 NVLink的演進:從內部互聯到超級網絡
NVLink的演進:從內部互聯到超級網絡
隨著人工智能(AI)技術的迅猛發展,對于高效、快速的數據傳輸和處理變得越來越迫切。英偉達的NVLink技術一直處于技術前沿,不斷推動著GPU之間和GPU與其他組件之間的互聯效率。
本文將介紹NVLink的演進歷程,從最初的內部互聯到如今的超級網絡,探索其在AI芯片架構中的重要作用。

Part 1
NVLink的起源
NVLink是NVIDIA開發的一種高速、低延遲的互聯技術,旨在連接多個GPU以實現高性能并行計算。與傳統的PCIe總線相比,NVLink提供了更高的帶寬和更低的延遲,使得GPU之間可以更加高效地共享數據和通信。

NVLink最初的目標是解決GPU之間的互聯問題。早期的GPU一定需要保留與CPU互聯的PCIe接口,因此NVLink自然而然地繼承了這一技術。
NVLink利用了Ethernet生態的成熟互聯技術,但并未完全遵循Ethernet的規范,采用了不同的調制方式以降低時延。這使得NVLink在速率和時延上都具有優勢,逐漸成為了PCIe的競爭對手。
NVLink采用了基于差分信號線的高速串行通信技術,通過將多個Sub-Link(子鏈接)組合成Port(端口),實現GPU之間的快速數據傳輸。每個Port由多個Sub-Link組成,每個Sub-Link都由一對差分信號線構成,可以實現高達幾百Gbps的傳輸速率。NVLink還支持內存一致性和直接內存訪問(DMA),進一步提高了數據傳輸效率和計算性能。
Part 2
NVLink的發展
NVLink 首次作為與 NVIDIA P100 GPU 的 GPU 互連推出,并與每個新的 NVIDIA GPU 架構保持同步發展。隨著技術的不斷發展,NVLink逐漸走出了盒子和機框,成為了一個獨立的網絡設備,對標InfiniBand和Ethernet網絡。
每一代NVLink的速率都會是上一代的1.5到2倍,未來NVLink5.0預計將采用更高的速率,如200G每通道。同時,NVLink在帶寬指標上對PCIe形成了碾壓式的競爭優勢,不斷拓展著其應用領域。
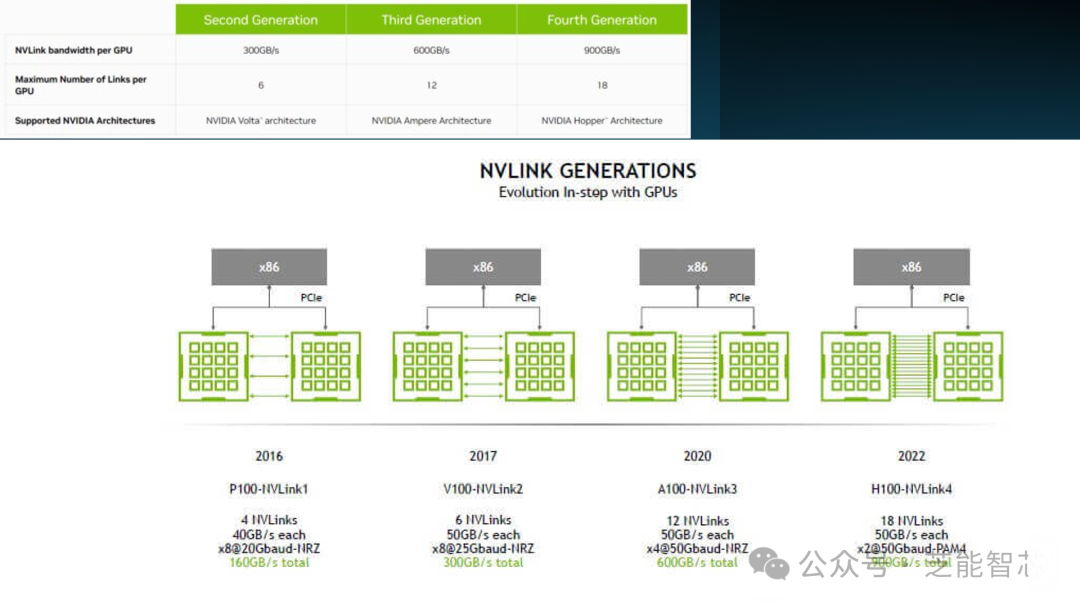
NVLink的發展經歷了多個版本,每一代都在帶寬、延遲和能效方面有所提升。新的NVLink帶寬比上一代提高了兩倍,這意味著數據傳輸更快,GPU之間的協作更加高效。第五代NVLink還在總帶寬和性能方面有所提升。
NVSwitch3芯片集成了SHARP功能,對多個GPU單元的計算結果進行聚合和更新,減少網絡數據包并提高計算性能。這些改進使得第五代NVLink在多GPU系統中的應用更加高效和靈活。
NVLink將繼續發揮重要作用,隨著AI芯片架構的不斷演進,NVLink將進一步優化其性能和效率。NVLink的未來發展方向可能包括更高速率的互聯技術以及更廣泛的應用場景,從而滿足不斷增長的數據處理需求。
小結
NVLink是一種由NVIDIA開發并推出的高速連接技術,作為Nvidia的核心技術之一,在AI芯片領域扮演著至關重要的角色。
?
-
gpu
+關注
關注
28文章
4701瀏覽量
128706 -
PCIe
+關注
關注
15文章
1217瀏覽量
82445 -
英偉達
+關注
關注
22文章
3747瀏覽量
90834
原文標題:NVLink的演進:從內部互聯到超級網絡
文章出處:【微信號:QCDZSJ,微信公眾號:汽車電子設計】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
從 IPv4 到 IPv6,網絡世界的進化之路

分布式通信的原理和實現高效分布式通信背后的技術NVLink的演進
奇異摩爾賦能萬卡集群互聯
從單一到互聯:KNX網關如何改變你的家居生活
為什么安卓手機無法顯示從ESP8266發送的網頁?
工業互聯網如何從混沌到創新?卡奧斯給出了智能交互引擎的答案

科技巨頭組建“復仇者聯盟”,挑戰英偉達的NVLink技術
進一步解讀英偉達 Blackwell 架構、NVlink及GB200 超級芯片
一文詳解基于以太網的GPU Scale-UP網絡

全面解讀英偉達NVLink技術

什么是NVIDIA?InfiniBand網絡VSNVLink網絡

IPv6促進從網絡云化到算網融合的演進,賦予網絡創新機會
英偉達官宣新一代Blackwell架構,把AI擴展到萬億參數
NVIDIA 推出 Blackwell 架構 DGX SuperPOD,適用于萬億參數級的生成式 AI 超級計算






 工商網監
工商網監
評論