 利用NVIDIA組件提升GPU推理的吞吐
利用NVIDIA組件提升GPU推理的吞吐
利用NVIDIA 組件提升GPU推理的吞吐
本實踐中,唯品會 AI 平臺與 NVIDIA 團隊合作,結合 NVIDIA TensorRT 和 NVIDIA Merlin HierarchicalKV(HKV)將推理的稠密網絡和熱 Embedding 全置于 GPU 上進行加速,吞吐相比 CPU 推理服務提升高于 3 倍。
應對GPU推理上的難題
唯品會(NYSE: VIPS)成立于 2008 年 8 月,總部設在中國廣州,旗下網站于同年 12 月 8 日上線。唯品會主營業務為互聯網在線銷售品牌折扣商品,涵蓋名品服飾鞋包、美妝、母嬰、居家、生活等全品類。
唯品會 AI 平臺服務于公司搜索、推薦、廣告等業務團隊,提供公司級一站式服務平臺。搜索、推薦、廣告等業務旨在通過算法模型迭代,不斷優化用戶購買體驗,從而提升點擊率和轉化率等業務指標,最終實現公司銷售業績增長。
在使用 GPU 打開推理算力天花板過程中,遇到了如下問題:
稠密網絡,如何獲取更好的 GPU 推理性能;
Embedding table 如何使用 GPU 加速查詢。
為了解決上面的問題,我們選擇使用了 NVIDIA TensorRT 和 Merlin HierarchicalKV。具體原因如下:
稠密網絡使用 TensorRT 推理,通過 TensorRT 和自研 Plugin 方式獲取更好的推理性能;
HierarchicalKV 是一個高性能 GPU Table 實現,我們將熱 Embedding 緩存在 GPU 中,冷 Embedding 則通過內存和分布式 KV 存儲,加速查表過程。
GPU推理服務設計方案
AI 平臺支持搜索、推薦、廣告等所有算法業務,提供大規模分布式訓練、推理、實時模型等基礎引擎平臺,打造屬于唯品會自己的 AI 基礎能力引擎。
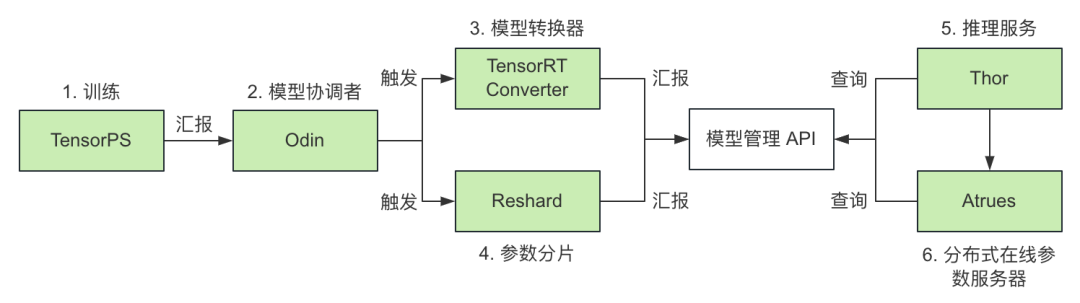
圖 1. GPU 推理服務工作流程圖
如上圖所示,支持 GPU 推理服務,可以分為如下幾步:
TensorPS(自研訓練框架)
支持離線和實時訓練;
離線訓練:生成天級全量模型,完成后同步給 Odin;
實時訓練:生成小時級別的全量模型和分鐘級別的增量模型,完成后同步給 Odin;
2. Odin(模型協調者)
(離線/實時)單機模型的全量模型:觸發 TensorRT Converter;
(離線/實時)分布式模型的全量模型:同時觸發 TensorRT Converter 和 Reshard;
(離線/實時)單機/分布式模型的增量模型:觸發 TensorRT Converter;
3. TensorRTConverter(模型轉換器)
將 Dense 網絡轉換成 TensorRT Engine;
轉化完成,如果是全量模型,向模型管理 API 匯報全量版本;如果是增量模型,向模型管理 API 匯報增量版本;
4. Reshard(參數分片模塊)
對模型參數分片后,向模型管理 API 匯報版本;
分片后參數,同步到分布式在線參數服務 Atreus;
5. Thor(自研推理服務)
單機模型:通過模型管理 API 獲取全量模型版本,拉取模型并啟動推理服務 Thor;
分布式模型:需要部署分布式參數服務 Atreus 和推理服務 Thor;
如果開啟了實時模型特性,Thor 會定時通過模型管理 API 獲取增量版本,拉取并更新增量模型;
6. Atreus(自研分布式在線參數服務)
僅用于分布式模型,可支持 TB 級參數;
如果開啟了實時模型特性,Atreus 會定時通過模型管理 API 獲取增量版本,拉取并更新增量參數。
GPU模型推理
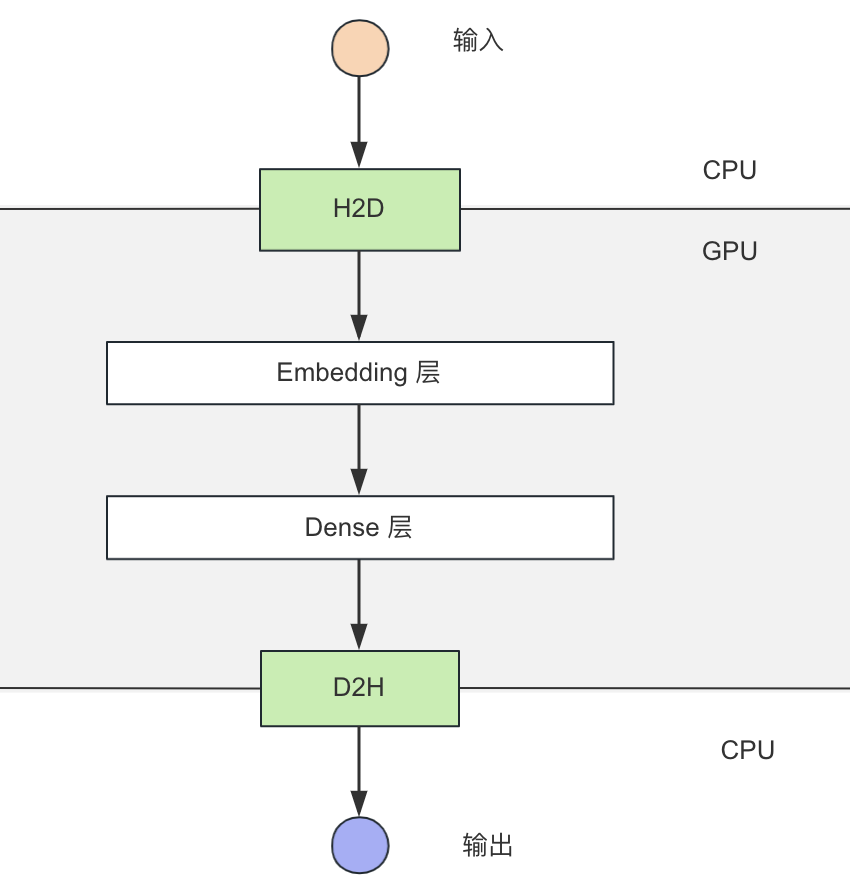
圖 2. 前向計算流程圖
如上圖所示,前向計算可以分為如下幾步:
H2D 拷貝(CPU -> GPU);
Embedding 層,使用 GPU Table lookup(GPU);
Dense 層,使用 TensorRT +自研 Plugin 推理(GPU);
D2H 拷貝(GPU -> CPU)。
稠密網絡使用TensorRT在GPU上計算
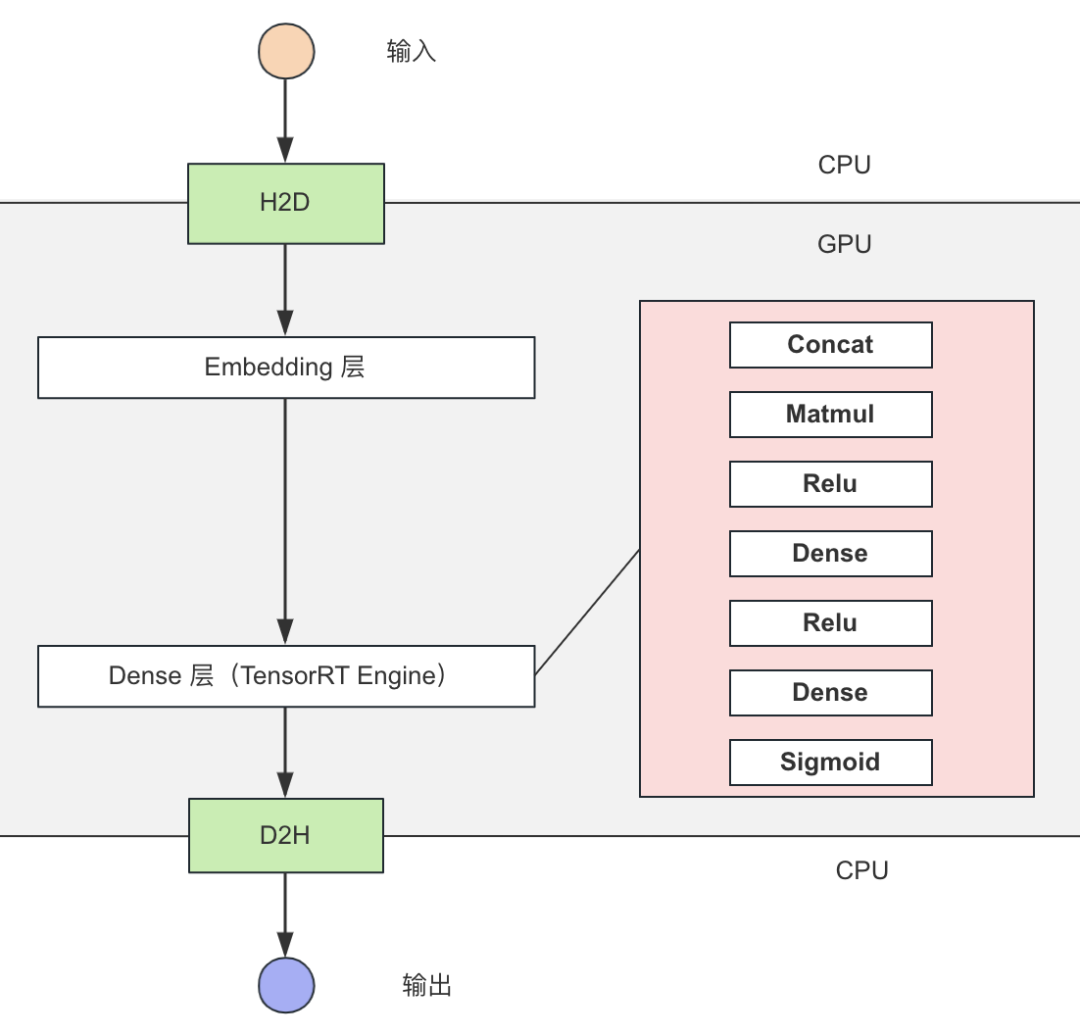
圖 3. 稠密網絡 TensorRT 推理優化
如上圖所示:
稠密網絡使用 TensorRT 推理,結合自定義 Plugin 實現推理性能優化。
利用HierarchicalKV實現GPUTablelookup
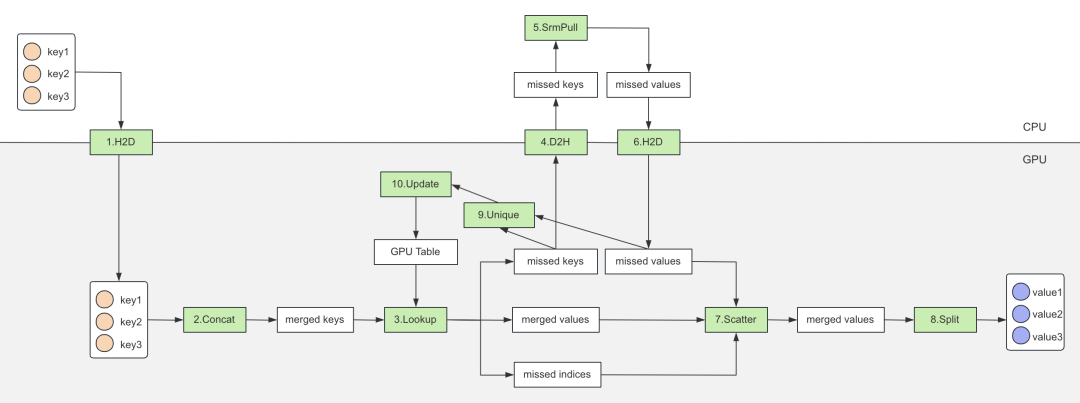
圖 4. 基于 HierarchicalKV 的 GPU Table
如上圖所示,查表過程可以分為如下幾步:
將 keys 拷貝到 GPU;
將 keys concat 成一個大的 merged keys,減少后續查表次數;
merged keys 查 GPU Table,輸出 merged values,并輸出未命中 missed keys 和 missed indices;
拷貝 missed keys 到 CPU;
查詢 Atreus(分布式參數服務器),獲取 missed values;
missed values 拷貝到 GPU;
將 missed values 更新到 merged values;
將 merged values 輸出 Split 成多個 Tensor(和 keys 一一對應);
對 missed keys 進行去重;
去重之后,異步更新 GPU Table。
TensorRTConverter實現GPU模型轉換
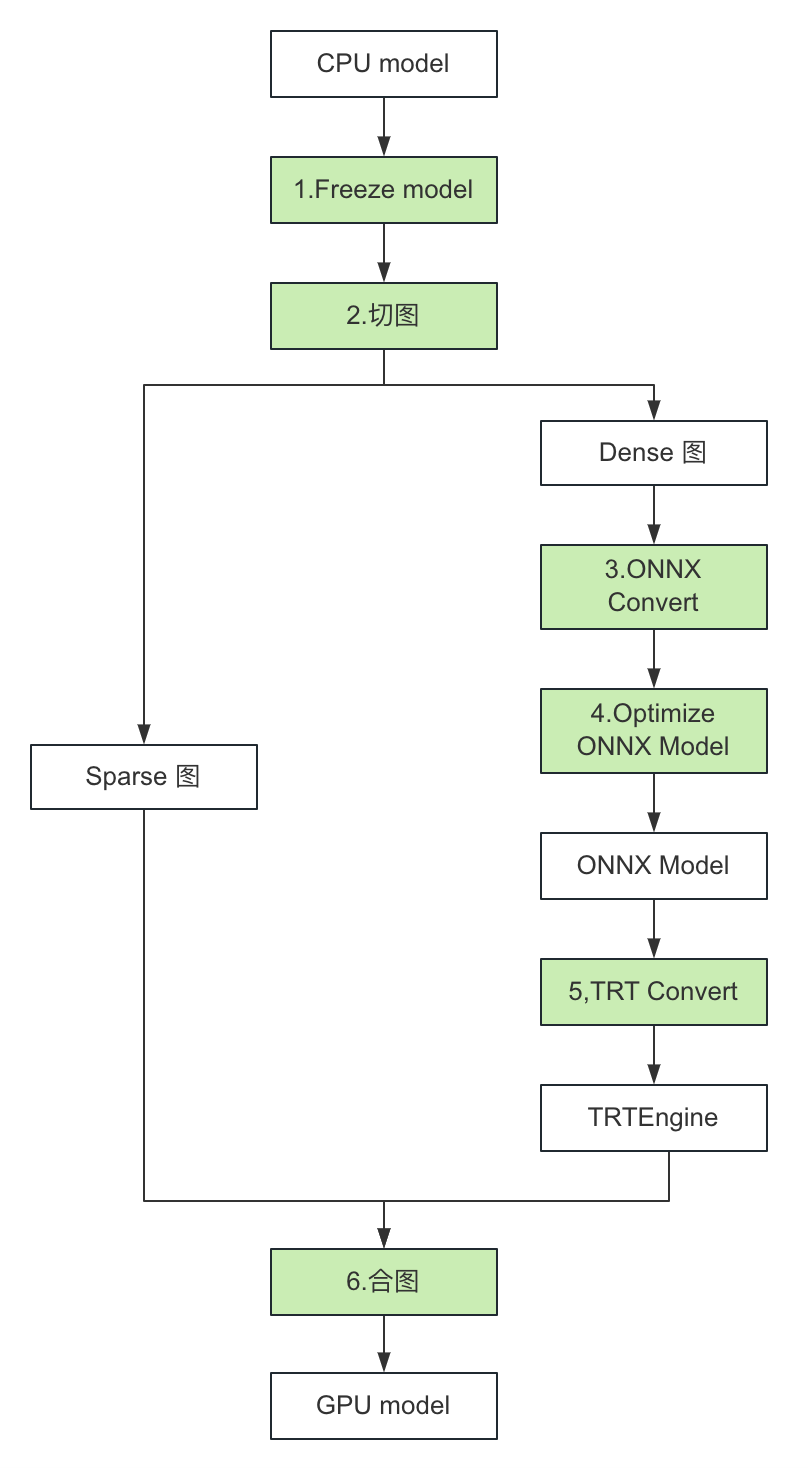
圖 5. TensorRT Converter 轉換流程
如上圖所示,TensorRT Converter 可以分為如下幾步:
Freeze CPU 模型;
切分模型 Graph 成 Sparse 和 Dense 兩個子圖,Sparse 圖在 GPU 上執行,Dense 圖經過圖優化后使用 TensorRT 推理;
Dense 圖轉化成 ONNX 模型;
優化 ONNX 模型,把圖中 OP 替換成自定義的高性能 TensorRT Plugin;
轉換 ONNX 模型成 TensorRT Engine;
合并 Sparse 圖和 TensorRT Engine 生成 GPU 模型。
自研CUDAKernel,提高性能
GPUTable加速查表
基于 HierarchicalKV 增強了 find 接口,支持獲取未命中 keys indices 等信息,在高命中率情況下有更好的性能,并貢獻給社區:
void find(const size_type n,
const key_type* keys, // (n)
value_type* values, // (n, DIM)
key_type* missed_keys, // (n)
int* missed_indices, // (n)
int* missed_size, // scalar
score_type* scores = nullptr, // (n)
cudaStream_t stream = 0) const
2. GPU支持CSR(Compressedsparserow)格式的序列特征
根據統計,序列特征有 85%+的數據都是填充值,使用 CSR 格式壓縮序列特征可以大幅度減小序列特征大小。考慮到搜推序列數據的特殊性(填充值都在序列尾部),這里僅使用 value 和 offset 兩個序列表示原始稀疏矩陣,如下圖:
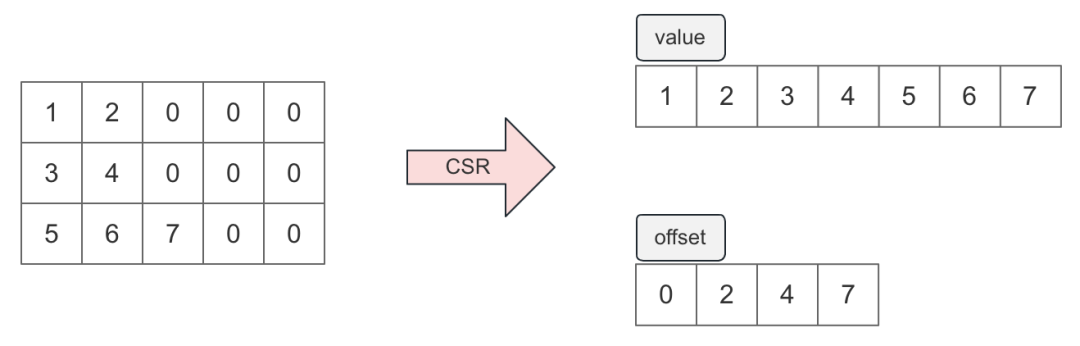
圖 6. CSR 的稀疏矩陣
通過 Fusion 的方式,減少 Lookup 過程 CUDA Kernel 數量,提升推理性能。

圖 7. Lookup 過程優化對比
優化前:N 個輸入對應 N 個 Lookup CUDA Kernel;
優化后:通過提前合并,將 CUDA Kernel 數量減少為 3 個(Concat、Lookup 和 Split)。
通過 Fusion 的方式,減少 CSR 處理過程 CUDA Kernel 數量,提升推理性能,下圖以 ReduceSum 舉例。
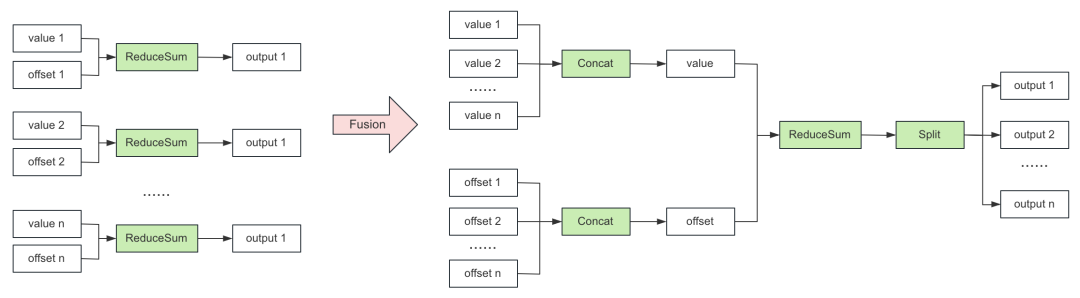
圖 8. CSR 處理優化流程
優化前:N 對輸入對應 N 個 ReduceSum CUDA Kernel;
優化后:通過提前合并,將 CUDA Kernel 數量減少為 4 個(2 個 Concat,1 個 ReduceSum 和 1 個 Split)。
3.H2D,合并CPU->GPU內存拷貝
搜推模型中有較多的特征輸入,GPU 推理中需要將這些 Tensor 從 CPU 拷貝到 GPU,頻繁小內存的 cudaMemcpy 會導致性能下降,最佳實踐是將這些 Tensor 打包在一塊連續內存中,將整個大內存 H2D 拷貝到 GPU。
4.Tile算子融合
搜推模型中有超過 200個 Tile,大量的 Kernel Launch 會帶來 GPU 推理性能惡化,最佳實踐是進行 Kernel Fusion,在一個大的算子中執行多個小 Kernel,從而充分發揮 GPU 的并發優勢。
持續在搜推廣場景中GPU加速
唯品會 AI 平臺一直追求性能上的極致,未來將會持續與 NVIDIA 技術團隊合作,繼續探索使用 HierarchicalKV 在訓練超大型模型上的 GPU 性能優化,在提升 GPU 性能方面進行不斷地探索和實踐,也會對 Generative Recommenders 進行探索和實踐。
審核編輯:劉清
-
NVIDIA
+關注
關注
14文章
4935瀏覽量
102807 -
CSR
+關注
關注
3文章
118瀏覽量
69596 -
GPU芯片
+關注
關注
1文章
303瀏覽量
5781
原文標題:利用 NVIDIA Merlin HierarchicalKV 實現唯品會在搜推廣場景中的 GPU 推理實踐
文章出處:【微信號:NVIDIA-Enterprise,微信公眾號:NVIDIA英偉達企業解決方案】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
NVIDIA-SMI:監控GPU的絕佳起點
NVIDIA 在首個AI推理基準測試中大放異彩
Nvidia GPU風扇和電源顯示ERR怎么解決
在Ubuntu上使用Nvidia GPU訓練模型
充分利用Arm NN進行GPU推理
NVIDIA宣布其AI推理平臺的重大更新
NVIDIA Triton推理服務器簡化人工智能推理
使用NVIDIA GPU助力美團CTR預測服務升級
利用NVIDIA Triton推理服務器加速語音識別的速度
NVIDIA Triton助力騰訊PCG加速在線推理
NVIDIA助力阿里巴巴天貓精靈大幅提升服務運行效率
騰訊云TI平臺利用NVIDIA Triton推理服務器構造不同AI應用場景需求
螞蟻鏈AIoT團隊與NVIDIA合作加速AI推理
NVIDIA GPU 加速 WPS Office AI 服務,助力打造優質的用戶體驗





 工商網監
工商網監
評論