 存內計算芯片研究進展以及應用-以基于Nor Flash的卷積神經網絡量化以及部署
存內計算芯片研究進展以及應用-以基于Nor Flash的卷積神經網絡量化以及部署
@[toc]
如果我能看得更遠一點的話,那是因為我站在巨人的肩膀上。 —牛頓
存內計算的背景
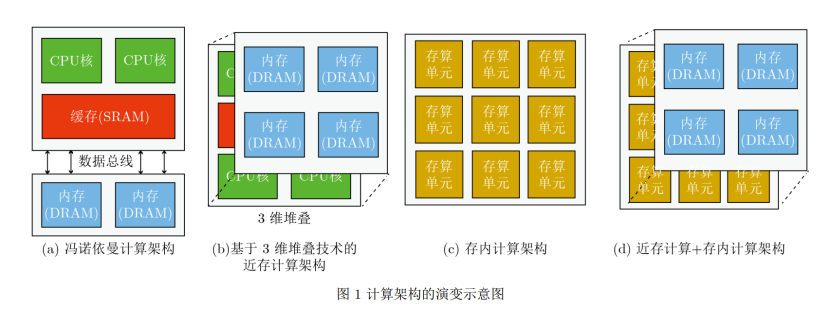
存內計算是一種革新性的計算范式,旨在克服傳統馮·諾依曼架構的局限性。隨著大數據時代的到來,傳統的馮·諾依曼架構由于處理單元和存儲器互相分離,帶來了巨大的延時和能耗,承受著高昂的數據傳輸成本,即所謂的“馮·諾依曼瓶頸”。為了解決這個問題,存內計算應運而生。
存內計算架構在功能和物理上合并了數據處理和存儲單元,在數據存儲的位置即處理數據,在器件層面以原位的方式執行計算。這種方式可以避免頻繁的數據通信,從而減少相應的延時和能耗。存儲器是存內計算的核心器件,這種架構的需求同時也促進了新型非易失性存儲器(NVM)的發展。
早期,由于大數據、人工智能、云計算等需要大量數據處理的應用還沒展開,存內計算僅僅停留在理論研究階段,并未實現實際的應用。然而,近年來隨著這些應用的興起,人們再次關注存內計算的研究。世界知名的IC企業和高校都推出了存內計算的架構。
存內計算的研究還涉及模擬式憶阻器等重要器件,這些器件可以支持各種模擬計算應用,包括人工神經網絡(ANN)、機器學習、科學計算和數字圖像處理等,展現出了突出的潛力。
首個存內計算開發者社區-CSDN存內計算
全球首個存內計算社區創立,涵蓋最豐富的存內計算內容,以存內計算技術為核心,絕無僅有存內技術開源內容,囊括云/邊/端側商業化應用解析以及新技術趨勢洞察等, 邀請業內大咖定期舉辦線下存內workshop,實戰演練體驗前沿架構;從理論到實踐,做為最佳窗口,存內計算讓你觸手可及。
傳送門:[https://bbs.csdn.net/forums/computinginmemory?category=10003]
社區最新活動存內計算大使招募中,享受社區資源傾斜,打造屬于你的個人品牌,點擊下方一鍵加入。
[https://bbs.csdn.net/topics/617915760]
首個存內計算開發者社區,0門檻新人加入,發文享積分兌超值禮品;
成為存內計算大使,享受資源支持與激勵,打造亮眼個人品牌,共同引流存內計算潮流。
存算一體技術發展歷程
存算一體技術,也稱為近存計算與存內計算,其概念最早在1969年被提出。這種技術旨在克服傳統馮·諾依曼架構的局限性,通過在存儲器中直接進行計算,減少數據傳輸的開銷。然而,早期由于缺乏大數據處理的應用需求以及芯片制造成本高昂,存算一體技術主要停留在研究階段。
計算架構的演變示意圖如下: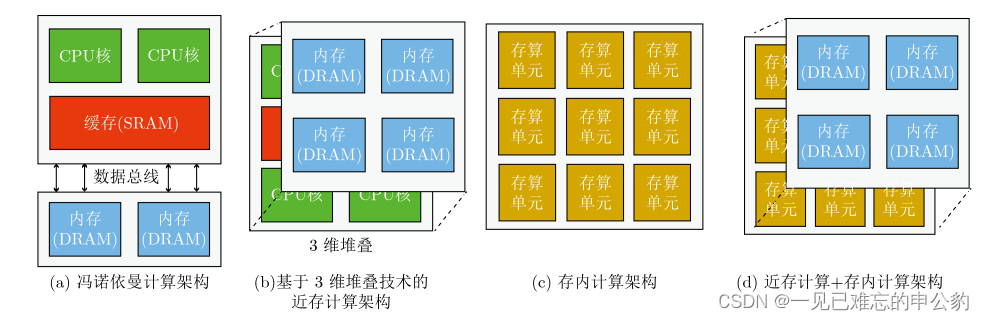
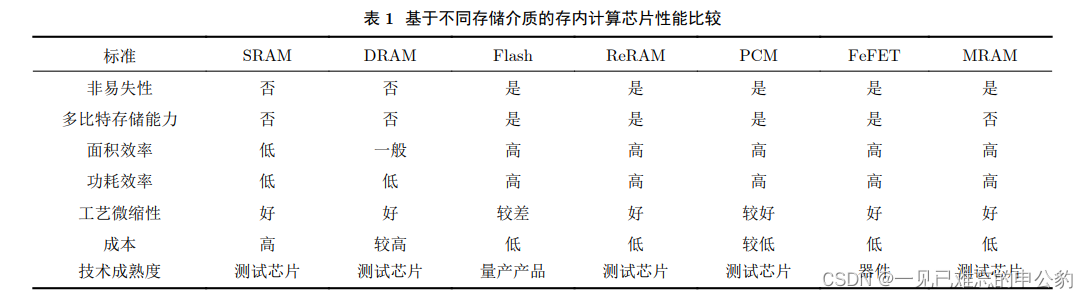
隨著技術的發展,尤其是摩爾定律的逐漸失效和大數據應用的驅動,存算一體技術重新受到關注。2015年以來,這一領域的研究取得了顯著進展,涌現出了一系列相關研究工作,包括基于SRAM、DRAM、Flash、ReRAM、PCM、FeFET、MRAM等各種存儲介質的研究。
存內計算芯片8 bit精度運算測試結果如下圖: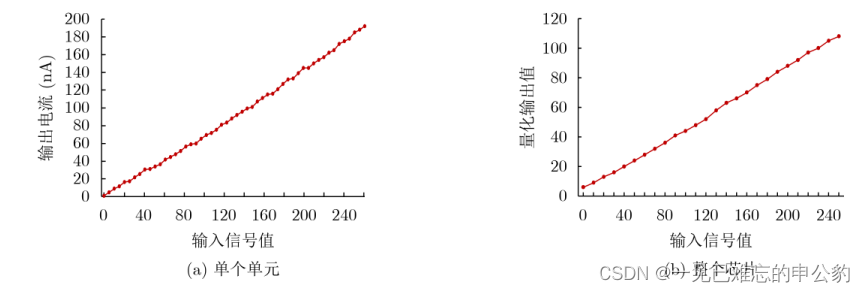
存算一體技術被認為是先進算力的代表性技術之一。在學術界和工業界,許多知名機構都在積極開展存算一體芯片或系統原型的研究,如蘇黎世聯邦理工學院、加利福尼亞大學圣巴巴拉分校、英偉達、英特爾、微軟、三星等。這些研究工作不僅在學術期刊上發表了一系列研究成果,也在國際會議上得到了廣泛關注。
基于不同存儲介質的計算架構演變圖如下: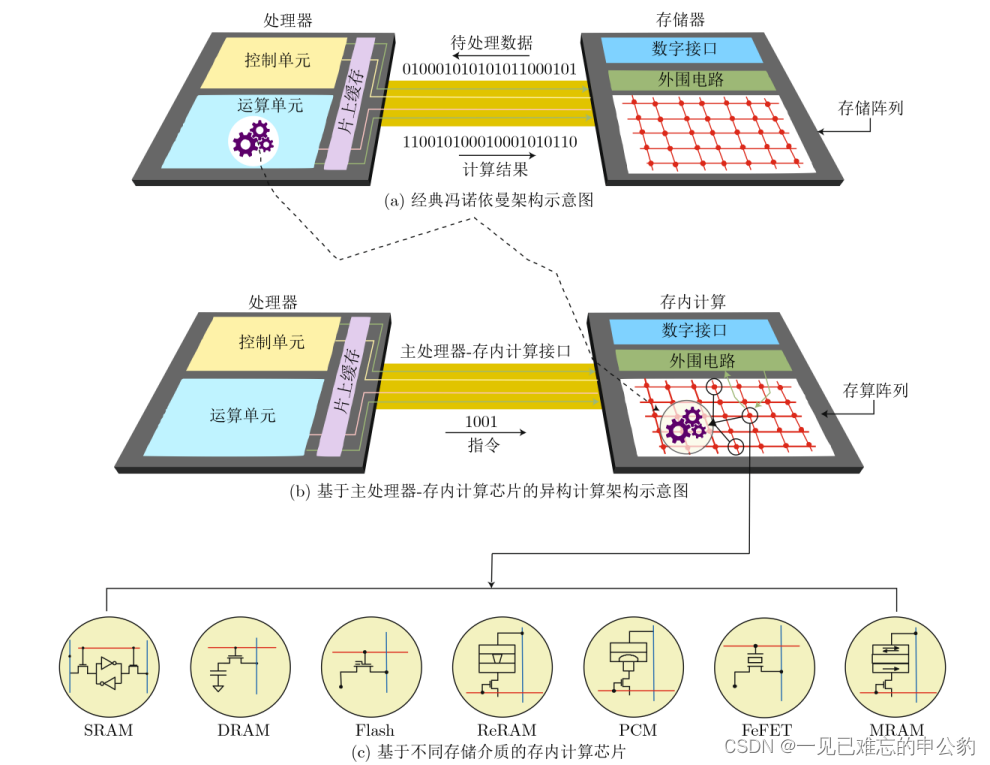
存算一體技術的發展歷程表明,盡管早期受到技術和成本等方面的限制,但隨著大數據和人工智能等應用的興起,這一領域的研究已經取得了顯著進展,并被認為是未來計算架構的重要方向之一。
存內計算芯片研究現狀
存內計算芯片可以根據計算范式和存儲介質的不同進行分類。主要分為模擬式和數字式兩種,根據存儲介質的不同又可分為基于傳統存儲器和基于新型非易失性存儲器兩種。
- 計算范式分類:
- 存儲介質分類:
在當前的研究工作中,許多存內計算芯片綜合了模擬和數字兩種運算方式,并且在存儲介質的選擇上也有很多不同的組合。其中,基于NOR Flash和基于SRAM的存內計算芯片距離產業化較近,已經在一些應用中取得了一定的進展。
SRAM存內計算
基于SRAM的存內計算芯片通常以典型的6T(6-Transistor)基本單元為基礎。由于SRAM是二值存儲器,它可以用于二值乘累加運算,這等效于同或累加運算。這使得它適用于二值神經網絡運算。核心思想是將網絡權重存儲于SRAM單元中,激勵信號從字線給入,最終利用外圍電路實現同或累加運算。結果可以通過計數器或模擬電流/電壓輸出。
如果要實現多比特精度運算,通常需要多個單元進行拼接,這不可避免地會帶來面積開銷。對6T基本單元的一個簡單修改是將字線進行拆分。此外,為了解決讀寫干擾問題,可以采用8T基本單元,但這明顯增加了布局面積,如圖所示。
基于SRAM的存內計算技術由于其工藝成熟度與微縮性良好,受到業界的高度關注。在近幾年的ISSCC(國際固態電路大會)上,連續報道了多篇相關論文。例如,2021年,存內計算共有兩個分論壇,共收錄8篇論文,其中5篇是關于SRAM存內計算芯片的。在2022年的ISSCC中,北京大學提出了一種基于動態邏輯且無模數轉換器的SRAM存內計算芯片[42]。SRAM存內計算技術的主要應用難點在于在保證運算精度的前提下,實現高算力和小面積。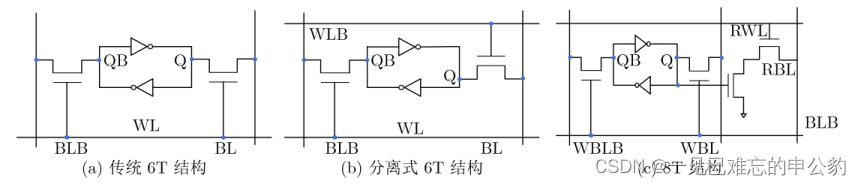
DRAM存內計算
基于DRAM的存內計算芯片的層次結構通常分為陣列、子陣列和單元。一組陣列由若干子陣列和用于讀寫操作的相關外圍電路組成,而子陣列則包含若干行1T1C(1-Transistor-1-Capacitor)單元、感知放大器和本地解碼器。其基本原理是利用DRAM單元之間的電荷共享機制。圖4展示了一種典型的實現方案,當多行單元同時被選通時,不同單元之間因為存儲數據的不同會產生電荷交換共享,從而實現邏輯運算。
然而,DRAM存內計算方案面臨兩個主要難點。首先,由于DRAM本身為易失性存儲器,計算操作會破壞數據,因此需要在每次運算后進行刷新,這會帶來額外的功耗問題。其次,在實現大陣列運算時,難以保證運算精度,這可能在一定程度上影響其應用的可靠性。
盡管存在這些難點,基于DRAM的存內計算方案仍然具有潛在的優勢,包括其相對較低的成本和高度集成的能力。不斷的研究和創新可能有助于解決這些難題,使其更加適用于特定的應用場景。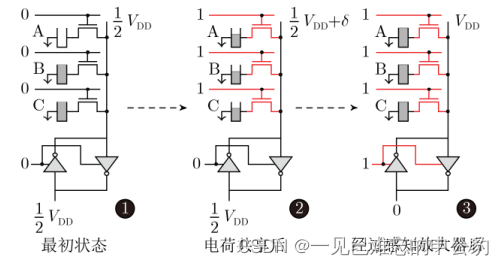
ReRAM/PCM存內計算
ReRAM(電阻隨機存儲器)/PCM(相變存儲器)存內計算的基本原理是利用存儲單元的模擬多比特特性,通過基于電流/電壓的歐姆定律與基爾霍夫定律進行矩陣乘加運算。主要有兩種實現方案,分別是1T1R(1-transistor-1-resistance)結構和交叉陣列結構,如圖所示。
- 1T1R結構: 使用1T1R結構,即一個晶體管和一個電阻組成一個存儲單元。這種結構通過控制電流或電壓,可以實現對存儲單元的狀態調控,進而進行計算操作。
- 交叉陣列結構: 利用ReRAM能夠實現大規模交叉點陣列,將存儲單元排列成交叉的結構。這樣的陣列結構可以進行并行計算,提高計算效率。
自2008年ReRAM首次實驗發現以來,基于ReRAM的存內計算研究不斷涌現。特別是在2020年,清華大學研發了基于多個ReRAM陣列的存內計算系統,該系統在手寫數字集上的識別準確率達到96.19%,與軟件的識別準確率相當,證明了存內計算架構全硬件實現的可行性。測試芯片如圖所示。
盡管ReRAM存內計算技術具有廣闊的應用潛力,但目前仍面臨一些挑戰。其中主要難點包括工藝尚不夠成熟、多比特精度實現較為困難以及一致性和魯棒性較差。隨著技術的不斷發展,這些問題有望在未來得到解決,推動ReRAM存內計算技術的進一步應用和成熟。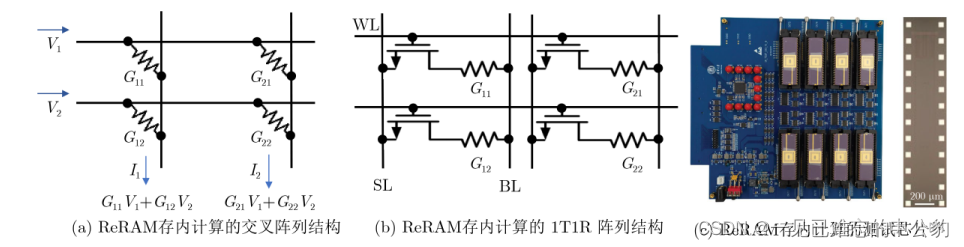
MRAM存內計算
MRAM(磁性隨機存儲器)存內計算主要有兩種技術方案:
- 基于讀/寫操作的數字式存內計算: 早期的MRAM存內計算多采用數字式方案。例如,在2015年,日本東北大學提出了一種基于讀操作實現多種布爾邏輯的方案,并通過實驗驗證獲得了48.3%的能效提升。此外,在2019年,北京航空航天大學提出了基于單次寫操作的數字式MRAM存內計算方案,實現計算結果原位存儲的同時降低了延時和功耗。
- 基于基爾霍夫電流定律和歐姆定律的模擬式存內計算: 近年來,隨著計算范式、器件和電路的創新,MRAM模擬存內計算得到了迅速發展。在2021年,美國普林斯頓大學通過電路級優化,實現了第一款基于STT-MRAM的模擬存內計算硬核。而在2022年,韓國三星公司在Nature期刊上發表了基于電阻累加方案的MRAM模擬存內計算芯片原型,并取得了最高405 TOPS/W的能效比。該芯片的陣列布局圖、顯微圖和結構如圖所示。
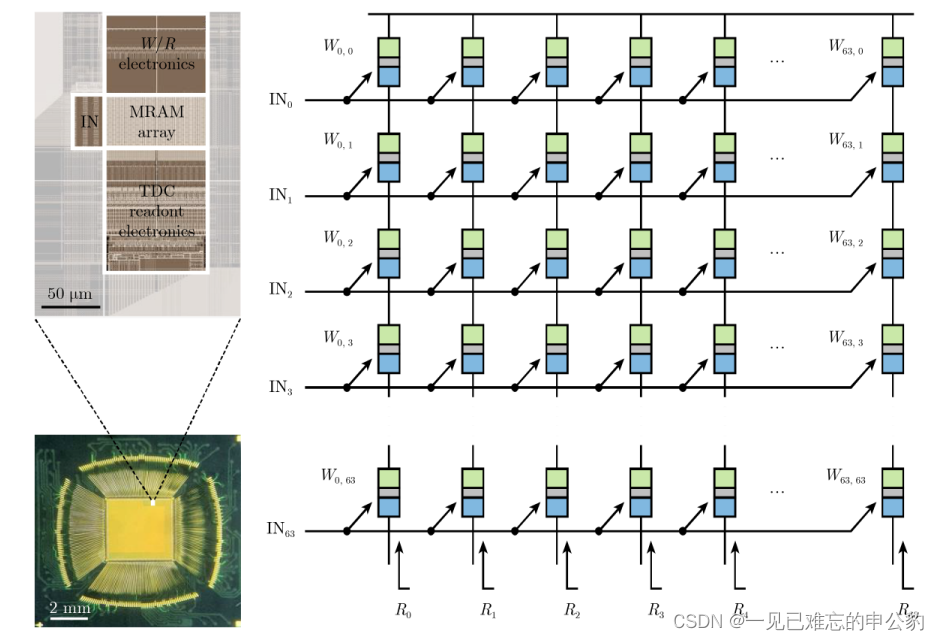
模擬式存內計算在MRAM中的難點主要體現在器件的阻值相對較小(約幾千歐姆)以及高低阻值比率相對較小(約250%),這使得實現多比特精度較為困難。然而,通過多層次的創新突破,MRAM模擬存內計算技術在最近取得了顯著的進展。
NOR Flash存內計算
基于NOR Flash的存內計算技術原理與ReRAM相似,如圖所示。目前,NOR Flash存內計算芯片技術相對較成熟,并已于2021年實現量產。美國的Mythic和國內的知存科技都推出了基于NOR Flash的存內計算芯片產品。
- Mythic M1076芯片: Mythic推出了M1076芯片,如圖所示。這款芯片采用NOR Flash存內計算技術,具有嵌入式AI推理能力,適用于各種端側設備,如攝像頭、傳感器和邊緣計算設備等。
- 知存科技WTM2101芯片: 知存科技推出了WTM2101量產SoC芯片,如圖所示。該芯片基于NOR Flash存內計算技術,具有邊緣AI計算能力,適用于智能攝像頭、智能家居等場景,實現了高效的本地AI處理。
這些NOR Flash存內計算芯片的推出表明該技術已經進入商業化階段,成為實際應用的一部分。這種技術的優勢在于其相對成熟的制造工藝和較低的成本,使其成為在端側設備中進行AI計算的有力選擇。
基于 NOR Flash 的卷積神經網絡量化
基于 NOR Flash 陣列實現模擬乘法的原理結合浮柵單元的存儲特點,以實現 4 位(即網絡正向傳播時只存在精度為 4 位的計算)的卷積神經網絡模型,采用基于動態閾值調整的量化方法。這個方法主要涉及神經網絡量化時的參數(權值 w 和偏置 b)以及激活函數的不同量化方案。
- 參數量化: 在訓練過程中,采樣浮點參數的閾值多次,以改變縮放因子,使得量化的映射更加精確。通過動態調整閾值,可以更好地適應不同參數的取值范圍,提高量化的準確性。
- 激活函數的量化: 針對激活函數,引入可學習的參數,在 ReLU(Rectified Linear Unit)激活函數中,使激活的量化可以根據實際情況在反向傳播過程中不斷更新,以提高量化精度。這樣的調整可以根據網絡的訓練過程中動態變化的激活值來調整量化的參數,以適應不同的輸入情況。
這種基于 NOR Flash 陣列和浮柵單元的量化方法可以在訓練過程中動態地調整閾值和參數,以適應不同的神經網絡結構和輸入數據的變化,提高量化的精度,同時降低模型的計算和存儲開銷。這種動態的量化方法有望在實際的卷積神經網絡模型中取得更好的性能。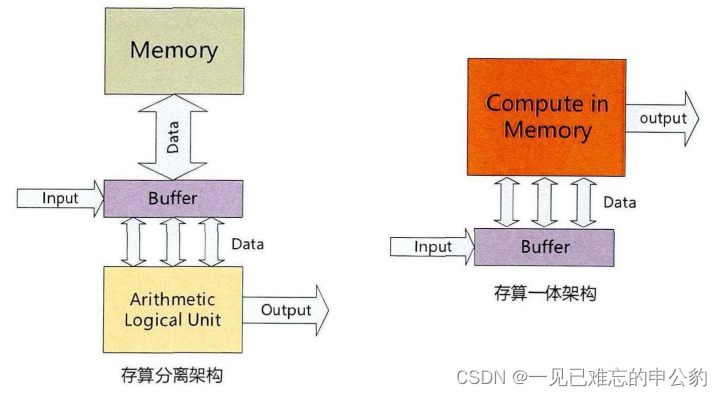
卷積神經網絡基本結構
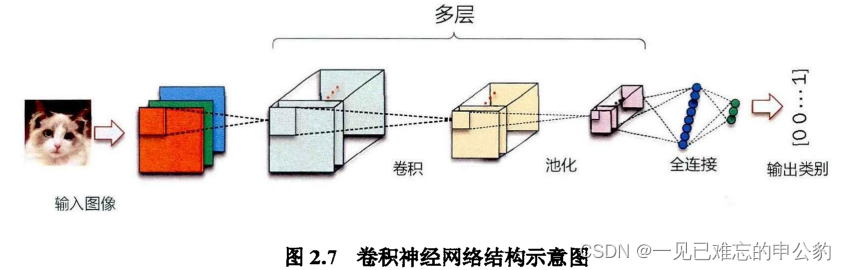
卷積神經網絡(Convolutional Neural Network,CNN)是一類專門用于處理具有類似網格結構的數據的深度學習模型,特別適用于圖像和視頻的處理。以下是卷積神經網絡的基本結構:
- 輸入層(Input Layer): 輸入層負責接收原始數據,通常是圖像的像素值。每個輸入節點對應圖像中的一個像素或一組像素。
- 卷積層(Convolutional Layer): 卷積層是卷積神經網絡的核心部分。它通過使用卷積操作從輸入數據中提取特征。卷積操作是通過濾波器(也稱為卷積核)在輸入數據上滑動并執行元素乘法和求和來實現的。這有助于捕捉輸入中的局部特征,同時減少網絡參數的數量。
- 激活函數層(Activation Layer): 卷積操作的結果通常通過一個激活函數進行非線性變換,以引入網絡的非線性特性。常見的激活函數包括ReLU(Rectified Linear Unit)和Sigmoid等。
- 池化層(Pooling Layer): 池化層用于減小特征圖的空間維度,減少計算復雜度并使網絡對平移更加不變。常見的池化操作包括最大池化和平均池化。
- 全連接層(Fully Connected Layer): 全連接層負責整合之前層的信息,并將其映射到輸出層。每個節點與前一層的所有節點相連,引入了全局信息。
- 輸出層(Output Layer): 輸出層負責生成網絡的最終輸出,通常對應于問題的類別數。對于分類問題,輸出層通常使用softmax激活函數,對每個類別產生一個概率分布。
上述結構構成了一個基本的卷積神經網絡的層次結構。在實際應用中,人們通常會堆疊多個這樣的層次,形成深層的網絡結構,以提高模型的學習能力和表示能力。深層卷積神經網絡已經在圖像識別、目標檢測、語音識別等領域取得了顯著的成果。
一維卷積: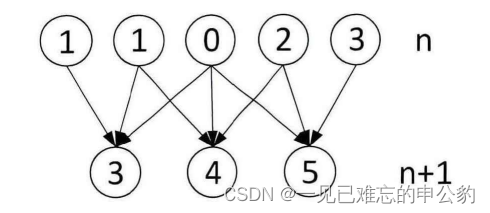
二維卷積: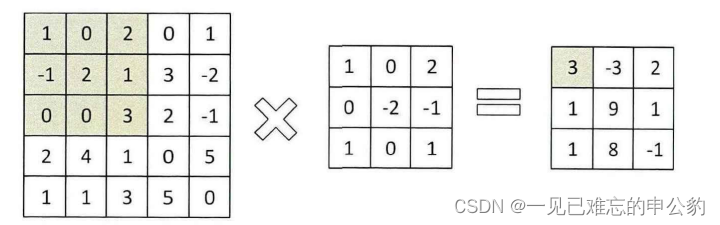
三維卷積: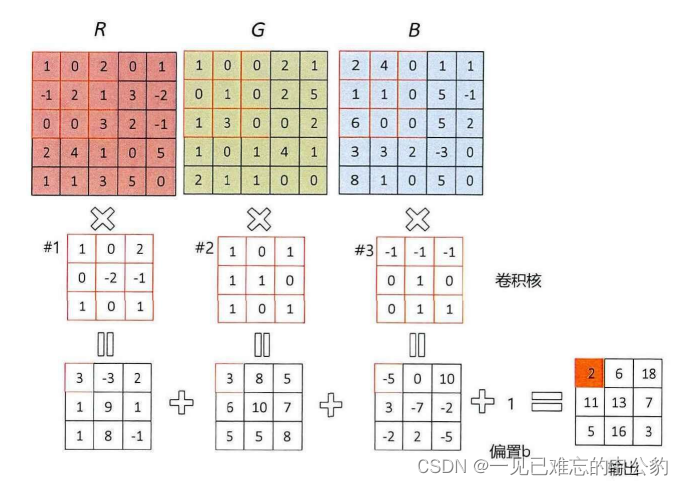
卷積神經網絡量化方法研究
基于動態閾值調整的量化方法,主要針對神經網絡中的參數和激活值的量化。以下是該方法的主要步驟:
- 參數量化: 針對模型的權重(參數),不斷采樣浮點參數,并在反向傳播過程中更新浮點參數的閾值范圍。通過這種方式,動態地調整映射系數,使得參數的量化能夠更好地適應模型的變化。
- 激活量化: 針對激活值,引入可學習的截斷參數。在激活函數中,通過學習可調整的截斷參數,使激活函數能夠在訓練過程中不斷學習,并確定最佳的截斷位置。這有助于提高激活值的量化精度。
- BN層處理: 針對批量歸一化(Batch Normalization,BN)層的浮點計算過程,提供相應的處理方案。BN層通常用于神經網絡的訓練,而在量化神經網絡中,需要特殊的處理方式來實現全整數計算。
該方法通過動態調整參數的映射系數和引入可學習的截斷參數,實現了對神經網絡的全整數計算的量化。這有助于減小神經網絡在推理階段的計算復雜度,適應特定硬件或嵌入式設備的需求。
這些措施的目標是在神經網絡的訓練過程中,通過動態調整閾值和引入可學習的參數,優化量化的精度,提高在反向傳播中的更新效果。文本還提到了對BN層和其他激活函數的相應處理,以確保整個神經網絡在量化過程中能夠保持良好的性能。
實驗及結果分析
在CIFAR-10數據集上評估動態閾值調整算法的性能。
- 數據集選擇理由: 選擇CIFAR-10數據集的原因有三點:首先,相對于MNIST數據集,CIFAR-10包含RGB三通道彩色圖像,更符合當今卷積神經網絡的應用場景;其次,相對于ImageNet數據集,CIFAR-10訓練可以使用十幾層的神經網絡,這提高了在邊緣設備上部署這些模型的可行性;最后,盡管CIFAR-10只有10個類別,但由于數據集本身的訓練難度,通過更改Softmax輸出層來實現遷移學習,從而完成更多物品的分類識別。
- CIFAR-10數據集描述: CIFAR-10數據集包括60000張大小為32x32的彩色圖像,分為10個類別,每個類別有6000張圖像。
- 訓練集和測試集劃分: 數據集中的50000張圖像用于訓練,10000張用于測試。
對于訓練難度和遷移學習的考慮使得CIFAR-10數據集成為評估動態閾值調整算法性能的有力選擇。
Res18模型精度如下圖: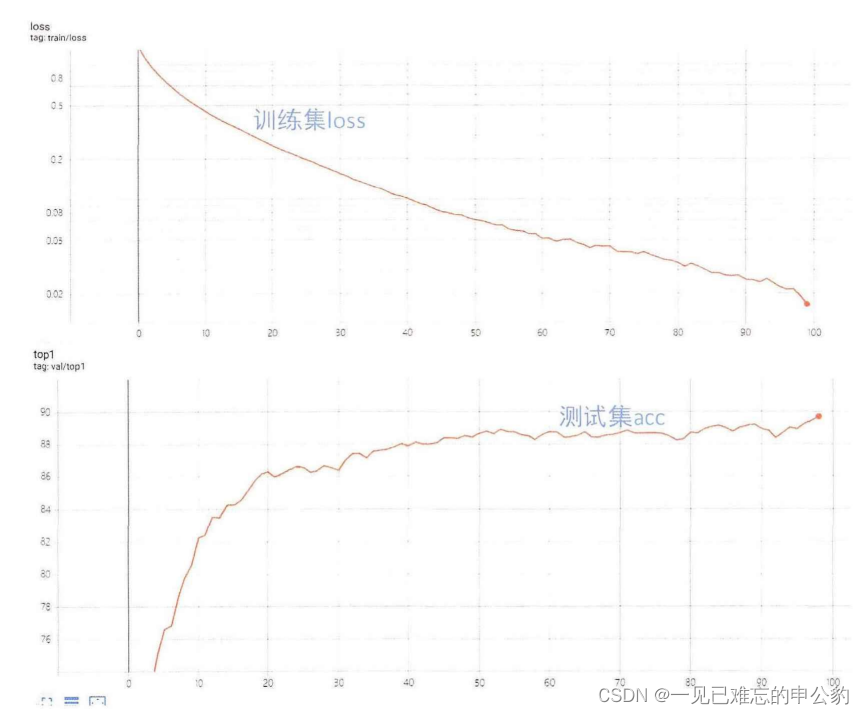
使用CIFAR-10數據集訓練的全精度AlexNet、VGG16和ResNet-18模型在測試集上的分類準確率。
- 訓練結果: 本文使用CIFAR-10數據集訓練了AlexNet、VGG16和ResNet-18模型,它們在測試集上的分類準確率分別為90.07%,91.65%,93.23%。
- 與其他工作的對比: 文中對比了其他相關工作的結果。其中,引用的文獻1使用AlexNet網絡在CIFAR-10數據集上訓練,最終分類準確率為89%。文獻2使用VGG16網絡和ResNet-18網絡在CIFAR-10數據集上分別達到90.92%和92.32%的準確率。文獻3使用ResNet-110在CIFAR-10數據集上訓練,最終分類準確率為93.57%。本文的結果與這些工作相似,但文獻3中的模型深度明顯大于本文的模型。
本文的模型在CIFAR-10數據集上達到了競爭性的分類準確率。
數據結果對比: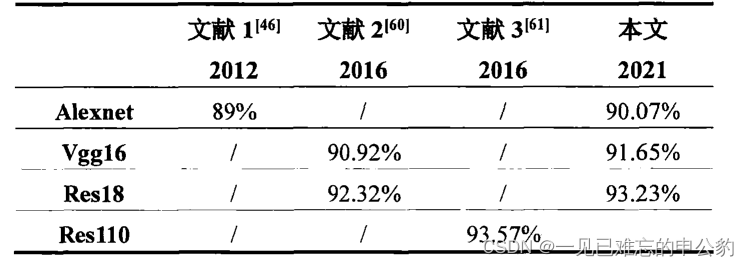
量化結果對比: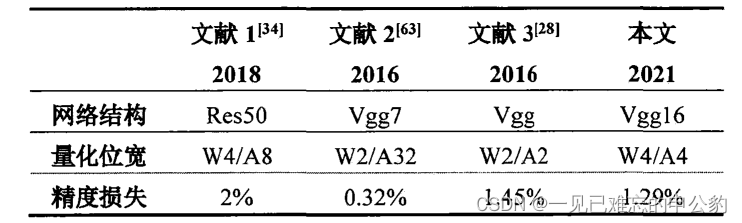
心得
經過對動態閾值量化算法的實驗驗證,包括實驗平臺及相關設置、在CIFAR-10數據集上對參數和激活層進行的驗證以及對AlexNet、VGG16和ResNet-18這三種卷積神經網絡進行4位量化的結果。
在CIFAR-10數據集上,對動態閾值量化算法進行了驗證,分別針對模型參數和激活層。實驗結果表明,該算法在減小量化模型精度損失方面取得了成功,將損失控制在1.5%以內。
對AlexNet、VGG16和ResNet-18這三種卷積神經網絡進行了4位量化的實驗。結果表明,動態閾值量化算法在這些網絡上能夠將量化模型的精度損失有效地降低到1.5%以內。
參考文獻
1.知存科技
2.中國移動研究院
3.電子與信息學報—存內計算芯片研究進展及應用
4.中科院—基于NorFlash的表積神經網絡量化
文獻內容極多,本文基于眾多文獻經過仔細仔細分析總結而來。支持存內計算發展。
審核編輯 黃宇
-
數據集
+關注
關注
4文章
1205瀏覽量
24649 -
卷積神經網絡
+關注
關注
4文章
366瀏覽量
11853 -
存算一體
+關注
關注
0文章
100瀏覽量
4288 -
存內計算
+關注
關注
0文章
29瀏覽量
1373
發布評論請先 登錄
相關推薦
卷積神經網絡如何使用
可分離卷積神經網絡在 Cortex-M 處理器上實現關鍵詞識別
輕量化神經網絡的相關資料下載
卷積神經網絡一維卷積的處理過程
卷積神經網絡模型發展及應用
面向“邊緣”應用的卷積神經網絡如何進行量化與壓縮詳細方法





 工商網監
工商網監
評論