 “Spark+Hive”在DPU環境下的性能測評 | OLAP數據庫引擎選型白皮書(24版)DPU部分節選
“Spark+Hive”在DPU環境下的性能測評 | OLAP數據庫引擎選型白皮書(24版)DPU部分節選
近年來,大數據行業的蓬勃發展除了來自軟件層的持續迭代與創新,更有賴于計算機硬件環境的持續優化,尤其是在芯片與操作系統國產化的大趨勢下,硬件升級帶來的性能提升、成本降低、并行處理能力優化、存儲與網絡優化、安全風險管控等均為數據引擎的發展提供了階梯式進步的空間。在奇點云2024年版《OLAP數據庫引擎選型白皮書》中,中科馭數聯合奇點云針對Spark+Hive這類大數據計算場景下的主力引擎,測評DPU環境下對比CPU環境下的性能提升效果。特此節選該章節內容,與大家共享。
DPU概述
什么是DPU?為什么要關注DPU?
DPU(Data Processing Unit)是以數據為中心構造的專用處理器,采用軟件定義技術路線支撐基礎設施層資源虛擬化,支持存儲、安全、服務質量管理等基礎設施層服務。提到DPU,2020年英偉達CEO黃仁勛在其GTC大會上的一句話引起業界高度關注:“DPU 將成為未來計算的三大支柱之一,未來的數據中心標配是“ CPU + DPU + GPU”。NVIDIA GTC 2020(英偉達2020年GPU技術大會)上,其CEO黃仁勛的一句話引起了業界高度關注:“DPU 將成為未來計算的三大支柱之一,未來的數據中心標配是CPU + DPU + GPU。”DPU的設計思路,是將“CPU處理效率低下、GPU處理不了”的負載卸載到專用DPU,提升整個計算系統的效率、降低整體系統的總體擁有成本(TCO,Total Cost of Ownership),以實現底層基礎設施的“降本增效”。DPU最直接的作用是作為CPU的卸載引擎,接管網絡虛擬化、硬件資源池化等基礎設施層服務,釋放CPU的算力到上層應用。對比CPU、GPU與DPU:
CPU面向應用程序,負責進行系統管理維持軟硬件生態;
GPU面向科學計算,負責進行規則計算支持數據級并行應用;
DPU面向數據中心基礎設施,負責進行異構計算支撐卸載網絡、存儲、安全業務等降低“Datacenter Tax”。
DPU與CPU最大的區別是,DPU是IO密集型,而GPU是計算密集型。CPU通過間接手段來支持網絡IO,其前端總線帶寬也主要匹配主存(特別是DDR)的帶寬,而非網絡IO的帶寬;DPU的IO帶寬則幾乎可以與網絡帶寬等同,其在支持強IO基礎上具備強算力。DPU的出現并非偶然,而是IT產業發展到一定階段的必然選擇。隨著AI、5G等技術的發展,端、邊、云各處的計算節點暴露在了劇增的數據量下,CPU的性能增長率與數據量增長率出現了“剪刀差”現象。同時,以數據為中心的新興應用對數據的實時處理提出了越來越高的要求。DPU則可以在數據流上就近計算,實現數據處理的低時延和高吞吐,更具靈活性與效率。業內越來越多觀點認為,CPU+DPU的異構計算解決方案將是應對大數據性能瓶頸的新趨勢,DPU也越來越得到數據中心運營商和大數據軟件廠商的關注。因此,本書選擇“Spark+Hive”(大數據計算場景下的主力引擎)為代表,進行了DPU與CPU環境下的性能對比測評,為讀者提供參考。
DPU如何實現加速?有哪些應用場景?
針對Spark+Hive的大數據計算場景測試,本次測評的技術方案中除了引入中科馭數Spark-Race解決方案中最底層的DPU硬件(面向數據中心的專用處理器)、HADOS平臺層(異構軟件開發平臺)外,也包含專門針對Spark的DPU加速層,其最核心的能力就是修改查詢計劃樹。簡單來講就是通過 Spark Plugin的機制(作為Spark插件),把 Spark 查詢計劃攔截并下發給 DPU來執行,跳過原生 Spark 不高效的執行路徑。整體的執行框架仍沿用 Spark 既有實現,包括消費接口、資源和執行調度、查詢計劃優化、上下游集成等,用戶可以直接使用已有的代碼,“無痛”享受DPU帶來的性能提升。
中科馭數介紹,DPU環境對超大業務表或寬表的join聯合查詢場景有突破性的優化效果。例如,對于連續join 4張100萬條數據的維表,在CPU模式下全部time out(3600s),而DPU模式下只需數百秒即可查詢出結果,計算加速比達到8.4倍。在應對涉及復雜SQL多表查詢的挑戰時,Spark-Race 2.0的優勢也尤為突出。因此,本書就“Spark+Hive”引擎(包括高復雜度的數據查詢任務場景),進行了測試和檢驗。
DPU測試方案說明
測評方案概述
DPU測評方案仍沿用引擎測評模型2.0,在相同環境與資源配置前提下,分別在底層硬件資源開啟DPU模型與不開啟DPU模式下,執行本次測評SQL用例三次,采集SQL執行耗時、整機CPU、整機內存消耗等核心數據進行對比實驗。在測試過程中,除底層硬件資源開啟/關閉DPU加速功能外,保持DPU和CPU對比實驗環境的主機與網絡環境一致,大數據計算引擎Hive、Yarn、Spark配置一致,測評工具(即模型2.0)一致,測試表與數據一致。
環境參數說明
機器資源配置:12C/144G/6T 物理機1臺;2C/144G/3T物理機2臺
測試工具、測試數據集、模型維度、指標與引擎測評模型2.0保持一致,具體參數信息詳見附錄。
中科馭數DPU性能測試結果
經過對比測試,在數據計算和處理場景中,DPU環境相較于CPU環境下的查詢性能提升能達到50%-60%,且DPU環境下整體較CPU環境的峰值性能資源有優化,整機CPU峰值降低24%,內存消耗降低50%且波動更平穩。
數據處理場景下,SQL性能提升50%
在數據處理相關的場景,如TPC-DS標準SQL和行業典型場景SQL的測試用例下,DPU模式下占優的用例數明顯高于CPU模式下占優的用例數,且從相同SQL用例的查詢耗時數據來看,DPU模式下的耗時相較于CPU模式有50%-60%的提升。
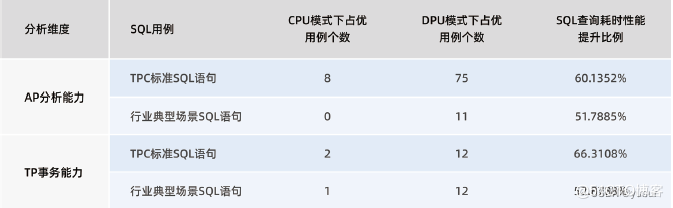
注:性能對比計算公式,針對執行結果數據(CPU-DPU)/CPU
表:DPU模式對比CPU模式下SQL查詢耗時性能結果表
DPU環境下的整機CPU峰值高位較CPU環境降低24%
從測試過程中采集到的整機CPU峰值數據來看,DPU環境下的整機CPU峰值高位比CPU環境下整機CPU峰值高位低24%左右,配合大數據平臺完善的調度體系,可以實現更多的任務并行。
DPU環境較CPU環境可以降低50%的內存配置,內存消耗走勢更平穩
測試過程中采集到的內存消耗數據來看,DPU環境在測試執行過程中內存消耗走勢更平穩,且整體峰值相較于CPU環境更低。從性能優化的角度來看,DPU環境相較于CPU環境降低50%左右的內存配置,即本次實驗DPU環境內存可從128G降為64G。
附錄:測評環境與數據詳細說明
以下針對本次測評的測試環境、資源參數、測試數據集進行說明:
| 測試環境 | 操作系統:CentOS 7.9芯片:Intel Cascade Lake 3.0 16C/64G |
| 機器資源配置 | 16C/64G/3T物理機2臺16C/64G/6T物理機1臺 |
| 數據規模 | 總數據量2.8T,213億行數據 |
| 數據類型 |
業內標準測試數據:400G ? TPC-DS:300G。數據總量22億5873萬,最大表數據量8億6400萬 ? PC-H:100G。數據總量約8億6604萬,最大表數據6億條 各行業構造數據:合計138億5111萬 ? 泛零售:最大表數據10億條,場景合集數據條數:24億8284萬 ? 金融:最大表數據10億條,26億300萬條 ? 制造:最大表數據10億條,75億300萬條 ? 政企:最大表數據3億條,7億6172萬條 ? 地產:最大表數據5億條,5億100萬 標準業務表構造數據:合計43億2440萬 ? 業務表:最大表數據20億條 ? 寬表:3億條,130+維度 |
審核編輯 黃宇
-
數據庫
+關注
關注
7文章
3712瀏覽量
64030 -
DPU
+關注
關注
0文章
344瀏覽量
24047 -
OLAP
+關注
關注
0文章
24瀏覽量
10072 -
SPARK
+關注
關注
1文章
105瀏覽量
19823 -
hive
+關注
關注
0文章
11瀏覽量
3821
發布評論請先 登錄
相關推薦
《數據處理器:DPU編程入門》讀書筆記
《數據處理器:DPU編程入門》DPU計算入門書籍測評
IaaS+on+DPU(IoD)+下一代高性能算力底座技術白皮書
jAVA語言環境白皮書
最新的智能電網的白皮書資料
業內首部白皮書《DPU技術白皮書》——中科院計算所主編
中科馭數等單位牽頭發布行業首部DPU評測方法技術白皮書

芯啟源參與撰寫的中國移動DPU技術白皮書正式發布
打破對DPU的誤解:中移動重磅白皮書解讀

DPU在通信云里的重要角色:中國聯通白皮書解讀

中國DPU行業白皮書
中科馭數助力奇點云《2024 OLAP數據庫引擎選型白皮書》發布






 工商網監
工商網監
評論