 深入理解 Sora 的技術原理
深入理解 Sora 的技術原理
OpenAI 發布的視頻生成模型 Sora(https://openai.com/sora),能根據文本生成長達一分鐘的高質量視頻,理論上支持任意分辨率,如 1920x1080 、1080x1920 ,生成能力遠超此前只能生成 25 幀 576x1024 圖像的頂尖視頻生成模型 Stable Video Diffusion。
一起公布的,還有一篇非常簡短的技術報告,報告大致介紹了 Sora 的架構及應用場景,并未對模型的原理做過多的介紹。
筆者參考了大量的資料,試著深入理解 Sora 的技術原理,最終將 Sora 生成視頻的原理總結成以下大致的步驟:
通過收集大量不同分辨率不同時長的視頻,并對視頻進行降維處理得到視頻的潛在空間數據,并在潛在空間中進行文本標注與訓練。
使用 DALLE3 的重標注技術,對人工標注的文本進行訓練,生成能更加詳細描述視頻的標注信息。
視頻生成時,獲取隨機噪聲視頻,通過訓練的視頻壓縮網絡,將噪聲視頻壓縮成低維度的潛在空間數據,以便更好的處理視頻數據。
將壓縮后的潛在空間數據分解成空間時間補丁 Patches,這些補丁包含了視頻中空間和時間的關系,并將這些補丁轉為一維的 Tokens 數據。
將Tokens數據提交給經過擴散模型訓練后的Transformer(DiT),利用 Transformer 的注意力機制,時刻關注文本提示詞中的關鍵信息,結合擴散模型(Diffusion Model)對 Tokens 數據進行去噪聲,并循環采樣觀察去噪音后的結果數據是否符合提示詞的要求。
將去除噪音后的結果數據,利用視頻解碼器進行解碼,將低維潛在空間數據還原成原始視頻數據,這里可以實現不同分辨率的視頻解碼。
如果你不想查看冗余的細節,看到這里就可以結束了,如果你還希望了解相關的細節,可以繼續往下看,可能有理解不全面的地方歡迎大家補充交流。
一
文本生成圖片的流程
在理解文本生成視頻的原理之前,我們可以先回顧下文本生成圖片的原理,筆者的另一篇文章有做過相關介紹:AIGC 文生圖原理與實踐分享
本文我們不討論傳統的通過對抗網絡生成圖片的方式,我們主要討論的是基于擴散模型生成圖片的方式,開源的 Stable Diffusion 就是基于 LDM,即 Latent Diffusion Model(潛在的擴展模型)實現的,另外 Stable Diffusion 通過引入 Transformer 架構實現了對提示詞的支持,能夠在去除圖片噪音的過程中進行精確的控制。
潛在的擴散模型
Stable Diffusion 背后的技術方案被稱為 Latent Diffusion Model,即潛在的擴散模型,此外 Stable Diffusion 模型在原始的 UNet 模型中加入了 Transformer 結構,這么做可謂一舉兩得,因為 Transformer 結構不但能提升噪聲去除效果,還是實現 Prompt 控制圖像內容的關鍵技術。
在深度學習領域中,潛在空間(Latent Space)是指模型學習到的表示數據的抽象空間。這個潛在空間通常是一個低維的向量空間,其中每個點(向量)代表著模型對輸入數據的一種表示或特征。潛在空間的概念在各種生成模型和表示學習方法中被廣泛應用。
以下是潛在空間對模型的作用:
數據的抽象表示:
潛在空間可以被視為對輸入數據的一種抽象表示。通過學習到的潛在空間可以更好地捕捉輸入數據的特征和結構,有助于模型更高效地學習和生成數據。
降維和去噪:
潛在空間通常是一個低維空間,相比原始數據空間具有更低的維度。通過將數據映射到潛在空間,可以實現數據的降維和去噪,將數據的主要特征和模式表示在更緊湊的空間中。
生成和重建:
在生成模型中,潛在空間扮演著重要角色,可以在潛在空間中生成新的數據樣本。模型可以從潛在空間中采樣并解碼生成具有逼真特征的數據樣本,這種生成過程通常通過解碼器(Decoder)實現。
插值和操作:
在潛在空間中,向量表示不同的數據特征或屬性,可以通過向量之間的插值或操作來探索數據空間中的變化和關系。例如,通過在潛在空間中沿著不同方向移動向量,可以觀察到在數據生成過程中對應的變化。
擴散模型的一個大概的過程可以描述為:對原始圖片不斷的加噪音可以得到一張噪聲圖,然后再對噪聲圖不斷的去除噪音的同時再添加其他信息,就可以得到一張新圖片。
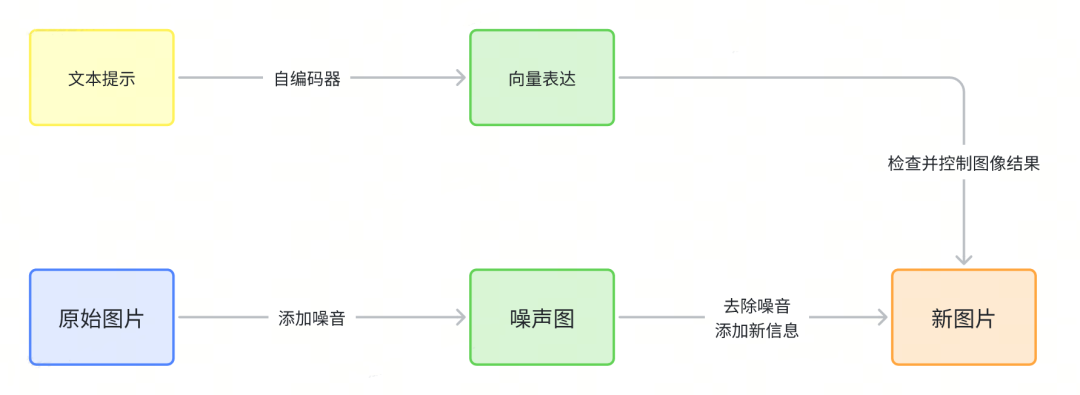
Stable Diffusion 生成圖片的大致流程如下:
Stable Diffusion 使用一個新穎的文本編碼器(OpenCLIP),將文本輸入轉換為一個向量表示。這個向量表示可以捕捉文本的語義信息,并與圖像空間對齊。
Stable Diffusion 使用一個擴散模型(Diffusion Model),將一個隨機噪聲圖像逐漸變換為目標圖像。擴散模型是一種生成模型,可以從訓練數據中學習出一個概率分布,并從中采樣出新的數據。
在擴散過程中,Stable Diffusion 利用文本向量和噪聲圖像作為條件輸入,給出每一步變換的概率分布。這樣,Stable Diffusion 可以根據文本指導噪聲圖像向目標圖像收斂,并保持圖像的清晰度和連貫性。
最后,Stable Diffusion 使用一個超分辨率放大器(Upscaler Diffusion Model),將生成的低分辨率圖像放大到更高的分辨率。超分辨率放大器也是一個擴散模型,可以從低分辨率圖像中恢復出細節信息,并增強圖像質量。
以下是 Latent Diffusion 模型的技術架構:
Latent Diffusion Models 整體框架如圖,首先需要訓練好一個自編碼模型(AutoEncoder,包括一個編碼器 ε 和一個解碼器 δ )。這樣一來,我們就可以利用編碼器對圖片進行壓縮,然后在潛在表示空間上做 Diffusion 操作,最后我們再用解碼器恢復到原始像素空間即可,論文將這個方法稱之為感知壓縮(Perceptual Compression)。個人認為這種將高維特征壓縮到低維,然后在低維空間上進行操作的方法具有普適性,可以很容易推廣到文本、音頻、視頻等領域。
在潛在表示空間上做 Diffusion 操作其主要過程和標準的擴散模型沒有太大的區別,所用到的擴散模型的具體實現為 Time-Conditional UNet。但是有一個重要的地方是論文為 Diffusion 操作引入了條件機制(Conditioning Mechanisms),通過 Cross-Attention 的方式來實現多模態訓練,使得條件圖片生成任務也可以實現。
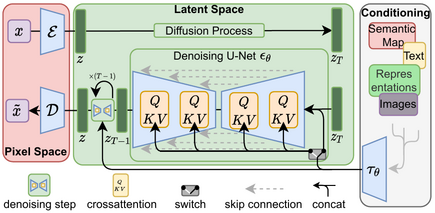
https://github.com/CompVis/latent-diffusion
Transformer架構
Transformer 架構是 2017 年 6 月由 Google 提出的,是一種基于自注意力機制(Self-Attention)的模型,它有效解決了 RNN 類方法的并行計算和長時依賴兩大痛點。原本研究的重點是翻譯任務,隨后推出了幾個有影響力的模型,以下是 Transformer 模型簡短歷史中的一些關鍵節點:
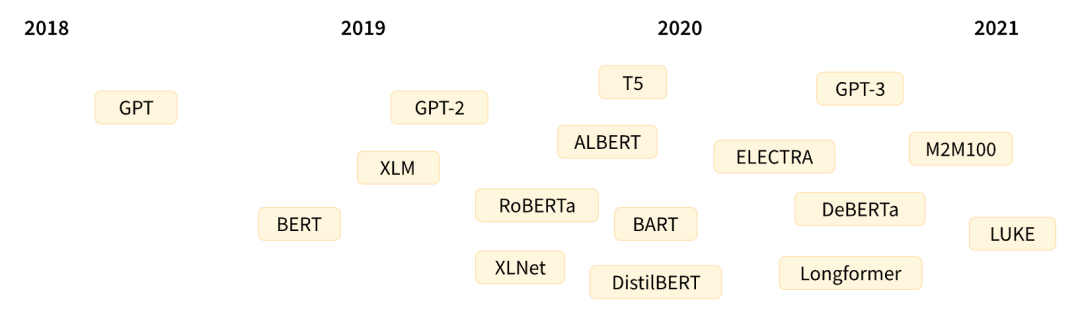
Transformer 的架構設計如下圖所示:
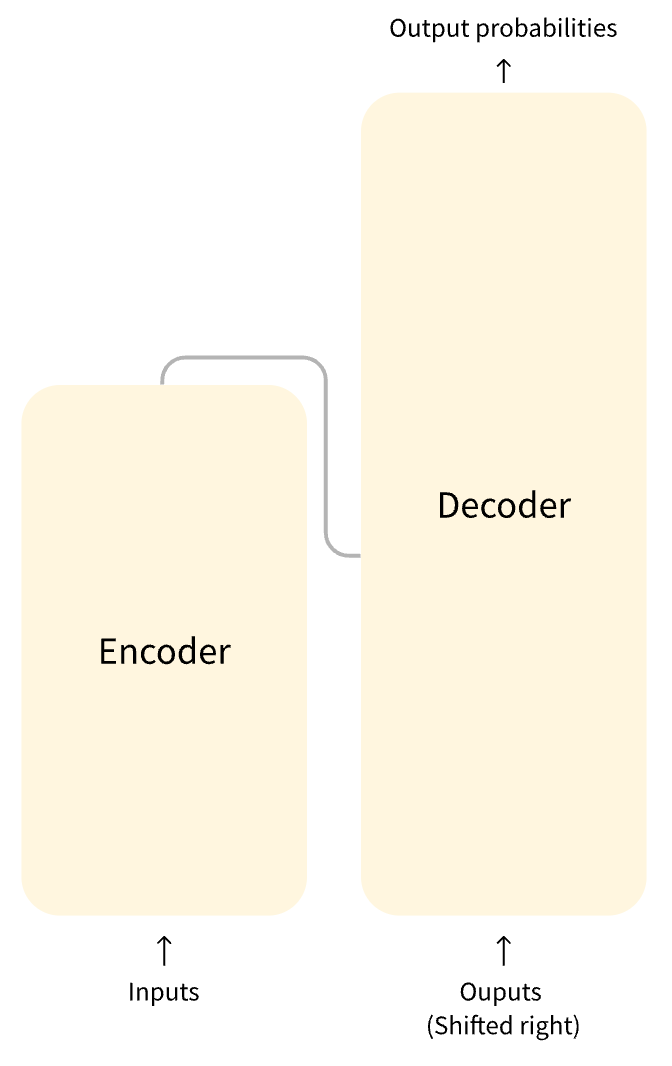
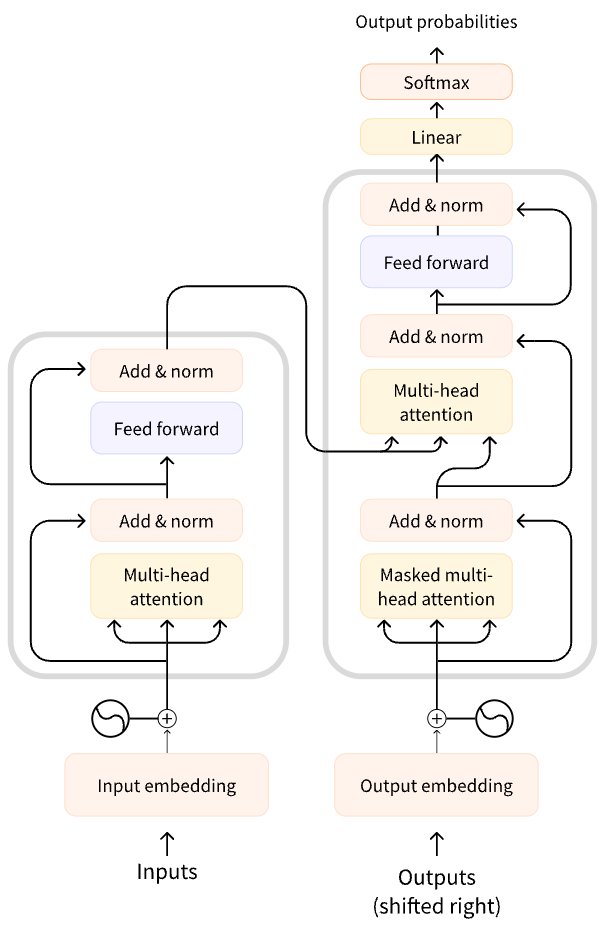
左邊的這張圖是 Transformers 架構的一個簡單表示形式,右邊的這張圖是 Transformers 架構的一個完整表示形式,其中有一個重要的 Multi-Head Attention組件,稱為注意力層。
Transformer 模型的一個關鍵特性是注意力層。事實上,谷歌在發布 Transformer 架構的論文時,文章的標題就是“注意力就是你所需要的”。注意力層將告訴模型在處理每個單詞的表示時,要特別重視傳遞給它的句子中的某些單詞,也可以是或多或少地忽略其他單詞。通過注意力層,模型可以不斷修正自己處理的結果,以符合輸入的文本的意圖。
總結來說 Transformer 通過注意力層,來理解并觀察輸入文本的上下文,在 Decoder 的過程中,通過多頭注意力層來控制結果的輸出是符合上下文語境的。
在回顧完 Stable Diffusion 的原理后,我們可以想象下,對于視頻的生成該怎么做呢?
是否可以嘗試把預訓練 Stable Diffusion 拓展成視頻生成模型呢。例如在拓展時,將視頻的每一幀都單獨輸入進 Stable Diffusion 的自編碼器,再重新構成一個壓縮過的圖像序列。這就是 VideoLDM 嘗試解決的問題,然而經過 VideoLDM 研究發現直接對視頻使用之前的圖像自編碼器,會令輸出視頻出現閃爍的現象。為此,該工作對自編碼器的解碼器進行了微調,加入了一些能夠處理時間維度的模塊,使之能一次性處理整段壓縮視頻,并輸出連貫的真實視頻。
二
Sora生成視頻的流程
那 Sora 是怎么做的呢?接下來我們通過一張圖來了解下 Sora 的工作流程,大概可以簡化為三個部分:
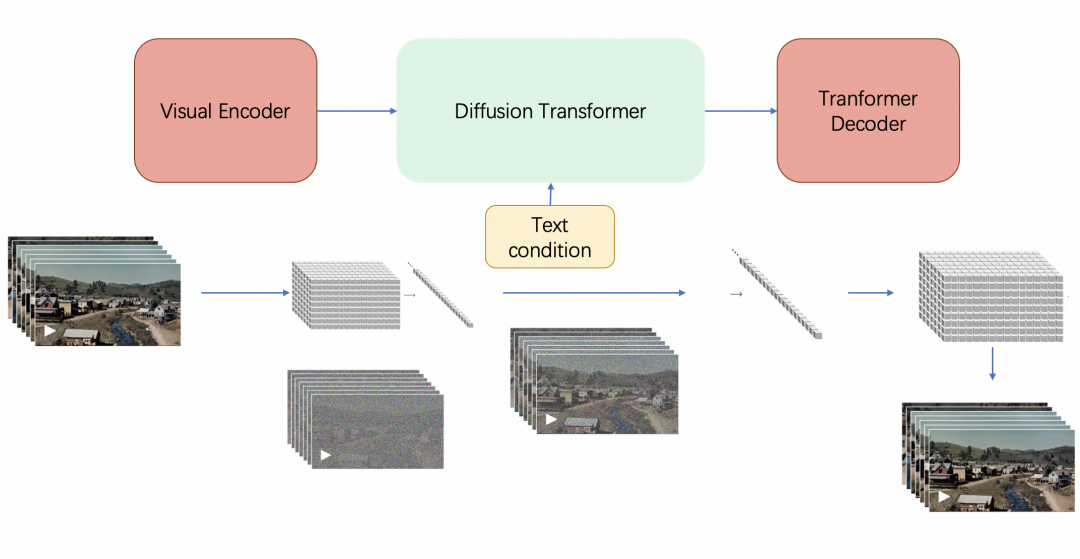
簡單來說,Sora 就是依賴了兩個模型 Latent Diffusion Model (LDM) 加上 Diffusion Transformer (DiT)。我們先簡要回顧一下這兩種模型架構。
LDM 就是 Stable Diffusion 使用的模型架構。擴散模型的一大問題是計算需求大,難以擬合高分辨率圖像。為了解決這一問題,實現 LDM 時,會先訓練一個幾乎能無損壓縮圖像的自編碼器,能把 512x512 的真實圖像壓縮成 64x64 的壓縮圖像并還原。接著,再訓練一個擴散模型去擬合分辨率更低的壓縮圖像。這樣,僅需少量計算資源就能訓練出高分辨率的圖像生成模型。
LDM 的擴散模型使用的模型是 U-Net。而根據其他深度學習任務中的經驗,相比 U-Net,Transformer 架構的參數可拓展性強,即隨著參數量的增加,Transformer 架構的性能提升會更加明顯。這也是為什么大模型普遍都采用了 Transformer 架構。從這一動機出發,DiT 應運而生。DiT 在 LDM 的基礎上,把 U-Net 換成了 Transformer。
總結來說 Sora 是一個視頻版的 DiT 模型,讓我們看一下 Sora 在 DiT 上做了哪些改進。
視頻壓縮網絡
首先,Sora 通過一個叫做“視頻壓縮網絡”的技術,將輸入的圖片或視頻壓縮成一個更低維度的數據,即潛在空間數據,為了實現視頻壓縮,Sora 從頭訓練了一套能直接壓縮視頻的自編碼器。相比之前的工作,Sora 的自編碼器不僅能在空間上壓縮圖像,還能在時間上壓縮視頻長度。
輸入的視頻在經過 Sora 的自編碼器后,會被轉換成一段空間和時間維度上都變小的壓縮視頻。這段壓縮視頻就是 Sora 的 DiT 的擬合對象。
這一過程類似于將不同尺寸和分辨率的照片“標準化”,便于處理和存儲,但壓縮并不意味著忽略原始數據的獨特性,而是將它們轉換成一個對 Sora 來說更容易理解和操作的格式。
報告中反復提及,Sora 在訓練和生成時使用的視頻可以是任何分辨率(在 1920x1080 以內)、任何長寬比、任何時長的,這意味著視頻訓練數據不需要做縮放、裁剪等預處理,因為 Sora 會把這些視頻進行壓縮以獲得符合模型訓練的數據。
空間時間補丁
接下來,Sora 將這些壓縮后的數據進一步分解為“空間時間補丁”(Spacetime Patches),這些補丁可以看作是視覺內容的基本構建塊,例如照片可以分解為包含獨特景觀、顏色和紋理的小片段。這樣不管原始視頻的長度、分辨率或風格如何,Sora 都可以將它們處理成一致的格式。

有了空間時間補丁之后,還需要將這些補丁轉換成一維的數據序列,以便提供給 Transformer 模型進行處理,因為 Transformer 只能處理一維序列數據。
Sora 的這種性質還是得益于 Transformer 架構。雖然 Transformer 的計算與輸入順序無關,但必須用位置編碼來指明每個數據的位置。盡管報告沒有提及,我覺得 Sora 的 DiT 使用了類似于 (x,y,t) 的位置編碼來表示一個圖塊的時空位置。這樣不管輸入的視頻的大小如何,長度如何,只要給每個圖塊都分配一個位置編碼,DiT 就能分清圖塊間的相對關系了。
Diffusion Transformer
最后,Sora 擴展了 Transformer 模型,以便適用于視頻生成,這里的視頻就是一幀幀的靜態圖片加上了時間維度的信息,所以只需要用 Transformer 模型來生成攜帶時間維度信息的圖片。
需要注意的是,Transformer 本來是用于文本任務的,它只能處理一維的序列數據。為了讓 Transformer 處理二維圖像,通常會把輸入圖像先切成邊長為 p 的圖塊,再把每個圖塊整理成一維數據。也就是說,原來邊長為 I 的正方形圖片,經圖塊化后,變成了長度為 (I/p)2 的一維序列數據。
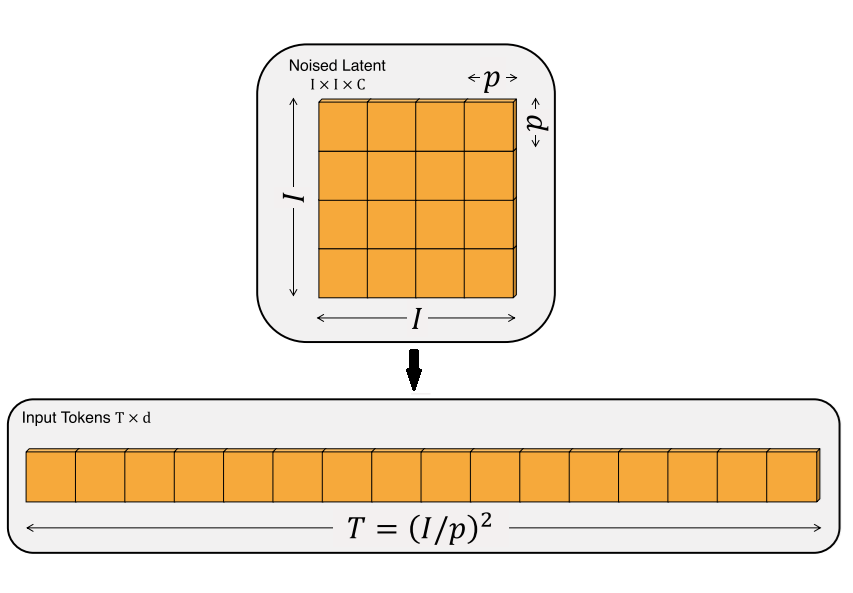
DiT 在處理輸入圖塊(也就是空間時間補丁)時,因為每個視頻圖塊被編上了類似 (x,y,t) 這樣的位置編碼,輸入視頻可以是任何分辨率、任何長度。將每個空間時間補丁輸入 Transformer,作為輸入的 Token,接著 Transformer 會完成每個空間時間補丁的噪聲去除,最后所有的空間時間補丁都完成噪聲去除后,再通過解碼器將 Transformer 處理后的張量數據還原成視頻數據。
下圖展示了 DiT 的架構,左:我們訓練調節的潛 DiT 模型。輸入潛變量被分解成幾個 Patch 并由幾個 DiT 塊處理。右:DiT 塊的細節。我們對標準 Transformer 的變體進行了實驗,這些變體通過自適應層歸一化、交叉注意力和額外的輸入 Token 做調節。自適應層歸一化效果最好。
假設輸入是一張 256x256x3 的圖片,對圖片做 Patch 后經過投影得到每個 Patch 的 Token,得到 32x32x4 的 Latent 潛在空間(在推理時輸入直接是 32x32x4 的噪聲)。結合當前的 Step t, 將 Label y 作為輸入, 經過 N 個 DiT Block 處理,處理中通過 MLP 進行控制輸出,得到輸出的噪聲以及對應的協方差矩陣,經過 T 個 Step 采樣,得到 32x32x4 的降噪后的 Latent。
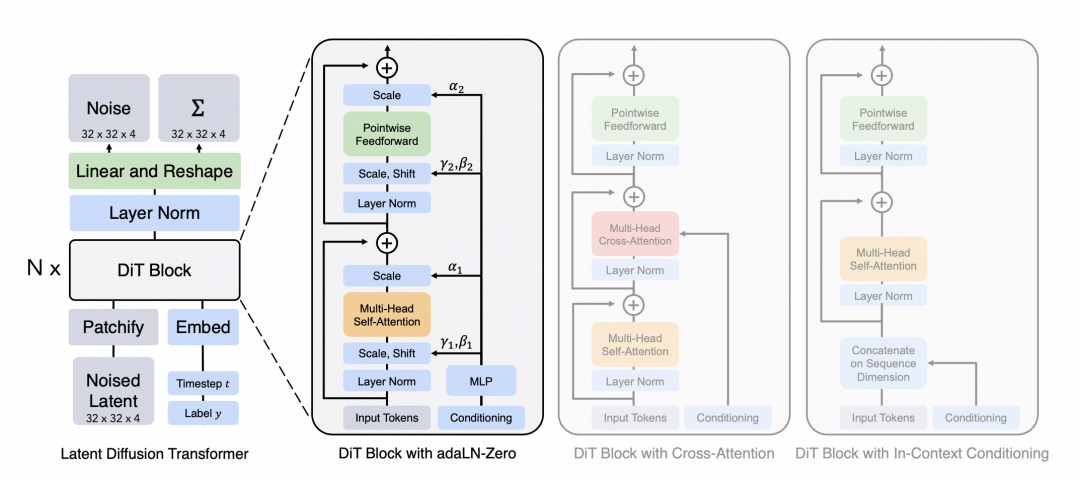
得到處理后的 Latent 之后,通過 Visual Decoder 對 Latent 進行解碼,最終得到生成的視頻。
三
從訓練到生成視頻全流程
視頻標注與訓練
收集視頻及其文本標注
初始步驟是收集大量視頻數據,并獲取或創建這些視頻對應的文本標注。這些文本簡要描述了視頻內容,是訓練模型理解視頻主題的關鍵。
預處理視頻數據
對視頻進行預處理,包括調整分辨率、格式轉換、裁剪長度等,以確保數據格式統一,適合模型處理。
生成高度描述性的文本標注
使用 DALLE3 的技術,首先訓練一個模型,這個模型專門用于為視頻內容生成高度描述性的文本標注。這一步是為了提升文本標注的質量,讓其更加詳細和具體。對訓練集中的所有視頻應用這個模型,產生新的、更加詳細的文本標注。
之前大部分文生圖擴散模型都是在人工標注的圖片-文字數據集上訓練的。后來大家發現,人工標注的圖片描述質量較低,紛紛提出了各種提升標注質量的方法。Sora 復用了自家 DALL·E 3 的重標注技術,用一個訓練的能生成詳細描述的標注器來重新為訓練視頻生成標注。這種做法不僅解決了視頻缺乏標注的問題,且相比人工標注質量更高。Sora 的部分結果展示了其強大了抽象理解能力(如理解人和貓之間的交互),這多半是因為視頻標注模型足夠強大,視頻生成模型學到了視頻標注模型的知識。但同樣,視頻標注模型的相關細節完全沒有公開。
擴散模型訓練
Sora 作為一個擴散模型,通過預測從含噪聲補丁到原始清晰補丁的轉換過程進行訓練。這個過程涉及到大量的迭代,逐步提高生成視頻的質量。
視頻生成與處理
視頻壓縮和空間時間補丁生成
開發并訓練一個視頻壓縮網絡,將高維的視頻數據壓縮到一個低維的潛在空間,簡化后的數據表示更容易被模型處理。將壓縮后的視頻表示分解成空間時間補丁,這些補丁既包含空間上的信息也包含隨時間變化的信息。
利用 Transformer 架構處理時空關系
基于 Transformer 架構,處理這些空間時間補丁。由于 Transformer 架構在處理序列數據(如文本)方面的強大能力,這里用于捕獲視頻補丁之間復雜的時空關系。
通過 GPT 模型理解并優化提示詞
類似于 DALLE3,Sora 在處理用戶提供的文本提示時,也可以利用 GPT 模型來擴展或優化這些提示。GPT 模型可以將簡短的用戶提示轉化成更詳細、更富有描述性的文本,這有助于 Sora 更準確地理解并生成符合用戶意圖的視頻。
利用擴散模型生成視頻
用戶提供一個文本提示,Sora 根據這個提示在潛在空間中初始化視頻的生成過程。利用訓練好的擴散模型,Sora 從這些初始化的空間時間補丁開始,逐步生成清晰的視頻內容。
視頻解碼與處理
使用與視頻壓縮相對應的解碼器將潛在空間中的視頻轉換回原始像素視頻。
對生成的視頻進行可能的后處理,如調整分辨率、裁剪等,以滿足發布或展示的需求。
審核編輯:黃飛
-
解碼器
+關注
關注
9文章
1100瀏覽量
40400 -
放大器
+關注
關注
143文章
13364瀏覽量
211661 -
GPT
+關注
關注
0文章
342瀏覽量
15152 -
Transformer
+關注
關注
0文章
135瀏覽量
5934 -
Sora
+關注
關注
0文章
75瀏覽量
170
原文標題:深入理解Sora技術原理
文章出處:【微信號:OSC開源社區,微信公眾號:OSC開源社區】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論