") 盤點國產(chǎn)GPU在支持大模型應(yīng)用方面的進展
盤點國產(chǎn)GPU在支持大模型應(yīng)用方面的進展
電子發(fā)燒友網(wǎng)報道(文/李彎彎)目前談到GPU,大家首先想到的應(yīng)該就是英偉達了。近一年多時間來,隨著大模型的發(fā)展,英偉達GPU的強大實力可謂無人不知。而相比之下,國產(chǎn)GPU的聲勢就小了許多。事實上,近些年國內(nèi)也有不少GPU企業(yè)在逐步成長,雖然在大模型的訓(xùn)練和推理方面,與英偉達GPU差距極大,但是不可忽視的是,不少國產(chǎn)GPU企業(yè)也在AI的訓(xùn)練和推理應(yīng)用上找到位置。
景嘉微
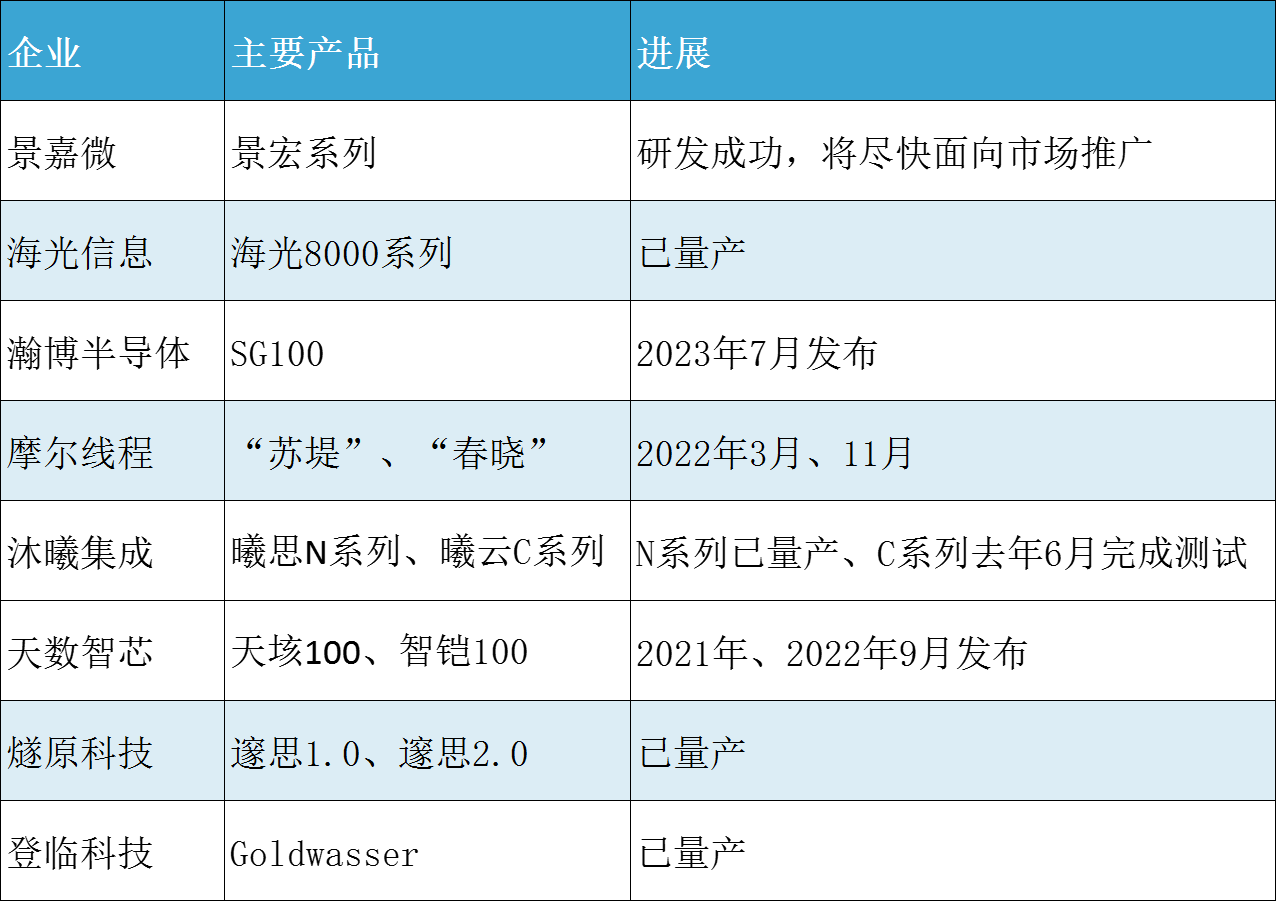
景嘉微是國產(chǎn)GPU市場的主要參與者,目前已經(jīng)完成JM5、JM7和JM9系列三代圖形處理芯片的研發(fā),并成功實現(xiàn)產(chǎn)業(yè)化。
2024年3月12日,該公司發(fā)布公告稱,其面向AI 訓(xùn)練、AI推理、科學(xué)計算等應(yīng)用領(lǐng)域的景宏系列高性能智算模塊及整機產(chǎn)品研發(fā)成功,并將盡快面向市場推廣。
根據(jù)公告,景宏系列支持INT8、FP16、FP32、FP64等混合精度運算,支持全新的多卡互聯(lián)技術(shù)進行算力擴展,適配國內(nèi)外主流CPU、操作系統(tǒng)及服務(wù)器廠商,能夠支持當(dāng)前主流的計算生態(tài)、深度學(xué)習(xí)框架和算法模型庫,大幅縮短用戶適配驗證周期。
海光信息
海光信息的產(chǎn)品包括海光通用處理器(CPU)和海光協(xié)處理器(DCU)。海光DCU屬于GPGPU 的一種,采用“類CUDA”通用并行計算架構(gòu),能夠較好地適配、適應(yīng)國際主流商業(yè)計算軟件和人工智能軟件。
海光8000系列具有全精度浮點數(shù)據(jù)和各種常見整型數(shù)據(jù)計算能力,具有最多64個計算單元,能夠充分挖掘應(yīng)用的并行性,發(fā)揮其大規(guī)模并行計算的能力,快速開發(fā)高能效的應(yīng)用程序。
海光DCU主要部署在服務(wù)器集群或數(shù)據(jù)中心,為應(yīng)用程序提供性能高、能效比高的算力,支撐高復(fù)雜度和高吞吐量的數(shù)據(jù)處理任務(wù)。在AIGC持續(xù)快速發(fā)展的時代背景下,海光DCU 能夠完整支持大模型訓(xùn)練,實現(xiàn)LLaMa、GPT、Bloom、ChatGLM、悟道、紫東太初等為代表的大模型的全面應(yīng)用,與國內(nèi)包括文心一言等大模型全面適配,達到國內(nèi)領(lǐng)先水平。
瀚博半導(dǎo)體
瀚博半導(dǎo)體成立于2018年12月,是一家GPU芯片提供商,致力于為人工智能核心算力和圖形渲染、內(nèi)容生成、AIGC提供全棧式芯片解決方案。瀚博目前擁有自主研發(fā)的核心IP以及兩代GPU芯片,并衍生AI、渲染、視頻三大產(chǎn)品線。
據(jù)介紹,其2023年推出的第二代GPU SG100芯片,采用7nm先進制程,具備業(yè)界一流的渲染性能,同時兼具低延時高吞吐的AI算力和強大的視頻處理能力,可廣泛支持?jǐn)?shù)字孿生、數(shù)字人、云桌面、云手機、云游戲、云渲染、工業(yè)軟件等多領(lǐng)域應(yīng)用。
同時針對大模型時代算力需求,瀚博還首發(fā)了LLM大模型AI加速卡VA1L,具備200 TOPS INT8/72 TFLOPS FP16算力,并支持ChatGPT、LLaMA、Stable Diffusion等主流AIGC網(wǎng)絡(luò)模型。同時,瀚博更重磅推出AIGC大模型一體機,共使用8張LLM大模型AI加速卡VA1L,支持512GB顯存,進而支持1750億參數(shù)的大模型。
摩爾線程
摩爾線程成立于2020年10月,是一家以全功能GPU芯片設(shè)計為主的集成電路公司。該公司已經(jīng)發(fā)布兩款自主研發(fā)的GPU芯片產(chǎn)品,2022年3月發(fā)布GPU產(chǎn)品“蘇堤”,11月又發(fā)布了第二款GPU芯片“春曉”。
“春曉”內(nèi)置MUSA架構(gòu)通用計算核心以及張量計算核心,可支持FP32、FP16和INT8三種計算精度;相較于其首款自研的GPU“蘇堤”,“春曉”內(nèi)置的四大計算引擎都進行了全面升級,性能顯著提升,AI計算加速平均提升4倍。
沐曦集成
沐曦成立于2020年9月,致力于為異構(gòu)計算提供全棧GPU芯片及解決方案,可廣泛應(yīng)用于智算、智慧城市、云計算、自動駕駛、數(shù)字孿生、元宇宙等前沿領(lǐng)域。
沐曦集成目前有三條產(chǎn)品線規(guī)劃,曦思N系列GPU產(chǎn)品用于智算推理,曦云C系列GPU產(chǎn)品用于通用計算,曦彩G系列GPU產(chǎn)品用于圖形渲染。據(jù)沐曦此前對外透露,公司N系列云端推理芯片已經(jīng)量產(chǎn)出貨,C系列于2023年6月13日回片并完成測試。
沐曦產(chǎn)品均采用完全自主研發(fā)的GPU IP,擁有完全自主知識產(chǎn)權(quán)的指令集和架構(gòu),配以兼容主流GPU生態(tài)的完整軟件棧(MXMACA),具備高能效和高通用性的天然優(yōu)勢,能夠為客戶構(gòu)建軟硬件一體的全面生態(tài)解決方案。
天數(shù)智芯
天數(shù)智芯致力于開發(fā)自主可控、國際領(lǐng)先的高性能通用GPU產(chǎn)品,探索通用GPU趕超發(fā)展道路,加快建設(shè)自主產(chǎn)業(yè)生態(tài),為全產(chǎn)業(yè)提供高端算力解決方案。
天數(shù)智芯2018年正式啟動通用GPU芯片設(shè)計,在2021年發(fā)布了其通用GPU“天垓100”芯片及天垓100加速卡,2021年10月宣布天垓100正式進入量產(chǎn)環(huán)節(jié)。2022年9月,又發(fā)布了首款7nm制程的云端推理通用GPU產(chǎn)品“智鎧100”。
智鎧 100 芯片支持 FP32、FP16、INT8 等多精度混合計算,實現(xiàn)了指令集增強、算力密度提升、計算存儲再平衡,支持多種視頻規(guī)格解碼。
燧原科技
燧原科技專注人工智能領(lǐng)域云端和邊緣算力產(chǎn)品,致力為通用人工智能打造算力底座,提供原始創(chuàng)新、具備自主知識產(chǎn)權(quán)的AI加速卡、系統(tǒng)集群和軟硬件解決方案。產(chǎn)品可廣泛應(yīng)用于泛互聯(lián)網(wǎng)、智算中心、智慧城市,智慧金融、科學(xué)計算、自動駕駛等多個行業(yè)和場景。
該公司于2018年3月成立,僅用18個月時間,即發(fā)布第一代AI芯片邃思1.0,又于2021年7月發(fā)布邃思2.0。到現(xiàn)在,該公司已經(jīng)在兩款芯片的基礎(chǔ)上迭代了兩代訓(xùn)練和推理產(chǎn)品,第三代產(chǎn)品也已經(jīng)在研發(fā)中。并且,燧原科技已經(jīng)在科研領(lǐng)域和智慧城市的應(yīng)用中落地了訓(xùn)練和推理的超千卡算力集群。
登臨科技
登臨科技專注于芯片研發(fā)與技術(shù)創(chuàng)新,致力于打造云邊端一體、軟硬件協(xié)同的前沿芯片產(chǎn)品和平臺化基礎(chǔ)系統(tǒng)軟件。公司自主創(chuàng)新的GPU+(基于GPGPU的軟件定義的片內(nèi)異構(gòu)計算架構(gòu)),在兼容CUDA/OpenCL在內(nèi)的編程模型和軟件生態(tài)的基礎(chǔ)上,通過架構(gòu)創(chuàng)新,完美解決了通用性和高效率的雙重難題。
登臨首款基于GPU+的創(chuàng)新AI計算加速器Goldwasser已規(guī)模化運用在各個應(yīng)用場景。未來將繼續(xù)秉承核心IP全自研的架構(gòu)實現(xiàn),以AI計算為主線,以創(chuàng)新為靈魂,加強核心IP自主研發(fā),加速產(chǎn)品在高級自動駕駛,圖形加速等相關(guān)領(lǐng)域的開拓創(chuàng)新和商業(yè)化進程。
寫在最后
GPU最初是為解決CPU在圖形處理領(lǐng)域性能不足的問題而誕生的,早期它多用于圖形處理,而如今大家談到用于AI訓(xùn)練和推理多是通用計算GPGPU,它脫胎于早期的圖形處理器。
上述談到的GPU企業(yè),有些既有用于AI計算的GPU產(chǎn)品,也有用于圖形處理的產(chǎn)品,如景嘉微,是國內(nèi)較早入局GPU市場的企業(yè),之前已經(jīng)發(fā)布過多個系列的產(chǎn)品,主要用于圖形處理。近期才公布面向AI 訓(xùn)練、AI推理、科學(xué)計算等應(yīng)用領(lǐng)域的GPU產(chǎn)品研發(fā)成功。
如沐曦入局GPU市場較晚,像用于AI訓(xùn)練、推理的產(chǎn)品,以及用于圖形渲染的產(chǎn)品都有規(guī)劃,不過它是先推出了用于AI計算的GPU芯片,而用于圖形渲染的產(chǎn)品預(yù)計要到2025年才發(fā)布。像瀚博半導(dǎo)體、摩爾線程等也是面向圖形渲染和AI計算都有產(chǎn)品。
面對現(xiàn)在關(guān)注比較多的大模型的訓(xùn)練和推理,國產(chǎn)GPU企業(yè)也在積極跟進,如海光DCU就能夠完整支持大模型訓(xùn)練,實現(xiàn)LLaMa、GPT、Bloom、ChatGLM、悟道、紫東太初等為代表的大模型的全面應(yīng)用;瀚博基于新一代GPU芯片首發(fā)了LLM大模型AI加速卡VA1L,能支持ChatGPT、LLaMA、Stable Diffusion等主流AIGC網(wǎng)絡(luò)模型。天數(shù)智芯、燧原科技等也都在支持大模型的應(yīng)用上取得進展。
-
gpu
+關(guān)注
關(guān)注
28文章
4700瀏覽量
128694 -
大模型
+關(guān)注
關(guān)注
2文章
2322瀏覽量
2479
發(fā)布評論請先 登錄
相關(guān)推薦
PyTorch GPU 加速訓(xùn)練模型方法
GPU深度學(xué)習(xí)應(yīng)用案例
AI大模型的最新研究進展
國產(chǎn)光耦:實際應(yīng)用和市場進展
大模型發(fā)展下,國產(chǎn)GPU的機會和挑戰(zhàn)

大數(shù)據(jù)在軍事方面的應(yīng)用
大數(shù)據(jù)在軍事方面的應(yīng)用有哪些
大模型快速發(fā)展,GPU IP有何作用
摩爾線程與無問芯穹在國產(chǎn)GPU上首次實現(xiàn)大模型實訓(xùn)
大模型時代,國產(chǎn)GPU面臨哪些挑戰(zhàn)

國產(chǎn)GPU在AI大模型領(lǐng)域的應(yīng)用案例一覽

NVIDIA在加速識因智能AI大模型落地應(yīng)用方面的重要作用介紹
FPGA在深度學(xué)習(xí)應(yīng)用中或?qū)⑷〈?b class='flag-5'>GPU
揭秘GPU: 高端GPU架構(gòu)設(shè)計的挑戰(zhàn)






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論