 1024 CSDN 程序員節-基于存內計算WTM2101芯片開發板驗證語音識別
1024 CSDN 程序員節-基于存內計算WTM2101芯片開發板驗證語音識別
前言
在今年的 CSDN 程序員節上,我參與了這次知存科技舉辦的一個 AI Workshop 小活動——“基于存內計算芯片開發板驗證語音識別”,并且有幸成為完成任務的學習者之一XD。上一次參與類似的活動是算能公司舉辦的“千校萬里行”AIGC 大模型編譯部署活動,感覺雖然只是簡單的燒錄現成代碼,經歷這幾次活動后 AI 小白也能有一個小小的成就感。趁著這股新鮮感還沒冷卻,我打算寫一篇博文來記錄下這次活動的一些經歷,也供后續參與的童鞋參考~
任務目標
AISHELL-WakeUp-1 數據集是中英文喚醒詞語音數據庫,命令詞為“你好,米雅” “hi, mia” ,語音數據庫中喚醒詞語音 3936003 條,1561.12 小時,邀請 254 名發言人參與錄制。錄制過程在真實家居環境中,設置 7 個錄音位,使用 6 個圓形 16 路 PDM 麥克風陣列錄音板做遠講拾音(16kHz,16bit)、1 個高保真麥克風做近講拾音(44.1kHz, 16bit)。此數據庫可用于聲紋識別、語音喚醒識別等研究使用。
本 demo 以該數據集為例,用不同網絡結構展示模型訓練及移植過程。
我們最終想要通過語音“你好,米雅”喚醒開發板。具體步驟如下:
訓練得到模型,并轉換為知存科技開發板相應格式模型。
工具鏈編譯模型,得到模型權重表。
燒寫模型權重。
燒寫代碼。
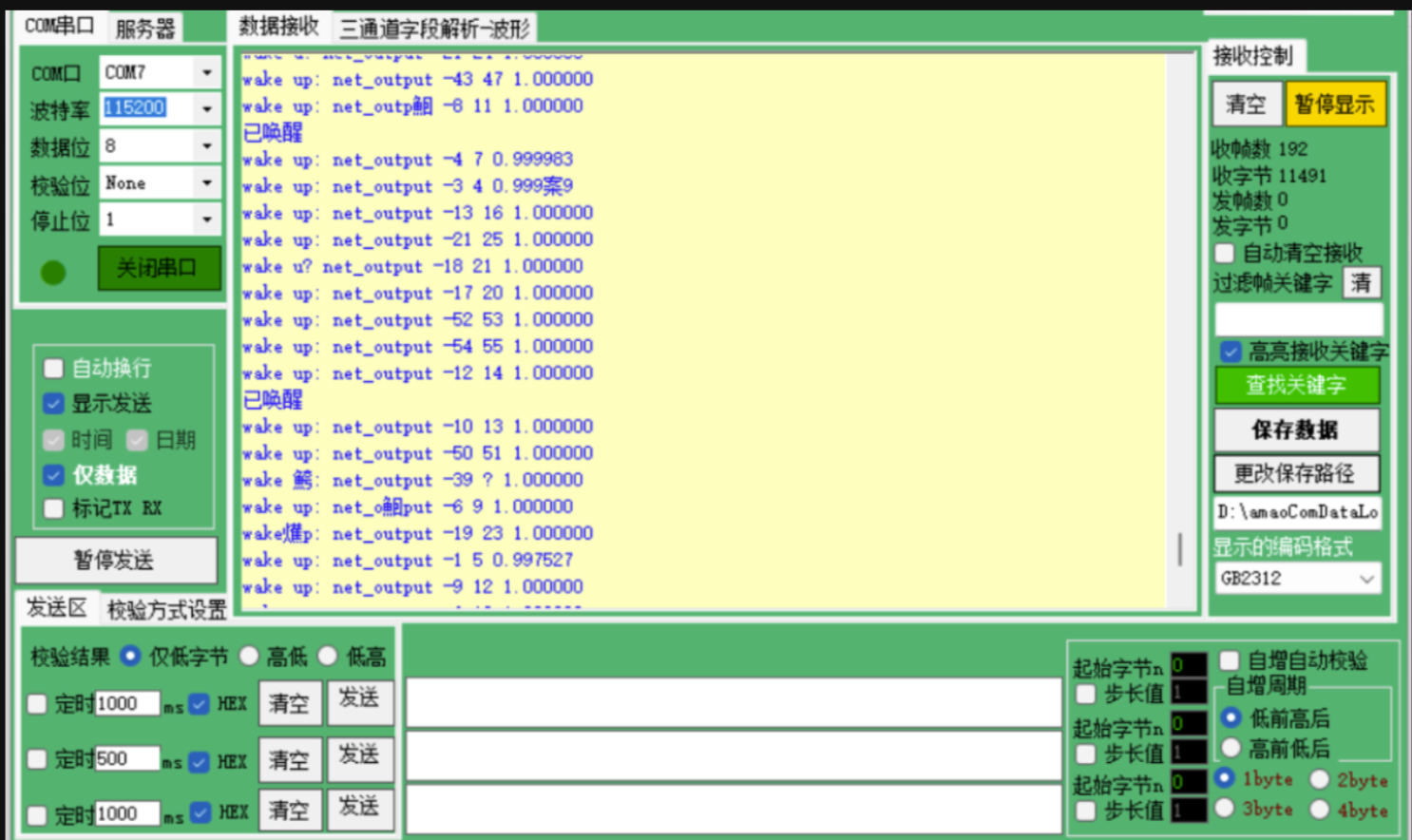
成功運行后,當我們對著開發板說出“你好,米雅”時,開發板就會通過串口發送“已喚醒”的信息。
開發板信息如下:
WTMDK2101-X3 是針對 WTM2101 AI SOC 設計的評估板,包含:
(1) WTM2101 核心板,即我們的存算芯片。
(2) 和 I/O 板:WTM2101 運行需要的電源、以及應用 I/O 接口等.

任務步驟
首先,本機上下載訓練數據和訓練代碼并運行。這樣我們就得到要燒錄到知存開發板上的對應格式的模型。

? 這一步結束后,我們可以得到以下模型+運行代碼:
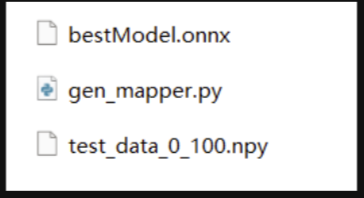
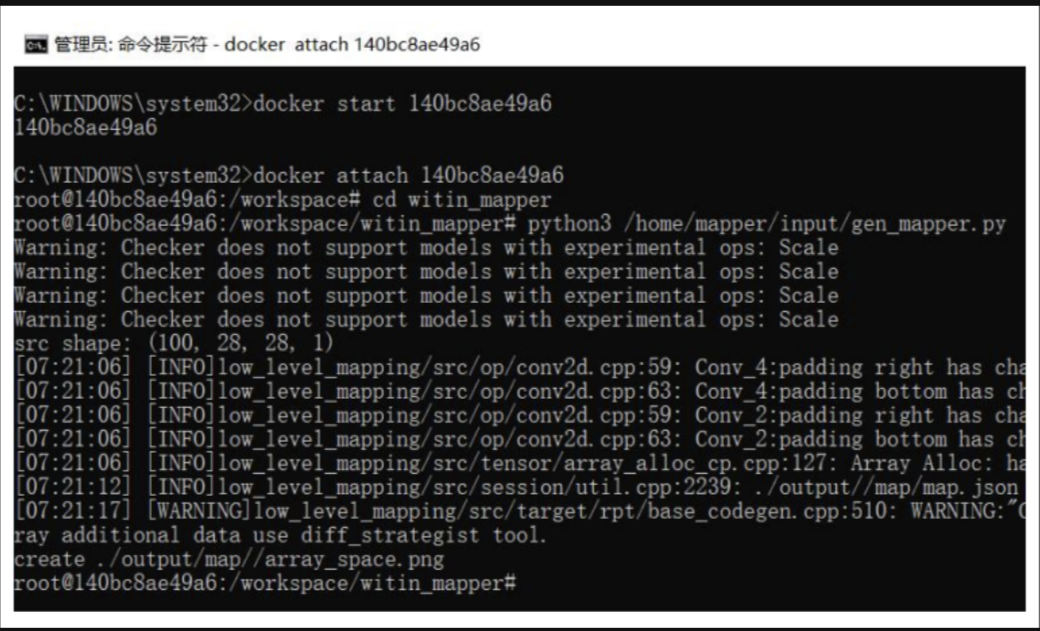
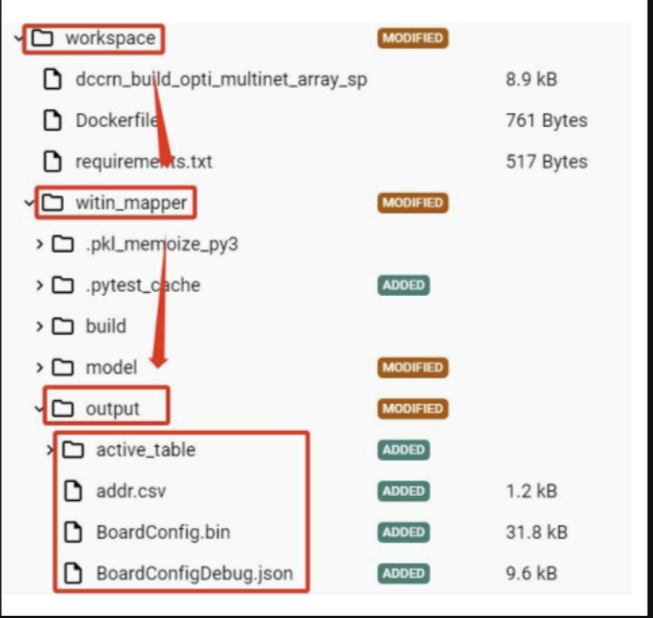
將代碼放入 docker 工具鏈環境中,編譯運行,得到輸出的模型權重表:
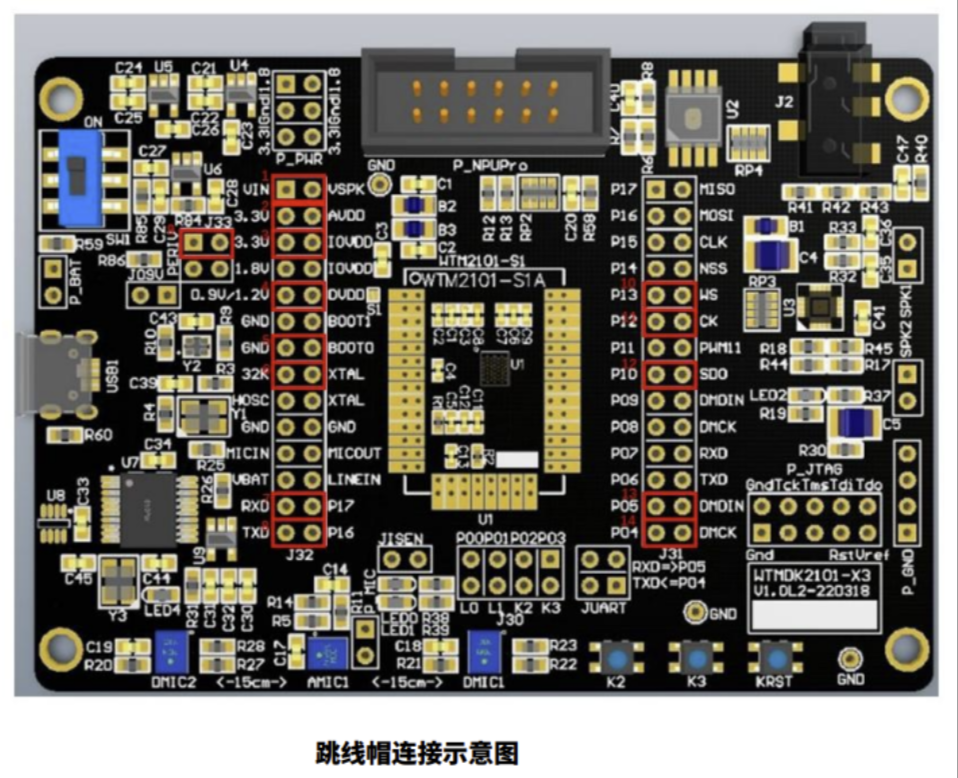
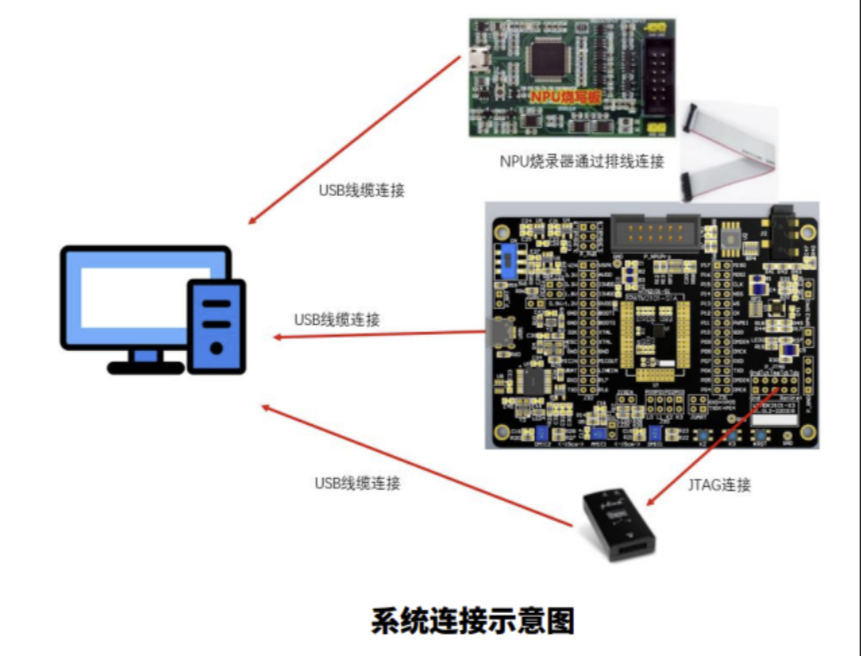
開發板連接好跳線帽、數據線如下圖:
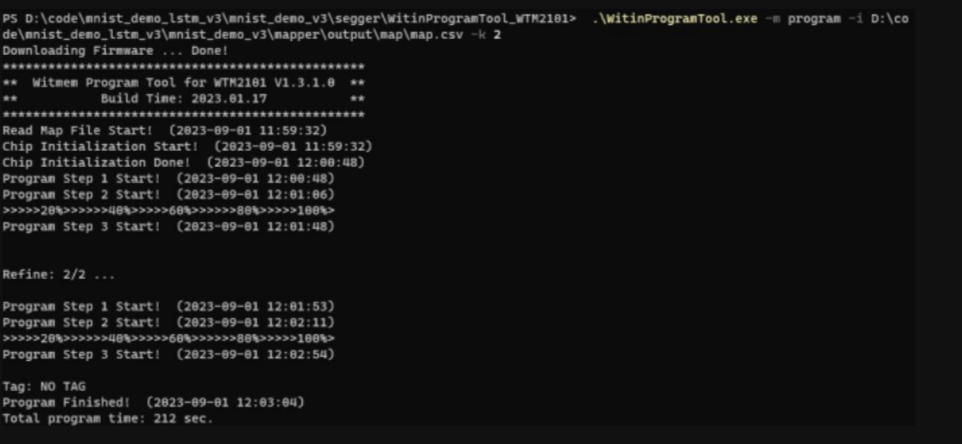
通過燒寫工具 WitinProgramTool 將模型權重燒錄到開發板上:
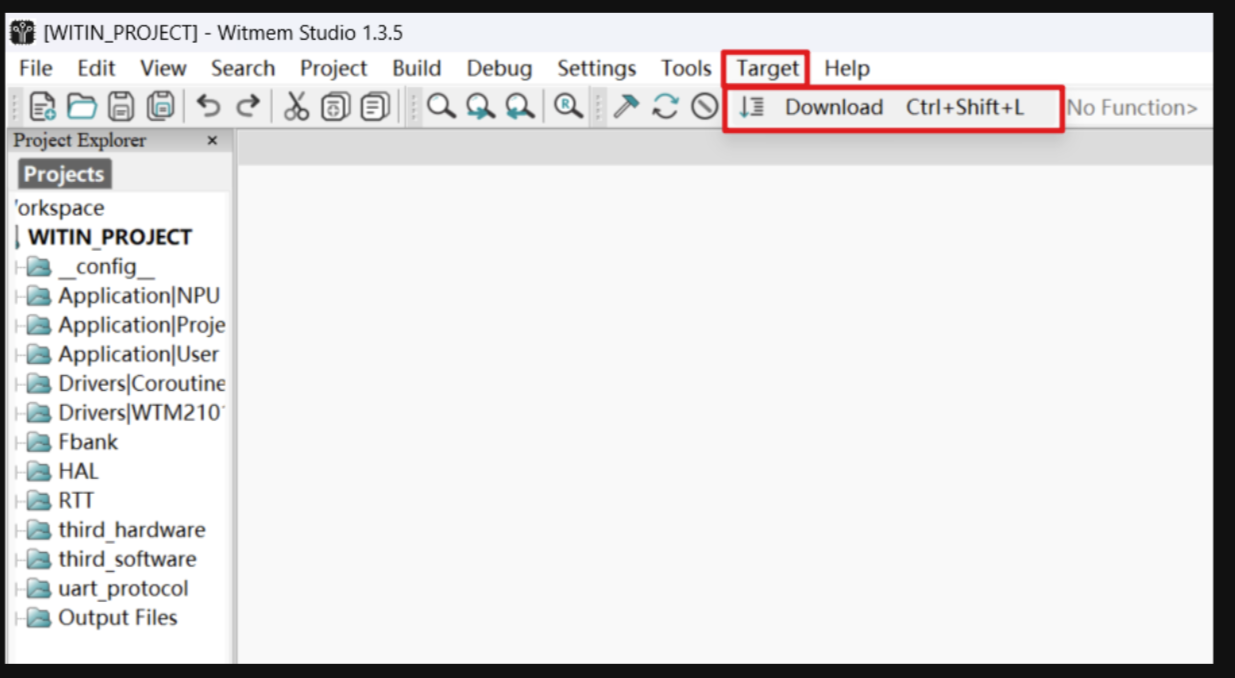
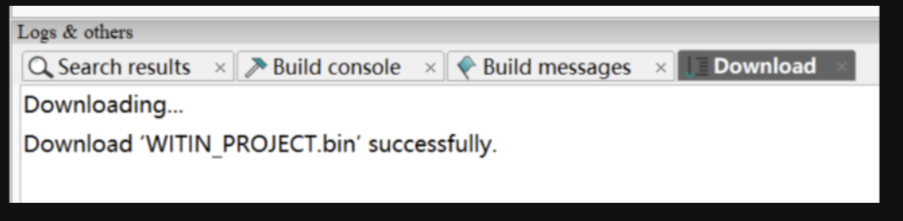
通過知存 IDE Witmem Studio,燒錄提供好的工程代碼。
打開串口調試助手(波特率115200,數據位8,停止位1,無校驗位)。若成功運行,此時當我們對著開發板說出“你好,米雅”或 “Hi, Mia” 時,串口便會輸出“已喚醒” 的提示信息。
總結
對我個人而言,我接觸 AI 非常少,只在前后端、嵌入式領域有過一些涉獵。因此,這次活動雖然在 AI 領域前輩來看可能是比較輕松的一個小任務,不過這份成就感讓我很滿足,我也大致能理解各個流程的作用。

從今年5月的 ST 峰會上大力推廣的邊緣AI,7月 RV 峰會上百家爭鳴的 AI 應用,這兩次算能和知存科技的 AI 硬件體驗活動,我逐漸也能感覺到 AI (特別是當下的 AIGC)對嵌入式領域同樣不容小覷的影響。現階段自己的學習還停留在一些簡單的控制,RTOS 這些。也許加深一些學習后,未來也可能在嵌入式深度學習領域有所學習~
審核編輯 黃宇
-
AI
+關注
關注
87文章
28877瀏覽量
266236 -
數據庫
+關注
關注
7文章
3712瀏覽量
64025 -
語音識別
+關注
關注
38文章
1696瀏覽量
112248 -
開發板
+關注
關注
25文章
4771瀏覽量
96178 -
存內計算
+關注
關注
0文章
28瀏覽量
1348
發布評論請先 登錄
相關推薦
【基于存內計算芯片開發板驗證語音識別】訓練手冊
存內計算WTM2101編譯工具鏈 資料

1024程序員節怎么過?帶上電腦去旅行!
知存科技WTM2101語音芯片的具備四個優勢

創新成果受肯定,WTM2101芯片亮相中關村論壇多個展區

2023 長沙-中國1024程序員節全面啟動

1024程序員節特別篇 | 知存科技xCSDN北京·杭州雙城嘉年華精彩回顧

今天程序員節長沙出招 全國首個!長沙為程序員打造“1024街”
喜迎1024程序員節!祝各位開發者們“碼”到“程”功!

一文速覽!拓維信息@1024程序員節精彩看點

智能低代碼洪流涌動程序員節,華為云 Astro 觸發 1024 的乘法效應!






 工商網監
工商網監
評論