 大模型時代,國產GPU面臨哪些挑戰
大模型時代,國產GPU面臨哪些挑戰
電子發燒友網報道(文/李彎彎)隨著人工智能技術的快速發展,對GPU計算能力的需求也越來越高。國內企業也正在不斷提升GPU性能,以滿足日益增長的應用需求。然而,相較于國際巨頭,國內GPU仍然存在差距,國產GPU在不斷成長的過程中也存在諸多挑戰。
在大模型訓練上存在差距
大語言模型是基于深度學習的技術。這些模型通過在海量文本數據上的訓練,學習語言的語法、語境和語義等多層次的信息,用于理解和生成自然語言文本。大語言模型是自然語言處理(NLP)領域中的一個重要分支,應用于文本生成、分類、情感分析等多種任務。
深度學習是現代機器學習領域的一種強大的算法,它可以在圖像識別、語音識別、自然語言處理、游戲AI等各種應用領域取得驚人的成果。然而,深度學習對計算幾硬件的要求非常高,通常需要使用GPU進行大規模訓練。在使用GPU進行深度學習時,一個常見的問題就是選擇單精度還是雙精度。
浮點數是一種用于表示實數的數值格式,它包括符號位、指數位和尾數位三部分。通過這三部分,浮點數可以表示非常大或非常小的數,同時保持一定的精度。
單精度和雙精度是指浮點數在計算機中的存儲方式和精度。單精度通常使用32位(4字節)來存儲一個浮點數,而雙精度則使用64位(8字節)來存儲。由于雙精度使用了更多的位數,因此它可以表示更大范圍的數值,并具有更高的精度。
大模型訓練需要處理高顆粒度的信息,因此對于用于大模型訓練的GPU芯片處理信息的精細度和算力速度要求更高,現階段,國產GPU在支持大模型訓練的能力方面相對來說還較差。
不同于多媒體和圖形處理的單精度浮點計算(FP32)計算需求,雙精度浮點計算能力FP64是進行高算力計算的硬性指標。英偉達的A100同時具備上述兩類能力,而國內大多GPU只能處理單精度浮點計算。
從目前的信息來看,海光信息的協處理器(DCU)能夠支持FP64雙精度浮點運算,海光DCU屬于GPGPU 的一種,采用“類CUDA”通用并行計算架構。據該公司介紹,其DCU產品能夠完整支持大模型訓練。不過相比于英偉達的A100性能只有其60%。
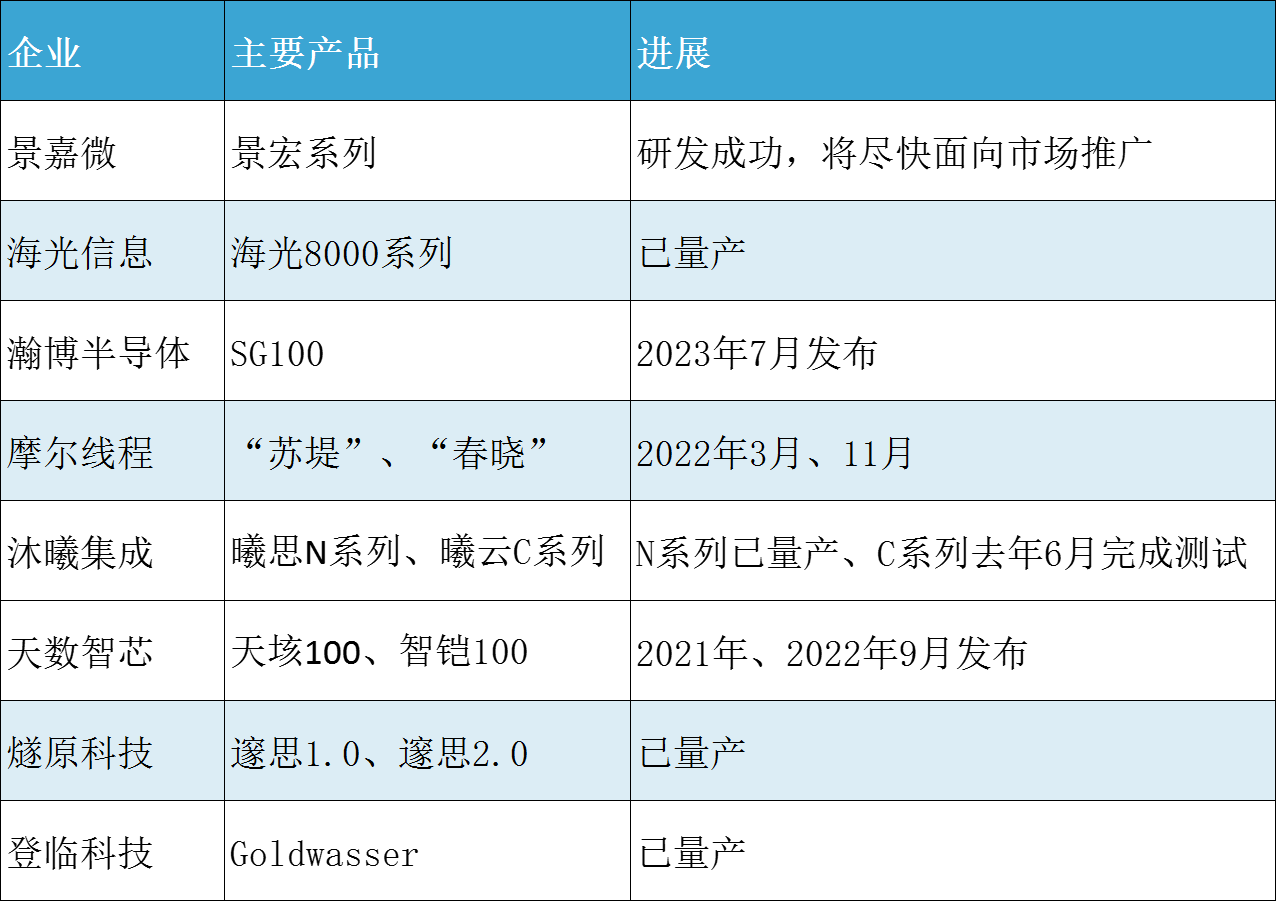
另外,景嘉微表示面向AI 訓練、AI推理、科學計算等應用領域研發成功的景宏系列,支持INT8、FP16、FP32、FP64等混合精度運算,該產品在大模型的訓練上或許也可以期待一下。
在軟件和生態方面存在差距
除上述情況以外,國產GPU在軟件和生態方面與全球領先品牌相比,也存在一定的差距。軟件工具鏈的完善度方面,全球領先的GPU廠商已經構建了完整的軟件工具鏈,包括編譯器、調試器、性能分析工具等,可以方便地支持開發人員進行GPU程序的開發、調試和優化。而國產GPU在這方面還需要進一步完善,以滿足用戶的多樣化需求。
生態系統的成熟度方面,全球GPU市場已經形成了較為成熟的生態系統,涵蓋了各種應用領域和場景。然而,國產GPU在生態系統建設方面尚處于起步階段,缺乏足夠的應用支持和市場認可。這導致國產GPU在市場上的競爭力相對較弱,難以與全球領先品牌抗衡。
近些年可以明顯的看到,國產PGU企業也正在這些方面不斷努力。在軟件支持方面,國產GPU企業正在積極與主流操作系統、開發環境以及圖形處理軟件等進行適配,確保用戶能夠流暢地使用各種應用軟件。同時,一些企業還在推動GPU在人工智能、云計算等新興領域的應用,為國產GPU生態注入新的活力。
在驅動程序優化方面,國產GPU企業也在加大投入力度,不斷提升驅動程序的性能和穩定性。通過優化驅動程序,可以充分發揮GPU的性能優勢,提升整體計算效率。
此外,國產GPU企業還在積極探索與各種應用場景的深度融合。例如,在游戲、圖形設計、視頻渲染等領域,國產GPU正在與相關企業合作,共同推動相關應用的發展。這種深度融合不僅有助于提升國產GPU的市場競爭力,也有助于推動整個產業的進步。
寫在最后
近些年國產GPU正在蓬勃發展,不過相較于國際巨頭,仍然存在較大差距。近年來,大模型快速發展,國產GPU在大模型訓練方面的不足也凸顯出來。不過也可以看到,目前國產GPU企業都在積極朝大模型方向布局,包括訓練和推理。另外軟件和生態建設也在加速推進。
-
gpu
+關注
關注
28文章
4703瀏覽量
128723 -
大模型
+關注
關注
2文章
2339瀏覽量
2499
發布評論請先 登錄
相關推薦
國產大模型發展的經驗與教訓

【「大模型時代的基礎架構」閱讀體驗】+ 第一、二章學習感受
【「大模型時代的基礎架構」閱讀體驗】+ 未知領域的感受
大模型時代的算力需求
名單公布!【書籍評測活動NO.41】大模型時代的基礎架構:大模型算力中心建設指南
國產FPGA的發展前景是什么?



摩爾線程與無問芯穹在國產GPU上首次實現大模型實訓
國產GPU在AI大模型領域的應用案例一覽

盤點國產GPU在支持大模型應用方面的進展
FPGA在深度學習應用中或將取代GPU
揭秘GPU: 高端GPU架構設計的挑戰






 工商網監
工商網監
評論