 如何利用NVIDIA中的單視角3D追蹤功能減輕視覺感知中的遮擋現象?
如何利用NVIDIA中的單視角3D追蹤功能減輕視覺感知中的遮擋現象?
說到智能視頻分析(IVA)應用(如交通監控、倉庫安全和零售消費者分析)的感知,最大的挑戰之一就是遮擋。例如,人們可能會移動到結構性障礙物后面,零售消費者可能由于貨架而無法被完全看到,汽車可能會被隱藏在大型卡車后面。
本文將介紹如何利用NVIDIA DeepStream SDK中全新的單視角 3D 追蹤功能,來解決現實生活中 IVA 部署常見的視覺感知遮擋問題。
視覺感知中的視角和投影
在我們的物理世界中,通過相機鏡頭觀察到的一些物體的運動可能看起來并不穩定,這是由于相機對 3D 世界的 2D 呈現所造成的。
水星和火星等行星的逆行就是一個例子,這讓古希臘天文學家感到困惑。他們無法解釋為什么行星有時看起來會向后移動(圖 1)。
之所以會出現明顯退行,是由于恒星和行星在夜空中的軌跡所造成的。這些是宇宙 3D 空間中軌道運動在夜空2D畫布上的投影,如果古代天文學家知道3D空間的運動模式,他們就可以預測這些行星在2D夜空中的出現。
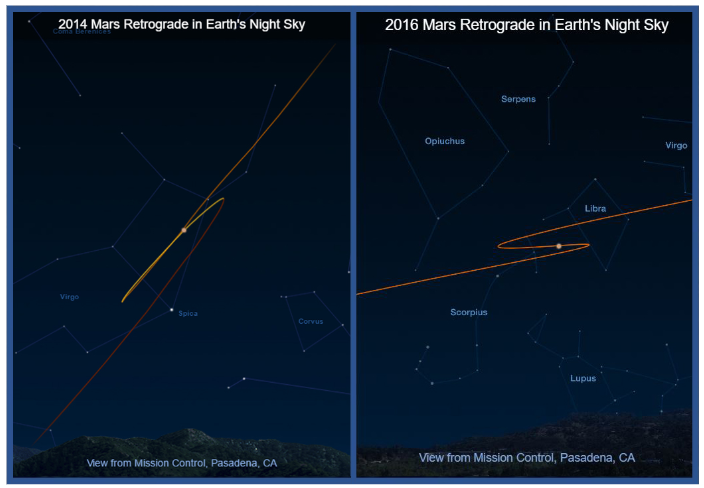
圖 1. 2014 年(左)和 2016 年(右)
火星在夜空中的逆行運動軌跡(圖片來源:NASA)
交通監控攝像頭提供了類似的例子。這些攝像頭通常用于監測一個大面積的區域,在這個區域里,車輛在近場和遠場的運動動態可能截然不同。
在視頻 1 中,遠處的車輛看起來較小且移動緩慢。當車輛靠近攝像頭并轉彎時,可以觀察到物體運動的突然變化。這些變化使得我們在 2D 攝像機視圖中很難找到常見的模式,因此也很難預測車輛未來可能移動的位置。
視頻 1. 近場車輛似乎移動得很快,
而遠場車輛則移動得較慢
物體跟蹤本質上是對物體物理狀態的連續估計,同時隨著時間的推移來識別其獨特身份。該過程通常包括對物體運動動態進行建模和預測,以抑制測量(檢測)中的固有干擾。從所提供的示例來看,直接在原生3D空間中對物體狀態進行估計和預測顯然比在投影的2D 攝像頭圖像平面中效果更好,這是因為物體存在于3D空間中。
使用 NVIDIA DeepStream進行單視角 3D 跟蹤
NVIDIA DeepStream SDK 是一個基于 GStreamer 的完整流媒體分析工具包,可用于基于 AI 的多傳感器處理,視頻、音頻和圖像理解。DeepStream 6.4 版本引入了一種名為單視角 3D 跟蹤(SV3DT)的新功能,該功能能夠在單攝像頭視圖內估計 3D 物理世界中的物體狀態。
這一過程包括使用每個攝像頭的 3×4 投影矩陣或攝像頭矩陣,將 2D 攝像頭圖像平面上的觀測測量轉換為 3D 世界坐標系。物體在3D世界地平面中的位置表示為物體底部的中心,因此,行人被建模為一個立在世界地面平面上的圓柱體(具有高度和半徑),圓柱體模型底部的中心是行人的腳部位置(圖 2)。

圖 2. 每個圓柱形模型的底部中心表示
每個行人在 3D 世界地平面上的位置(用綠點標記)
使用 3×4 投影矩陣和圓柱形人體模型,可以估算出針對檢測到物體的 3D 人體模型在 3D 世界地平面上的位置,從而使投影在 2D 攝像頭圖像平面上的 3D 人體模型,與檢測到的物體的邊界框相吻合。
例如,在圖 3(左)中,灰色邊界框表示對象檢測器使用NVIDIA TAO PeopleNet模型檢測到的物體,紫色和黃色圓柱體代表從 3D 世界地平面上的估計位置投影到 2D 攝像頭圖像平面的相應的 3D 人體模型,投影的 3D 人體模型底部的綠點代表預估的腳部位置。盡管攝像頭視圖有透視和旋轉,但這些位置與實際腳部位置非常吻合。

圖 3. SV3DT 有助于跟蹤零售消費者準確的腳部位置,
即使存在遮擋也不影響
新推出的 DeepStream SV3DT 功能的一個重要優勢是,即使存在明顯的局部遮擋,也可以準確地找到物體的 2D 和 3D 腳部位置,而這是現實世界 IVA 應用中最具挑戰性的問題之一。
例如,圖 3(右)顯示了一個人在狹窄的過道里購物,攝像頭只能看到其上半身的一小部分,這將導致物體邊界框較小,只能捕獲頭部和肩部區域。在這種情況下,要在全局商店地圖上對此人進行定位就變得極具挑戰性,至少可以說,估計腳部位置是一項非同小可的任務。
使用邊界框的底部中心作為對象位置的代表會為軌跡估計帶來很大的誤差。即使使用攝像頭校準信息將 2D 點轉換為 3D 點情況也是如此,尤其是當攝像頭透視和旋轉較大時。
DeepStream SDK 中的多目標跟蹤器模塊中的 SV3DT 算法,在假設攝像頭安裝在頭部上方的情況下,通過利用 3D 人體建模信息來解決這個問題。大多數部署在智能空間中的大型攝像頭網絡系統通常都是這種情況。有了這個假設,在估算相應的 3D 人體模型位置時,就可以使用頭部作為錨點。如圖 3 顯示,即使在人被嚴重遮擋的情況下,SV3DT 算法也可以成功地找到匹配的 3D 人體模型位置。
視頻 2 顯示了在一家便利店中對消費者進行跟蹤的情況。需要注意的是,所使用的 3×4 投影矩陣沒有考慮鏡頭失真,盡管特定的攝像頭有一定的鏡頭失真,正如您所看到的,水平線有點彎曲而不是直線。這會導致 3D 人體模型位置估計更加不準確,尤其是當人位于視頻幀的邊緣時。
盡管如此,人們在便利店的 2D 和 3D 腳部位置(用綠點表示)還是被準確而穩健地追蹤到了,這也提高了隊列長度監控和占用率地圖等其他分析的準確性。
圖 4 顯示了如何在合成數據集中穩健地追蹤每個行人的腳部位置,即使下半身的大部分被貨架等大型物體遮擋。

圖 4. 基于合成數據集的嚴重顆粒遮擋情況下的SV3DT 行人位置跟蹤
我們相信,解決部分遮擋問題將為現實應用帶來許多可能性。SV3DT 目前處于 Alpha 模式,因為其對象類型支持有限(僅限站立的人),其他情況(如人們坐著和躺著)或其他對象類型可能會在未來的版本中得到支持。
DeepStream SV3DT 用例
該 DeepStream SV3DT 用例演示了如何在本文介紹的零售商店視頻上啟用單視角 3D 跟蹤,并從管道中保存 3D 元數據。如圖 4 和視頻 2 所示,用戶可以從數據中可視化凸起的船體和腳部位置。README 還介紹了如何在定制視頻上運行該算法。
總結
NVIDIA DeepStream SDK 中的單視角 3D 跟蹤有助于緩解現實生活中 IVA 應用程序和部署的部分遮擋問題。該功能在 6.4 版本中首次推出,并在 7.0 版本中進行了增強。具體而言,SV3DT 能夠在局部遮擋的情況下估計腳部位置,并能夠進行更穩健和準確的對象追蹤,從而實現 3D 地平面中的準確定位。依賴或利用地理空間分析的企業有望從這項技術中受益。
-
傳感器
+關注
關注
2548文章
50699瀏覽量
752074 -
NVIDIA
+關注
關注
14文章
4940瀏覽量
102820 -
攝像頭
+關注
關注
59文章
4810瀏覽量
95454
原文標題:利用 NVIDIA DeepStream 中的單視角 3D 跟蹤技術減輕視覺感知中的遮擋現象
文章出處:【微信號:NVIDIA-Enterprise,微信公眾號:NVIDIA英偉達企業解決方案】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
OpenCV攜奧比中光3D相機亮相CVPR 2024
蘇州吳中區多色PCB板元器件3D視覺檢測技術


天馬微電子首發TIANMA META SIGHT光場3D解決方案

奧比中光攜多款3D相機深度參與國內3D視覺最高規格會議

奧比中光3D相機及方案亮相,攜手NVIDIA探索機器人應用革新
奧比中光3D相機及方案亮相,攜手NVIDIA探索機器人應用革新
高分工作!Uni3D:3D基礎大模型,刷新多個SOTA!

技術基因+自主創新,光鑒科技塑造3D視覺感知新范式

2D與3D視覺技術的比較
圖漾科技發布3D工業視覺應用開發平臺Vision++
3D視覺的三大優勢

阿迪達斯與 Covision Media 使用 AI 和 NVIDIA RTX 創建逼真的 3D 內容






 工商網監
工商網監
評論