") 摩爾線程與無問芯穹聯(lián)手開啟千億大模型服務(wù)新篇章
摩爾線程與無問芯穹聯(lián)手開啟千億大模型服務(wù)新篇章
3月31日,無問芯穹AI算力優(yōu)化論壇暨產(chǎn)品發(fā)布會在上海成功舉辦,重磅發(fā)布了“無穹Infini-AI”大模型開發(fā)與服務(wù)平臺,并宣布與國內(nèi)AI芯片領(lǐng)軍企業(yè)摩爾線程達(dá)成深度戰(zhàn)略合作。這一強(qiáng)強(qiáng)聯(lián)合旨在基于摩爾線程大模型智算千卡集群夸娥(KUAE),攜手打造集高效算力、便捷調(diào)度、穩(wěn)定運(yùn)行于一體的全國產(chǎn)大模型算力服務(wù)和云端調(diào)度平臺,為更多用戶開展大模型開發(fā)、訓(xùn)練、運(yùn)行、應(yīng)用提供完整的交鑰匙解決方案。
無穹Infini-AI大模型開發(fā)與服務(wù)平臺是基于無問芯穹的智算云平臺,針對生成式大模型的應(yīng)用落地的多種場景需求,為應(yīng)用開發(fā)者提供高性能、易上手、安全可靠的大模型服務(wù),覆蓋從大模型開發(fā)到大模型服務(wù)化部署的全流程。目前,無穹Infini-AI已支持了Baichuan2、ChatGLM2、ChatGLM3、ChatGLM3閉源模型、Llama2、Qwen、Qwen1.5等系列模型共20多個模型。

圖注:無穹Infini-AI平臺演示
當(dāng)前,無穹Infini-AI與摩爾線程大模型智算千卡集群夸娥(KUAE)已順利完成系統(tǒng)級融合適配,并完成了LLama2-70B大模型的訓(xùn)練測試。發(fā)布會現(xiàn)場演示了無穹Infini-AI如何靈活調(diào)用夸娥的集群能力以完成大模型的訓(xùn)練、微調(diào)與推理任務(wù)。
摩爾線程是第一家接入無問芯穹并成功完成千卡級別大模型訓(xùn)練的國產(chǎn)GPU公司。無問芯穹聯(lián)合創(chuàng)始人兼CEO夏立雪表示:“經(jīng)驗(yàn)證,摩爾線程夸娥千卡智算集群在性能、穩(wěn)定性、易用性和算力利用率上均有優(yōu)異表現(xiàn),可以為千億參數(shù)級別大模型訓(xùn)練提供持續(xù)高效的高性能算力支持。”雙方的合作是國產(chǎn)算力產(chǎn)業(yè)鏈上下游攜手推動大模型落地應(yīng)用的完美例證。
摩爾線程聯(lián)合創(chuàng)始人兼執(zhí)行總裁王東表示,“基于先進(jìn)的MUSA架構(gòu),摩爾線程已建立了從芯片、板卡、集群到軟件的全棧AI產(chǎn)品線。摩爾線程夸娥智算集群是以全功能GPU為底座、軟硬一體化的全棧解決方案,憑借高兼容性、高穩(wěn)定性、高擴(kuò)展性等綜合優(yōu)勢,我們致力于成為大模型訓(xùn)練堅實(shí)可靠的先進(jìn)基礎(chǔ)設(shè)施。”
無問芯穹依托行業(yè)領(lǐng)先且經(jīng)過驗(yàn)證的AI計算優(yōu)化能力與算力解決方案,追求大模型落地的極致能效。打造 “M 種模型” 和 “N 種芯片” 間的“M×N”中間層產(chǎn)品,實(shí)現(xiàn)多種大模型算法在多元芯片上的高效、統(tǒng)一部署。鏈接上下游,共建AGI時代大模型基礎(chǔ)設(shè)施,加速AGI落地千行百業(yè)。摩爾線程作為國內(nèi)AI芯片領(lǐng)軍企業(yè),旨在為廣泛的生態(tài)合作伙伴提供強(qiáng)大的AI計算加速能力,可充分賦能大模型AIGC、數(shù)字孿生、物理仿真等場景,驅(qū)動各行業(yè)智能變革,致力于為新質(zhì)生產(chǎn)力提供 AI原動力。
基于此次戰(zhàn)略合作,無問芯穹與摩爾線程將攜手共進(jìn),開展更多適配與測試,推動國產(chǎn)大模型技術(shù)的快速發(fā)展與應(yīng)用普及,為中國人工智能產(chǎn)業(yè)的蓬勃發(fā)展貢獻(xiàn)力量。
審核編輯:劉清
-
AI芯片
+關(guān)注
關(guān)注
17文章
1859瀏覽量
34908 -
摩爾線程
+關(guān)注
關(guān)注
2文章
198瀏覽量
4519 -
大模型
+關(guān)注
關(guān)注
2文章
2322瀏覽量
2479
原文標(biāo)題:以夸娥千卡集群為底座,摩爾線程與無問芯穹聯(lián)手開啟千億大模型服務(wù)新篇章
文章出處:【微信號:moorethreads,微信公眾號:摩爾線程】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
魏德米勒開啟產(chǎn)業(yè)數(shù)智轉(zhuǎn)型新篇章
IOT物聯(lián)網(wǎng)中臺:開啟智慧生活新篇章 物聯(lián)網(wǎng)平臺系統(tǒng)
摩爾線程成立摩爾學(xué)院,賦能GPU開發(fā)者
摩爾線程與中國移動攜手,共筑生態(tài)與應(yīng)用開創(chuàng)數(shù)智新篇章
無問芯穹獲完成5億元A輪融資
無問芯穹發(fā)布千卡規(guī)模異構(gòu)芯片混訓(xùn)平臺
國產(chǎn)GPU可替代!摩爾線程千卡集群點(diǎn)亮新成就
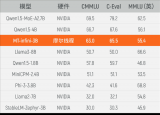
摩爾線程與無問芯穹在國產(chǎn)GPU上首次實(shí)現(xiàn)大模型實(shí)訓(xùn)
摩爾線程與無問芯穹宣布完成基于GPU千卡集群的3B規(guī)模大模型實(shí)訓(xùn)
高校嵌入式教學(xué)實(shí)驗(yàn)箱,開啟智慧教學(xué)新篇章

華盛昌與易達(dá)云成功簽署戰(zhàn)略協(xié)議,共同開啟合作新篇章

摩爾線程助力AI大模型訓(xùn)練與計算升級,共建美好數(shù)字化未來
燧原科技與無問芯穹簽約宣布共同打造千卡集群案例
瑞芯微RK3576|觸覺智能:開啟科技新篇章






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論