") MySQL聯(lián)表查詢優(yōu)化
MySQL聯(lián)表查詢優(yōu)化
sql執(zhí)行順序
執(zhí)行FROM語句
執(zhí)行ON過濾
join添加外部行
執(zhí)行where條件過濾
執(zhí)行g(shù)roup by以及分組語句,(開始使用select中的別名,后面的語句中都可以使用別名)
執(zhí)行having
select列表
執(zhí)行distinct去重復(fù)數(shù)據(jù)
執(zhí)行order by字句
執(zhí)行l(wèi)imit字句
多表聯(lián)合查詢優(yōu)化建議
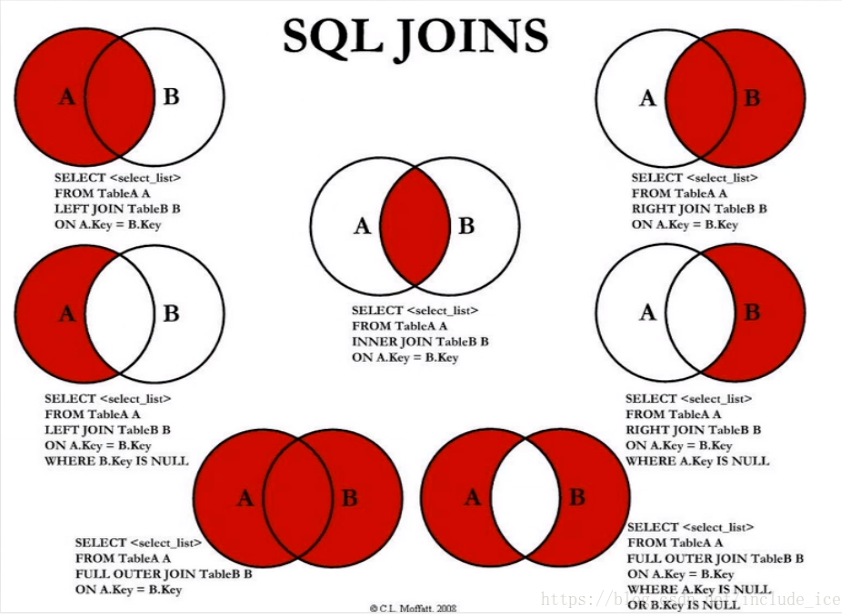
1、使用顯示連接left join(right join,inner join),盡量避免隱式連接(where逗號(hào)連接表 .... and .... and ...)這類寫法,假設(shè)三張表每張表有一千條數(shù)據(jù),本意想查出<=1000條數(shù)據(jù),當(dāng)使用where語句查詢,就查出了1000*1000*1000=10億條數(shù)據(jù),很大程度上浪費(fèi)了內(nèi)存執(zhí)行時(shí)間?
ps:在不使用on語法時(shí),join、inner join、逗號(hào)、cross join結(jié)果相同,都是取2個(gè)表的笛卡爾積。逗號(hào)與其他操作符優(yōu)先級(jí)不同,所以有可能產(chǎn)生語法錯(cuò)誤,盡量減少用逗號(hào)
2、需要哪些列就查哪些列,不要有很多冗余的列查詢出來,有的時(shí)候一張表當(dāng)中有好幾十個(gè)字段,我們需要的可能就是其中的三四個(gè)或者四五個(gè)字段,在這樣的情況下,我們就直接查這幾個(gè)我們需要的字段就可以了
3、盡量避免使用 .* ,因?yàn)槭褂命c(diǎn)* 需要先去數(shù)據(jù)字典當(dāng)中查找你所查找的表當(dāng)中所擁有的字段,再轉(zhuǎn)換成對(duì)應(yīng)的字段的放在select后面查詢出來
4、優(yōu)先使用大于等于,比大于執(zhí)行效率高
5、查詢的時(shí)候我們應(yīng)該把更具有限制條件的條件語句放在最前面,比如我們有一張學(xué)生成績表(score),分別有學(xué)號(hào)、語數(shù)英三科成績以及總成績總共五列,要查找數(shù)學(xué)、英語優(yōu)秀,語文及格,總成績?cè)偾耙话倜娜?/p>
select * from score where sno in(select sno from score where language>60 and math>80 and english>80 order by total_score desc)(慢) select sno,language,math,english,total_score from score where exist (select sno from where engilsh>=80 and math>=80 and language>=80 order by total_score desc)(快)
上面那條語句將大于60分的條件放前面,大于80的放后面,導(dǎo)致很多情況下多查了很多數(shù)據(jù)
就比如說一張表里有有很多字段,有一百萬條記錄,主鍵id由1到1百萬,當(dāng)我們需要查找小于1000大于100的數(shù)據(jù)的時(shí)候,我們就應(yīng)該把小于1000這個(gè)條件放前面,這就是相對(duì)比下最具限制性的條件
6、盡量使用連接查詢 替代 子查詢,因?yàn)樽硬樵冃枰?銷毀臨時(shí)表,開銷昂貴
select a.id,a.name from a where a.id in(select b.aid from b where b.id=123); select a.id,a.name from a inner join b on a.id=b.aid wehre b.id=123;
子查詢執(zhí)行表現(xiàn)為,外表遍歷每一條,內(nèi)表都需要掃描一次,邊遍歷查詢外表,邊掃描內(nèi)表;
如果數(shù)量較大,則使用連接查詢,因?yàn)樽硬樵儠?huì)掃描多次;
如果數(shù)據(jù)量較小,則子查詢與連接查詢對(duì)比不明顯
如果需要用到子查詢:
6.1、用EXISTS(或內(nèi)連接)替代IN、用NOT EXISTS(或者外連接)替代NOT IN
6.2、用EXISTS替換DISTINCT
7、where條件盡量使用索引,避免在索引列使用計(jì)算(加減乘除),避免索引列使用函數(shù)(轉(zhuǎn)換類型),避免索引列使用is(not)null,避免索引列使用通配符,否則數(shù)據(jù)庫將放棄索引,執(zhí)行全表掃描
8、where代替having,優(yōu)化group by
提高GROUP BY 語句的效率, 可以通過將不需要的記錄在GROUP BY 之前過濾掉,如下
低效: SELECT JOB , AVG(SAL) FROM EMP GROUP BY JOB HAVING JOB = ‘PRESIDENT' OR JOB = ‘MANAGER'
高效: SELECT JOB , AVG(SAL) FROM EMP WHERE JOB = ‘PRESIDENT' OR JOB = ‘MANAGER' GROUP BY JOB
9、Order By語句加在索引列,最好是主鍵PK上
10、用EXISTS替換DISTINCT
當(dāng)提交一個(gè)包含一對(duì)多表信息(比如部門表和雇員表)的查詢時(shí),避免在SELECT子句中使用DISTINCT. 一般可以考慮用EXIST替換, EXISTS 使查詢更為迅速,因?yàn)镽DBMS核心模塊將在子查詢的條件一旦滿足后,立刻返回結(jié)果
11、in是把外表和內(nèi)表作hash連接,而exists是對(duì)外表作loop循環(huán),每次loop循環(huán)再對(duì)內(nèi)表進(jìn)行查詢,一直以來認(rèn)為exists比in效率高的說法是不準(zhǔn)確的。如果查詢的兩個(gè)表大小相當(dāng),那么用in和exists差別不大;如果兩個(gè)表中一個(gè)較小一個(gè)較大,則子查詢表大的用exists,子查詢表小的用in(減少遍歷次數(shù))
12、字符串型=,in,like’abc%‘索引生效;!=, not in, like'%abc', like'a%bc'索引失效
13、數(shù)值型=, !=, in, not in都可以索引生效
索引一般性建議
對(duì)于單鍵索引,盡量選擇針對(duì)當(dāng)前query過濾性更好的索引
在選擇組合索引的時(shí)候,當(dāng)前Query中過濾性最好的字段在索引字段順序中,位置越靠前越好
在選擇組合索引的時(shí)候,盡量選擇可以能夠包含當(dāng)前query中的where子句中更多字段的索引
盡可能通過分析統(tǒng)計(jì)信息和調(diào)整query的寫法來達(dá)到選擇合適索引的目的
索引口訣
全職匹配我最愛,最左前綴要遵守
帶頭大哥不能死,中間兄弟不能斷
索引列上少計(jì)算,范圍之后全失效
like百分寫最右,覆蓋索引不寫星
不等空值還有or,索引失效要少用
var引號(hào)不可丟,SQL高級(jí)也不難
審核編輯:黃飛
-
SQL
+關(guān)注
關(guān)注
1文章
759瀏覽量
44069 -
MySQL
+關(guān)注
關(guān)注
1文章
801瀏覽量
26439
原文標(biāo)題:MySQL聯(lián)表查詢優(yōu)化
文章出處:【微信號(hào):magedu-Linux,微信公眾號(hào):馬哥Linux運(yùn)維】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
MySQL表分區(qū)類型及介紹
Mysql優(yōu)化選擇最佳索引規(guī)則
MySQL優(yōu)化之查詢性能優(yōu)化之查詢優(yōu)化器的局限性與提示
詳解MySQL的查詢優(yōu)化 MySQL邏輯架構(gòu)分析
MySQL 基本知識(shí)點(diǎn)梳理和查詢優(yōu)化
MySQL查詢幫助的使用
MySQL數(shù)據(jù)庫:理解MySQL的性能優(yōu)化、優(yōu)化查詢

為什么ElasticSearch復(fù)雜條件查詢比MySQL好?

你會(huì)從哪些維度進(jìn)行MySQL性能優(yōu)化?1
你會(huì)從哪些維度進(jìn)行MySQL性能優(yōu)化?2
查詢SQL在mysql內(nèi)部是如何執(zhí)行?





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論