 高性能計算中的芯片架構設計探索
高性能計算中的芯片架構設計探索
朝著多芯片集成和新型內存處理的演進標志著一種范式轉變,其中靈活性、效率和對各種工作負載的優化變得至關重要。 亞馬遜、谷歌、Meta、微軟、甲骨文和Akamai等世界領先的超大規模云數據中心公司正在推出專門針對云計算的異構多核架構,這對整個芯片行業的高性能CPU開發都產生了影響。
這些芯片都不太可能進行商業銷售。它們針對特定的數據類型和工作負載進行了優化,設計預算龐大,但可以通過提高性能和降低功耗來節省成本。行業的目標是在更小的面積上容納更多的計算能力,同時降低冷卻成本,而實現這一目標的最佳途徑就是采用定制化架構、緊密集成的微架構和精心設計的數據流。
這一趨勢始于近十年前,當時 AMD 開始采用異構架構和加速處理單元,取代了過去的同質多核 CPU 模式,但起步較慢。此后,異構架構開始興起,緊隨為移動消費設備設計的腳步,這些設備需要處理非常緊湊的占地面積以及嚴格的功耗和散熱要求。
Quadric市場營銷副總裁Steve Roddy說:“英特爾等行業巨頭的單片硅幾乎在每一個產品代碼中都有人工智能NPU。當然,人工智能先驅英偉達長期以來一直在其大獲成功的數據中心產品中混合使用 CPU、著色器(CUDA)內核和張量(Tensor)內核。未來幾年轉向芯片片組將鞏固這一轉變,因為系統購買者可以根據設計插槽的特定需求選擇計算和互連類型,從而確定芯片片組的組合。”
這在很大程度上是物理學和經濟學造成的。隨著擴展優勢的縮小,以及先進封裝技術的成熟--它允許在設計中添加更多的定制功能,而過去這些功能受限于網罩尺寸--每瓦特和每美元性能的競爭已進入白熱化階段。
西門子 EDA IC 部門市場總監 Neil Hand 說:“如今,每個人都在構建自己的架構,尤其是數據中心企業,而處理器架構的很大一部分取決于工作負載的外觀。與此同時,這些開發人員也在探索加速的最佳路徑,因為加速的方式有很多種。你可以選擇并行處理的方式,這對某些任務效果不好,但在其他任務下很有效。與此同時,應用對內存帶寬的限制越來越大,因此你會發現一些高性能計算公司開始把所有精力投入在內存控制器上。還有一些公司會說:‘這實際上是一個分解問題,我們要走加速器路線,擁有獨立的內核。’但我不認為存在一刀切的做法。“
Roddy指出,這些新型超級芯片內的CPU內核仍然遵循久經考驗的高性能CPU設計原則:快速、深度流水線,追逐指針的效率極高,但這已不再是設計團隊關注的唯一焦點。他說:”這些大型CPU現在與其他可編程引擎共享空間 — 如GPU和通用可編程NPU,用于加速AI工作負載。與大眾消費設備中高度專業化的 SoC 相比,一個顯著的區別是,AI 工作負載中的視頻轉碼或矩陣加速等任務避免了硬連邏輯塊(加速器)。為數據中心設計的設備需要保持可編程性,以應對各種工作負載,而不僅僅是消費類設備中的單一已知功能。“
然而,所有這些都需要更多的分析,而設計界正在繼續推動流程中更多的步驟。Hand說:”無論是通過工具,還是通過仿真或虛擬原型,你都擁有了幫助了解數據的工具。此外,該行業已經發展壯大,其專業化程度足以證明所花費用的合理性。第一部分是為了降低制造新硬件的風險,因為你有工具來了解情況,就不必保守行事。現在,市場已經開始分化,因此它的重要性值得資金投入。此外,現在也有了實現這一目標的方法。過去,當英特爾推出處理器時,要想與英特爾競爭,幾乎是不可能的。現在,通過生態系統、技術和其他因素的綜合作用,競爭變得容易多了。對于高性能計算公司來說,最初的低懸果實是:'我們只需獲得一個良好的平臺,讓我們可以按照自己的方式對其進行維度化,然后再放入一些加速器。所以我們開始看到人工智能加速器和視頻加速器,然后一些更深奧的公司開始追求機器學習。這意味著什么?這意味著他們需要非常高的 MAC 性能。他們會將處理器架構聚焦于此,并通過這種方式讓自己脫穎而出。"
再加上 RISC-V、可重復使用的芯片組和硬 IP,架構開始變得與幾年前大不相同。Hand說:“如果你看看現在的數據中心和數據中心中的整個軟件堆棧,在堆棧中添加一些東西并不像以前那樣困難,你不必重建整個數據中心。如今變得重要的是進行系統級分析的能力,應用的系統級協同設計已變得非常重要,而且更加容易,這就是一個移動的數據中心。”
許多人認為,應該開發新的架構來克服幾代 CPU 所面臨的內存挑戰。Fraunhofer IIS 自適應系統工程部高效電子學部門主管 Andy Heinig 說:“對 AI/ML 的需求將加速開發新的特定應用架構的進程。傳統的 CPU 如果能提供更好的內存接口來解決內存問題,就能成為這場革命的一部分。如果 CPU 能夠提供這種新的內存架構,那么 AI/ML 加速器就能與 CPU 一起成為數據中心的最佳解決方案。CPU 負責需要靈活性的經典任務,而加速器則為特定任務提供最佳性能。”
例如,Arm 直接與多家超大規模云供應商合作開發基于 Neoverse 的計算解決方案,以實現高性能、定制靈活性以及強大的軟件和硬件生態系統。這已經產生了公開發布的芯片,如 AWS 的 Graviton 和 Nitro 處理器、谷歌的 Mt.Evans DPU、微軟 Azure 的 Cobalt 100、英偉達的 Grace CPU 超級芯片以及阿里巴巴的Yitian 710。
Arm基礎架構業務線產品管理高級總監Brian Jeff說:“我們從這些和其他設計合作伙伴身上學到了很多東西。我們塑造高性能 CPU 和平臺開發的主要方式之一是通過對基礎設施工作負載的深入了解,實現特定的架構和微架構增強,尤其是對 CPU 管線前端和 CMN 網狀結構的增強。”
但捕捉到這種工作負載并為其開發芯片架構并不總是這么簡單。對于AI訓練和推理來說尤其如此,因為算法的改變可能會導致工作負載發生變化。
Synopsys接口IP首席產品經理Priyank Shukla表示:“目前正在訓練不同的模型,例如Meta公司公開的Llama模型和Chat GPT模型。所有這些模型都有一個模式和一定數量的參數。以 GPT-3 為例,它有 1,750 億個參數,每個參數的寬度為 2 字節,即 16 位。你需要在 2 個字節中存儲這么多信息--1750 億個參數,相當于 3500 億字節的內存。該內存需要存儲在所有共享該模型的加速器中,而該模型需要放置在加速器的結構中,參數需要放置在與該加速器相關的內存中。因此,你需要一個能接收更大模型并對其進行處理的結構。你可以以不同的方式實現該模型,即實現該算法的方式。有些工作可以串行方式進行,有些工作可以并行方式進行。以串行方式進行的工作需要與高速緩存保持一致,并將延遲降到最低。這種以串行方式進行的工作將在一個機架內進行分工,以便將延遲降到最低。以并行方式進行的工作將通過擴展網絡在不同機架之間進行分配。我們看到系統人員正在創建這一模型和算法,并在定制硬件中加以實現。
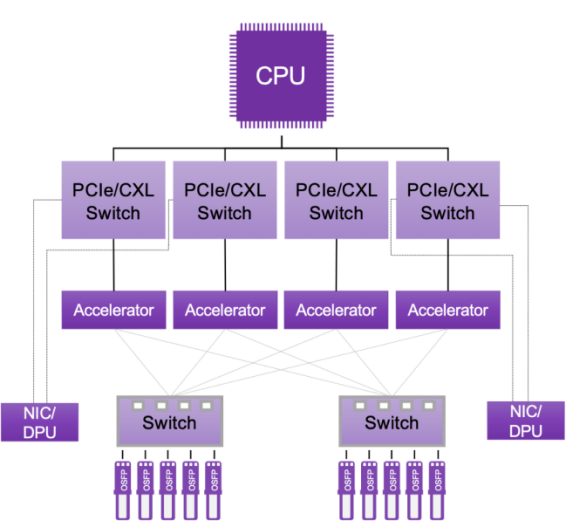 ?圖1:針對機器學習優化的服務器機架。來源:Synopsys
?圖1:針對機器學習優化的服務器機架。來源:Synopsys
組裝各種處理元件并非易事。Synopsys公司ASIP工具產品經理Patrick Verbist說:"它們是異構多核架構,通常是通用CPU和GPU的混合,具體取決于公司的類型,因為它們偏好其中一種。然后是具有固定功能的RTL加速器,它們與這些異構多核架構混合在一起。這些加速器運行的應用負載類型一般包括數據操作、矩陣乘法引擎、激活函數、參數壓縮/解壓縮、圖形權重等。但所有這些應用都有一個共同點,那就是需要進行大量運算。通常,這些計算是在標準或自定義數據類型上完成的。許多處理架構都支持Int 16,但如果只需要處理16位數據,則沒有必要在32位數據路徑中浪費16位。對此必須進行定制。因此,加速器不僅需要支持浮點 32 數據類型,還需要支持 int 8 和/或 int 16、半精度浮點、自定義 int 或自定義浮點類型的數據類型,而功能單元、運算器通常是矢量加法器、矢量乘法器、加法器樹和激活函數的組合。這些激活函數通常是指數或雙曲函數、平方根、大除法等超越函數,但都是矢量化的,而且具有單周期吞吐量要求,因為每個周期都要對這些東西進行新的運算。對于這類加速器,在異構性方面,我們看到許多客戶在異構空間中使用 ASIP(特定應用指令處理器)。ASIP 允許定制運算器,因此數據路徑和指令集只能以比常規 DSP 更有效的方式執行有限的一組操作。”
DSP 通常不夠靈活,因為它太通用了。另一方面,固定函數 RTL 可能不夠靈活,這就為“是的,我們需要比固定函數 RTL 更靈活、比通用 DSP 更不靈活的東西”的需求創造了空間。如果你看一下 GPU,在某種程度上,GPU 也是通用的。它必須支持各種工作負載,但不是所有的工作負載。這就是 ASIP 的作用所在,它支持靈活性和可編程性。你需要這種靈活性來支持一系列計算算法,以適應不斷變化的軟件或人工智能圖的要求,以及人工智能算法本身不斷變化的要求。"
西門子的 Hand 認為,考慮工作負載是一項艱巨的挑戰。
“為了解決這個問題,垂直整合的公司正在以這種方式投資于高性能計算,因為高性能計算并不比AI有什么不同,你只能根據你所看到的數據模式來工作,”Hand說道。“如果你是亞馬遜或微軟這樣的公司,那么你擁有大量的追蹤數據,而且不需要侵入任何數據,你知道你的機器存在哪些瓶頸。你可以利用這些信息,說‘我們發現我們得到了內存帶寬,我們必須對此做些什么,或者這是一個網絡帶寬問題,或者這是一個AI吞吐量問題,我們在這些領域遇到了問題。’這與邊緣上發生的挑戰沒有什么不同。邊緣的目標是不同的,我們經常在思考‘我可以擺脫什么?我不需要什么?’或者‘我可以在哪里縮小功率范圍?’而在數據中心,你會問,‘我如何能夠通過更多的數據,并且以一種不會燒毀設備的方式來做?隨著設備越來越大,我如何以可擴展的方式做到這一點?’”
Hand 認為,轉向多芯片封裝將推動許多有趣的發展,AMD 和英偉達等公司已經在使用這種技術。“現在,你可以開始為這些高性能計算應用提供一些有趣的即插即用組件,在很大程度上,你可以開始說,'這個應用需要什么互連芯片?這個應用的處理芯片是什么?'它提供了一個介于構建標準計算機與不做太大改動之間的中間地帶。我能做什么?我可以安裝不同的進程、不同的網卡、不同的 DIMM。作為云計算服務提供商,我所能做的有限。在另一端,微軟和 Azure 等大型云提供商會說,’我可以構建自己的完整 SOC,做我想做的任何事情。‘但你現在可以在中間地帶,比方說,你認為生物計算數據中心有市場,有足夠多的人進入這個領域,你可以賺到一些錢。你能組裝一個3D IC并使其在該環境中正常工作嗎?看到會有什么樣的東西出現會很有趣,因為這將降低進入門檻。我們已經看到像蘋果、英特爾、AMD和Nvidia等公司正在使用它作為一種加快產品開發速度、提供更多樣化而不必測試龐大芯片的方式。當你開始將它們與諸如環境的全數字孿生之類的東西結合起來時,你就可以開始理解環境中的工作負載,理解瓶頸,然后嘗試不同的分區,然后推進。”
Arm 的 Jeff 還認為,數據中心芯片架構也在發生變化,以適應 AI/ML 功能。“CPU上的推理非常重要,我們看到合作伙伴正在利用我們的SVE管道和矩陣數學增強功能以及數據類型來運行推理。我們還看到,通過高速相干接口緊密耦合的人工智能加速器正在發揮作用,DPUs 正在擴展其帶寬和智能,以便將節點連接在一起。"
多芯片集成是不可避免的
芯片行業非常清楚,對于許多計算密集型應用而言,單芯片解決方案已變得不現實。過去十年的最大問題是,向多芯片解決方案的轉變何時才能成為主流。Synopsys 研發總監 Sutirtha Kabir 說:”整個行業正處于一個拐點,你不能再回避這個問題了。我們談論著摩爾定律和'SysMoore',但設計人員必須在 CPU 和 GPU 中增加更多功能,而由于版圖尺寸限制、產量限制等原因,他們根本無法做到這一點。多芯片在這里是不可避免的,這帶來了一些有趣的考慮。首先,拿一張紙對折。這基本上就是多芯片的一個例子。你拿一塊芯片,把它折疊起來,如果你能巧妙地進行設計,你就能想到可以大大縮短時序。如果你要從頂部芯片到底部芯片,你可能只經過一小部分芯片的布線,但它們大多是芯片之間的球形焊點或焊絲焊點。“
多芯片設計所面臨的挑戰包括:確定有多少條路徑需要同步、時序應放在兩個芯片之間還是單獨關閉、L1 應放在頂部芯片還是底部芯片上,以及是否可以增加 L4。
Kabir解釋說:"從三維角度來看布局設計變得非常有趣。你可以把一棟單層房屋改建成三層或四層,但隨之而來的還有其他設計挑戰。你不能再忽視散熱問題了。散熱曾經是PCB的事,而現在系統設計師們認為這些芯片非常熱。黃仁勛(Jensen Huang)最近在 SNUG 上說,你在一端送入室溫水,另一端就會出來溫泉溫度。他是在開玩笑,但事實是,從溫度的角度來看,這些芯片確實非常熱,如果你在布局設計時不考慮到這一點,你的處理器就會被燒毀。這意味著你必須更早地開始這樣做這些工作。在三維布局設計方面,當涉及到工作負載時,你如何確保已經分析了多芯片的不同工作負載,并確保即使在沒有電路原理圖的情況下也能考慮到紅外、熱和時序等關鍵影響?我們稱之為零電路圖原理階段。這些考慮因素都變得非常有趣,因為你再也無法避免做多芯片,所以從晶圓廠的角度、從 EDA 的角度,這些都是生態系統的前沿和中心,而設計人員則處于中間位置。
與數據中心芯片的散熱問題相關的是低功耗設計問題。
Ansys 產品營銷總監 Marc Swinnen 說:“這些數據中心耗電量巨大。我參加了舊金山 ISSCC,我們的展臺就在英偉達旁邊,英偉達正在展示其人工智能訓練箱--一個裝有八個芯片、大量風扇和散熱片的大箱子。我們問它的耗電量有多大,他們說:'哦,最高時有 1 萬瓦,但平均也有 6000 瓦。'功率真是越來越瘋狂了。”
Arm公司的Jeff也認為,應對數據中心芯片新挑戰的最佳方法是采用全系統方法,包括指令集架構、軟件生態系統和特定優化、CPU微架構、互聯結構、系統內存管理和中斷控制,以及封裝內和芯片外I/O。”完整的系統方法使我們能夠與合作伙伴合作,根據現代工作負載和工藝節點定制 SoC 設計,同時利用基于芯片組的設計方法。”
這種定制芯片設計方法使數據中心運營商能夠優化其功耗成本和計算效率。Jeff 說:”我們 Neoverse N 系列的高效率使每個插槽的內核數達到 128c 到 192c 甚至更高。這些相同的 N 系列產品可以在更小的空間內擴展到 DPU 和 6g L2 設計以及邊緣服務器。我們的 V 系列產品面向云計算,具有更高的單線程性能和更高的矢量性能(用于人工智能推理和視頻轉碼等工作負載),同時仍然提供高效率。加速器附件的廣泛選擇使我們的合作伙伴能夠將定制處理和云原生計算的正確組合集成到根據其工作負載定制的SoC中。“
結論
由于高性能計算的演進性質,以及數據中心優化的不同方面,最終結果幾乎無法預測。西門子的Hand說:”在網絡技術爆炸式發展的初期,人們開始在數據中心內部建立南北和東西的路由,這改變了所有的網絡交換架構,因為這是一大瓶頸。這導致了對數據中心的整體重新思考。類似的事情也發生在內存方面,當你開始集成光學技術和一些更智能的內存時,你會發現這將會是非常有趣的事情。”
Hand 提到了幾年前的一次英特爾開發者大會,當時該公司解釋了如何利用硅光子學中的表面發射光學技術將內存與數據中心機架中的存儲分離開來。他說:“他們有一個統一的內存結構,可以在服務器之間共享,也可以從不同的服務器分配內存。因此,數據中心的拓撲結構開始變得非常有趣。即使在機架中,你也可以看到像NVIDIA這樣的公司擁有的AI系統結構。最大的變化是,人們可以看看它,如果有市場需求,你就可以構建它。我們一直認為,架構的關鍵在于核心是否快速。我們從’內核快不快?’過渡到’我有足夠的內核嗎?’但問題遠不止于此。一旦開始打破馮-諾依曼架構,開始使用不同的內存流,開始關注內存內計算,它就會變得非常酷。然后你會思考,‘高性能計算到底意味著什么?”
審核編輯:黃飛
-
芯片
+關注
關注
454文章
50460瀏覽量
421967 -
amd
+關注
關注
25文章
5449瀏覽量
133959 -
cpu
+關注
關注
68文章
10829瀏覽量
211183 -
數據類型
+關注
關注
0文章
236瀏覽量
13610 -
RISC-V
+關注
關注
44文章
2233瀏覽量
46045
原文標題:面向高性能計算的芯片架構設計
文章出處:【微信號:ICViews,微信公眾號:半導體產業縱橫】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
如何優化SOC芯片性能
《算力芯片 高性能 CPUGPUNPU 微架構分析》第二篇閱讀心得:芯片拓撲學:并行擴展與CPU設計的巨頭對決
邊緣計算架構設計最佳實踐
【「算力芯片 | 高性能 CPU/GPU/NPU 微架構分析」閱讀體驗】--了解算力芯片CPU
《算力芯片 高性能 CPU/GPU/NPU 微架構分析》第1-4章閱讀心得——算力之巔:從基準測試到CPU微架構的深度探索
【「算力芯片 | 高性能 CPU/GPU/NPU 微架構分析」閱讀體驗】--全書概覽
名單公布!【書籍評測活動NO.43】 算力芯片 | 高性能 CPU/GPU/NPU 微架構分析
芯品# 高性能計算芯片
構建高性能計算芯片

揭秘GPU: 高端GPU架構設計的挑戰

異構眾核系統高性能計算架構





 工商網監
工商網監
評論