") 請(qǐng)問移動(dòng)端生成式AI如何在Arm CPU上運(yùn)行呢?
請(qǐng)問移動(dòng)端生成式AI如何在Arm CPU上運(yùn)行呢?
2023 年,生成式人工智能 (Generative AI) 領(lǐng)域涌現(xiàn)出諸多用例。這一突破性的人工智能 (AI) 技術(shù)是 OpenAI 的 ChatGPT 和 Google 的 Gemini AI 模型的核心,能夠根據(jù)用戶輸入的文本提示生成文本、圖像,甚至音頻內(nèi)容,其有望簡化工作流程和推動(dòng)教育發(fā)展。這是不是聽起來相當(dāng)震撼呢?
而隨著生成式 AI 技術(shù)下沉到我們鐘愛的消費(fèi)電子設(shè)備上,其未來又將會(huì)如何發(fā)展?答案是,在邊緣移動(dòng)設(shè)備上部署生成式 AI。
在本文中,我們將展示大語言模型 (LLM) 作為一種生成式 AI 推理形式,如何在基于 Arm 技術(shù)的多數(shù)移動(dòng)設(shè)備上運(yùn)行。此外我們還將介紹,鑒于此類 AI 工作負(fù)載所需的典型批量處理大小以及計(jì)算和帶寬的平衡,Arm CPU 如何適配此類用例。并進(jìn)一步闡釋 Arm CPU 的 AI 功能,展示其靈活性和可編程性如何巧妙地實(shí)現(xiàn)軟件優(yōu)化,從而為許多 LLM 用例帶來巨大的性能優(yōu)勢(shì)和發(fā)展機(jī)會(huì)。
LLM 簡介
生成式 AI 可采用的網(wǎng)絡(luò)架構(gòu)多種多樣。LLM 以其無可比擬的大規(guī)模解釋和生成文本的能力,迅速嶄露頭角。
顧名思義,大語言模型 (LLM) 比以往使用的模型要大得多。確切地說,其可訓(xùn)練參數(shù)達(dá)到一千億到一萬億。如此規(guī)模的參數(shù)量,至少是 2018 年 Google 訓(xùn)練的最大型先進(jìn)自然語言處理 (NLP) 模型之一的 BERT(基于 Transformer 的雙向編碼器表示技術(shù))三倍以上的數(shù)量級(jí)。
那么,一個(gè)一千億參數(shù)的模型如何轉(zhuǎn)化為 RAM 呢?如果打算在使用 16 位浮點(diǎn)數(shù)加速的處理器上部署這一模型,那么至少需要 200 GB 的 RAM!
因此,這些大模型只能在云端運(yùn)行。然而,這帶來了三個(gè)根本性的挑戰(zhàn),并進(jìn)而限制此項(xiàng)技術(shù)的普及:
高昂的基礎(chǔ)設(shè)施成本
隱私問題(因?yàn)橛脩魯?shù)據(jù)可能會(huì)泄漏)
可擴(kuò)展性挑戰(zhàn)
2023 年下半年,一些規(guī)模較小、效率更高的 LLM 逐漸涌現(xiàn)。這些模型將生成式 AI 擴(kuò)展至移動(dòng)端,讓此項(xiàng)技術(shù)的應(yīng)用變得更加普遍。
2023 年,Meta 的 Llama 2、Google 的 Gemini Nano 和微軟的 Phi-2 開辟了移動(dòng)端 LLM 的部署,以解決上述三大挑戰(zhàn)。具體來說,這三個(gè)模型的可訓(xùn)練參數(shù)分別達(dá)到 70 億、32.5 億和 27 億。
在移動(dòng)端 CPU 上運(yùn)行 LLM
基于 Arm 技術(shù),當(dāng)今的移動(dòng)設(shè)備擁有強(qiáng)大的計(jì)算能力,能夠?qū)崟r(shí)運(yùn)行復(fù)雜的 AI 算法。事實(shí)上,現(xiàn)有的旗艦和高端智能手機(jī)已經(jīng)可以運(yùn)行 LLM。
預(yù)計(jì)未來 LLM 在移動(dòng)端的部署將會(huì)加速,并可能出現(xiàn)如下用例:
文本生成:舉例而言,我們要求虛擬助理為我們撰寫一封電子郵件。
智能回復(fù):即時(shí)通訊應(yīng)用自動(dòng)提供針對(duì)某個(gè)問題的建議回復(fù)。
文本摘要:電子書閱讀器提供章節(jié)摘要。
在上述的用例中,模型需要處理大量的用戶數(shù)據(jù)。而在邊緣側(cè)運(yùn)行的 LLM 則無需連接網(wǎng)絡(luò),用戶數(shù)據(jù)便會(huì)保留在設(shè)備中,這將有助于保護(hù)個(gè)人隱私,同時(shí)降低延遲,改善響應(yīng)速度和用戶體驗(yàn)。這些都是在邊緣側(cè)移動(dòng)設(shè)備上部署 LLM 所能帶來的優(yōu)勢(shì)。
幸運(yùn)的是,得益于 Arm CPU,全世界約 99% 的智能手機(jī)都具備在邊緣側(cè)處理 LLM 所需的技術(shù)。
在 2024 世界移動(dòng)通信大會(huì) (MWC 2024) 上 Arm 進(jìn)行了相關(guān)演示,敬請(qǐng)觀看以下視頻:
該視頻演示了在搭載三核 Arm Cortex-A700 系列 CPU 核心的現(xiàn)有安卓手機(jī)上運(yùn)行 Llama2-7B LLM 的性能表現(xiàn)。視頻中展示的是實(shí)際運(yùn)行速度,可以看到安卓應(yīng)用里的虛擬助手反應(yīng)非常靈敏,回復(fù)速度很快。詞元 (Token) 首次響應(yīng)時(shí)間表現(xiàn)驚人,文本生成速率達(dá)到每秒 9.6 個(gè)詞元,高于人們的平均閱讀速度。這得益于現(xiàn)有針對(duì) AI 設(shè)計(jì)的 CPU 指令和專門為 LLM 進(jìn)行的軟件優(yōu)化。更重要的是,所有處理都在邊緣(即移動(dòng)設(shè)備上)本地完成。
隨著新模型的不斷涌現(xiàn),Arm 也在不斷地改進(jìn) Arm 平臺(tái)上的 LLM 體驗(yàn)。隨著近期 Meta 推出了最新 Llama 3 模型,以及微軟發(fā)布了 Phi-3-mini (Phi-3 3.8B) 模型,我們迅速地讓它們得以在移動(dòng)設(shè)備上的 Arm CPU 運(yùn)行。Llama 3 和 Phi-3-mini 比它們的前代模型更大。從體量上來看,最小版本的 Llama 2 為 7B,而 Llama 3 達(dá)到了 8B;另外,Phi-2 為 2.7B,而 Phi-3-mini 達(dá)到了 3.8B。這些新的 AI 模型能力更強(qiáng),可以回應(yīng)更廣泛的問題。
新的演示配備了一個(gè)經(jīng)過專門訓(xùn)練的聊天機(jī)器人“Ada”,可以作為科學(xué)和編碼的虛擬助教。在以下視頻中運(yùn)行的 Phi-3-mini 模型顯示出同樣令人印象深刻的詞元首次響應(yīng)時(shí)間性能,文本生成速率每秒超過 15 個(gè)詞元。該演示基于我們?yōu)?Llama 2 和 Phi-2 開發(fā)的現(xiàn)有軟件優(yōu)化。盡管這些模型更大、更復(fù)雜,但這清楚地表明它們可以在當(dāng)今由 Arm CPU 驅(qū)動(dòng)的移動(dòng)設(shè)備上良好運(yùn)行。
那么這些演示是如何開發(fā)出來的呢?接下來,我將分享一些技巧,來幫助大家在搭載 Arm CPU 的安卓手機(jī)上部署 LLM。
在移動(dòng)設(shè)備上部署 LLM
首先要強(qiáng)調(diào)的是,Arm CPU 為 AI 開發(fā)者提供了諸多便利。因此,如今第三方應(yīng)用中有 70% 的 AI 應(yīng)用均運(yùn)行在 Arm CPU 上。由于其編程能力非常靈活,AI 開發(fā)者可以嘗試應(yīng)用創(chuàng)新的壓縮和量化技術(shù),讓 LLM 更加小巧,并且在各種環(huán)境下運(yùn)行得更快。實(shí)際上,我們之所以能運(yùn)行一個(gè)具有 70 億參數(shù)的模型,關(guān)鍵就在于整數(shù)量化技術(shù),我們的演示中使用的是 int4。
int4 位量化
作為一項(xiàng)關(guān)鍵技術(shù),量化可以將 AI 和機(jī)器學(xué)習(xí) (ML) 模型壓縮至足夠小,以便能在 RAM 有限的設(shè)備上高效運(yùn)行。因此,這項(xiàng)技術(shù)對(duì)于那些原生以浮點(diǎn)數(shù)據(jù)類型(如 32 位浮點(diǎn) FP32 和 16 位浮點(diǎn) FP16)存儲(chǔ)數(shù)十億可訓(xùn)練參數(shù)的 LLM 來說,是必不可少的。例如,采用 FP16 權(quán)重的 Llama2-7B 版本至少需要大約 14 GB 的 RAM,而這是許多移動(dòng)設(shè)備無法滿足的條件。
通過將 FP16 模型量化到四位,我們可以將其大小縮減至原來的四分之一,并將 RAM 使用量降低到大約 4 GB。得益于 Arm CPU 提供的巨大軟件靈活性,開發(fā)者還可以通過減少參數(shù)值位數(shù)來獲得更小的模型。但請(qǐng)注意,將位數(shù)減少至三位或兩位可能會(huì)導(dǎo)致準(zhǔn)確度明顯降低。
在 CPU 上運(yùn)行工作負(fù)載時(shí),我們建議通過一個(gè)簡單的技巧來提高其性能,即設(shè)置線程的 CPU 關(guān)聯(lián)性。
采用線程關(guān)聯(lián)性改善 LLM 的實(shí)時(shí)體驗(yàn)
一般來說,當(dāng)部署 CPU 應(yīng)用時(shí),操作系統(tǒng) (OS) 負(fù)責(zé)選擇運(yùn)行線程的核心。此決策并不總是以實(shí)現(xiàn)最佳性能為目標(biāo)。
但是,對(duì)于非常看重性能表現(xiàn)的應(yīng)用而言,開發(fā)者可以使用線程關(guān)聯(lián)性,強(qiáng)制線程運(yùn)行在特定核心上。這項(xiàng)技術(shù)幫助我們提升了 10% 以上的延遲速度。
您可以通過關(guān)聯(lián)性掩碼指定線程關(guān)聯(lián)性,關(guān)聯(lián)性掩碼的每一位都代表系統(tǒng)中的一個(gè) CPU 核心。假設(shè)有八核,其中四核是 Arm Cortex-A715 CPU,并被分配給位掩碼的最高有效位 (0b1111 0000)。
為了在每個(gè) Cortex-A715 CPU 核心上運(yùn)行每個(gè)線程,我們應(yīng)該在執(zhí)行工作負(fù)載之前將線程關(guān)聯(lián)性掩碼傳遞給系統(tǒng)調(diào)度程序。在安卓設(shè)備中,此操作可通過以下系統(tǒng)調(diào)用函數(shù)完成:
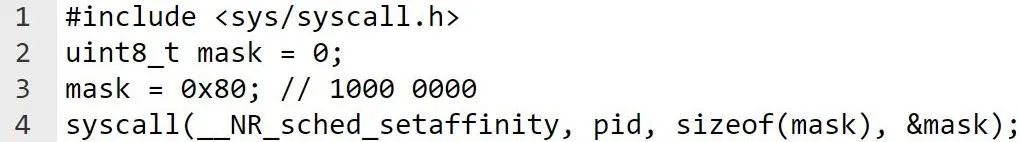
例如,假設(shè)有兩個(gè)線程,我們可以為每個(gè)線程使用以下位掩碼:
線程 1:位掩碼 0b1000 0000
線程 2:位掩碼 0b0100 0000
執(zhí)行工作負(fù)載后,我們應(yīng)將關(guān)聯(lián)性掩碼重置為默認(rèn)狀態(tài),如下面的代碼片段所示:

通過利用線程關(guān)聯(lián)性,您可輕松提高各類 CPU 工作負(fù)載性能。然而,僅靠 int4 量化和線程關(guān)聯(lián)性還不足以全方面發(fā)揮 LLM 的性能。我們知道,低延遲直接關(guān)系到用戶的整體體驗(yàn),對(duì)此類模型至關(guān)重要。
因此,Arm 開發(fā)了高度優(yōu)化的 int4 矩陣乘向量和矩陣乘矩陣 CPU 例程,以顯著提升性能表現(xiàn)。
Arm int4 優(yōu)化矩陣乘矩陣和矩陣乘向量例程
矩陣乘矩陣和矩陣乘向量例程是對(duì) LLM 性能至關(guān)重要的函數(shù)。這些例程已使用 SDOT 和 SMMLA 指令針對(duì) Cortex-A700 系列 CPU 進(jìn)行了優(yōu)化。相較于 llama.cpp 中的原生實(shí)現(xiàn),我們的例程(即將推出)將詞元首次響應(yīng)時(shí)間(編碼器)縮短了 50% 以上,文本生成速率提升了 20%。
這僅僅只是開始......
出色的用戶體驗(yàn)、優(yōu)越的性能表現(xiàn),而這僅僅只是開始......借助專用 AI 指令、CPU 線程關(guān)聯(lián)性,以及經(jīng)過軟件優(yōu)化的例程,這些演示展示了出色的交互式用例的整體使用體驗(yàn)。上文中的演示視頻展示出,詞元首次響應(yīng)時(shí)間非常短,文本生成速率快于人們的平均閱讀速度。更令人興奮的是,所有搭載 Cortex-A700 的移動(dòng)設(shè)備均能實(shí)現(xiàn)這樣的性能表現(xiàn)。
我們也很高興看到開發(fā)者開源社區(qū)參與到 Arm 平臺(tái)上的模型工作。Arm CPU 為 AI 開發(fā)者社區(qū)提供了試煉自己技術(shù)的機(jī)會(huì),以提供進(jìn)一步的軟件優(yōu)化,使 LLM 得以更小、更快、更高效。開源社區(qū)中的開發(fā)者大約在 48 小時(shí)內(nèi)就成功在 Arm 平臺(tái)上啟動(dòng)并運(yùn)行了新模型,這便是很好的例證。我們期待看到更多來自開源的力量參與到 Arm 平臺(tái)上的生成式 AI 開發(fā)。
而這只是基于 Arm 技術(shù)的 LLM 體驗(yàn)的初期成果。隨著 LLM 變得更加小巧而精密,它們?cè)谶吘壱苿?dòng)設(shè)備上的表現(xiàn)也將穩(wěn)步提升。此外,Arm 以及我們行業(yè)領(lǐng)先生態(tài)系統(tǒng)中的合作伙伴將繼續(xù)推動(dòng)硬件進(jìn)步和軟件優(yōu)化,加速發(fā)展 CPU 指令集的 AI 功能,如針對(duì) Armv9-A 架構(gòu)的可伸縮矩陣擴(kuò)展 (Scalable Matrix Extension, SME) 等。這些進(jìn)展預(yù)示著在不久的未來,基于 Arm 架構(gòu)的消費(fèi)電子設(shè)備將迎來 LLM 用例的新時(shí)代。
審核編輯:劉清
-
RAM
+關(guān)注
關(guān)注
8文章
1367瀏覽量
114529 -
人工智能
+關(guān)注
關(guān)注
1791文章
46853瀏覽量
237546 -
LLM
+關(guān)注
關(guān)注
0文章
273瀏覽量
306 -
生成式AI
+關(guān)注
關(guān)注
0文章
487瀏覽量
459
原文標(biāo)題:移動(dòng)端生成式 AI 如何在 Arm CPU 上運(yùn)行?
文章出處:【微信號(hào):Arm社區(qū),微信公眾號(hào):Arm社區(qū)】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
MediaTek發(fā)布天璣8300移動(dòng)芯片,全面革新推動(dòng)端側(cè)生成式AI創(chuàng)新
新功能get√:AI大學(xué)移動(dòng)端,來了!
如何在RK3399這一 Arm64平臺(tái)上搭建Tengine AI推理框架呢
如何在RK3399上搭建Tengine AI推理框架呢
如何在基于Arm的設(shè)備上運(yùn)行游戲AI呢
程序是如何在 CPU 中運(yùn)行的(二)

英偉達(dá) GTC 2023上黃仁勛談生成式AI

移動(dòng)設(shè)備部署機(jī)器學(xué)習(xí),Arm談如何賦能移動(dòng)AI
利用 NVIDIA Jetson 實(shí)現(xiàn)生成式 AI
MediaTek 發(fā)布天璣 8300 移動(dòng)芯片,全面革新推動(dòng)端側(cè)生成式 AI 創(chuàng)新

Arm平臺(tái)賦能移動(dòng)端生成式AI
新的Armv9 CPU技術(shù)加速AI在移動(dòng)設(shè)備等領(lǐng)域的發(fā)展
原來這才是【生成式AI】!!

在設(shè)備上利用AI Edge Torch生成式API部署自定義大語言模型






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論