 浪潮信息發布源2.0-M32開源大模型,模算效率大幅提升
浪潮信息發布源2.0-M32開源大模型,模算效率大幅提升
5月28日,浪潮信息發布“源2.0-M32”開源大模型。“源2.0-M32”在基于”源2.0”系列大模型已有工作基礎上,創新性地提出和采用了“基于注意力機制的門控網絡”技術,構建包含32個專家(Expert)的混合專家模型(MoE),并大幅提升了模型算力效率,模型運行時激活參數為37億,在業界主流基準評測中性能全面對標700億參數的LLaMA3開源大模型。
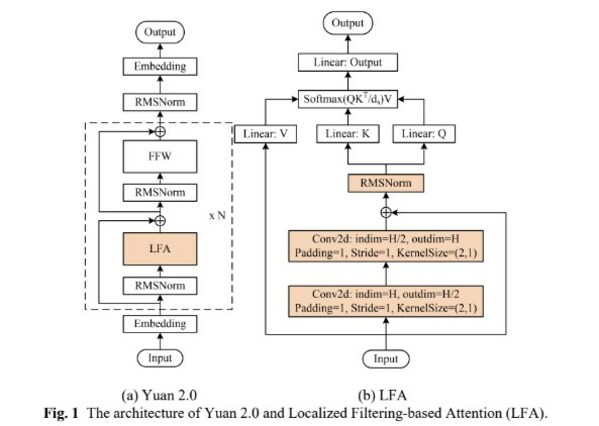
■ 算法層面,源2.0-M32提出并采用了一種新型的算法結構:基于注意力機制的門控網絡(Attention Router),針對MoE模型核心的專家調度策略,這種新的算法結構關注專家模型之間的協同性度量,有效解決傳統門控網絡下,選擇兩個或多個專家參與計算時關聯性缺失的問題,使得專家之間協同處理數據的水平大為提升。源2.0-M32采用源2.0-2B為基礎模型設計,沿用并融合局部過濾增強的注意力機制(LFA, Localized Filtering-based Attention),通過先學習相鄰詞之間的關聯性,然后再計算全局關聯性的方法,能夠更好地學習到自然語言的局部和全局的語言特征,對于自然語言的關聯語義理解更準確,進而提升了模型精度。
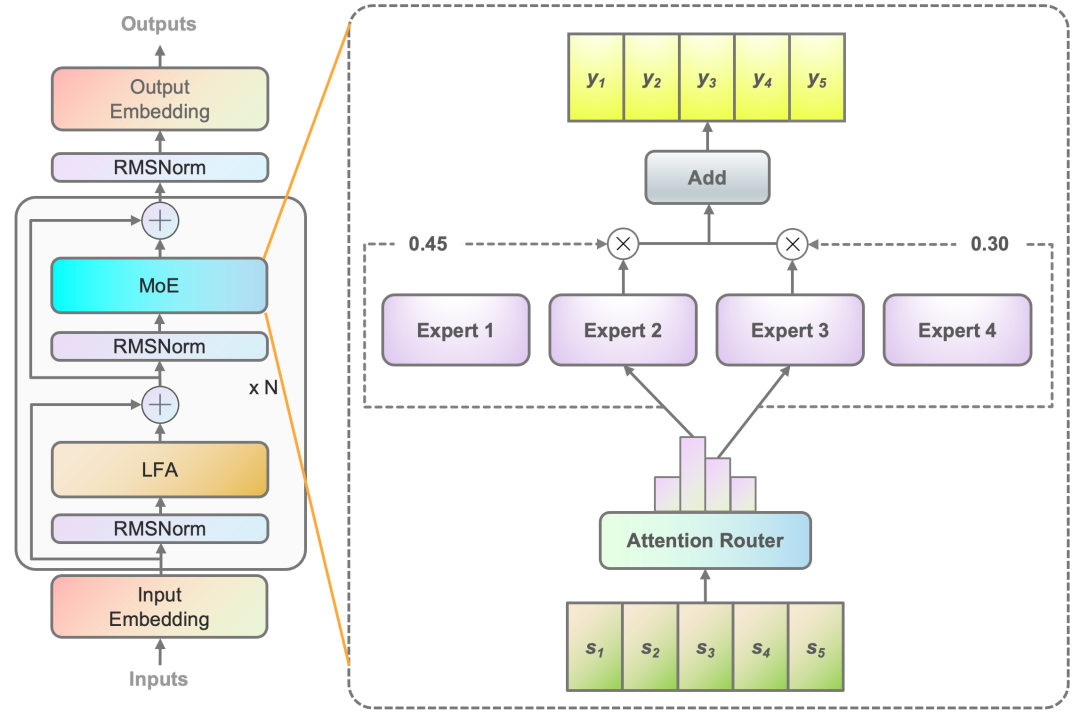
Figure1基于注意力機制的門控網絡(Attention Router)
■ 數據層面,源2.0-M32基于2萬億的token進行訓練、覆蓋萬億量級的代碼、中英文書籍、百科、論文及合成數據。大幅擴展代碼數據占比至47.5%,從6類最流行的代碼擴充至619類,并通過對代碼中英文注釋的翻譯,將中文代碼數據量增大至1800億token。結合高效的數據清洗流程,滿足大模型訓練“豐富性、全面性、高質量”的數據集需求。基于這些數據的整合和擴展,源2.0-M32在代碼生成、代碼理解、代碼推理、數學求解等方面有著出色的表現。
■ 算力層面,源2.0-M32采用了非均勻流水并行的方法,綜合運用流水線并行+數據并行的策略,顯著降低了大模型對芯片間P2P帶寬的需求,為硬件差異較大訓練環境提供了一種高性能的訓練方法。針對MoE模型的稀疏專家計算,采用合并矩陣乘法的方法,模算效率得到大幅提升。
基于在算法、數據和算力方面全面創新,源2.0-M32的性能得以大幅提升,在多個業界主流的評測任務中,展示出了較為先進的能力表現,在MATH(數學競賽)、ARC-C(科學推理)榜單上超越了擁有700億參數的LLaMA3大模型。
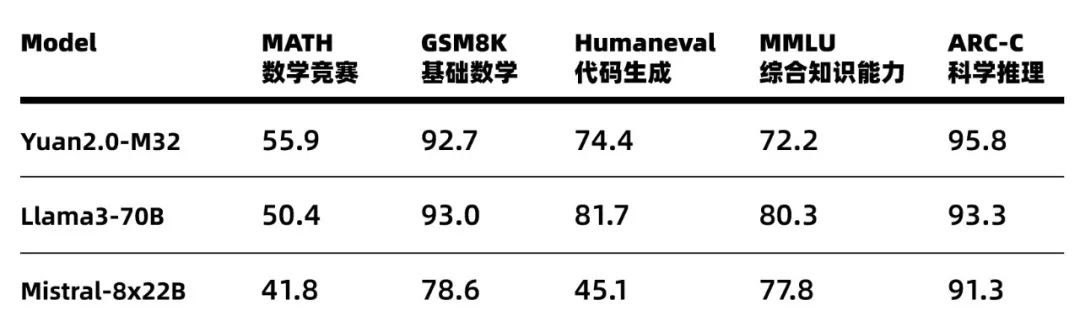
Figure2 源2.0-M32業界主流評測任務表現
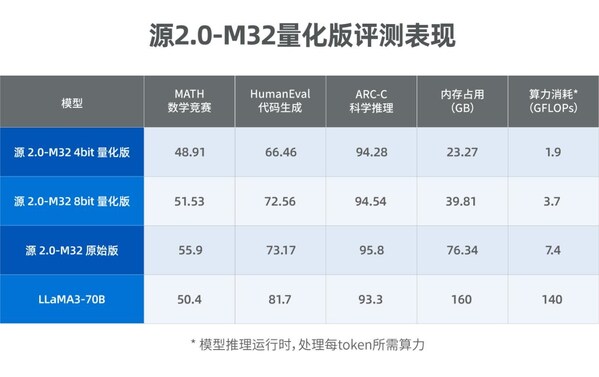
源2.0-M32大幅提升了模型算力效率,在實現與業界領先開源大模型性能相當的同時,顯著降低了在模型訓練、微調和推理所需的算力開銷。在模型推理運行階段,M32處理每token所需算力為7.4GFLOPs,而LLaMA3-70B所需算力為140GFLOPs。在模型微調訓練階段,對1萬條平均長度為1024 token的樣本進行全量微調,M32消耗算力約0.0026PD(PetaFLOPs/s-day),而LLaMA3消耗算力約為0.05PD。M32憑借特別優化設計的模型架構,在僅激活37億參數的情況下,取得了和700億參數LLaMA3相當的性能水平,而所消耗算力僅為LLaMA3的1/19,從而實現了更高的模算效率。
浪潮信息人工智能首席科學家吳韶華表示:當前業界大模型在性能不斷提升的同時,也面臨著所消耗算力大幅攀升的問題,對企業落地應用大模型帶來了極大的困難和挑戰。源2.0-M32是浪潮信息在大模型領域持續耕耘的最新探索成果,通過在算法、數據、算力等方面的全面創新,M32不僅可以提供與業界領先開源大模型相當的性能,更可以大幅降低大模型所需算力消耗。大幅提升的模算效率將為企業開發應用生成式AI提供模型高性能、算力低門檻的高效路徑。M32開源大模型配合企業大模型開發平臺EPAI(Enterprise Platform of AI),將助力企業實現更快的技術迭代與高效的應用落地,為人工智能產業的發展提供堅實的底座和成長的土壤,加速產業智能化進程。
-
人工智能
+關注
關注
1791文章
46856瀏覽量
237551 -
大模型
+關注
關注
2文章
2328瀏覽量
2481 -
生成式AI
+關注
關注
0文章
488瀏覽量
459
原文標題:浪潮信息發布源2.0-M32開源大模型,模算效率大幅提升,37億激活參數性能對標LLaMA3-700億
文章出處:【微信號:浪潮AIHPC,微信公眾號:浪潮AIHPC】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
浪潮信息發布KOS AI定制版,大幅提升大模型訓練效率
浪潮信息源2.0大模型與百度PaddleNLP全面適配
浪潮信息:元腦企智EPAI助力金融大模型快速落地

源2.0-M32大模型發布量化版 運行顯存僅需23GB 性能可媲美LLaMA3
浪潮信息攜全棧智算產品和方案亮相WAIC 2024
浪潮信息發布為大模型專門優化的分布式全閃存儲AS13000G7-N系列

浪潮信息發布企業大模型開發平臺"元腦企智"EPAI,加速AI創新落地

浪潮信息發布企業大模型開發平臺“元腦企智”EPAI

浪潮信息"源2.0"大模型YuanChat支持英特爾最新商用AI PC

浪潮信息與英特爾合作推出一種大模型效率工具“YuanChat”

潞晨科技Colossal-AI與浪潮信息AIStation完成兼容性互認證
潞晨科技Colossal-AI + 浪潮信息AIStation,大模型開發效率提升10倍





 工商網監
工商網監
評論