,大芯片可以分為對(duì)稱chiplet架構(gòu)、NUMA(非均勻內(nèi)存訪問(wèn))chiplet架構(gòu)、集群chiplet架構(gòu)和異構(gòu)chiplet架構(gòu)。在接下來(lái)的章節(jié)中,我們將以利用chiplet技術(shù)構(gòu)建大芯片為例,從性能、可擴(kuò)展性、可靠性、通信等方面討論這些大芯片架構(gòu)的特點(diǎn)。
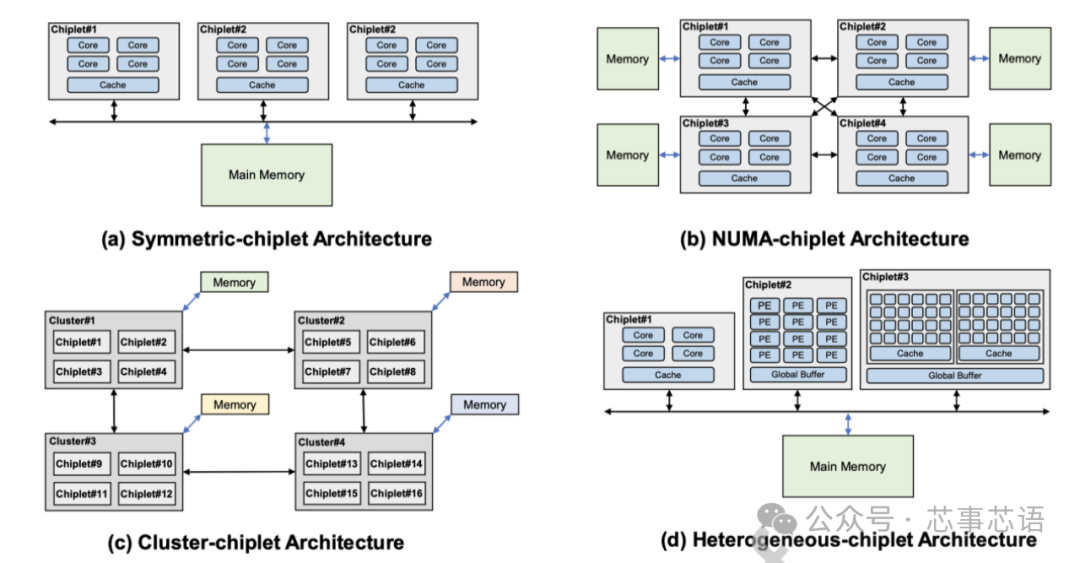
Symmetric-chiplet architecture
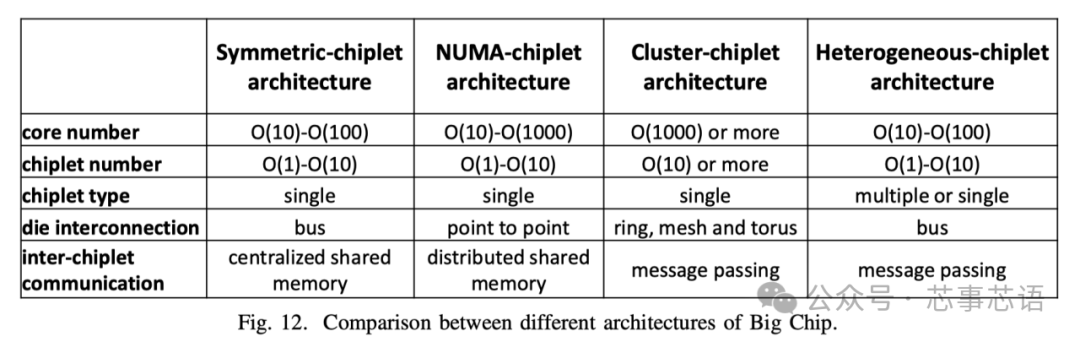
對(duì)稱小芯片架構(gòu)(Symmetric-chiplet architecture)。如圖11(a)所示,對(duì)稱chiplet架構(gòu)由許多相同的計(jì)算chiplet組成,通過(guò)路由器網(wǎng)絡(luò)或chiplet間資源(例如中介層)訪問(wèn)共享的統(tǒng)一存儲(chǔ)器或IO。Chiplet可以設(shè)計(jì)為具有本地緩存的多核結(jié)構(gòu),或者具有多個(gè)處理元件的NoC結(jié)構(gòu)。統(tǒng)一內(nèi)存可以被所有chiplet平等地訪問(wèn),這體現(xiàn)了UMA(統(tǒng)一內(nèi)存訪問(wèn))的效果。我們現(xiàn)在討論對(duì)稱小芯片架構(gòu)的三個(gè)主要優(yōu)點(diǎn)。
首先,對(duì)稱chiplet架構(gòu)允許多個(gè)chiplet執(zhí)行指令以提供高計(jì)算能力。工作負(fù)載可以分成小塊,然后分配給不同的Chiplet,以加快應(yīng)用程序的執(zhí)行速度,同時(shí)保持不同Chiplet之間的工作負(fù)載平衡。
其次,這種對(duì)稱的chiplet架構(gòu)提供了從不同chiplet到內(nèi)存的統(tǒng)一延遲,無(wú)需考慮NUMA等分布式共享內(nèi)存系統(tǒng)中的遠(yuǎn)程訪問(wèn)或內(nèi)存復(fù)制,從而節(jié)省了由于不必要的數(shù)據(jù)移動(dòng)而導(dǎo)致的延遲和能耗。
第三,對(duì)稱chiplet處理器還提供冗余設(shè)計(jì),其他chiplet可以接管故障chiplet的工作,從而提高系統(tǒng)可靠性。由于共享內(nèi)存,對(duì)稱小芯片處理器可以在不增加額外私有內(nèi)存的情況下增加小芯片的數(shù)量。然而,當(dāng)對(duì)稱chiplet架構(gòu)繼續(xù)擴(kuò)大chiplet數(shù)量時(shí),互連設(shè)計(jì)將受到物理布線的嚴(yán)重限制。解決高帶寬小芯片間通信和內(nèi)存請(qǐng)求沖突也具有挑戰(zhàn)性。請(qǐng)注意,增加Chiplet的數(shù)量可能會(huì)增加不同Chiplet對(duì)內(nèi)存的請(qǐng)求沖突,這會(huì)損害系統(tǒng)性能。平均而言,內(nèi)存帶寬由小芯片劃分。增加小芯片的數(shù)量會(huì)減少每個(gè)小芯片的分區(qū)內(nèi)存帶寬。工業(yè)界和學(xué)術(shù)界的一些設(shè)計(jì)采用了對(duì)稱芯片架構(gòu)。Apple M1 Ultra處理器[43]采用小芯片集成設(shè)計(jì),具有兩個(gè)相同的M1 Max芯片,具有統(tǒng)一的內(nèi)存架構(gòu)設(shè)計(jì)。芯片上的內(nèi)核可以訪問(wèn)高達(dá)128GB的統(tǒng)一內(nèi)存。Fotouhi [44]提出了一種基于小芯片集成的統(tǒng)一內(nèi)存架構(gòu),以克服距離相關(guān)的功耗和延遲問(wèn)題。Sharma [45]提出了一種通過(guò)板載光學(xué)互連共享統(tǒng)一存儲(chǔ)器的多芯片系統(tǒng)。
NUMA-chiplet architecture
NUMA-chiplet架構(gòu)(NUMA-chiplet architecture)。NUMA小芯片架構(gòu)包含通過(guò)點(diǎn)對(duì)點(diǎn)網(wǎng)絡(luò)或中央路由器互連的多個(gè)小芯片,并且NUMA小芯片架構(gòu)的存儲(chǔ)器系統(tǒng)由所有小芯片共享但分布在架構(gòu)中,如圖11(b)所示。Chiplet可以采用共享緩存的多核設(shè)計(jì),或者通過(guò)NoC互連的PE的設(shè)計(jì)。而且,每個(gè)chiplet可以占用自己的本地存儲(chǔ)器,例如DRAM、HBM等,這是其區(qū)別于對(duì)稱chiplet架構(gòu)的最明顯特征。盡管這些連接到不同chiplet的存儲(chǔ)器分布在系統(tǒng)中,但存儲(chǔ)器地址空間是全局共享的。共享內(nèi)存的這種分布式放置會(huì)導(dǎo)致NUMA效應(yīng),即訪問(wèn)遠(yuǎn)程內(nèi)存比訪問(wèn)本地內(nèi)存慢[46]。NUMA-chiplet架構(gòu)考慮了一些優(yōu)點(diǎn)。從單個(gè)chiplet的角度來(lái)看,每個(gè)chiplet都擁有自己的內(nèi)存,具有相對(duì)私有的內(nèi)存帶寬和容量,減少了與其他chiplet的內(nèi)存請(qǐng)求的沖突。此外,芯片與內(nèi)存的緊密放置提供了數(shù)據(jù)移動(dòng)的低延遲和低功耗。
此外,在NUMA-chiplet架構(gòu)中,通過(guò)高帶寬點(diǎn)對(duì)點(diǎn)網(wǎng)絡(luò)或路由器互連的多個(gè)chiplet可以并行執(zhí)行任務(wù),從而提高系統(tǒng)性能和兼容性。這種NUMA小芯片架構(gòu)具有很高的可擴(kuò)展性,因?yàn)槊總€(gè)小芯片都有自己的內(nèi)存。然而,隨著NUMA-chiplet架構(gòu)擴(kuò)展到更多的chiplet,設(shè)計(jì)chiplet到chiplet互連網(wǎng)絡(luò)變得具有挑戰(zhàn)性。
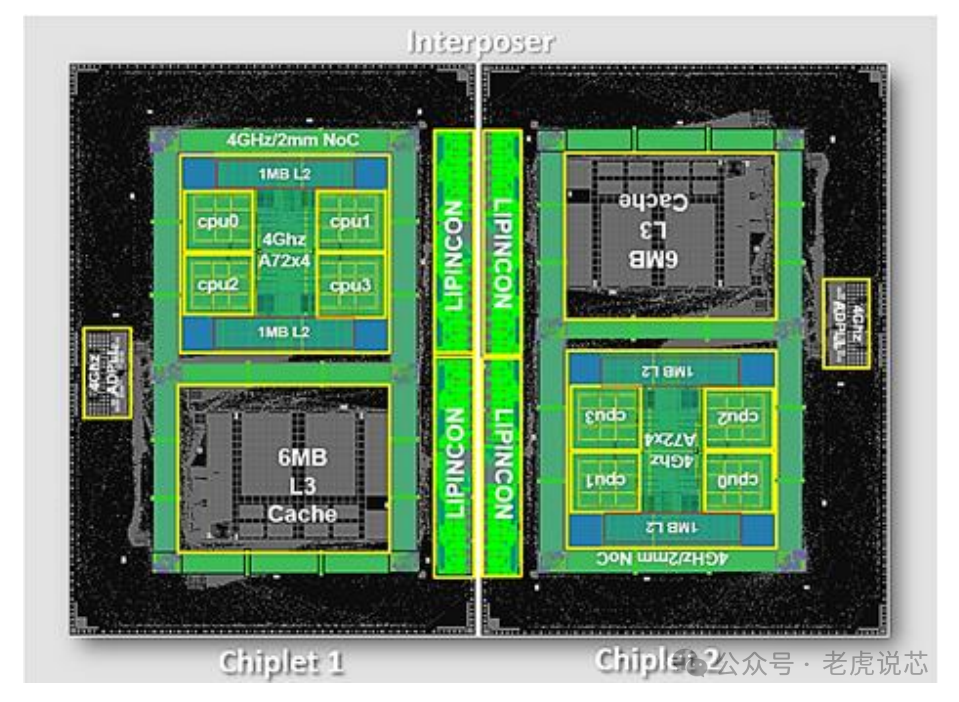
此外,隨著chiplet數(shù)量的增加,編程模型的成本和難度也隨之增加。有一些設(shè)計(jì)采用NUMAchiplet架構(gòu)。AMD的第一代EPYC處理器將四個(gè)相同的小芯片與本地內(nèi)存連接起來(lái)[39]。對(duì)內(nèi)存的本地訪問(wèn)和遠(yuǎn)程訪問(wèn)之間的延遲差異可達(dá)51ns [46]。
在AMD第二代EPYC處理器中,計(jì)算Chiplet通過(guò)IO Chiplet連接到內(nèi)存,這顯示了NUMA-chiplet架構(gòu)[34]。另一種典型的NUMAchiplet架構(gòu)設(shè)計(jì)是Intel Sapphire Rapids [47]。它由四個(gè)小芯片組成,通過(guò)MDFIO(多芯片結(jié)構(gòu)IO)連接。四個(gè)小芯片組織為2x2陣列,每個(gè)芯片充當(dāng)NUMA節(jié)點(diǎn)。Zaruba [48]架構(gòu)了4個(gè)基于RISC-V處理器的小芯片,每個(gè)小芯片都有三個(gè)分別與其他三個(gè)小芯片的鏈接,以提供非統(tǒng)一的內(nèi)存訪問(wèn)。
Cluster-chiplet architecture
集群小芯片架構(gòu)(Cluster-chiplet architecture)。如圖11(c)所示,集群chiplet架構(gòu)包含許多chiplet集群,總共有數(shù)千個(gè)核心。采用環(huán)形、網(wǎng)狀、一維/二維環(huán)面等高速或高吞吐量網(wǎng)絡(luò)拓?fù)鋪?lái)連接集群,以滿足此類超大規(guī)模系統(tǒng)的高帶寬和低延遲通信需求。每個(gè)集群由許多互連的小芯片和單獨(dú)的內(nèi)存組成,并且每個(gè)集群都可以運(yùn)行單獨(dú)的操作系統(tǒng)。集群可以通過(guò)消息傳遞的方式與其他集群進(jìn)行通信。通過(guò)高性能互連實(shí)現(xiàn)強(qiáng)大集群互連的集群-chiplet架構(gòu)顯示出高可擴(kuò)展性并提供巨大的計(jì)算能力。
作為一種可擴(kuò)展性很強(qiáng)的架構(gòu),clusterchiplet架構(gòu)是許多設(shè)計(jì)的基礎(chǔ)。IntAct [30]集成了96個(gè)內(nèi)核,這些內(nèi)核在有源中介層上分為6個(gè)小芯片。6個(gè)小芯片通過(guò)NoC連接。Tesla [49]發(fā)布了用于億級(jí)計(jì)算的Dojo系統(tǒng)微架構(gòu)。在Dojo中,一個(gè)訓(xùn)練圖塊由25個(gè)D1小芯片組成,這些小芯片排列為5x5矩陣樣式。通過(guò)2D網(wǎng)格網(wǎng)絡(luò)互連的許多訓(xùn)練塊可以形成更大的系統(tǒng)。Simba [1]通過(guò)MCM集成,利用網(wǎng)狀互連構(gòu)建了6x6小芯片系統(tǒng)。Chiplet內(nèi)的PE使用NoC連接。
Heterogeneous-chiplet architecture
異構(gòu)小芯片架構(gòu)(Heterogeneous-chiplet architecture)。異構(gòu)chiplet架構(gòu)集成了異構(gòu)chiplet,由不同種類的chiplet組成,如圖11(d)所示。同一中介層上的不同種類的chiplet可以與其他種類的chiplet互補(bǔ),協(xié)同執(zhí)行計(jì)算任務(wù)。華為鯤鵬920系列SoC[25]是基于計(jì)算chiplet、IOchiplet、AIchiplet等的異構(gòu)系統(tǒng)。Intel Lakefield[50]提出了將計(jì)算chiplet堆疊在基礎(chǔ)chiplet上的設(shè)計(jì)。計(jì)算chiplet集成了許多處理核心,包括CPU、GPU、IPU(基礎(chǔ)設(shè)施處理單元)等,基礎(chǔ)chiplet包含豐富的IO接口,包括PCIe Gen3、USB type-C等。在Ponte Vecchio [51]中,兩個(gè)基礎(chǔ)塊使用EMIB(嵌入式多芯片互連橋)互連。計(jì)算瓦片和RAMBO瓦片堆疊在每個(gè)基礎(chǔ)瓦片上。Intel Meteor Lake處理器[52]集成了GPUtile、CPUtile、IOtile和SoCtile。
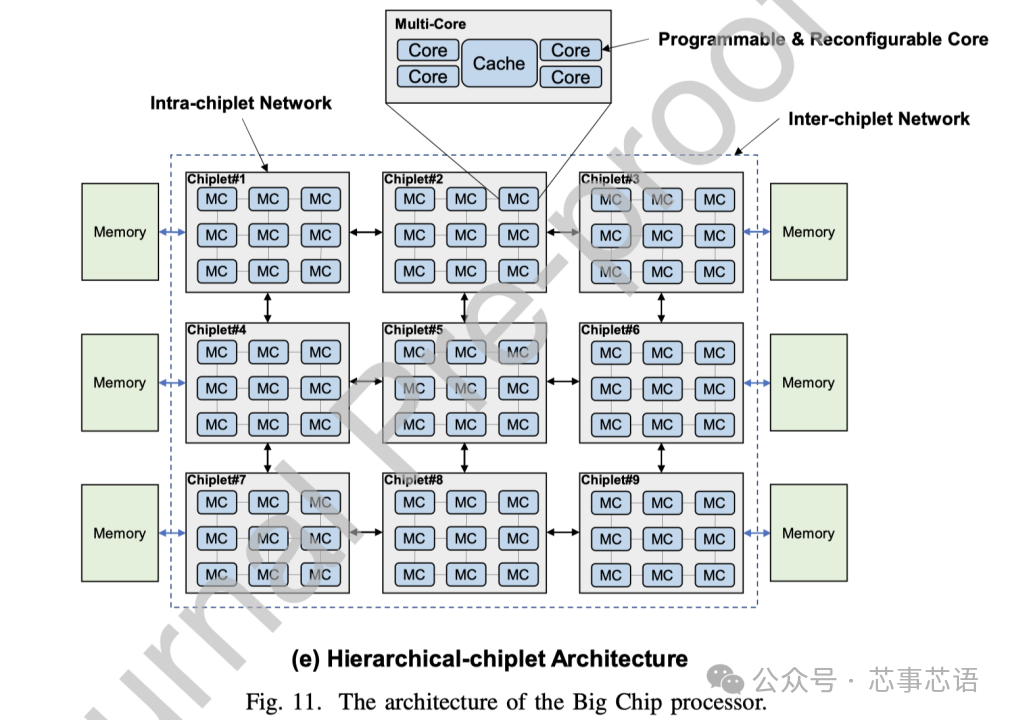
hierarchical-chiplet architecture
對(duì)于當(dāng)前和未來(lái)的億億級(jí)計(jì)算,我們預(yù)測(cè)分層chiplet架構(gòu)(hierarchical-chiplet architecture)將是一種強(qiáng)大而靈活的解決方案。如圖11(e)所示,分層chiplet架構(gòu)被設(shè)計(jì)為具有分層互連的許多內(nèi)核和許多chiplet。在chiplet內(nèi)部,內(nèi)核使用超低延遲互連進(jìn)行通信,而chiplet之間則通過(guò)先進(jìn)封裝技術(shù)的低延遲互連,從而可以在這種高可擴(kuò)展性系統(tǒng)中降低片上(let)延遲和NUMA效應(yīng)最小化。存儲(chǔ)器層次結(jié)構(gòu)包含核心存儲(chǔ)器、片內(nèi)存儲(chǔ)器和片外存儲(chǔ)器。這三個(gè)級(jí)別的內(nèi)存在內(nèi)存帶寬、延遲、功耗和成本方面有所不同。
在分層chiplet架構(gòu)的概述中,多個(gè)核心通過(guò)交叉交換機(jī)連接并共享緩存。這就形成了一個(gè)pod結(jié)構(gòu),并且pod通過(guò)chiplet內(nèi)網(wǎng)絡(luò)互連。多個(gè)pod形成一個(gè)chiplet,chiplet通過(guò)chiplet間網(wǎng)絡(luò)互連,然后連接到片外存儲(chǔ)器。需要仔細(xì)設(shè)計(jì)才能充分利用這種層次結(jié)構(gòu)。合理利用內(nèi)存帶寬來(lái)平衡不同計(jì)算層次的工作負(fù)載可以顯著提高chiplet系統(tǒng)的效率。正確設(shè)計(jì)通信網(wǎng)絡(luò)資源可以確保chiplet協(xié)同執(zhí)行共享內(nèi)存任務(wù)。
VI.構(gòu)建大芯片:我們的實(shí)現(xiàn)
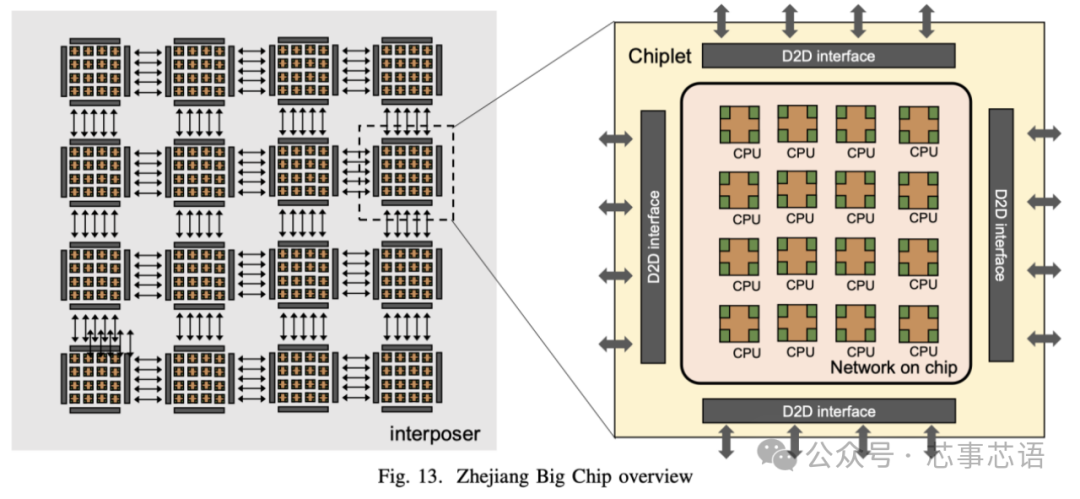
為了探索大芯片的設(shè)計(jì)和實(shí)現(xiàn)技術(shù),我們構(gòu)建并設(shè)計(jì)了一個(gè)基于16個(gè)小芯片的256核處理器系統(tǒng),名為浙江大芯片。在這里,我們介紹了擬議的Big Chip處理器。
浙江大芯片采用可擴(kuò)展的基于tile的架構(gòu),如圖13所示。該處理器由16個(gè)chiplet組成,并且有可能擴(kuò)展到100個(gè)chiplet。每個(gè)chiplet中都有16個(gè)CPU處理器,通過(guò)片上網(wǎng)絡(luò)(NOC)連接,每個(gè)tile完全對(duì)稱互連,以實(shí)現(xiàn)多個(gè)chiplet之間的通信。CPU處理器是基于RISC-V指令集設(shè)計(jì)的。此外,該處理器采用統(tǒng)一內(nèi)存系統(tǒng),這意味著任何區(qū)塊上的任何核心都可以直接訪問(wèn)整個(gè)處理器的內(nèi)存。
為了連接多個(gè)小芯片,采用了芯片間(D2D)接口。該接口采用基于時(shí)分復(fù)用機(jī)制的通道共享技術(shù)進(jìn)行設(shè)計(jì)。這種方法減少了芯片間信號(hào)的數(shù)量,從而最大限度地減少了I/O bumps和內(nèi)插器布線(interposer wiring)資源的面積開(kāi)銷,從而顯著降低了基板設(shè)計(jì)的復(fù)雜性。小芯片終止于構(gòu)建微型I/Opads的頂部金屬層。浙江大芯處理器采用22 nm CMOS工藝設(shè)計(jì)和制造。
審核編輯:劉清
-
處理器
+關(guān)注
關(guān)注
68文章
18927瀏覽量
227228 -
存儲(chǔ)器
+關(guān)注
關(guān)注
38文章
7366瀏覽量
163092 -
芯片設(shè)計(jì)
+關(guān)注
關(guān)注
15文章
980瀏覽量
54620 -
路由器
+關(guān)注
關(guān)注
22文章
3641瀏覽量
112808 -
chiplet
+關(guān)注
關(guān)注
6文章
404瀏覽量
12513
原文標(biāo)題:大芯片:挑戰(zhàn)、模型與架構(gòu)----構(gòu)建大芯片
文章出處:【微信號(hào):Rocker-IC,微信公眾號(hào):路科驗(yàn)證】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
什么是Chiplet技術(shù)?chiplet芯片封裝為啥突然熱起來(lái)
Chiplet成大芯片設(shè)計(jì)主流方式,開(kāi)啟IP復(fù)用新模式
北極雄芯開(kāi)發(fā)的首款基于Chiplet異構(gòu)集成的智能處理芯片“啟明930”
chiplet是什么意思?chiplet和SoC區(qū)別在哪里?一文讀懂chiplet
國(guó)產(chǎn)封測(cè)廠商競(jìng)速Chiplet,能否突破芯片技術(shù)封鎖?
Chiplet技術(shù)給EDA帶來(lái)了哪些挑戰(zhàn)?
半導(dǎo)體Chiplet技術(shù)及與SOC技術(shù)的區(qū)別

如何助力 Chiplet 生態(tài)克服發(fā)展的挑戰(zhàn)
Chiplet關(guān)鍵技術(shù)與挑戰(zhàn)
Chiplet究竟是什么?中國(guó)如何利用Chiplet技術(shù)實(shí)現(xiàn)突圍
chiplet和cowos的關(guān)系
Chiplet主流封裝技術(shù)都有哪些?
先進(jìn)封裝 Chiplet 技術(shù)與 AI 芯片發(fā)展
什么是Chiplet技術(shù)?Chiplet技術(shù)有哪些優(yōu)缺點(diǎn)?
什么是Chiplet技術(shù)?





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論