 CVPR'24 Highlight!跟蹤3D空間中的一切!
CVPR'24 Highlight!跟蹤3D空間中的一切!
0. 這篇文章干了啥?
運動估計一直通過兩種范式來處理:特征跟蹤和光流。雖然每種方法都可以實現許多應用,但它們都不能完全捕捉視頻中的運動:光流只能為相鄰幀產生運動,而特征跟蹤只能跟蹤稀疏像素。
一個理想的解決方案將涉及在視頻序列中估計密集和長程像素軌跡的能力。但當前的解決方案在挑戰性場景中仍然存在困難,特別是在復雜變形伴隨頻繁自遮擋的情況下。這種困難的一個潛在原因在于僅在二維圖像空間中進行跟蹤,從而忽略了運動的固有三維性質。由于運動發生在三維空間中,某些屬性只能通過三維表示來充分表達。例如,旋轉可以用三維中的三個參數簡潔地解釋,遮擋可以簡單地用z緩沖表示,但在二維表示中要復雜得多。圖像投影可以將空間上遠離的區域帶到二維空間中,這可能導致用于相關性的局部二維鄰域可能包含不相關的上下文(特別是在遮擋邊界附近),從而導致推理困難。
為了解決這些挑戰,作者建議利用最先進的單目深度估計器的幾何先驗,將二維像素提升到三維,并在三維空間中進行跟蹤。這涉及在三維空間中進行特征相關性計算,為跟蹤提供更有意義的三維上下文,特別是在復雜運動的情況下。在三維中跟蹤還允許強制執行三維運動先驗,例如ARAP約束。鼓勵模型學習哪些點一起剛性移動可以幫助跟蹤模糊或被遮擋的像素,因為它們的運動可以通過同一剛性組中相鄰的清晰可見區域推斷出來。
下面一起來閱讀一下這項工作~
1. 論文信息
標題:SpatialTracker: Tracking Any 2D Pixels in 3D Space
作者:Yuxi Xiao, Qianqian Wang, Shangzhan Zhang, Nan Xue, Sida Peng, Yujun Shen, Xiaowei Zhou
機構:浙江大學、UC伯克利、螞蟻集團
原文鏈接:https://arxiv.org/abs/2404.04319
代碼鏈接:https://github.com/henry123-boy/SpaTracker
官方主頁:https://henry123-boy.github.io/SpaTracker/
2. 摘要
視頻中恢復密集且長距離的像素運動是一個具有挑戰性的問題。部分困難來自于3D到2D的投影過程,導致2D運動領域出現遮擋和不連續性。雖然2D運動可能很復雜,但我們認為潛在的3D運動通常是簡單且低維的。在這項工作中,我們提出通過估計3D空間中的點軌跡來減輕圖像投影引起的問題。我們的方法,命名為SpatialTracker,使用單眼深度估計器將2D像素轉換為3D,使用三平面表示高效地表示每一幀的3D內容,并使用變換器執行迭代更新來估計3D軌跡。在3D中進行跟蹤使我們能夠利用盡可能剛性(ARAP)約束,同時學習將像素聚類到不同剛性部分的剛性嵌入。廣泛的評估表明,我們的方法在定性和定量上都實現了最先進的跟蹤性能,特別是在諸如平面外旋轉之類具有挑戰性的場景中。
3. 效果展示
在三維空間中跟蹤2D像素。為了估計遮擋和復雜3D運動下的2D運動,作者將2D像素提升到3D,并在3D空間中執行跟蹤。

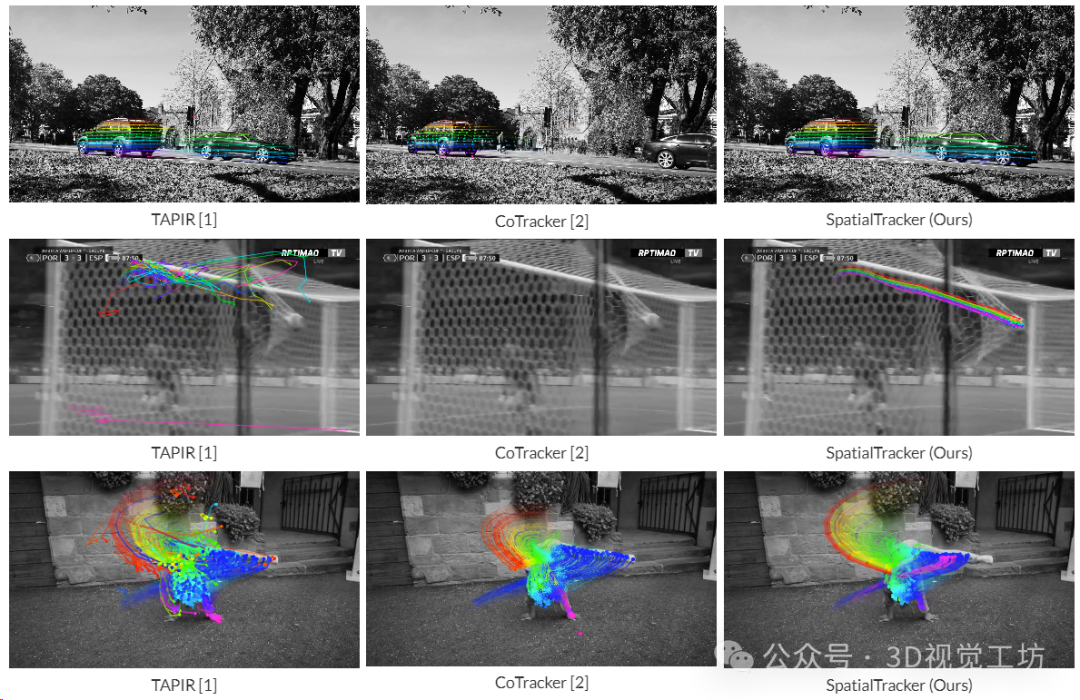
與TAPIR和Cotracker的2D跟蹤進行比較。SpatialTracker可以處理具有挑戰性的場景,如平面外旋轉和遮擋。
視頻中剛性部件的分割。SpatialTracker通過聚類它們的3D軌跡來識別場景中不同的剛性部分。

4. 主要貢獻
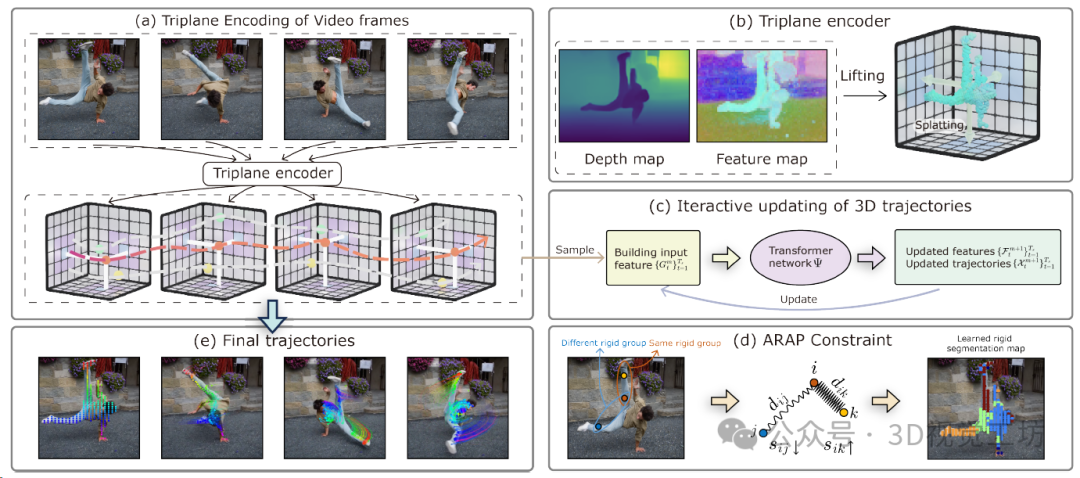
(1)作者建議使用三平面特征圖來表示每個幀的三維場景,首先將圖像特征提升到三維特征點云,然后將其噴灑到三個正交平面上。三平面表示緊湊而規則,適合學習框架。
(2)三平面在三維空間中密集覆蓋,能夠提取任何三維點的特征向量進行跟蹤。然后,通過迭代更新使用來自三平面表示的特征的變壓器預測的查詢像素的三維軌跡。
(3)為了使用三維運動先驗正則化估計的三維軌跡,模型另外預測了每條軌跡的剛性嵌入,這使能夠軟地分組表現出相同剛性體運動的像素,并為每個剛性集群強制執行ARAP正則化。作者證明了剛性嵌入可以通過自監督學習,并產生不同剛性部分的合理分割。
(4)模型在各種公共跟蹤基準上實現了最先進的性能,包括TAP-Vid、BADJA和PointOdyssey。對具有挑戰性的互聯網視頻的定性結果還表明了模型處理快速復雜運動和延長遮擋的出色能力。
5. 基本原理是啥?
Pipeline概述。首先使用三面編碼器將每個幀編碼為三面表示(a)。然后,使用從這些三面提取的特征作為輸入,使用變換器在三維空間中初始化并迭代更新點軌跡(c)。三維軌跡使用地面真實注釋進行訓練,并通過具有學習到的剛性嵌入的盡可能剛性(ARAP)約束進行規范化(d)。ARAP約束強制要求具有相似剛性嵌入的點之間的三維距離隨時間保持恒定。這里dij表示點i和j之間的距離,而sij表示剛性相似性。SpatialTracker即使在快速移動和嚴重遮擋下也能產生準確的遠距離運動軌跡(e)。
6. 實驗結果
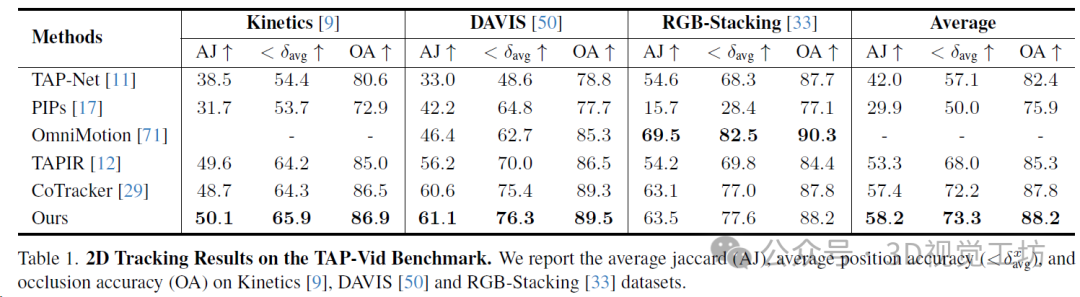
TAP-Vid基準包含幾個數據集:TAPVid-DAVIS(約34-104幀的30個真實視頻)、TAP-Vid-Kinetics(250幀的1144個真實視頻)和RGB-Stacking(250幀的50個合成視頻)。基準中的每個視頻都使用真實2D軌跡和遮擋進行注釋。使用與TAP-Vid基準相同的度量標準來評估性能:平均位置精度(<δavg)、平均Jaccard(AJ)和遮擋精度(OA)。SpatialTracker在所有三個數據集上一致優于所有基線方法,除了Omnimotion之外,展示了在3D空間中進行跟蹤的好處。Omnimotion還在3D中執行跟蹤,并通過一次性優化所有幀在RGB-Stacking上獲得最佳結果,但這需要非常昂貴的測試時間優化。
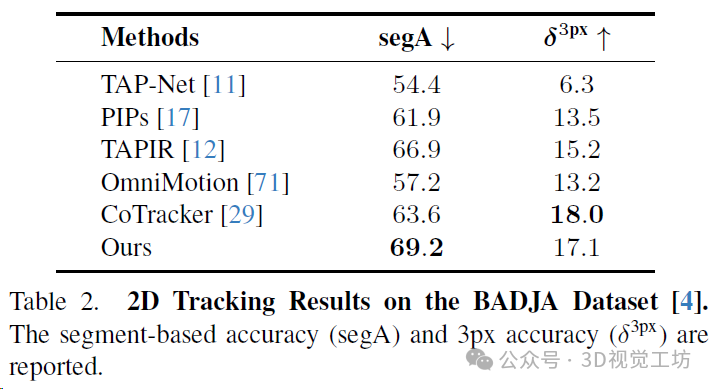
BADJA是一個包含七個帶有關鍵點注釋的動物移動視頻的基準。此基準中使用的指標包括基于段的準確性(segA)和3px準確性(δ3px)。SpatialTracker在δ3px方面表現出有競爭力的性能,并在基于段的準確性上大幅超過所有基線方法。
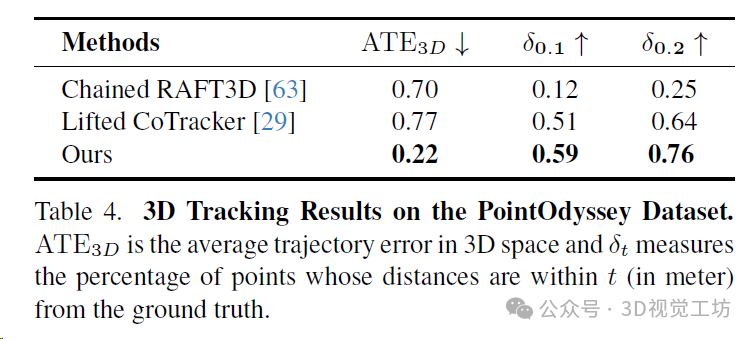
PointOdyssey是一個大規模的合成數據集,其中包含各種各樣的動畫人物,從人類到動物,置于不同的3D環境中。在PointOdyssey的測試集上評估,該測試集包含12個具有復雜運動的視頻,每個視頻大約有2000幀。采用PointOdyssey提出的評估度量標準,這些度量標準旨在評估非常長的軌跡。SpatialTracker在所有度量標準上一貫優于基線方法,并且優勢明顯。特別是,作者展示了通過使用更準確的地面真實深度,模型的性能可以進一步提升。這表明了SpatialTracker在單目深度估計的進步中持續改進的潛力。
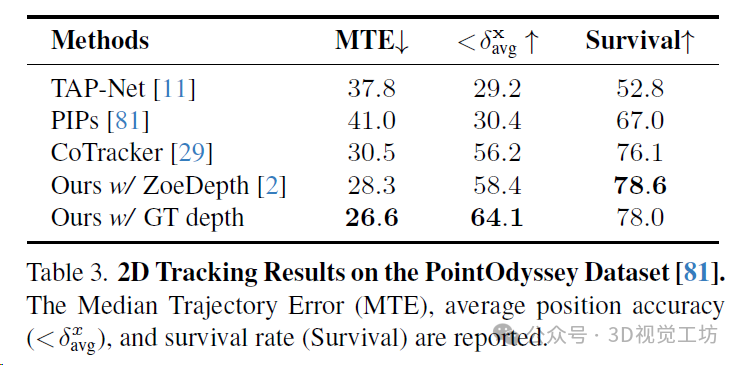
3D跟蹤結果。
7. 總結 & 討論
在這項工作中,作者展示了一個適當設計的三維表示對解決視頻中稠密且遠距離運動估計的長期挑戰至關重要。運動自然發生在三維空間中,而在三維空間中跟蹤運動使模型能夠更好地利用其在三維空間中的規律,例如 ARAP 約束。作者提出了一個新穎的框架,使用可學習的 ARAP 約束,利用三面體表示來估計三維軌跡,該約束能夠識別場景中的剛性群,并在每個群體內強制實施剛性。實驗表明,與現有基線方法相比,SpatialTracker具有優越的性能,并適用于具有挑戰性的真實世界場景。
SpatialTracker依賴于現成的單目深度估計器,其準確性可能會影響最終的跟蹤性能。然而,作者預計單目重建技術的進步將提高運動估計的性能。這兩個問題能夠更密切地相互作用,相互受益。
-
編碼器
+關注
關注
44文章
3525瀏覽量
133245 -
3D
+關注
關注
9文章
2835瀏覽量
106989 -
三維空間
+關注
關注
0文章
17瀏覽量
7452
原文標題:CVPR'24 Highlight!跟蹤3D空間中的一切!
文章出處:【微信號:3D視覺工坊,微信公眾號:3D視覺工坊】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
Labview中如何導入3D 的模型
自己搞一個3D打印機
3D打印:除了思想 一切皆可打印!
如何把OpenGL中3D坐標轉換成2D坐標
Vimeo宣布推出“現場直播”功能,允許用戶實時直播3D視頻
NVIDIA 3D MoMa:基于2D圖像創建3D物體

3D機器視覺基本原理及應用場景
VR虛擬空間中的3D 技術





 工商網監
工商網監
評論