 Spark基于DPU Snappy壓縮算法的異構加速方案
Spark基于DPU Snappy壓縮算法的異構加速方案
一、總體介紹
1.1 背景介紹
Apache Spark是專為大規模數據計算而設計的快速通用的計算引擎,是一種與 Hadoop 相似的開源集群計算環境,但是兩者之間還存在一些不同之處,這些不同之處使 Spark 在某些工作負載方面表現得更加優越。換句話說,Spark 啟用了內存分布數據集,除了能夠提供交互式查詢外,它還可以優化迭代工作負載。Spark SQL是Spark的計算模塊之一,專門用于處理結構化的數據。Spark SQL允許用戶使用標準的SQL語句來執行SQL的查詢和讀寫,也可以使用Hive SQL來執行對Hive倉庫的查詢和讀寫。
在Spark作業中,數據通常在內存中進行計算和操作,并且通過網絡進行節點間的數據傳輸。Snappy壓縮算法已經被廣泛應用于各種大數據處理框架中,并且通常是默認的壓縮選項。在Spark系統中,用戶無需額外的配置即可使用Snappy壓縮算法,這使得它成為Spark處理數據的首選壓縮方式之一。
Snappy壓縮算法是一種同時具備非常高的壓縮速度,和較為合理的壓縮率的壓縮算法。Snappy壓縮具有速度快、占用內存小、通用性強的優點,被廣泛應用于大規模數據處理、網絡傳輸、數據庫存儲、機器學習、圖像處理等多個領域。
目前使用Snappy算法進行壓縮解壓縮的場景全部基于CPU進行,CPU除了需要維持整個計算場景的數據調度,還需要額外的算力進行壓縮解壓縮計算。CPU作為通用處理芯片,在大數據高密集型的數據計算上并無明顯優勢,這使得大部分應用場景下基于CPU運算時計算算力成為性能的主要瓶頸。
中科馭數自研的基于KPU架構的DPU芯片作為專用的數據處理芯片,在處理復雜的數據計算時相比于CPU擁有極高的性能提升。因此將Snappy壓縮解壓縮算法由CPU卸載到DPU,可以極大的提升計算性能。在復雜場景下,CPU專注于數據傳遞和計算任務調度,DPU專注于壓縮解壓縮計算。
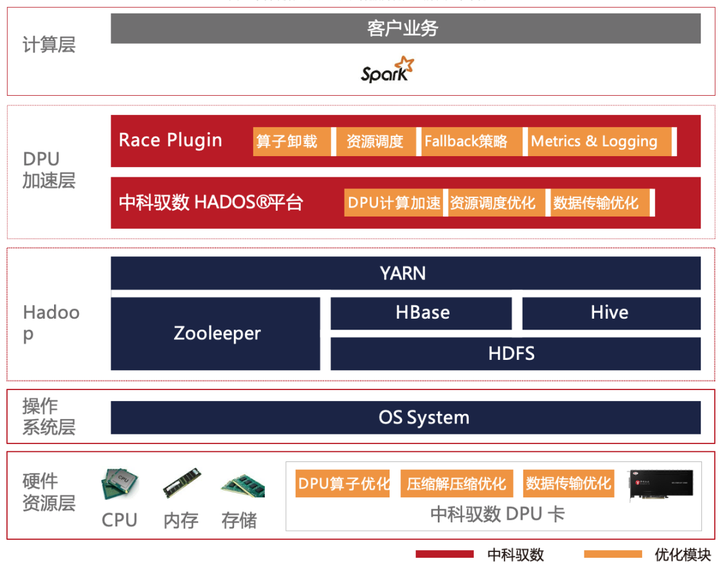
中科馭數HADOS是一款敏捷異構軟件平臺,能夠為網絡、存儲、安全、大數據計算等場景進行提速。對于大數據計算場景,HADOS可以認為是一個異構執行庫,提供了數據類型、向量數據結構、表達式計算、IO和資源管理等功能。為了發揮CPU與DPU各自的性能優勢,我們開發了HADOS-RACE項目,結合HADOS平臺,既能夠發揮CPU高速穩定的計算調度能力,又可以發揮DPU的向量化執行能力。
我們通過實驗發現,Spark讀數據的解壓和寫數據的壓縮過程,在耗時上占比比較高,將Snappy壓縮解壓縮的計算任務通過HADOS-RACE卸載到DPU上, 相比于純CPU計算,性能可提升約2倍。
本文將簡單介紹基于DPU的Snappy壓縮解壓縮計算原理,并介紹如何基于DPU和HADOS-RACE來加速Snappy壓縮解壓縮計算,為大規模數據分析和處理提供更可靠的解決方案。
1.2 挑戰和困難
在數據處理和傳輸的領域,快速且高效的壓縮算法對于提高系統性能至關重要。然而,盡管Snappy壓縮解壓縮算法以其快速的壓縮和解壓縮速度而聞名,但其卻存在一個不容忽視的挑戰,即對CPU和內存資源的大量占用,從而導致性能下降的問題。
Snappy算法在壓縮和解壓縮數據時需要進行復雜的計算和處理。雖然它以其高效的算法設計和優化而著稱,但在處理大量數據時,仍會對CPU提出較高的要求。特別是在需要快速壓縮或解壓縮大文件時,Snappy算法的CPU消耗可能會變得更為顯著,從而導致系統整體性能的下降。對于CPU性能較低的系統而言,這一挑戰尤為嚴峻,可能導致系統響應變慢,甚至造成任務阻塞和性能瓶頸。
綜上所述,Snappy壓縮解壓縮算法的高效性和速度帶來了性能優勢,但其對CPU的大量占用也成為其性能低下的一個主要挑戰。
二、整體方案
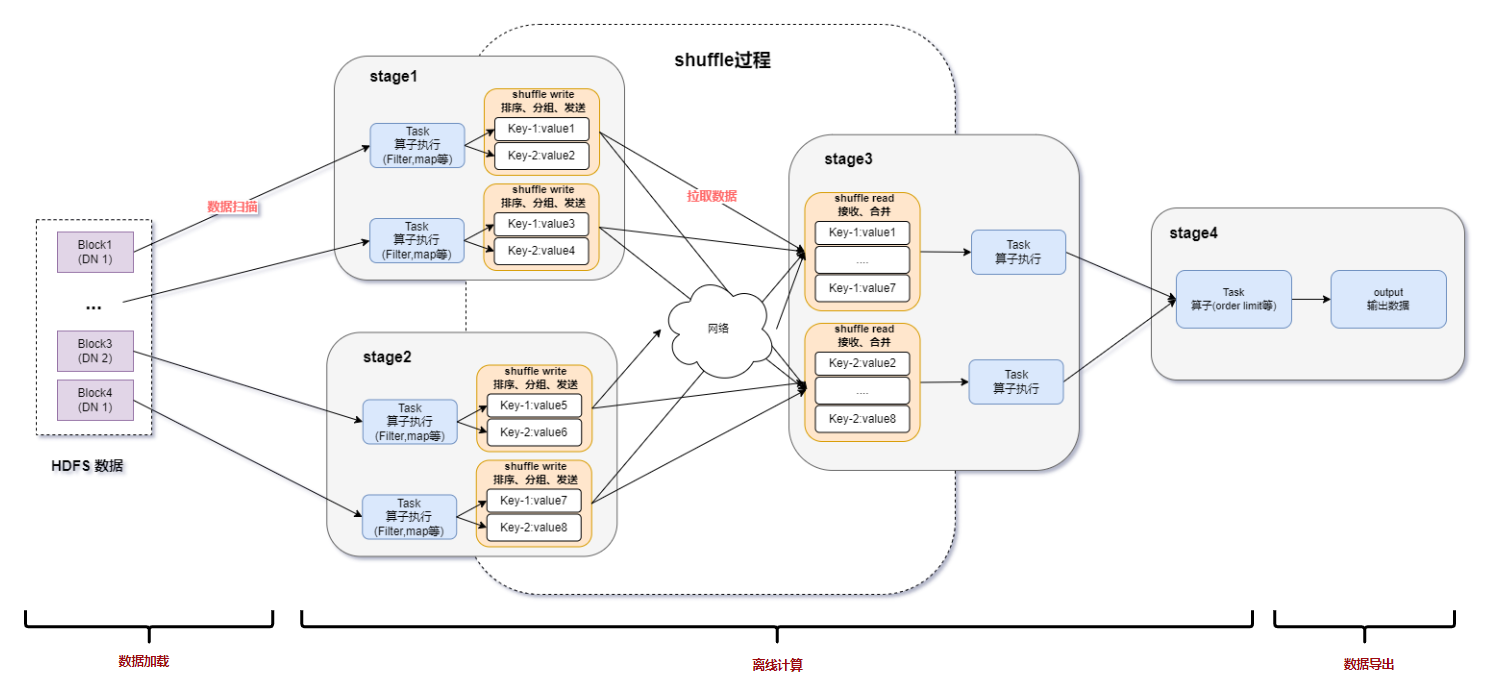
圖一:Spark基于DPU Snappy壓縮算法的異構加速整體方案
上圖所示為Spark SQL的一個涉及FileScan、Shuffle、Aggregate、OrderBy計算的完整數據流轉過程,Spark SQL的數據處理首先需要讀取HDFS分布式文件存儲系統中的Snappy壓縮文件,然后會對Snappy壓縮文件進行解壓縮處理,從而得到計算所需的數據。拿到數據后根據SQL的邏輯進行相應的計算,常見的計算比如Filter、Aggregate、Join、Order By等,經過數據計算拿到想要輸出的結果數據。最后會將結果數據寫出并按Snappy格式進行壓縮,得到的壓縮文件會寫回到HDFS中存儲。
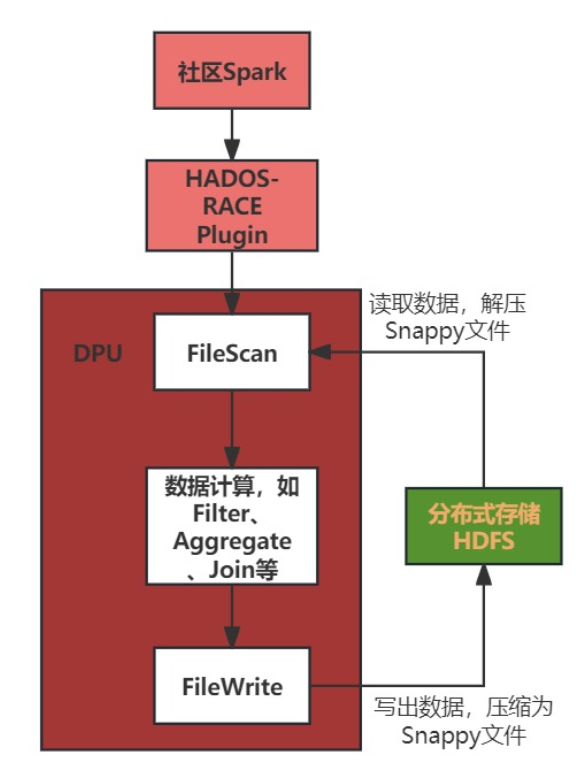
圖二:基于DPU的算子卸載加速流程
上圖所示為Spark將算子卸載到DPU進行計算的一個通用流程。首先Spark將SQL進行解析并得到最終的物理執行計劃,然后將物理執行計劃轉化為具體的算子操作,Spark會通過HADOS-RACE Plugin將具體算子卸載到DPU進行處理。在DPU處理過程中,首先需要執行FileScan算子,將數據從HDFS文件系統中讀取出來并對Snappy壓縮文件執行解壓縮操作。中間過程是對解壓縮的數據進行計算,得到最終的結果數據。最后會將結果數據按Snappy格式壓縮并導出到HDFS中存儲。
在對整個Spark計算過程進行性能分析后,發現Snappy壓縮和解壓縮是兩個耗時非常高的過程,占整個計算過程的比重較高。因此我們需要對Snappy的壓縮和解壓縮過程進行加速。
我們采用軟硬件結合的方式,在數據壓縮解壓縮鏈路的軟硬件兩大方面都進行了全面提升和加速。
在軟件方面,基于硬件對不同場景、數據量的壓縮解壓縮表現,HADOS-RACE可以靈活選擇合適的壓縮、解壓縮的硬件平臺。
在硬件方面,自研的DPU計算引擎擁有強大的Snappy壓縮、解壓縮能力,滿足日益復雜的計算場景。
三、核心加速階段
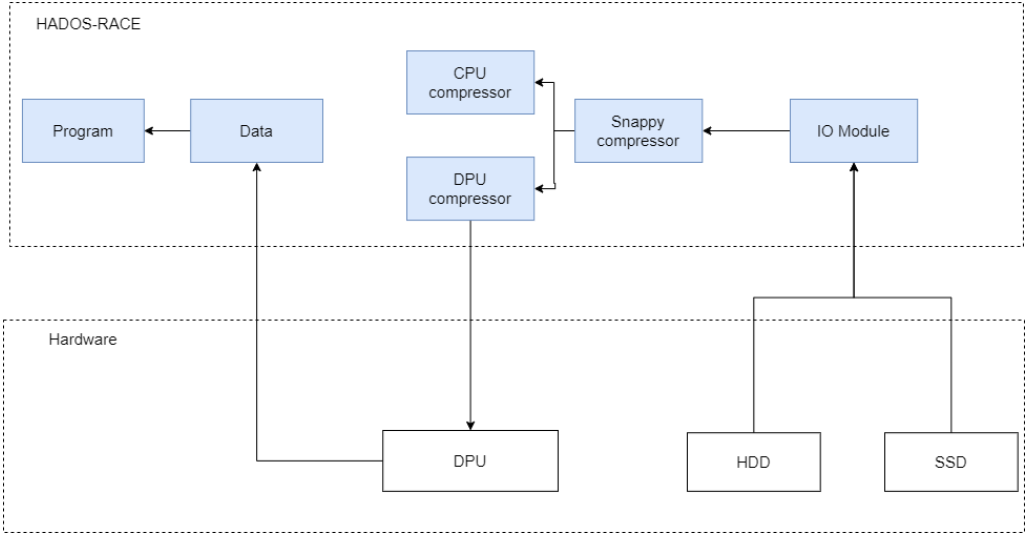
圖三:基于DPU的整體加速流程圖
加速階段如上圖所示,核心數據加速方案分為兩個階段,分別為 1.智能壓縮解壓縮策略選擇階段;2.對數據壓縮解壓縮階段。
3.1 策略選擇階段
3.1.1 面臨挑戰
在數據壓縮解壓縮過程中,壓縮解壓縮策略選擇階段是整個過程的開始。傳統的硬件體系結構中,數據的壓縮和解壓縮過程通常只能依賴CPU完成,沒有其他策略可以選擇,從而無法利用GPU、DPU等其他處理器資源。這種局限性導致數據壓縮解壓縮過程會大量占用CPU資源,從而降低系統的性能。
3.1.2 解決方案與原理
近年來,隨著數據處理領域的不斷發展和硬件技術的進步,DPU、GPU等計算資源的加入為數據壓縮解壓縮帶來了新的可能性。這些不同的硬件平臺具有各自獨特的特點和優勢,可以根據不同的場景和需求來選擇合適的硬件平臺進行數據壓縮解壓縮。
HADOS-RACE的IO模塊負責將數據從硬盤讀入內存中,并將其交由Compressor模塊進行卸載策略判斷。通過IO模塊的數據加載過程,系統能夠根據數據的特點和硬件平臺的性能選擇合適的壓縮解壓縮策略,從而實現數據處理的優化和提升。
在HADOS-RACE中,基于硬件對不同場景、數據量的性能表現,可以靈活配置壓縮解壓縮策略。例如,當數據量比較小的時候,可以直接通過CPU進行壓縮解壓縮,減少了內存和DPU硬件之間的數據傳輸,從而提高了系統的性能和效率。而對于大規模數據處理的場景,可以利用DPU等硬件資源進行并行計算,加速數據的處理速度。
3.1.3 優勢與效果
HADOS-RACE的智能策略選擇模塊在數據加載過程中發揮了重要作用,通過分析數據的特征和硬件平臺的性能,實現了對壓縮解壓縮策略的選擇。這種靈活配置的策略不僅提高了數據處理的效率,也降低了系統的資源消耗,為數據處理和應用提供了更好的支持。
我們可以根據一定的策略選擇合適的硬件平臺來進行數據壓縮解壓縮,從而實現數據壓縮解壓縮的優化和提升。這為未來的數據壓縮解壓縮領域的發展帶來了新的機遇和挑戰,也為用戶提供了更加靈活和高效的數據壓縮解壓縮方案。
3.2 壓縮解壓縮階段
3.2.1 面臨挑戰
由于CPU在數據處理方面具有較強的通用性和靈活性,因此壓縮解壓縮算法通常被設計為在CPU上執行。然而,與DPU相比,CPU的并行處理能力相對較弱,無法充分發揮硬件資源的潛力。在大規模數據處理的場景下,數據壓縮解壓縮過程可能成為CPU的瓶頸,導致系統性能下降。此外,由于數據壓縮解壓縮是一個計算密集型任務,當系統中同時存在其他需要CPU資源的任務時,壓縮解壓縮過程可能會與其他任務產生競爭,進一步加劇了CPU資源的緊張程度,導致系統整體的響應速度變慢。
3.2.2 解決方案與原理
在傳統的硬件體系結構中,數據的壓縮和解壓縮過程通常只能依賴CPU完成。然而,隨著芯片技術的不斷發展和創新,現代計算機系統已經實現了DPU等計算資源的利用,從而在數據處理領域帶來了革命性的變化。DPU的并行計算能力遠遠超過CPU,使得它成為處理大規模數據的理想選擇。近年來,隨著DPU技術的日益成熟和運用,數據壓縮解壓縮過程已經可以借助DPU來執行,從而大大減少了對CPU資源的占用,提升了系統的性能和效率。
隨著DPU芯片技術的不斷發展和成熟,DPU已經成為了處理大規模數據的強大工具。DPU的并行計算能力遠遠超過CPU,能夠同時處理大量數據,極大地加快了數據處理的速度。因此,現在可以利用DPU來執行數據的壓縮和解壓縮過程,從而減少了對CPU資源的占用,提升了系統的性能和效率。
3.2.3 優勢與效果
DPU在數據壓縮解壓縮中的應用,主要體現在以下幾個方面:
首先,DPU能夠同時處理多個數據塊,實現真正的并行計算。在數據壓縮解壓縮過程中,可以將大規模數據劃分成多個小塊,然后通過DPU同時對這些數據塊進行壓縮或解壓縮,極大地提高了處理速度。
此外,DPU的計算能力可以輕松處理大規模數據,從而滿足了現代大數據處理的需求。可以利用DPU來執行數據的壓縮和解壓縮過程,從而提高系統的性能和效率。
綜上所述,利用DPU進行數據壓縮解壓縮等算力的卸載,已經成為了計算機系統的重要趨勢。通過充分利用DPU的并行計算能力和卡上內存,可以大大減少對CPU資源的占用,提升系統的性能和效率。相信在未來的snappy數據壓縮解壓縮領域,DPU將會發揮越來越重要的作用。
四、加速效果
基于目前HADOS-RACE已經實現的Snappy壓縮解壓縮方案,制定了對應的性能測試計劃。首先生成snappy測試數據,使用基于CPU和DPU的Spark分別對數據進行處理,記錄各自的Snappy壓縮解壓縮階段和Spark整體端到端的耗時和吞吐。執行的測試語句為:select * from table where a1 is not null and a2 is not null(盡量減少中間的計算過程,突出Snappy壓縮解壓縮的過程)。
4.1 壓縮解壓縮加速效果
單獨分析Snappy壓縮解壓縮階段,基于CPU的Snappy解壓縮,吞吐量為300MB/s。而將解壓縮任務卸載到DPU后,DPU核內計算的吞吐量可達到1585MB/s。可以看到,基于DPU進行Snappy解壓縮,相比基于CPU進行Snappy解壓縮,性能可提升約5倍。
對于系統整體而言,壓縮解壓縮計算的輸入數據和輸出數據,如果需要傳輸到CPU繼續做計算,則有額外的PCIe數據傳輸的時間損耗,由于不同的數據量及壓縮比帶來的整體效果差別較大,所以以下測試數據僅供參考。表格中的DPU數據均為結合PCIe傳輸消耗的結果。壓縮前的數據量均為128MB,但是由于數據內容不同導致壓縮比不同,進而導致吞吐的不同,從以下測試結果中可以看出,壓縮率越大,計算占比越高,DPU表現的越好。
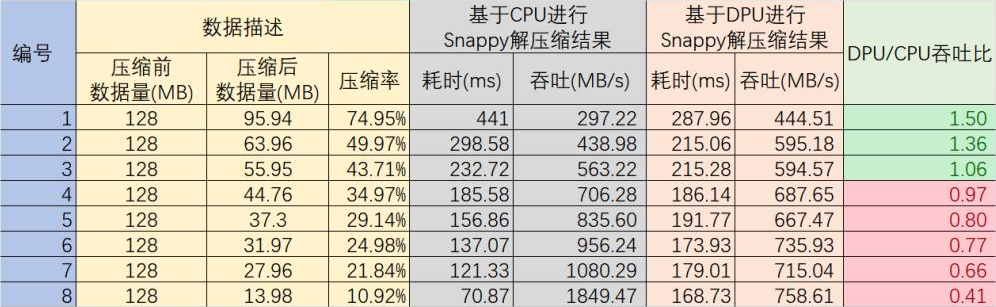
圖四:基于DPU的Snappy壓縮解壓縮方案測試結果
4.2 端到端整體加速效果
基于CPU的Spark計算過程總體比基于DPU的Spark計算過程耗時減少了約50%。相當于基于DPU的端到端執行性能是基于CPU端到端性能的兩倍。詳細測試結果如下所示:
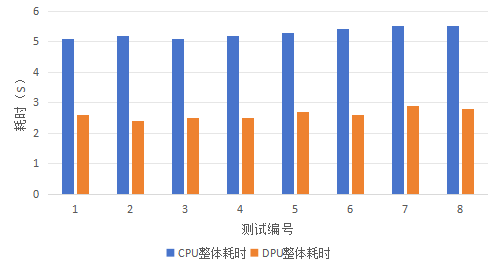
圖五:基于DPU加速的端到端方案測試結果
4.3 結果分析
從測試結果中可以看到,在壓縮率約為50%至70%時,基于DPU進行Snappy解壓縮相比基于CPU進行Snappy解壓縮,性能有1.1至1.5倍提升,其他情況下解壓縮性能均有下降。造成這一現象的原因是,此次測試沒有對DPU進行流程優化,從主機向DPU板卡傳輸數據時,DPU并沒有并發執行計算任務。DPU的計算流程還有著極大的優化空間,優化后,DPU中的計算任務可以以流水線的形式進行調度,則數據傳輸過程將不會占用整體計算時間。
從Spark整個執行過程來看,基于DPU的Spark計算過程總體比基于CPU的Spark計算過程有2倍的性能提升。單獨從Snappy壓縮解壓縮階段看,在壓縮率20%至100%之間,基于DPU的Snappy解壓縮,相比于基于CPU的Snappy解壓縮,性能上可以有1.5至5倍的性能提升。
五、未來規劃
5.1 現有優勢
性能方面,得益于DPU做算力卸載的高效性和智能策略選擇算法,相對于傳統壓縮解壓縮方式,基于DPU進行snappy壓縮解壓縮具備較為明顯的性能優勢。
資源占用方面,得益于將CPU的計算卸載到DPU上執行,服務器的CPU、內存、IO和網絡資源占用等方面都有明顯降低。特別是CPU資源,可以將壓縮解壓縮卸載到DPU的同時完成其他數據計算處理任務。
5.2 未來規劃
優化和完善現有功能,繼續增加其他算力的卸載。
未來計劃在存算分離場景下適配snappy壓縮解壓縮功能。從遠端讀取數據后,首先數據會直接經過壓縮或解壓縮計算,從DPU卡出來的數據已經是經過壓縮解壓縮的,無需多余的數據傳輸和計算。
審核編輯 黃宇
-
算法
+關注
關注
23文章
4599瀏覽量
92638 -
SQL
+關注
關注
1文章
759瀏覽量
44069 -
DPU
+關注
關注
0文章
354瀏覽量
24127 -
SPARK
+關注
關注
1文章
105瀏覽量
19874
發布評論請先 登錄
相關推薦
【BearPi-Pico H3863星閃開發板體驗連載】LZO壓縮算法移植
Huffman壓縮算法概述和詳細流程
IaaS+on+DPU(IoD)+下一代高性能算力底座技術白皮書
Spark基于DPU的Native引擎算子卸載方案

“Spark+Hive”在DPU環境下的性能測評 | OLAP數據庫引擎選型白皮書(24版)DPU部分節選
FPGA壓縮算法有哪些

基于門控線性網絡(GLN)的高壓縮比無損醫學圖像壓縮算法
明天線上見!DPU構建高性能云算力底座——DPU技術開放日最新議程公布!
如何利用DPU加速Spark大數據處理? | 總結篇
中科馭數DPU技術開放日秀“肌肉”:云原生網絡、RDMA、安全加速、低延時網絡等方案組團亮相

基于DPU和HADOS-RACE加速Spark 3.x





 工商網監
工商網監
評論