 基于英特爾至強可擴展處理器的浪潮信息服務器AI訓推一體化方案
基于英特爾至強可擴展處理器的浪潮信息服務器AI訓推一體化方案
概 述
大模型已經成為新一輪數字化轉型的重要驅動力,為了降低對算力與語料資源的要求,加快大模型在實際應用的部署,目前企業普遍在開源/商用大模型中,加入少量語料對模型進行預訓練,以構建面向具體場景的微調版大模型,并在實際業務中進行模型推理,這種方式在經濟性與靈活性方面通常更具優勢。對于輕量級的人工智能 (AI) 場景而言,找到一個既經濟又靈活的AI微調和推理解決方案顯得尤為重要。
浪潮信息和英特爾緊密合作,結合在硬件和軟件開發方面的技術優勢,推出了基于英特爾至強可擴展處理器的浪潮信息服務器AI訓推一體化方案。該AI訓推一體化方案支持計算機視覺模型的推理工作,同時還支持大語言模型 (LLM) 的微調和推理工作,并可以用于支持其他通用業務。這一方案具備高性能、高性價比、高靈活性等優勢,可以充分滿足用戶構建輕量級AI微調與推理系統的需求。
挑戰
在AI模型尤其是大模型微調及推理過程中,用戶普遍面臨著以下性能挑戰:
如何滿足AI微調及推理對于算力的要求
在AI模型微調和推理過程中,特別是在大語言模型微調中,對算力的需求尤其突出。這既包括硬件提供的算力支持,也包括向量化指令集和矩陣計算指令集的支持。
如何滿足模型微調對于內存規模的需求
在模型訓練和微調中,需要存儲中間激活值、梯度信息,以及用于優化器(如Adam、AdamW等)參數更新的信息,這就需要龐大的內存作為支撐。模型微調實踐表明,Batch size設定不能太小(通常需要大于16),避免Batch size過小造成不穩定的優化器梯度下降。同時,訓練過程中會產生大量的中間激活值,所需的內存遠遠超過模型本身的大小。但是,傳統訓練方案(雙路服務器,一機兩卡/一機四卡/一機八卡)由于顯存數量有限,難以滿足模型微調的顯存需求。
如何提供充足的內存帶寬
AI推理任務對內存帶寬有著高度需求,因此,AI訓推服務器需要提供足夠大的內存帶寬與內存訪問速度,傳統的雙路服務器在內存帶寬與訪問速度方面難以支撐模型的高效推理。
如何實現便捷擴展
為了提升服務器的算力、內存規模和帶寬,模型訓練和推理通常需要將多個 CPU socket高效鏈接起來。而采用以太網作為連接方式將面臨速度慢、不穩定、多顆CPU socket的擴展性能差等問題。 除了性能挑戰之外,用戶還希望能夠盡可能地降低模型微調、推理平臺的構建與運營成本,提升平臺的靈活性,從而進一步推動AI任務的普及和發展。
基于英特爾至強可擴展處理器的浪潮信息服務器AI訓推一體化方案
浪潮信息服務器AI訓推一體化方案的硬件基礎是基于第四代英特爾至強可擴展處理器的浪潮信息四路服務器。該服務器能夠充分發揮第四代英特爾至強可擴展處理器強大的計算性能,并借助英特爾高級矩陣擴展(英特爾AMX)和 IntelExtension for PyTorch (IPEX) 進一步加速大模型微調和推理任務,幫助用戶攻克AI應用中的各項挑戰。

圖1. 浪潮信息服務器AI訓推一體化方案架構
浪潮信息四路服務器
為了支持在單臺浪潮信息四路服務器上,實現復雜的計算機視覺模型和大語言模型的微調及推理任務,浪潮信息服務器AI訓推一體化方案推薦采用英特爾至強金牌處理器或以上的型號。這不僅可以為高負荷情況下的任務提供額外的性能提升,還能支持在多線程處理能力上取得優秀表現。 該方案推薦搭配DDR5內存。DDR5內存提供了比前代更高的帶寬,特別適合處理內存密集型的應用任務。當處理大規模數據和復雜的計算任務時,DDR5能確保系統運行的流暢性。同時,方案建議按照每個內存通道1個DIMM (1DPC) 的配置,將內存擴展至2TB以上,以滿足同時對高帶寬和高內存容量的需求。這一配置不僅可以優化系統的運行效率,還能在處理大型數據集時,提供足夠的內存支持,從而確保微調任務以及推理任務的順暢執行。

圖2-1. NF8260M7(2U4路)服務器

圖2-2. NF8480M7(4U4路)服務器
第四代英特爾至強可擴展處理器提供強大AI算力支持
第四代英特爾至強可擴展處理器通過創新架構增加了每個時鐘周期的指令,每個插槽多達60個核心,支持8通道DDR5內存,有效提升了內存帶寬與速度,并通過PCIe 5.0(80個通道)實現了更高的PCIe帶寬提升。第四代英特爾至強可擴展處理器提供了出色性能和安全性,可根據用戶的業務需求進行擴展。借助內置的加速器,用戶可以在AI、分析、云和微服務、網絡、數據庫、存儲等類型的工作負載中獲得優化的性能。通過與強大的生態系統相結合,第四代英特爾至強可擴展處理器能夠幫助用戶構建更加高效、安全的基礎設施。
第四代英特爾至強可擴展處理器內置了創新的英特爾AMX加速引擎。英特爾AMX針對廣泛的硬件和軟件優化,通過提供矩陣類型的運算,顯著增加了人工智能應用程序的每時鐘指令數 (IPC),可為AI工作負載中的訓練和推理上提供顯著的性能提升。在實際AI推理負載中,英特爾AMX能夠加速模型微調、提升模型的首包推理速度并降低延遲。英特爾AVX-512指令集能夠加速在KV Cache模式下的第二個及以上的token推理。
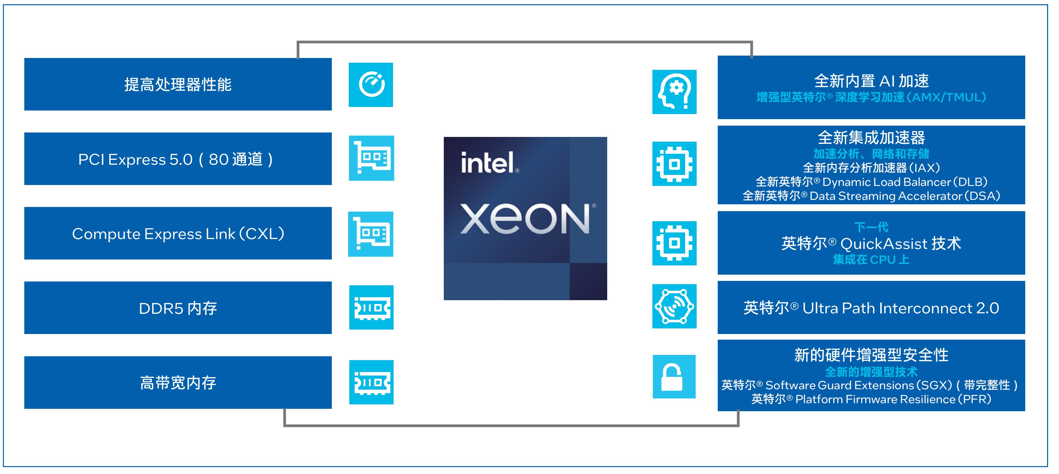
圖3. 英特爾至強可擴展處理器為數據中心提供多種優勢
英特爾豐富軟件生態助力加速AI部署,釋放算力潛能
除了在硬件領域取得顯著進展之外,英特爾在人工智能領域亦構建了一個強大且全面的軟件生態系統,提供了包含 IntelExtension for PyToch和英特爾oneDNN在內的豐富軟件,能夠幫助用戶充分利用英特爾硬件的強大性能,提高計算效率和運行速度。
IntelExtension for PyTorch是一種開源擴展,可優化英特爾處理器上的深度學習性能。許多優化最終將包含在未來的PyTorch主線版本中,但該擴展允許PyTorch用戶更快地獲得最新功能和優化。IntelExtension for Pytorch充分利用了英特爾AVX- 512、矢量神經網絡指令 (VNNI) 和英特爾AMX,將最新的性能優化應用于英特爾硬件平臺。這些優化既包括對PyTorch操作符、Graph和Runtime的改進,也包括特定于使用場景的自定義操作符和優化器的添加。用戶可以通過簡易的Python API,只需對原始代碼做出微小更改即可在英特爾硬件平臺應用最新性能優化。
英特爾oneAPI Deep Neural Network Library (oneDNN) 是英特爾在軟件優化領域的又一亮點。英特爾oneDNN是一個開源性能庫,專為深度學習應用設計,支持廣泛的深度學習框架和應用。該庫提供了高級性能優化的深度學習原語,專門優化了用于英特爾架構的深度學習操作,包括英特爾至強處理器和 英特爾集成顯卡。通過oneDNN,開發者可以輕松地在英特爾硬件上實現高效的深度學習模型推理和訓練,而無需深入了解底層硬件細節。英特爾oneDNN已經被融合到多個開源平臺中,包括PyTorch和TensorFlow等。
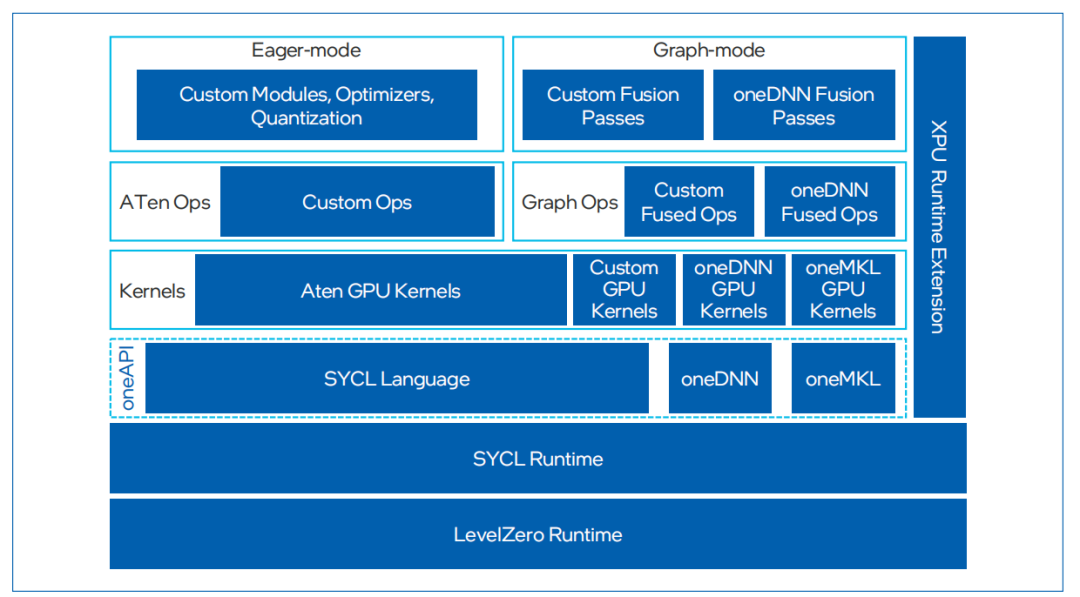
圖4. IntelExtension for PyTorch框架 
測 試 驗 證
在上述軟硬件基礎上,浪潮信息與英特爾合作,從多個方面入手,優化了AI模型微調及推理性能。
采用英特爾AMX加速器和IntelExtension for PyTorch加速模型微調
得益于對IntelExtension for PyTorch的支持,以及強大的運算能力和超大內存,浪潮信息四路服務器在微調方面表現出強大的性能。浪潮信息四路服務器采用分布式數據并行 + LoRA (Low-Rank Adaptation) 微調以減少通信開銷,其具備的大內存有利于支持更大的batch size,從而提高訓練的收斂效果,改善模型質量。目前,單臺浪潮信息四路服務器能夠支持高達30B模型的微調。
模型微調的測試數據如圖5顯示,當采用alpaca數據集(6.5M tokens,數據集大小24.2MB)時,單臺四路服務器可以在72分鐘的時間內完成Llama-2-7B微調 (batch size = 16);可以在362分鐘的時間內完成Llama-30B模型的微調 (batch size = 16),穩定支持非梯度累積模式下高達64的batch size1。
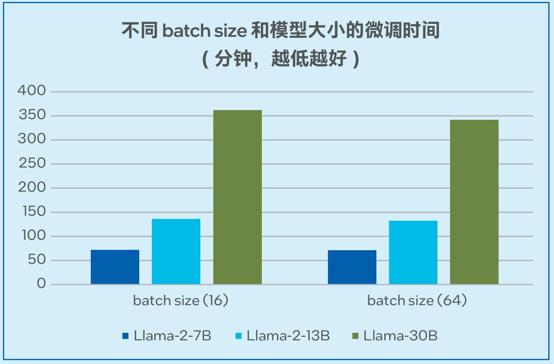
圖5. Llama-2-7B/13B/30B模型的微調時間
采用英特爾AMX加速器和張量并行加速大語言模型推理
浪潮信息四路服務器采用了英特爾UPI全拓撲連接方式, 張量并行推理方案下等同于有效地擴展了內存帶寬。這一優勢與英特爾AMX加速器一起,使得服務器最終在推理7/13B參數級別的模型時表現出高度的可擴展性。
測試數據如圖6-1和圖6-2所示,在7B和13B規模的模型中,模型推理的延遲可以低至20毫秒左右2,能夠滿足實際業務對于推理性能的要求。
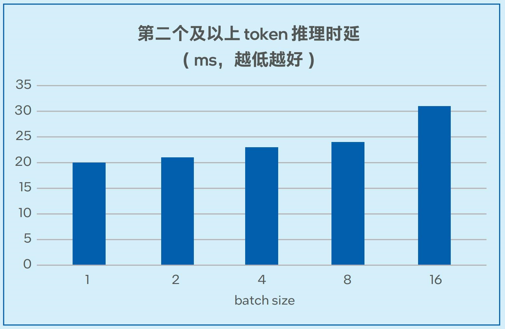
圖6-1. 不同batch size下Llama-2-7B推理延遲測試
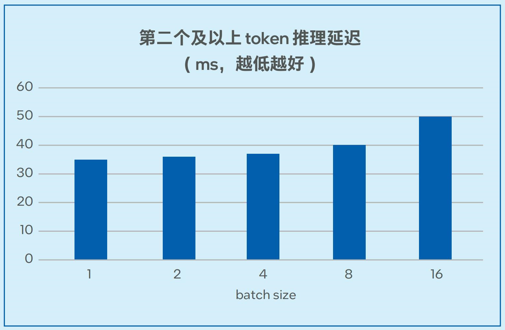
圖6-2. 不同batch size下Llama-2-13B推理延遲測試
采用英特爾AMX加速器和IntelExtension for PyTorch提升視覺模型推理性能
在非大語言模型的通用AI負載中,一般矩陣乘法(General Matrix Multiplication, GEMM) 往往消耗最多時間,推理訓練都受算力限制。浪潮信息四路服務器在為基于CNN的視覺模型推理帶來更強算力的同時,利用英特爾高級矩陣擴展(AMX) 加速矩陣乘法運算。如圖7所示,對于經典的視覺模型ResNet50,在推理階段,單顆處理器吞吐量最高可以達到2942.57FPS。同時,該解決方案可以支持高并發,在單臺四路配置時可以達到11322.08 FPS的吞吐量3。
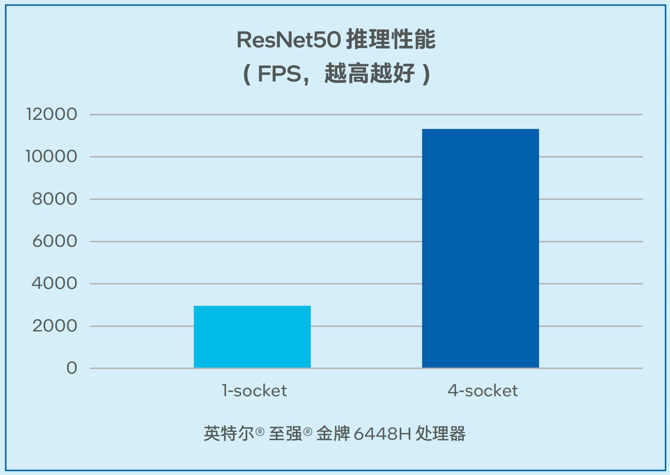
圖7. 浪潮信息四路服務器 ResNet50推理性能
收 益
基于英特爾至強可擴展處理器的浪潮信息服務器AI訓推一體化方案能夠為用戶AI任務帶來以下收益:
滿足中小規模的模型對于微調及推理的算力需求:通過硬件構建與軟件優化,該AI訓推一體化方案提供了強大的模型微調與推理算力支持,在7B和13B規模的模型中,模型推理的延遲可以低至20毫秒左右,在基于CNN的視覺模型推理中,單臺四路服務器上可以達到11322.08FPS的吞吐量4。
更高的適用性、擴展性:該AI訓推一體化方案可以靈活地支持計算機視覺模型推理、大語言模型的微調和推理,以及其它通用業務,并實現更高的擴展性。
更高的性價比與投資回報:對比專用的AI服務器方案,該AI訓推一體化方案具備高性價比、高可及性等優勢,可助力用戶獲得更高的投資回報。
展 望
在智能化成為業務關鍵驅動力的今天,用戶急切希望搭建自己的AI訓練與推理計算平臺,以便能夠躋身人工智能熱潮之中,探索和擴展他們的AI業務領域。以英特爾至強可擴展處理器為基礎的浪潮信息服務器AI訓推一體化方案憑借在性價比與靈活性等方面的優勢,有望成為推動AI微調與推理的關鍵基礎設施。
展望AI技術的未來發展,其不僅將創造更多的業務形態,而且為企業創造了巨大的商業潛力和發展機遇。浪潮和英特爾雙方將在技術探索、產品升級、應用推廣等多個層面深度協作,推動AI在更多應用場景的創新以及普及,助力AI的應用與發展。
審核編輯:劉清
-
處理器
+關注
關注
68文章
19178瀏覽量
229200 -
以太網
+關注
關注
40文章
5385瀏覽量
171161 -
DDR5
+關注
關注
1文章
419瀏覽量
24104 -
pytorch
+關注
關注
2文章
803瀏覽量
13152 -
AI大模型
+關注
關注
0文章
307瀏覽量
294
原文標題:浪潮信息基于至強? 可擴展處理器推出 AI 服務器訓推一體化方案
文章出處:【微信號:英特爾中國,微信公眾號:英特爾中國】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
英特爾發布至強6處理器產品
開箱即用,AISBench測試展示英特爾至強處理器的卓越推理性能

浪潮信息元腦?服務器率先支持英特爾?至強?6處理器

寧暢B5000 G5多節點服務器采用第五代英特爾至強可擴展處理器

浪潮信息與英特爾合作推出一種大模型效率工具“YuanChat”

第五代英特爾至強處理器,AI特化的通用服務器CPU

新升級 浪潮信息邊緣服務器支持英特爾第五代至強處理器

浪潮信息NE5260G7服務器適配第五代英特爾至強處理器
英特爾至強處理器優化升級,助力打造未來高能效數據中心
英特爾專家為您揭秘第五代英特爾? 至強? 可擴展處理器如何為AI加速

第五代英特爾至強可擴展處理器,為AI加速而生


第五代英特爾至強可擴展處理器,為AI加速而生






 工商網監
工商網監
評論