 存內生態構建重要一環- 存內計算工具鏈
存內生態構建重要一環- 存內計算工具鏈
本篇文章重點講述存內計算相關工具鏈,我們將從工具鏈定義出發,依次講述工具鏈研究背景及現有工具鏈、存內計算相關工具鏈發展現狀、存內計算工具鏈未來展望等內容。
一.工具鏈研究背景及現有工具鏈
工具鏈,英文名稱toolchain,通常是指在軟件開發或硬件設計中使用的一系列工具和軟件,用于完成特定任務或流程。這些工具一般接連地使用,從而完成一個個任務,這也是“工具鏈”名稱的由來。一般工具鏈的研發,大致與通用應用程序生命周期一致,分為五個階段,如下圖1所示,圖中包括每個階段對應的工具等[1]。
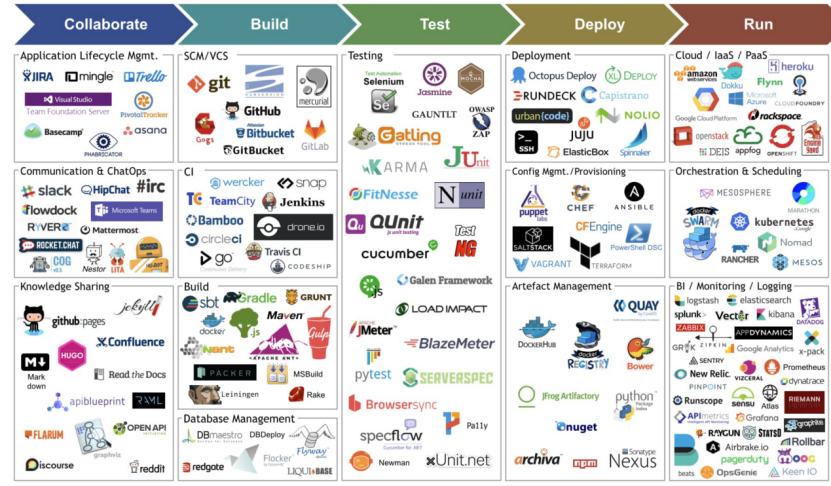 圖1 工具鏈研發模型
圖1 工具鏈研發模型(1)EDA工具鏈[2]:
EDA 是 Electronic Design Automation 的簡稱,即電子設計自動化,是指利用計算機輔助設計軟件,完成超大規模集成電路芯片的功能設計、綜合、驗證、物理設計等流程的設計方式。在集成電路應用的早期階段,集成電路集成度較低,設計、布線等工作由設計人員手工完成。1970 年代中期開始,隨芯片集成度的提高,設計人員開始嘗試將整個設計工程自動化。
1980 年發表的論文《超大規模集成電路系統導論》提出通過編程語言來進行芯片設計,是電子設計自動化發展的重要標志,EDA 工具也在這個時期開始走向商業化。21 世紀以來,EDA 工具快速發展,并已貫穿集成電路設計、制造、封測的全部環節,從而加速集成電路產業的技術革新。
EDA行業市場集成度較高,如下圖2所示,全球 EDA 行業主要由楷登電子、新思科技和西門子EDA 壟斷,上述三家公司屬于具有顯著領先優勢的第一梯隊。國內起步較晚,雖然發展迅速,但最高只能做到第二梯隊,有很大發展空間。
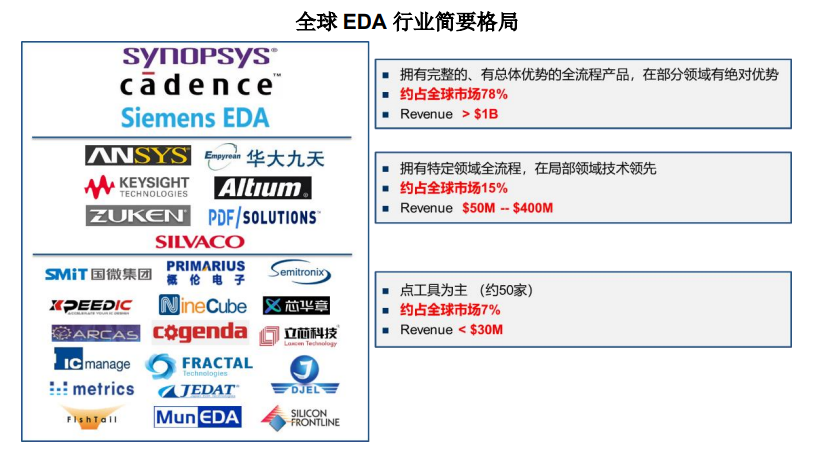 圖2 全球EDA簡要格局
圖2 全球EDA簡要格局(2)人工智能編譯工具鏈[3]:
由于人工智能算法的不斷突破,其模型尺寸和算力需求飛速增長,從而導致算法與芯片之間存在巨大的算力“鴻溝”。首先每個模型的算力利用率低,甚至小于10%,其次算子庫沒有統一的標準,每個芯片的制作流程中都要耗費巨大的人力物力來維護龐大算子庫。而人工智能編譯器是發揮硬件算力的保障,可以解決以上問題,如下圖3為人工智能編譯器常用設計架構概述。
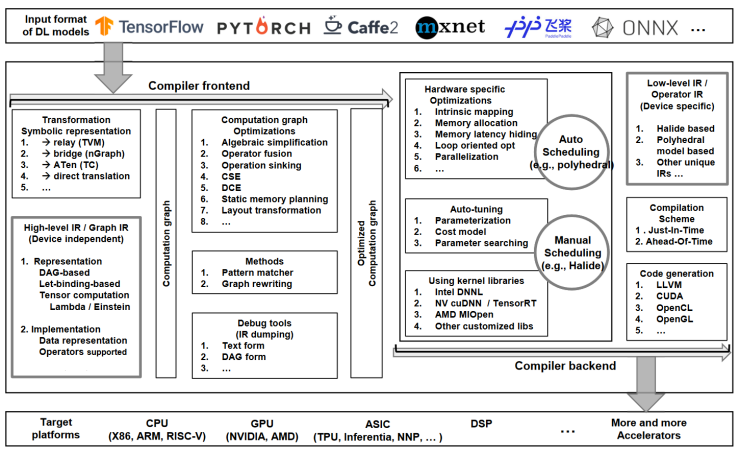 圖3 深度學習編譯器常用設計架構概述
圖3 深度學習編譯器常用設計架構概述人工智能編譯器在早期只是一個從計算圖(數據流圖)到算子庫的映射器。許多深度學習編程框架(TensorFlow和PyTorch等)將模型表示成計算圖,而計算圖的執行通過調用第三方算子庫完成。編譯器將計算圖映射到算子庫,是人工智能框架和算子庫中間的橋梁。此后,為了優化模型性能,各框架都引入了計算圖編譯器,進行計算圖級優化。然而人工智能編譯器的研究是我們的短板,例如谷歌的XLA編譯器可以將性能最高提升十倍以上,而國產人工智能芯片的峰值算力高,但實際代碼的利用率低,因此研究人工智能芯片的配套軟件工具鏈刻不容緩。
人工智能編譯工具鏈和存內計算芯片聯系密切,在存內計算芯片從設計到生產的全流程中,工具鏈的設計是非常重要的環節,其能夠將深度學習框架中的不同模型作為輸入,根據硬件設計產生高效的輸出代碼,實現深度學習模型到硬件設備的部署。然而,當前神經網絡模型在存內計算芯片上可移植性低,部署成本高,大大阻礙了存內計算技術在深度學習領域的大規模應用。因此,面向存內計算芯片的人工智能編譯工具鏈也是亟待研發的。
綜上所述,當前芯片設計、人工智能等工具鏈發展較為成熟,但存內計算相關工具鏈還有很大的發展空間。目前,存內計算相關工具鏈還存在著缺乏成熟的標準單元庫與快速組裝工具、缺乏成熟的功能與性能仿真驗證工具、缺乏建模和誤差評估工具等問題,都等待著從業人員去攻克解決。
二.存內計算相關工具鏈發展現狀
存內計算工具鏈可以認為是輔助開發人員將軟件設計部署到存內計算硬件上的工具。存內計算從原理上對神經網絡中常見的乘累加運算具有良好的支持,使得存內計算在人工智能領域具有巨大潛力。因此,存內計算工具鏈可以在狹義上認為是將神經網絡部署到存內計算芯片中,使其在片上運行的工具。
為了更方便地使用神經網絡模型,許多通用神經網絡框架已經被提出,如TensorFlow、PyTorch、Caffe、MXNet、CNTK等,它們提供了一系列打包好的網絡層等工具,方便用戶編寫自己的神經網絡模型。神經網絡模型在硬件上的運行依賴于神經網絡編譯工具鏈,如TVM、MLIR、nGraph、XLA等。[5]然而,存內計算作為一種新型計算范式,將存儲單元和計算單元融合,其存儲和計算特性不同于傳統硬件,使得現有神經網絡工具鏈并不適用于存內計算。[6]
學術研究中,由于研究的重點往往是存內計算硬件設計,并且工具鏈需要對軟件算法模型、編譯工具、電路等多個相關的特定領域知識有著深入理解,受限于高校的科研資源,該部分的研究往往作為存內計算硬件研究的附屬工作,實際使用中神經網絡的部署工作大多由研究者手動完成。同時,當前國內神經網絡工具鏈存在峰值算力高,但是實際代碼利用率低的問題。[7]
部分科研人員針對存內計算編譯器相關問題開展研究,并已經取得了一定的研究成果。例如,PUMA是一種基于憶阻器的機器學習推理加速器,它支持ISA指令集,并且具有轉換將高級語言為ISA代碼的編譯器,編譯器對計算圖進行分區,并優化指令調度和寄存器分配,以便為在數千個空間內核上運行的大型復雜工作負載生成代碼。[8]但是,該編譯器采用的啟發式權重復制和核心映射方法(heuristic weight replicating and core mapping method)難以保證高性能;此外,PUMA的層間流水線是以推理為粒度的,即不同層處理不同的推理數據,這種處理方式在低延遲場景下對性能同樣產生較大影響。[6]
然而,工具鏈是連接開發者與硬件的橋梁,是吸引開發者,豐富硬件平臺算法環境的重要一環,是企業節省開發成本的重要手段。因此,在商業領域中,工具鏈的作用不容忽視,如國內存內計算企業知存科技和后摩智能,已經提出了適配自身硬件的工具鏈。
根據后摩智能官網信息,后摩大道?軟件平臺是服務后摩鴻途?H30芯片硬件的自研軟件開發平臺,主要由模型開發SDK、算子開發SDK、系統及中間件等組件構成,可以兼容不同硬件平臺的底層異構計算框架,易于跨平臺遷移;自帶預編譯參考模型,方便用戶直接使用;使用適配存算一體架構的并行數據開發語言,同時支持C/C++編程;推理引擎支持自動融合流水、自動內存分配等編譯優化技術。[9]
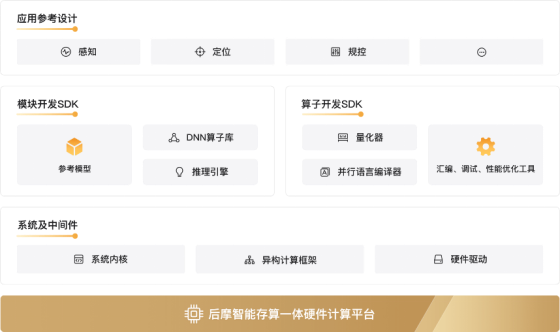 圖4 后摩智能存算一體平臺
圖4 后摩智能存算一體平臺
根據知存科技官網信息,WITIN_MAPPER是知存科技自研的用于神經網絡映射的編譯軟件棧,可以將量化后的神經網絡模型映射到WTM2101 MPU加速器上,是一種包括RISC-V和MPU的完整解決方案,可以完成算子和圖級別的轉換和優化,將預訓練權重編排到存算陣列中,極大地縮短模型移植的開發周期并提高算法開發的效率[10]。工具鏈配備五種可選的優化策略:參數放大、權重復制、高比特稀疏、多點卷積優化、正負(PN)優化,實際應用中,用戶可根據權重大小、輸入數據類型、精度要求、速度要求等多方面自行選擇,一般來講,權重復制+正負(PN)優化+多點卷積優化就可以滿足大部分要求。[11]
 圖 5 WTM2101軟件棧-witin_mapper[10]
圖 5 WTM2101軟件棧-witin_mapper[10]同時,知存科技提供WITMEM STUDIO集成開發環境、SPI Moniter工具、開發板等開發工具。其中,集成開發環境包含客戶識別的SDK推送功能,SDK包自動更新下載安裝功能,內核自動識別語法高亮編輯器,面向不同功能的個性化工程創建功能,以及常規IDE所具有的項目工程管理,文件編輯、編譯、調試等功能。[10]
 圖6 WTM2101-ZT1開發板
圖6 WTM2101-ZT1開發板
以上知存科技相關資料來自于知存科技打造的“存內計算芯片開發者中心”(開發者社區 知存科技 全球領先的存內計算芯片企業:http://www.witintech.com/),其中有知存科技打造的一套完整的芯片開發工具和IDE環境,在此中心中,知存科技將持續分享和更新針對存內計算芯片的軟件、編譯工具鏈、算法資源、開發教程等等,為工程師、研究人員和技術愛好者提供工具和靈感。
三.存內計算工具鏈未來展望
在上文中,我們介紹了當前存內計算工具鏈遇到的困難、存內計算工具鏈發展現狀等等,對于未來存內計算工具鏈的發展,我們有如下幾點展望。
由于存內計算芯片的設計與常規芯片有較大差異,我們需要適配于存內計算芯片設計的相關EDA軟件,他們需要包含以下必需工具:
1.標準單元庫與快速組裝工具。由于存內計算芯片設計的單元結構不唯一,采用不同存儲介質的存內芯片核設計起來缺少標準單元庫,且較大的存算陣列也缺少快速組裝工具,目前這兩點往往是靠設計者手動繪制完成,效率較低。
2.功能驗證與仿真驗證工具。當前EDA軟件沒有面向存內計算場景進行優化的功能仿真驗證工具,仿真時大規模的存算陣列會增加仿真難度與時間。
3.建模與誤差評估工具。當前軟件缺少面向存內計算芯片的電路噪聲建模與誤差評估工具,這些可以幫助開發者在設計階段對方案進行評估并及時調整。[12]
此外,由于存內計算在人工智能、深度學習層面運用廣泛,設計面向存算一體芯片的深度學習編譯工具鏈也是未來存內計算工具鏈發展的重要一環,針對人工智能與深度學習,我們希望工具鏈能達成:
1,由于深度學習算法與存算一體電路間可移植性低,部署成本高,我們需要設計一套工具鏈實現前端網絡模型轉換及優化的策略、后端硬件映射及優化的方法,從而構建一套高性能的存算一體軟硬件結合系統。
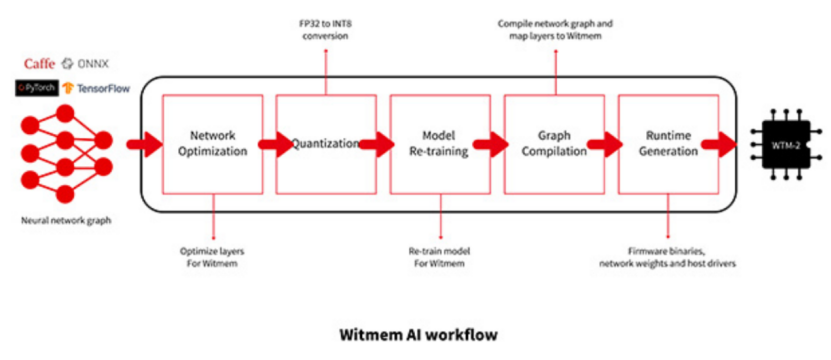 圖 7?神經網絡模型部署至WTM2101的一套編譯工具鏈[13]
圖 7?神經網絡模型部署至WTM2101的一套編譯工具鏈[13]
2,由于存內計算芯片中有眾多存算核,未來若要在存內計算芯片上部署大模型,那么多核之間的資源調度便十分重要;權重在核中怎么存、計算資源如何調度、多核之間如何協同等等問題,都需要我們設計出一套工具鏈來解決。
總而言之,為推動存內計算規模應用,相關EDA軟件、配套的開發環境、編譯平臺的建立將成為存內計算芯片設計中的必然訴求,它們需要業界共同發力,共同搭建面向存內計算的編程框架,健全仿真和編譯工具,完善算法設計與開發生態。相信在不久的將來,存內計算芯片相關工具鏈將迎來井噴式發展,讓我們一同分享、一同創造,一起見證存內計算芯片的生態繁榮時代。
[1]持續交付工具前景 ·詹姆斯·鮑曼 (jamesbowman.me).
[2]北京華大九天科技股份有限公司招股說明書.
[3]第二十屆全國容錯計算學術會議-過敏意-面向人工智能芯片的編譯新技術.
[4] Li M, Liu Y, Liu X, et al. The deep learning compiler: A comprehensive survey[J]. IEEE Transactions on Parallel and Distributed Systems, 2020, 32(3): 708-727.
[5] Li M, Liu Y, Liu X, et al. The deep learning compiler: A comprehensive survey[J]. IEEE Transactions on Parallel and Distributed Systems, 2020, 32(3): 708-727.
[6] Sun X, Wang X, Li W, et al. PIMCOMP: A Universal Compilation Framework for Crossbar-based PIM DNN Accelerators[C]//2023 60th ACM/IEEE Design Automation Conference (DAC). IEEE, 2023: 1-6.
[7] 第二十屆全國容錯計算學術會議-過敏意教授報告-面向人工智能芯片的編譯新技術
[8] Ankit A, Hajj I E, Chalamalasetti S R, et al. PUMA: A programmable ultra-efficient memristor-based accelerator for machine learning inference[C]//Proceedings of the Twenty-Fourth International Conference on Architectural Support for Programming Languages and Operating Systems. 2019: 715-731.
[9] 后摩智能官網(houmoai.com)
[10] 知存科技開發文檔(開發者社區 知存科技 全球領先的存內計算芯片企業:http://www.witintech.com/)
[11] Bai T, Mao W, Wang G, et al. An End-to-End In Memory Computing System Based On A 40nm eFlash-Based IMC SoC: Circuits, Toolchains, and Systems Co-Design Framework[J]. IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, 2024.
[12] 詳細解讀存算一體技術路線 - 電子發燒友(elecfans.com)
[13] 存內計算芯片開發者中心 - (開發者社區 知存科技 全球領先的存內計算芯片企業:http://www.witintech.com/)
-
eda
+關注
關注
71文章
2655瀏覽量
172199 -
開發工具鏈
+關注
關注
0文章
10瀏覽量
1578 -
IC芯片設計
+關注
關注
0文章
7瀏覽量
1065 -
知存科技
+關注
關注
0文章
50瀏覽量
3929 -
存內計算
+關注
關注
0文章
28瀏覽量
1348
發布評論請先 登錄
相關推薦
存內計算芯片研究進展及應用
探索存內計算—基于 SRAM 的存內計算與基于 MRAM 的存算一體的探究

論基于電壓域的SRAM存內計算技術的嶄新前景
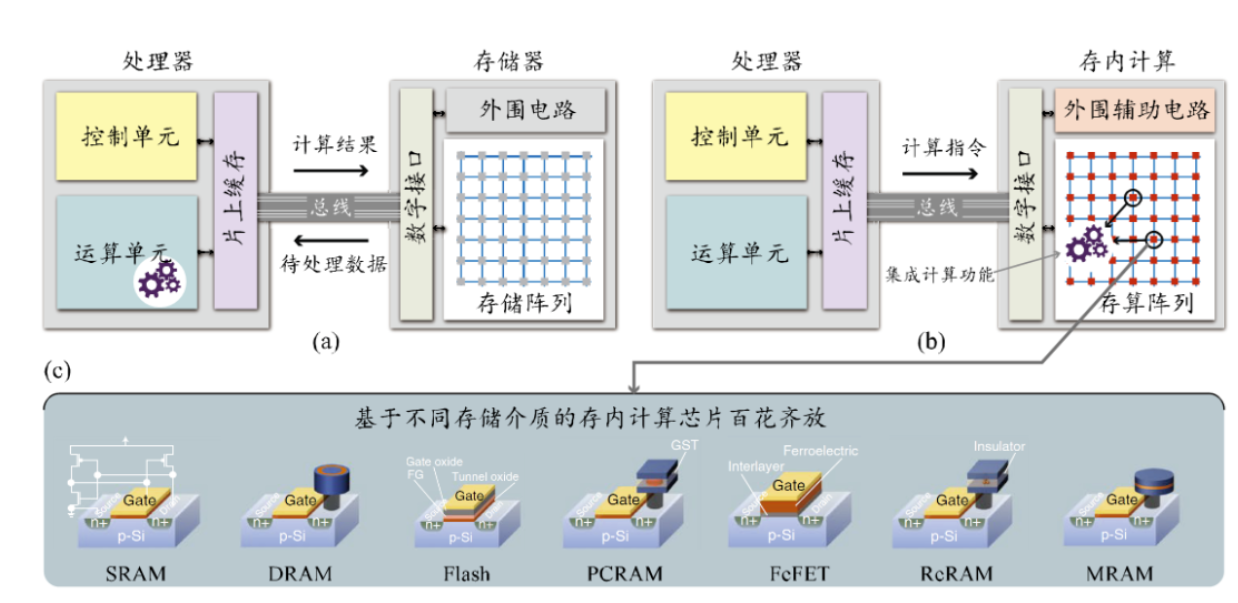
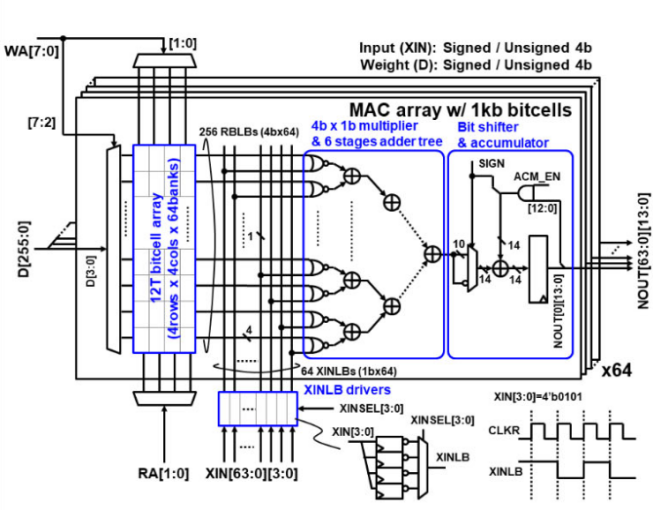

存內計算WTM2101編譯工具鏈 資料
?什么是存內計算
淺談存內計算生態環境搭建以及軟件開發





 工商網監
工商網監
評論