 英飛凌AURIX TC4x微控制器系列中的并行處理單元(PPU)簡介
英飛凌AURIX TC4x微控制器系列中的并行處理單元(PPU)簡介
并行處理單元(PPU)是集成在英飛凌AURIX TC4x微控制器系列中的協處理器。PPU旨在卸載主CPU的信號處理、濾波和其他數學運算,從而為要求嚴格的應用程序(例如實時控制、傳感器信號處理和軌跡規劃等)提供高計算能力和縮短執行時間,并且能支持實現簡單的神經網絡算法。
本文將簡要介紹PPU的內部結構、功能和應用領域。
1. PPU內部結構
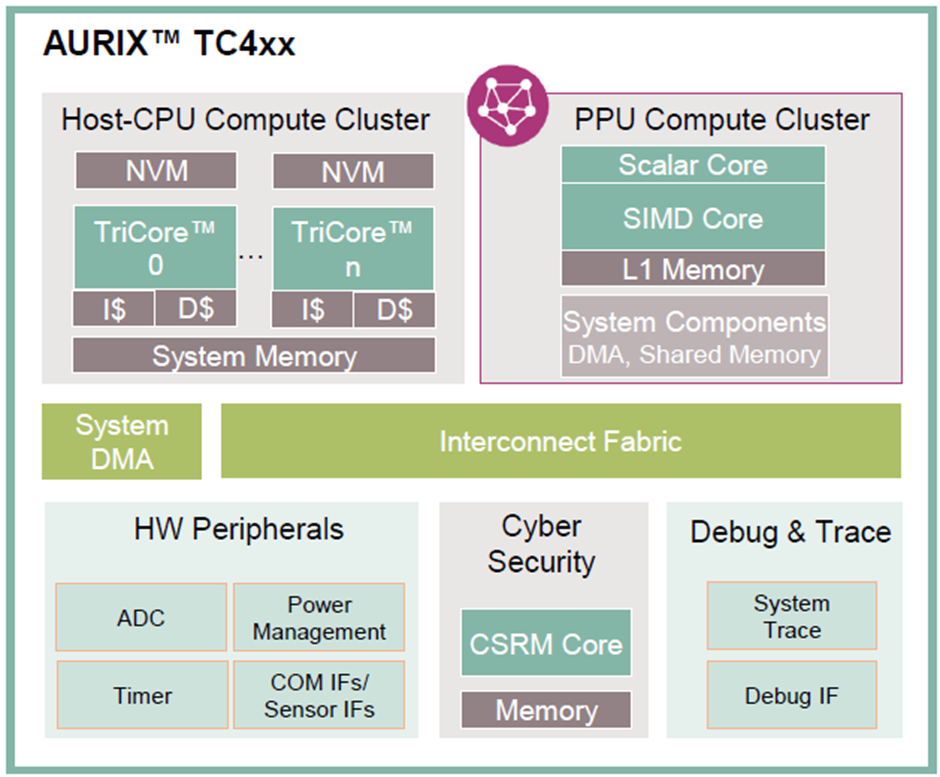
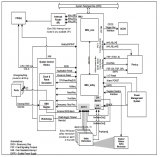
圖1. TC4x微控制器示意框圖
圖1是TC4x 微控制器示意框圖,圖中右上角是PPU的簡化結構,由標量核(scalar core),向量核(vector core/SIMD core),一級緩存,及其它系統資源組成。
01
標量核(Scalar Core):標量核用于執行大量的標量運算,以及任務調度。標量核支持多種算術運算和邏輯運算,還支持硬件浮點運算,從而實現更高的計算效率。另外,標量核提供豐富的硬件功能安全機制,可以輔助實現高功能安全等級的任務。
02
向量核(Vector core/SIMD Core):向量核是 PPU 的另一個重要功能模塊,專門用于執行向量運算。向量核支持多種向量算術運算、邏輯運算和專用信號處理,支持整型數和浮點運算,從而實現更高的計算效率。向量核還支持多級流水線和 SIMD(single instruction multiple data,單指令多數據)指令,對不同數據同時執行同樣的操作,通過并行執行多個向量運算來提高效率。
03
一級緩存:一級緩存是PPU用于保存計算輸入和輸出數據的存儲空間。由于結構上和運算核緊密耦合,該緩存可以在PPU 的執行過程中對狀態進行快速讀寫,并且有EDC/ECC保護,從而實現更高的執行效率和更高的可靠性。
04
其它系統資源:包括用于快速數據搬運的DMA,共享內存區等等。
2. SIMD 和VLIW指令
2.1SIMD(Single Instruction Multiple Data)指令
SIMD(Single Instruction Multiple Data)指令是一種并行指令,可以同時對多個不同數據進行相同的操作。這種指令可以大幅提高計算效率,特別是在執行向量運算時效果更為明顯。
PPU 的 SIMD 指令集包括多種運算指令,如數學運算、邏輯運算等。這些指令都是并行指令,可以同時對多個數據進行操作,從而大幅提高計算效率。例如,PPU 的 SIMD 加法指令可以一次性對多個數據進行加法運算,從而實現更高的計算速度。
下面是一個示例,假設有兩個向量 A 和 B,每個向量包含 16 個 16 位整數 ,要計算 A 和 B 的和。如果使用不支持SIMD指令的標量核,代碼示例如下,需要進行16次循環運算,將不同的A[i]、B[i] 數據依次順序進行加法操作,相當費時。

而如果使用支持SIMD指令的 PPU進行運算,則可以一次完成,假設PPU位寬是256bit(=16*16bit):

由此可見,支持SIMD指令的PPU在進行向量運算時,通過降低同樣運算的處理次數,從而有效節省運算時間,提高處理效率。
2.2VLIW(Very Long Instruction Word)指令
VLIW(Very Long Instruction Word)是一種處理器的并行架構,允許在單個時鐘周期內,由處理器的不同部件同時執行多個操作。
例如,如果要執行兩個復向量A和B的乘法 ,結果存儲在向量C中。

C語言實現如下:

如果在標量核上運算,會順序執行下列代碼,并循環多次:

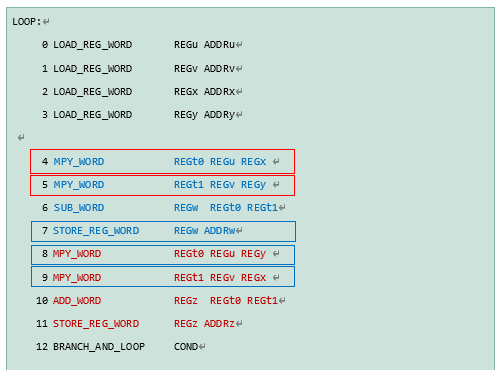
PPU內的向量核有三個處理單元,包括兩個浮點運算器,和一個讀取/存儲部件用于將RAM中的數據搬運到核內寄存器。這三個部件可以同時運行,形成指令層面的并行機制,從而實現VLIW指令。
上列代碼由PPU處理,可以將第4和第5行的乘法運算分別分配給兩個浮點運算器同時處理,如下紅框所示。而在下個指令周期內,第7,8,9行的指令可以分配給三個部件同時處理,如下藍框所示。從而將原先需要12條指令周期運行的代碼縮短到9條(12-1-2=9)指令周期,提高執行效率。
3. 應用場景
PPU適用于不同應用場景,圖2 列出了三種較常見的算法。第一種是將時域信號轉變為頻域信號,以提取頻率信息的快速傅里葉變換(FFT)。FFT 在數字信號處理中得到了廣泛的應用,如音頻信號處理、毫米波雷達信號處理等。
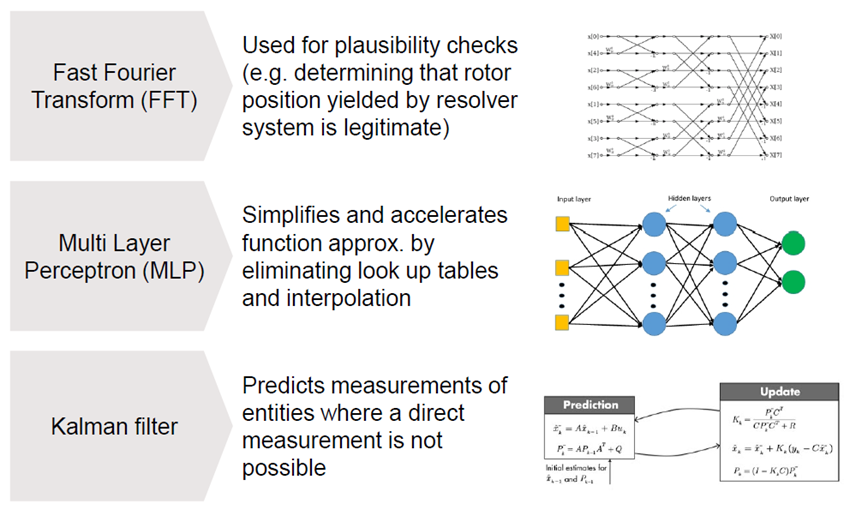
圖2. PPU實現的算法
第二種是多層感知算法,它是一種基于人工神經網絡的機器學習算法,可以用于分類、回歸和模式識別等應用。MLP 由多個神經元組成,每個神經元都包含多個輸入和一個輸出。MLP 通過學習輸入和輸出之間的映射關系,從而實現對新數據的預測和分類。MLP 在機器學習和數據挖掘中得到了廣泛的應用。除此之外,MLP 還可以用于控制和優化問題。例如,MLP 可以用于控制系統和過程控制,如傳感器信號處理分類、輔助駕駛、自動駕駛等。
第三種是卡爾曼濾波,該算法是一種基于狀態空間模型的濾波器,可以用于估計未知變量的狀態和參數。卡爾曼濾波通過利用系統的動態模型和傳感器的觀測值,遞歸地對狀態進行估計和預測,從而實現對系統的狀態進行優化和控制。卡爾曼濾波在自動控制和信號處理中得到了廣泛的應用,例如,卡爾曼濾波可以用于目標跟蹤、路徑規劃算法等。
4. 開發工具
新思科技(Synopsys)為PPU提供了豐富的開發工具資源【1】,包括Metaware編譯器及軟件組件,下列表格列出了相關工具組件:
| 軟件組件 | 描述 |
| MetaWare開發工具包 | 該工具包包含支持內核和應用程序開發編程的C/C++和OpenCL C編譯器。它還包括一個調試器和nSIM PPU模擬器,用于調試、分析和優化內核和應用程序。 |
| Simulink基于模型設計的支持 | 從MATLAB模型自動生成優化代碼,以便在PPU上執行。 |
| DSP和數學庫 | 這些是為在PPU上執行而優化的庫,包括矢量DSP和矢量線性代數庫。 |
| MetaWare神經網絡SDK | 該SDK包括一個神經網絡編譯器,用于編譯和運行為PPU優化的人工智能模型。 |
| AUTOSAR復雜設備驅動程序(CDD)和底層軟件驅動(LLD) |
CDD為AUTOSAR應用程序的軟件組件(SWC)提供PPU服務。 LLD是一個底層軟件驅動,用于處理TriCore和PPU之間的通信。 |
| PPU分配器 | 這是用于在TriCore處理器核心之間進行通信的PPU的靜態庫。 |
表1. 新思科技提供的PPU工具組件
上述PPU開發工具鏈,除了新思科技可提供外,Hightec 在提供TC4x TriCore CPU編譯器的同時,也集成了Metaware編譯工具,及相關軟件組件【2】,形成完整的TC4x開發環境工具鏈。該工具鏈符合ISO26262 ASIL D,能幫助客戶實現快速、可靠、高功能安全等級的基于TC4x微處理器的汽車軟件開發。
此外,Tasking也開發了PPU的編譯器,并集成在新的SmartCode開發環境中。
5. 總結
總的來說,PPU是一個性能強大的處理器,內部包含標量核、向量核、一級緩存和其它系統資源 等,可以實現高速數字濾波、向量矩陣運算、浮點運算、簡單的神經網絡等,為要求嚴格的實時計算應用提供了顯著的性能優勢。PPU為Tricore 主核卸載了復雜的信號處理和數學運算,使得執行時間更快,而其高可配置性和專用硬件資源使其非常適用于各種應用程序。使用戶有更多選擇余地,使用不同核構架實施不同性質的運算。
-
微控制器
+關注
關注
48文章
7487瀏覽量
151041 -
傳感器
+關注
關注
2548文章
50664瀏覽量
751931 -
神經網絡
+關注
關注
42文章
4762瀏覽量
100535 -
協處理器
+關注
關注
0文章
75瀏覽量
18155 -
傅里葉變換
+關注
關注
6文章
437瀏覽量
42562
原文標題:AURIX? TC4x 微控制器的并行處理單元(PPU)簡介
文章出處:【微信號:駿龍電子,微信公眾號:駿龍電子】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
英飛凌MCU AURIX? TC4x特性概覽 2024年下半年逐步量產
英飛凌AURIX TC297微控制器簡介

英飛凌TC3xx系列安全管理單元的使用
英飛凌推出新一代AURIX?微控制器,加速汽車的電氣化和數字化進程


英飛凌aurix tc27x系列介紹
英飛凌AURIX? TC4x微控制器賦能TERAKI雷達檢測軟件,提高自動駕駛的安全性

英飛凌科技和Eatron合作推進汽車電池管理系統(BMS)

英飛凌與Eatron合作推進電池管理管理解決方案

英飛凌最新的帶神經加速的汽車MCU系列 AURIX TC4x微控制器







 工商網監
工商網監
評論