") 自然語言控制機(jī)械臂:ChatGPT與機(jī)器人技術(shù)的融合創(chuàng)新(下)
自然語言控制機(jī)械臂:ChatGPT與機(jī)器人技術(shù)的融合創(chuàng)新(下)
引言
在我們的上一篇文章中,我們探索了如何將ChatGPT集成到myCobot 280機(jī)械臂中,實(shí)現(xiàn)了一個(gè)通過自然語言控制機(jī)械臂的系統(tǒng)。我們?cè)敿?xì)介紹了項(xiàng)目的動(dòng)機(jī)、使用的關(guān)鍵技術(shù)如ChatGPT和Google的Speech-to-text服務(wù),以及我們是如何通過pymycobot模塊來控制機(jī)械臂的。通過將自然語言處理和機(jī)械臂控制相結(jié)合,我們的項(xiàng)目旨在降低機(jī)器人編程的門檻,使得非專業(yè)人士也能輕松地進(jìn)行機(jī)器人編程和實(shí)驗(yàn)。
接下來,在這篇文章中,我們將討論在開發(fā)這一系統(tǒng)過程中遇到的挑戰(zhàn),我們是如何克服這些挑戰(zhàn)的,以及項(xiàng)目未來的擴(kuò)展可能性。我們的目標(biāo)是深入了解技術(shù)實(shí)施的具體問題,并探索該系統(tǒng)未來發(fā)展的新方向。

開發(fā)當(dāng)中遇到的困難
在開發(fā)集成了ChatGPT的mycobot 280機(jī)械臂控制系統(tǒng)的過程中,我面臨了幾個(gè)主要的技術(shù)挑戰(zhàn)。
1.語音識(shí)別的準(zhǔn)確性和響應(yīng)時(shí)間
首先,我遇到的挑戰(zhàn)是語音識(shí)別的準(zhǔn)確性和反應(yīng)時(shí)間。盡管使用了Google的Speech-to-text,但在實(shí)際應(yīng)用中,我發(fā)現(xiàn)它有時(shí)難以準(zhǔn)確識(shí)別專業(yè)術(shù)語或在嘈雜環(huán)境中捕捉語音指令。可能是因?yàn)椴惶斫獾讓舆壿嬤\(yùn)行的一個(gè)原理是什么,也不知道如何來正確的使用。此外,從語音輸入到文本輸出的過程延遲較長,如何來判斷這句話是不是說完了,通常響應(yīng)的時(shí)間較久。

在我說完之后,大概會(huì)有3s左右的響應(yīng)時(shí)間。
ChatGPT的API 是整個(gè)項(xiàng)目的核心功能點(diǎn),沒有了他就不能實(shí)現(xiàn)AI的機(jī)械臂控制系統(tǒng)了。在一開始測(cè)試代碼的時(shí)候我用的是WEB版本的ChatGPT,一開始沒有考慮到使用API是一個(gè)比較大的問題。
因?yàn)榈貐^(qū)的問題,沒有辦法直接通過API進(jìn)行訪問OpenAI,會(huì)出現(xiàn)網(wǎng)絡(luò)延遲,不能夠使用代理等軟件來實(shí)現(xiàn)訪問。除此之外還得確保網(wǎng)絡(luò)的穩(wěn)定性才能夠快快速的進(jìn)行處理。

3.自然語言轉(zhuǎn)指令的處理
如果解決了上邊的生成代碼的問題,我們將會(huì)得到類似于命令行的字符串,需要將它轉(zhuǎn)變成可以編譯的代碼。一開始只考慮到了單行的命令行
"robot.move_to_zero()"
要將字符串轉(zhuǎn)化成執(zhí)行的代碼可以用到python的getattr(),他是一個(gè)內(nèi)置函數(shù),用于獲取對(duì)象的屬性值。
getattr(object, name[, default]) object:表示要獲取屬性的對(duì)象。 name:表示要獲取的屬性的名稱。 default:可選參數(shù),表示如果指定的屬性不存在時(shí)返回的默認(rèn)值。
getattr() 函數(shù)會(huì)嘗試獲取指定對(duì)象的指定屬性的值。如果對(duì)象具有該屬性,則返回屬性的值;如果對(duì)象沒有指定的屬性,但提供了默認(rèn)值,則返回默認(rèn)值;如果對(duì)象沒有指定的屬性,并且沒有提供默認(rèn)值,則會(huì)引發(fā) AttributeError 異常。
舉個(gè)例子直接調(diào)用類的方法
class Myclass: def print_1(self): print("halo word") obj = mycalss() getattr(obj,"print_1")() """ halo word
用這個(gè)方法就可以完美解決如何將字符串的形式輸出可執(zhí)行的代碼了!
接下來是將字符串轉(zhuǎn)化為可執(zhí)行代碼的過程:
我們收到的字符串是代碼的形式例如
"robot.move_to_zero()"
我們要將這一部分進(jìn)行拆分,分為obj和方法兩部分,就要用到python當(dāng)中的分割的方法。
# 以.為節(jié)點(diǎn)分為前后兩個(gè)部分 command_str = "robot.move_to_zero()" parts = command_str.split(".") parts[0] = "robot" part[1] = "move_to_zero()" # 去掉括號(hào)保留,方法名 method_name = part[1].split("()")[0] method = getatter(robot,method_name) method() #處理轉(zhuǎn)化方法 def execute_command(instance,command_str): try: #分割對(duì)象名和方法 parts = command_str.split(".") if len(parts) != 2 or parts[0] != 'robot': print("Invalid command format.") return method_name = parts[1].split("()")[0] #移除括號(hào) #使用getattr 安全的獲取方法引用 if hasattr(instance, method_name): method = getattr(instance, method_name) method() else: print(f"the method {method_name} does not exist!") except Exception as e: print(f"An error occurred: {e}")
這樣就完成了,能夠處理單行的字符串,但是在測(cè)試的時(shí)候使用產(chǎn)生多行的命令的時(shí)候,這個(gè)代碼就不行了,它會(huì)變成一長串,所以這個(gè)方法是無效的。
上述三個(gè)是我主要遇到的問題,接下來我將一一的進(jìn)行解答。
解決方案和應(yīng)對(duì)策略
1.優(yōu)化語音識(shí)別
根據(jù)我上述描寫的識(shí)別延遲的問題,我是通過設(shè)置時(shí)間來優(yōu)化我的程序。
# 設(shè)置timeout為3秒,phrase_time_limit為10秒 audio = recognizer.listen(source, timeout=3, phrase_time_limit=10)
默認(rèn)設(shè)置沒有聽到聲音,一直的進(jìn)行監(jiān)聽,我設(shè)置了時(shí)間上的限制10s,也能夠保證我在說完話之后較快的一個(gè)響應(yīng)。
接下來完成的功能代碼
import speech_recognition as sr def speech_to_text(): # 初始化識(shí)別器 recognizer = sr.Recognizer() with sr.Microphone() as source: print("start speaking...") # 監(jiān)聽源,設(shè)置timeout和phrase_time_limit # timeout:在這段時(shí)間內(nèi)沒有檢測(cè)到聲音,則停止監(jiān)聽 # phrase_time_limit:監(jiān)聽的最大時(shí)長 try: audio = recognizer.listen(source, timeout=3, phrase_time_limit=10) except sr.WaitTimeoutError: print("No speech was detected within the timeout period.") return None try: # 使用Google的語音識(shí)別服務(wù) text = recognizer.recognize_google(audio, language='en-US') print("You said: " + text) return text except sr.UnknownValueError: print("Google Speech Recognition could not understand audio") return None except sr.RequestError as e: print(f"Could not request results from Google Speech Recognition service; {e}") return None
這目前已經(jīng)可以滿足大部分的需求了,實(shí)際的使用情況下來來看,整個(gè)的功能還是比較完整的,能夠有效的識(shí)別出語音內(nèi)容,特別是讓我說數(shù)字的時(shí)候他主動(dòng)轉(zhuǎn)化成阿拉伯?dāng)?shù)字,在進(jìn)行交互的過程中省了處理數(shù)字的問題。
1.自然語言轉(zhuǎn)化優(yōu)化
如何來解決多行的指令問題呢。
當(dāng)我們收到,多行的指令就不能跟之前單純的分離來進(jìn)行處理了得考慮其他的方式,以下的情況默認(rèn)ChatGPT生成的指令是下面這種換行行的字符串,沒有帶注釋的(ChatGPT很喜歡寫注釋)。
"robot.move_to_zero() robot.grab_position() robot.plus_z_coords(20)"
只要把多個(gè)當(dāng)成一個(gè)來看就好了!
# 分割成多行 commands = command_str.strip().split('n') #萬一里面存在一些空白符,得先進(jìn)行處理 for cmd in commands: cmd = cmd.strip() if not cmd: continue # 我們默認(rèn)obj 是robot,就只需要獲取方法名字就可以了 if cmd.startswith("robot."): cmd = cmd[6:] # 分割方法名,和參數(shù) if '(' in cmd and cmd.endswith(")"): method_name, args_str = cmd.split('(', 1) method_name = method_name.strip() #刪除前后空格 args_str = args_str.rstrip(")") #刪除右側(cè)的) # 移除可能的空白字符,并按逗號(hào)分隔參數(shù) args = [arg.strip() for arg in args_str.split(',')] if args_str else []
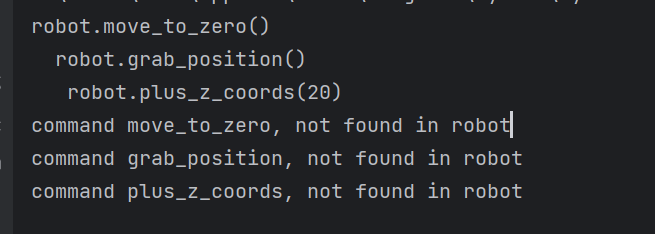
it works!
3.ChatGPT API的問題
關(guān)于這個(gè)問題,我目前并沒能很好的進(jìn)行解決,大家如果有好的方法可以,私信我跟我溝通,因?yàn)榈貐^(qū)的問題,并不能夠直接的用API獲取響應(yīng)。
項(xiàng)目的擴(kuò)展功能和未來展望
視覺功能
在本次記錄當(dāng)中,缺少了最重要的一個(gè)模塊,視覺模塊,單獨(dú)有一個(gè)機(jī)械臂沒有眼睛的話跟瞎子又有什么區(qū)別呢。 對(duì)于這一部分的開發(fā),會(huì)需要花費(fèi)較大的經(jīng)歷,如果以后有完成一定程度上的開發(fā),我也會(huì)及時(shí)出來跟大家進(jìn)行分享。
之前也有看到日本的Shirokuma 開發(fā)個(gè)類似的項(xiàng)目,用到了ChatGPT4-vision的功能,做了說出目標(biāo)進(jìn)行抓取的一個(gè)功能。
https://twitter.com/neka_nat/status/1733517151947108717
這個(gè)項(xiàng)目也是相當(dāng)?shù)挠幸馑迹o了我不少開發(fā)這個(gè)項(xiàng)目的想法。
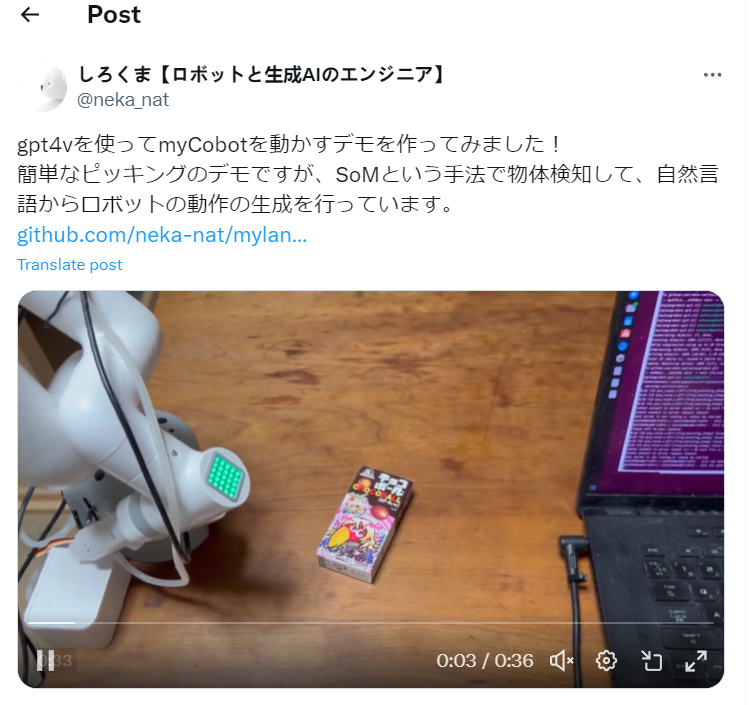
更加智能的“賈維斯”
相信大家的肯定都有看過鋼鐵俠,隨著AI的不斷發(fā)展,我覺得在不久的將來,肯定會(huì)出現(xiàn)一款如同電影當(dāng)中的機(jī)械臂,能夠通過交流的方式來幫助你完成一些工作。
近幾年也能說是人工智能的突發(fā)猛進(jìn)的幾年,AIGC是近期最火熱的內(nèi)容,只要接收到內(nèi)容就可以生成對(duì)應(yīng)的文本,圖像,視頻和音頻等等。
總結(jié)
很期待未來,AI和機(jī)器人相結(jié)合能夠融合到怎樣的一個(gè)程度,是不是已經(jīng)能夠幫助人類做一定的事情了!如果你有一些好的想法,或者對(duì)我的項(xiàng)目修改的意見歡迎隨時(shí)跟我提出!
審核編輯 黃宇
-
機(jī)器人
+關(guān)注
關(guān)注
210文章
28231瀏覽量
206620 -
人工智能
+關(guān)注
關(guān)注
1791文章
46896瀏覽量
237672 -
機(jī)械臂
+關(guān)注
關(guān)注
12文章
510瀏覽量
24500 -
ChatGPT
+關(guān)注
關(guān)注
29文章
1549瀏覽量
7509
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
語音識(shí)別與自然語言處理的關(guān)系
自然語言處理與機(jī)器學(xué)習(xí)的區(qū)別
機(jī)器人技術(shù)的發(fā)展趨勢(shì)
Al大模型機(jī)器人
自然語言處理技術(shù)有哪些
自然語言處理模式的優(yōu)點(diǎn)
自然語言處理技術(shù)的核心是什么
自然語言處理是什么技術(shù)的一種應(yīng)用
自然語言處理包括哪些內(nèi)容
大象機(jī)器人開源協(xié)作機(jī)械臂機(jī)械臂接入GPT4o大模型!

自然語言處理技術(shù)的原理的應(yīng)用
國產(chǎn)Cortex-A55人工智能教學(xué)實(shí)驗(yàn)箱_基于Python機(jī)械臂跳舞實(shí)驗(yàn)案例分享
自然語言控制機(jī)械臂:ChatGPT與機(jī)器人技術(shù)的融合創(chuàng)新(上)
【國產(chǎn)FPGA+OMAPL138開發(fā)板體驗(yàn)】(原創(chuàng))2.手把手玩轉(zhuǎn)游戲機(jī)械臂
自動(dòng)化革命:大象機(jī)器人的Mercury A1機(jī)械臂





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論