 SoC芯片設計系列-ARM CPU子系統組件介紹
SoC芯片設計系列-ARM CPU子系統組件介紹
1、概述
在ARM架構的CPU子系統中,組件設計旨在高效地整合了多種功能模塊,以支持處理器核心的運行、內存管理、中斷處理、數據交換以及與外部設備的交互等。以下是ARM CPU子系統中的一些關鍵組件:
1. CPU Cores (處理器核心): 包括多個處理單元,如高性能的Cortex-A系列核心或高效能效核心,負責執行指令。
2. GIC (Generic Interrupt Controller): 管理中斷請求,確保系統對事件做出快速響應,支持多級中斷處理和虛擬化。
3. DSU (DynamIQ Shared Unit): 在具備DynamIQ技術的SoC中,DSU管理共享資源,如L3緩存,優化多核通信和數據一致性。
4. Cache System: 包括L1 Cache(靠近核心的高速緩存,分指令和數據緩存),L2 Cache(更大,有時是多核共享)。
5. Memory Controller: 控制內存訪問,如DDR控制器,管理與主存交互。6. AMBA總線: 如AMBA總線架構,提供系統內部組件間的通信,包括常見的AXI(Advanced eXtensible Interface)協議。
7. System Control Block: 負理系統復位、時鐘、電源管理等初始化配置。
8. Security Features: 如TrustZone、加密引擎,確保系統安全。
9. Debugging and Trace: CoreSight、JTAGC等,方便調試和性能分析。
10. Connectivity and Peripherals: 包括USB、Ethernet控制器、顯示接口、I2C、SPI等,以支持與外設別交互。
這些組件共同構成了復雜且高度集成的CPU子系統,支持現代計算平臺的高效、低功耗、安全性以及可擴展性需求。
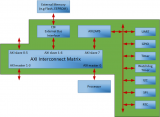
以下是一張比較早期的經典的bit-LITTLE的架構圖。
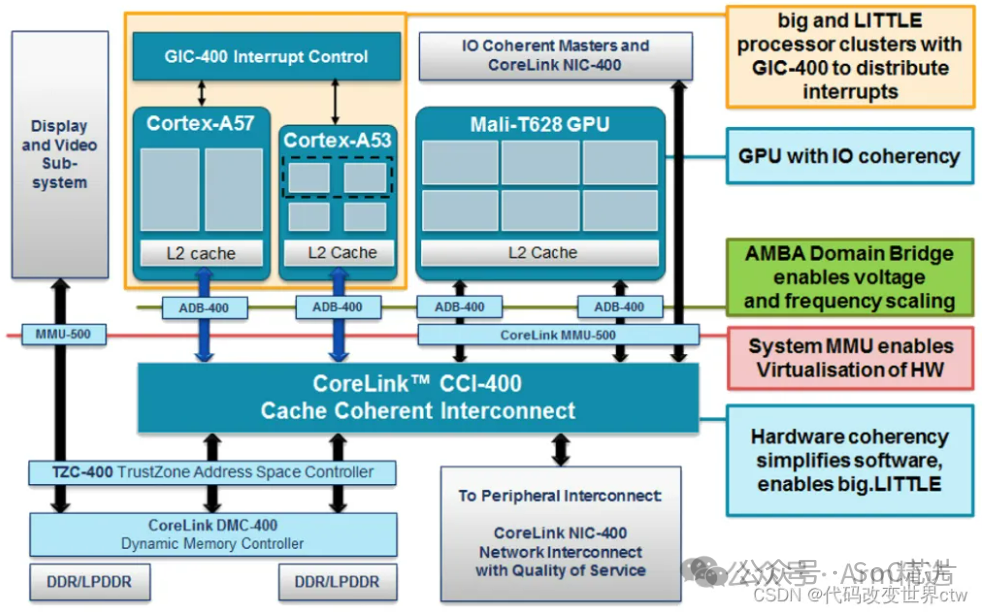
2、CPU Cores
2.1終端芯片處理器
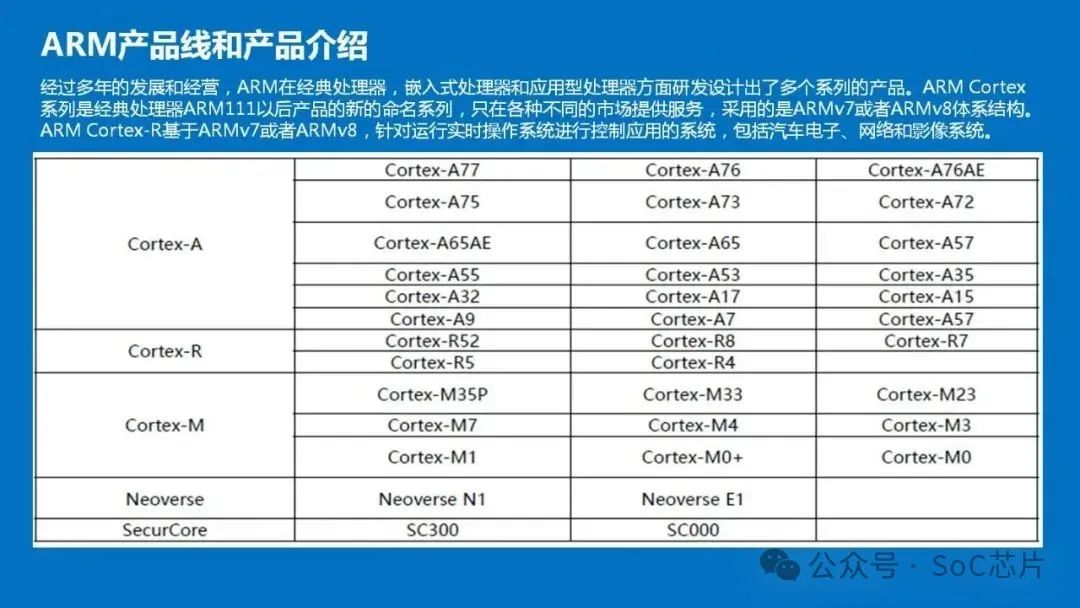
Arm架構是當今世界上最受歡迎的處理器架構之一,經過多年的發展和經營,ARM在經典處理器,嵌入式處理器和應用型處理器方面研發設計出了多個系列的產品。ARM Cortex系列是經典處理器ARM11以后產品的新的命名系列,只在各種不同的市場提供服務,采用的是ARMv7或者ARMv8體系結構,并分為三個系列,分別是Cortex-A,Cortex-R,Cortex-M。
 ? ?
? ?

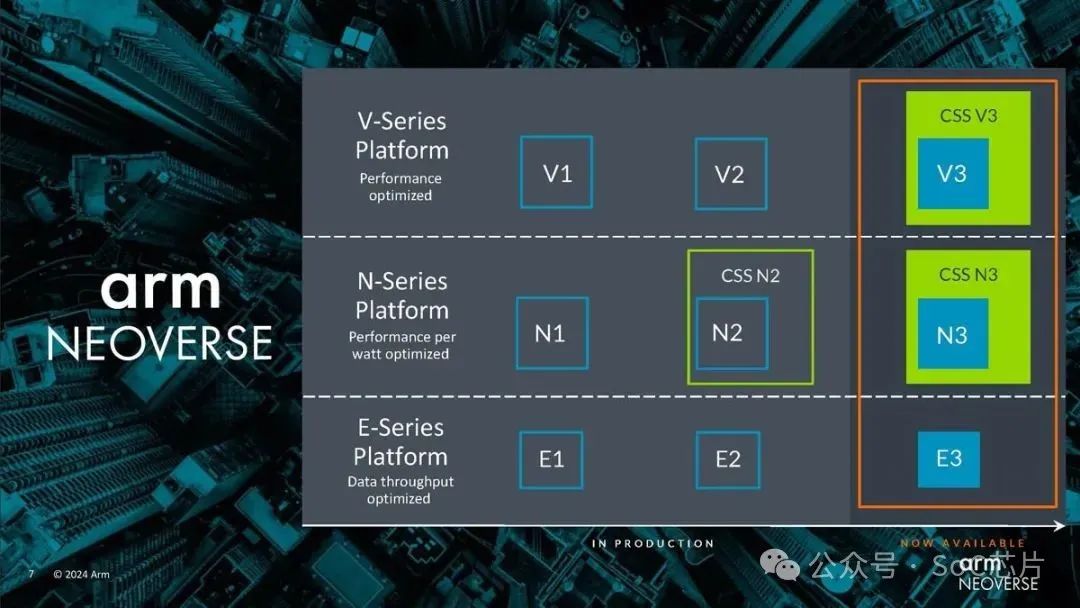
2.2服務器芯片處理器
2024年2月,Arm 推出了新的 Neoverse N3 和 V3 內核以及針對這兩個內核的 CSS 產品。正如人們所期望的那樣,Neoverse N3 更新了 N2,Neoverse V3 更新了 V2。CSS 是 Arm 的計算子系統,可提供更多預封裝 IP,幫助公司更快地開發芯片或小芯片。
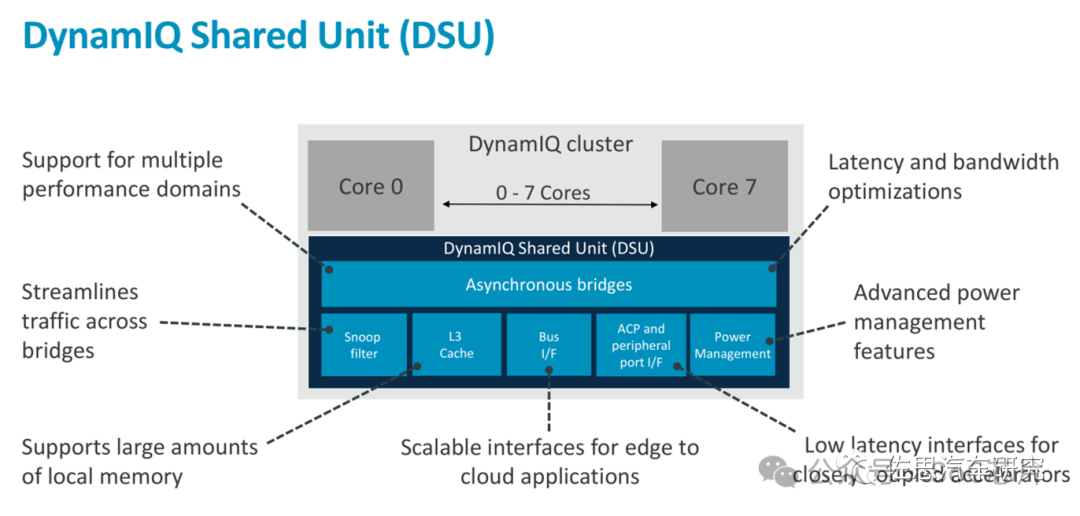
3、DynamIQ Shared Unit (DSU)
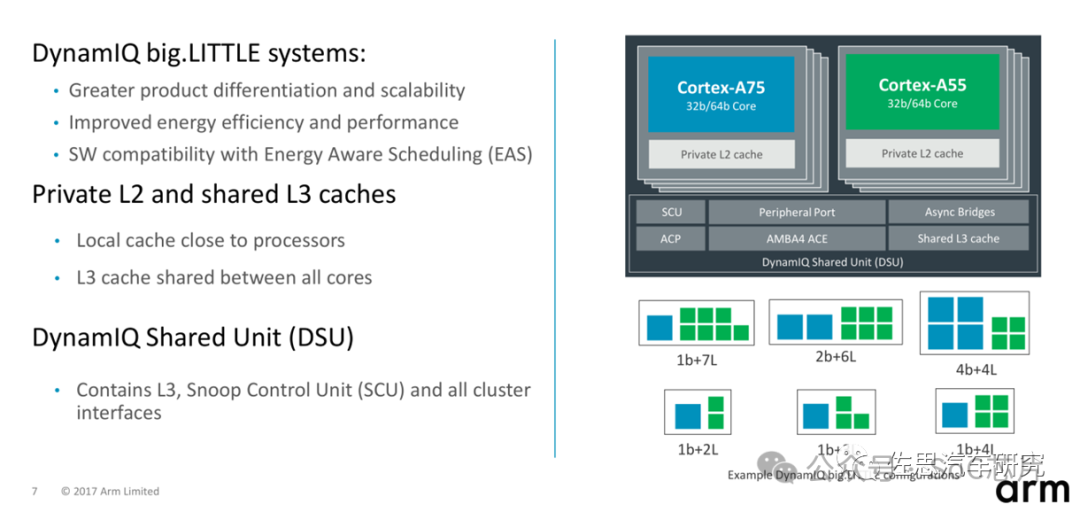
DynamIQ Shared Unit (DSU) 是ARM Cortex-A 系列列處理器中引入的一個關鍵組件,尤其是那些采用DynamIQ技術的高端多核設計中,如Cortex-A57、Cortex-A53、Cortex-A72、Cortex-A73等。DSU在SoC(System-on-Chip)架構中扮演著至關重要的角色,其主要功能和特點包括:
1. L3緩存控制器:DSU集成L3緩存控制器,為整個CPU集群提供共享的、大容量的高速緩存,以減少對更慢速主存的依賴,提高數據交換效率。
2. 一致性管理:在多核處理器系統中,DSU負責維護緩存一致性,確保所有核心看到的數據是一致的,通過實施緩存一致性協議(如MESI、MOESI)來協調數據更新。
3. 數據共享與分配:DSU優化多核間的數據分配和共享,通過有效的緩存分配策略和傳輸機制,減少數據復制,提高數據訪問效率。
4. 能效管理:作為SoC的一部分,DSU還可能集成能效管理機制,支持動態調整頻率和電源狀態,以平衡性能與能耗。
5. 系統互聯:DSU通過高帶寬、低延遲的內部總線與CPU核心、外設別、內存控制器等SoC組件相連,確保數據快速流動。
簡言之,DynamIQ Shared Unit是DynamIQ架構中的一個核心組件,它通過提供共享緩存、緩存一致性管理、數據高效共享和能效優化,支持高性能、多核處理器系統中復雜數據處理和高效協作。
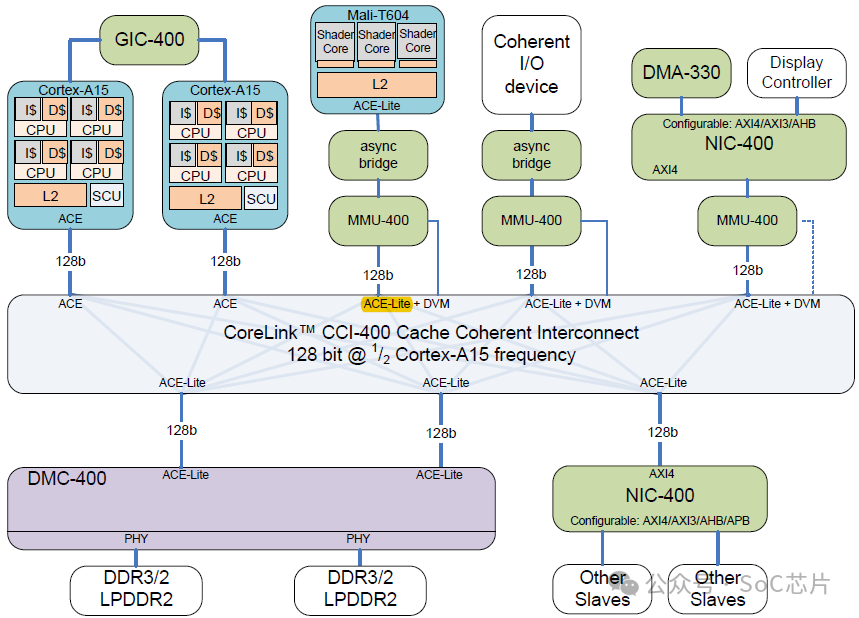
4、Snoop Control Unit(SCU)
Snoop Control Unit(SCU)是多處理器系統中的一個關鍵組件,特別是在包含緩存一致性設計中,如對稱多處理機群集(SMP)或片上系統(SoC)中。其主要作用是維護緩存一致性,確保所有處理器核心對共享緩存的內容有統一的視圖景,從而保證數據的一致性和正確性。SCU的工作機制通常包括以下方面:
1. 監聽(Snooping): SCU監聽所有處理器核心對共享緩存的訪問請求,包括讀取和寫入操作。當一個核心試圖修改緩存中的數據時,SCU介入以確保其他核心對該數據的緩存副本不會變得陳舊。
2. 緩存更新: 如果一個核心請求的數據在另一個核心的緩存中是臟(已修改但未回寫回主存),SCU會促使持有該臟數據的核心將其寫回到共享緩存或主存,然后更新請求核心的緩存,保證數據最新。
3. 一致性協議: SCU遵循一定的緩存一致性協議,如MESI(Modified, Exclusive, Shared, Invalid)、MOESI(Modified, Owner, Exclusive, Shared, Invalid)或其他協議,來決定如何響應緩存訪問并維護一致性。
4. 廣播與仲裁: 在多核系統中,SCU可能需要廣播某些緩存操作,比如寫操作,給所有核心,或仲裁緩存訪問沖突,決定哪個核心優先級次序。
5. 目錄管理: 在大型系統中,SCU可能配合緩存目錄使用,目錄存儲哪個緩存行位于哪些地方,其狀態,減少廣播范圍和提高效率。
綜上所述,Snoop Control Unit是多處理器緩存一致性機制中的重要一環,通過監聽和協調處理器間的緩存操作,確保數據的一致性,從而支持高效、可靠并行計算。
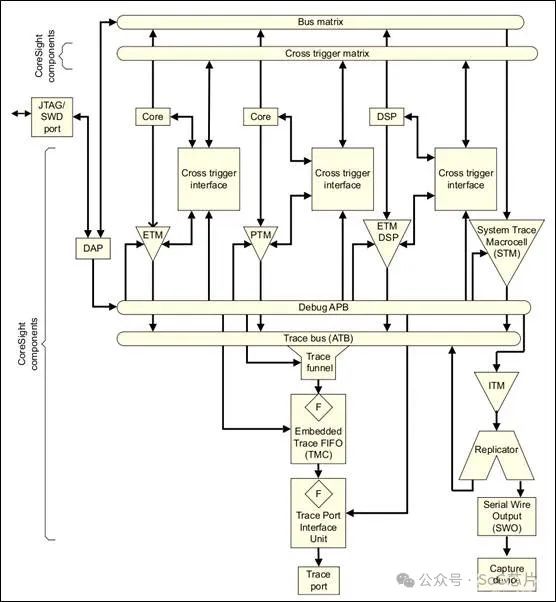
5、Coresight system
CoreSight架構是ARM公司為復雜系統級芯片(SoC)設計的調試和追蹤解決方案,它提供了一個高度集成且可擴展的框架,用于系統級的調試、性能分析和優化。CoreSight架構旨在支持多核和多處理器環境,尤其是在面對現代嵌入式系統和高性能計算領域,其功能強大且靈活的特性能夠顯著提升開發效率和系統性能。以下是CoreSight架構的一些關鍵組成部分和功能:
1. 調試和追蹤IP模塊:?包括嵌入式追蹤宏單元(ETM, Embedded Trace Macrocell, ETM)、系統追蹤宏單元(STM, System Trace Macrocell, STM)、數據觀看點單元(Data Watchpoint Unit, DWT)等,這些模塊負責捕獲程序執行時的指令流、數據訪問、系統事件、性能計數等信息。
2. 跨觸發接口 - CTI(Cross Trigger Interface, CTI):允許不同調試和追蹤組件之間同步事件,支持復雜的系統級調試和性能分析。
3. 調試訪問點 - DAP(Debug Access Port, DAP)和DP(Debug Port):提供調試接口,允許調試器通過串行線調試協議(如JTAG, SWD)訪問系統。
4. 電源管理:支持系統級的動態電壓和頻率調整(DVFS),優化能效。
 ? ?
? ?
CoreSight架構的組件可按需組合,根據SoC的具體需求定制化集成,以達到最佳的調試、性能監控和系統優化效果,支持從簡單的單核微控制器到復雜的多核服務器芯片的廣泛應用。
6、System Memory Management Unit(SMMU)
ARM SMMU指的是ARM架構中的System Memory Management Unit,它是一種系統級的內存管理單元,主要負責地址轉換和內存訪問權限控制。在ARM架構中,SMMU主要用于處理非CPU核心的內存管理,尤其是外設別和硬件加速器的內存訪問。與CPU核心中的MMU(管理虛擬地址到物理地址轉換)類似,SMMU提供了對系統其他組件的內存訪問控制,確保安全和高效的數據交互。特別地,ARM SMMU在不同場景下的應用和功能包括:
1. 外設別DMA訪問隔離:SMMU通過配置映射表管理外設別DMA請求,確保其只能訪問被授權的內存區域,防止非法或越界訪問,增強了系統安全性。
2. 硬件加速器訪問控制:對于硬件加速器(如GPU、網絡加速器、加密加速器等),SMMU確保它們僅訪問指定的內存區域,避免對系統關鍵數據的干擾,同時優化訪問效率。
3. 虛擬化支持:在虛擬化環境中,SMMU為每個虛擬機提供獨立的地址空間映射表,實現內存的隔離,保障虛擬機間不能互相干擾,提升了虛擬化平臺的安全性和穩定性。
4. 中斷處理:SMMU在某些實現中,如GICv3,可能間接參與中斷路由和管理,特別是與中斷的虛擬化處理,確保中斷能被正確、高效地路由至目標處理器。
5. 內存屬性管理:SMMU還可以控制內存訪問屬性,如是否緩存、共享與否、訪問權限等,進一步細化內存管理,提升系統整體性能和安全性。組件與實現:?Stream Table:根表基地址寄存于寄存器中,是SMMU查找中斷或DMA請求映射的起點。?Context Descriptor:描述符定義了第一階段映射表的基地址,與第二階段配置相關聯。?Translation Tables:用于實際的地址轉換,依據不同階段的映射表結構,完成從虛擬到物理地址的映射。
綜上,ARM SMMU是系統中一個關鍵的組件,它對內存訪問的高效、安全控制和虛擬化支持至關重要,特別是在高性能、多核和異構計算系統中。
6.1. 什么是SMMU?
SMMU(system mmu),是I/O device與總線之間的地址轉換橋。
它在系統的位置如下圖:
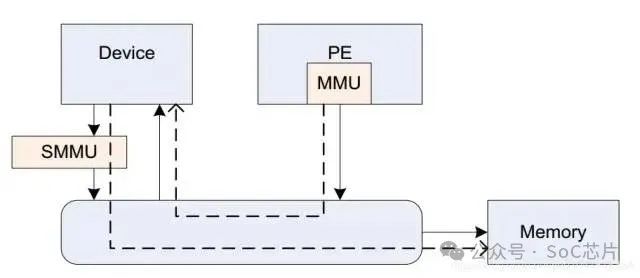
它與mmu的功能類似,可以實現地址轉換,內存屬性轉換,權限檢查等功能。
6.2. 為什么需要SMMU?
了解SMMU出現的背景,需要知道系統中的兩個概念:DMA和虛擬化。
DMA:((Direct Memory Access),直接內存存取, 是一種外部設備不通過CPU而直接與系統內存交換數據的接口技術 。外設可以通過DMA,將數據批量傳輸到內存,然后再發送一個中斷通知CPU取,其傳輸過程并不經過CPU, 減輕了CPU的負擔。但由于DMA不能像CPU一樣通過MMU操作虛擬地址,所以DMA需要連續的物理地址。
虛擬化:在虛擬化場景, 所有的VM都運行在中間層hypervisor上,每一個VM獨立運行自己的OS(guest OS),Hypervisor完成硬件資源的共享, 隔離和切換。
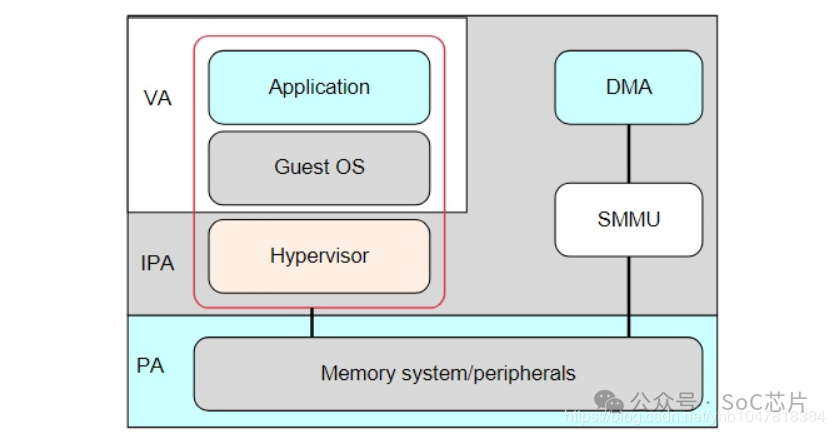
但對于Hypervisor + GuestOS的虛擬化系統來說, guest VM使用的物理地址是GPA, 看到的內存并非實際的物理地址(也就是HPA),因此Guest OS無法正常的將連續的物理地址分給硬件。
因此,為了支持I/O透傳機制中的DMA設備傳輸,而引入了IOMMU技術(ARM稱作SMMU)。
總而言之,SMMU可以為ARM架構下實現虛擬化擴展提供支持。它可以和MMU一樣,提供stage1轉換(VA->PA), 或者stage2轉換(IPA->PA),或者stage1 + stage2轉換(VA->IPA->PA)的靈活配置。
*[VA:虛擬地址;IPA: 中間物理地址;PA:物理地址]
6.3. SMMU常用概念
術語 概念
StreamID 一個平臺上可以有多個SMMU設備,每個SMMU設備下面可能連接著多個Endpoint, 多個設備互相之間可能不會復用同一個頁表,需要加以區分,SMMU用StreamID來做這個區分( SubstreamID的概念和PCIe PASID是等效的)
STE Stream Table Entry, STE里面包含一個指向stage2地址翻譯表的指針,并且同時還包含一個指向CD(Context Descriptor)的指針.
CD Context Descriptor, 是一個特定格式的數據結構,包含了指向stage1地址翻譯表的基地址指針
4. SMMU數據結構查找
SMMU翻譯過程需要使用多種數據結構,如STE, CD,PTW等。
4.1 SID查找STE
Stream Table是存放在內存中的一張表,在SMMU驅動初始化時由驅動程序創建好。
Stream table有兩種格式,一種是Linear Stream Table, 一種是2-level Stream Table.
1. Linear Stream Table
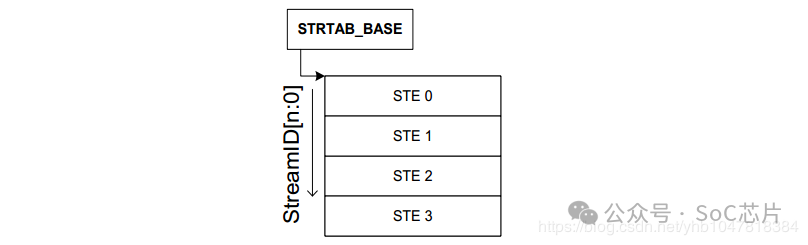
Linear Stream Table是將整個stream table在內存中線性展開成一個數組, 用Stream Id作為索引進行查找.
Linear Stream Table 實現簡單,只需要一次索引,速度快;但是平臺上外設較少時,浪費連續的內存空間。
2. 2-level Stream Table
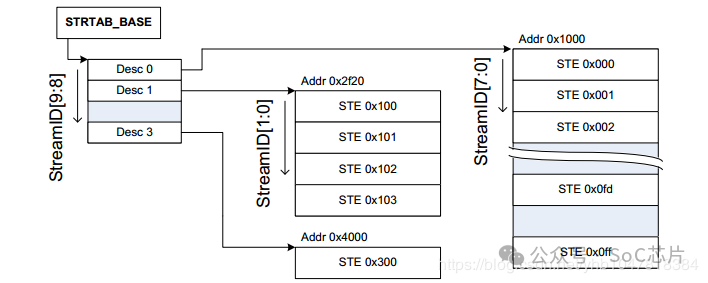
2-level Stream Table, 顧名思義,就是包含2級table, 第一級table, 即STD,包含了指向二級STE的基地址STD。第二級STE是Linear stream Table. 2-level Stream Table的優點是更加節省內存。
SMMU根據寄存器配置的STRTAB_BASE地址找到STE, STRTAB_BASE定義了STE的基地值, Stream id定義了STE的偏移。如果使用linear 查找, 通過STRTAB_BASE + sid * 64(一個STE的大小為64B)找到STE;若使用2-level查找, 則先通過sid的高位找到L1_STD(STRTAB_BASE + sid[9:8] * 8, 一個L1_STD的大小為8B), L1_STD定義了下一級查找的基地址,然后通過sid 找到具體的STE(l2ptr + sid[7:0] * 64).
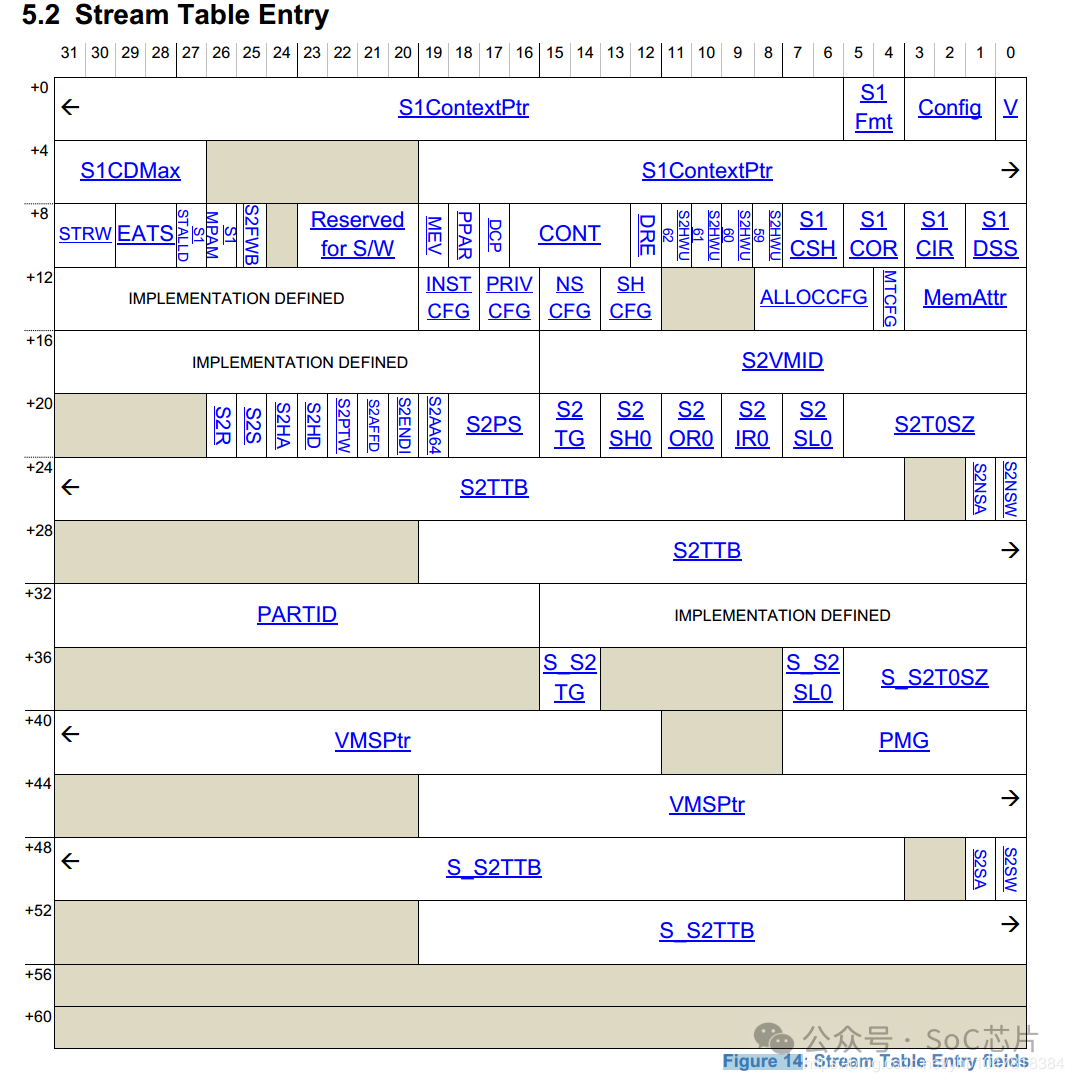
最終找到的STE如下所示,表中的信息包含屬性相關信息, 翻譯模式信息(是否 stream bypass, 若否,選擇stage1, stage2或者stage1 + stage2翻譯模式)。
.2 SSID查找CD
CD包含了指向stage1地址翻譯表的基地址指針.
如下圖所示, STE指明了CD數據結構在DDR中的基地址S1ContextPTR, SSID(substream id)指明了CD數據結構的偏移,如果SMMU選擇進行linear, 則使用S1ContextPTR + 64 * ssid 找到CD。如果SMMU選擇2-level, 則使用ssid進行二級查找獲得CD(與上節STE的方式一致)。
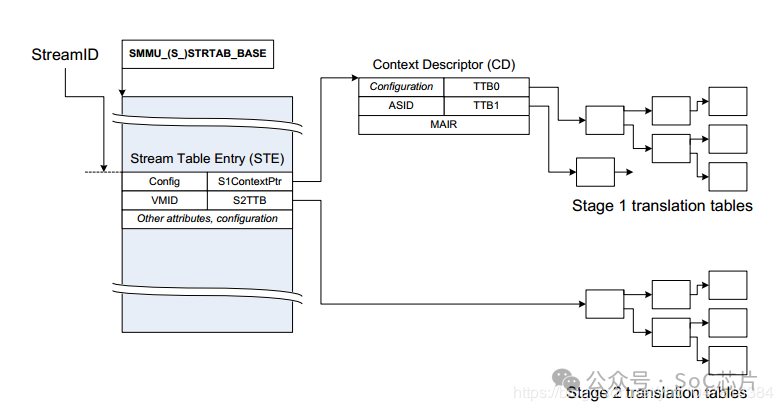
最終找到的CD如下所示:
 ? ?
? ?
表中信息包含memory屬性,翻譯控制信息,異常控制信息以及Page table walk(PTW)的起始地址TTB0, TTB1, 找到TTBx后,就可以PTW了。
5. SMMU地址轉換
5.1 單stage的地址轉換:
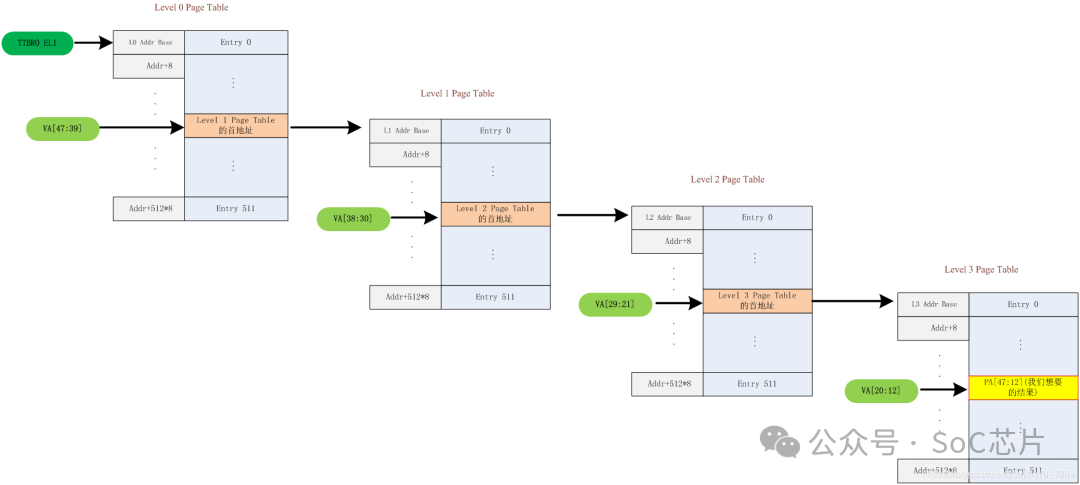
TTB 和 VA[47:39]組成獲取Level0頁表的地址PA;
Level0頁表中的next-level table address 和 VA[38:30]組成獲取Level1的頁表地址PA;
Level1頁表中的next-level table address 和 VA[29:21]組成獲取Level2的頁表地址PA;
Level2頁表中的next-level table address 和 VA[20:12]組成獲取Leve3的頁表地址PA;
level3頁表中的output address和va[12:0]組成獲取組后的鉆換地址
在stage1地址翻譯階段:硬件先通過StreamID索引到STE,然后用SubstreamID索引到CD, CD里面包含了stage1地址翻譯(把進程的GVA/IOVA翻譯成IPA)過程中需要的頁表基地址信息、per-stream的配置信息以及ASID。在stage1翻譯的過程中,多個CD對應著多個stage1的地址翻譯,通過Substream去確定對應的stage1地址翻譯頁表。所以,Stage1地址翻譯其實是一個(RequestID, PASID) => GPA的映射查找過程。
5.2 stage1+stage2的地址轉換:
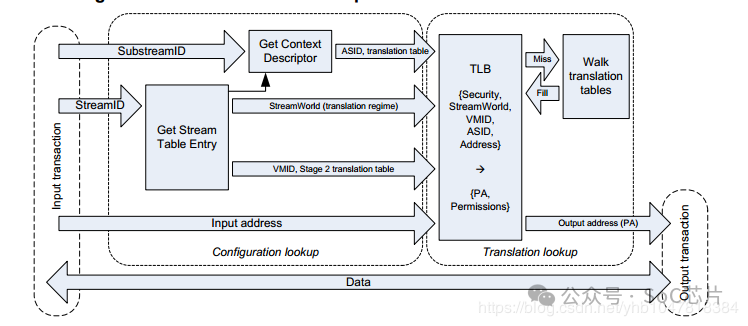
在使能SMMU兩階段地址翻譯的情況下,stage1負責將設備DMA請求發出的VA翻譯為IPA并作為stage2的輸入, stage2則利用stage1輸出的IPA再次進行翻譯得到PA,從而DMA請求正確地訪問到Guest的要操作的地址空間上。
在stage2地址翻譯階段:STE里面包含了stage2地址翻譯的頁表基地址(IPA->HPA)和VMID信息。如果多個設備被直通給同一個虛擬機,那么意味著他們共享同一個stage2地址翻譯頁表。
在兩階段地址翻譯場景下, 地址轉換流程步驟:
1.Guest驅動發起DMA請求,這個DMA請求包含VA + SID前綴
2.DMA請求到達SMMU,SMMU提取DMA請求中的SID就知道這個請求是哪個設備發來的,然后去StreamTable索引對應的STE
3.從對應的STE表中查找到對應的CD,然后用ssid到CD中進行索引找到對應的S1 Page Table
4.IOMMU進行S1 Page Table Walk,將VA翻譯成IPA并作為S2的輸入
5.IOMMU執行S2 Page Table Walk,將IPA翻譯成PA,地址轉化結束。
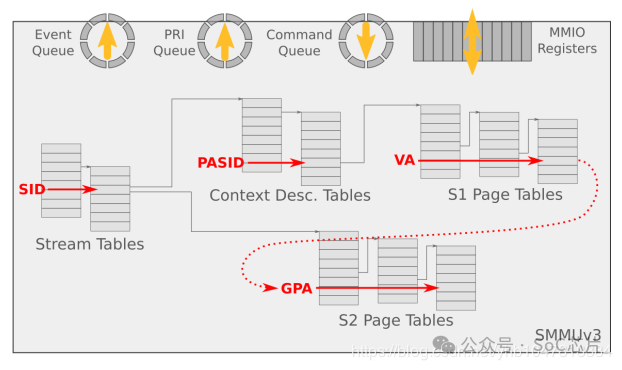
6. SMMU command queue 與 event queue
系統軟件通過Command Queue和Event Queue來和SMMU打交道,這2個Queue都是循環隊列。
Command queue用于軟件與SMMU的硬件交互,軟件寫命令到command queue, SMMU從command queue中 地區命令處理。
Event Queue用于SMMU發生軟件配置錯誤的狀態信息記錄,SMMU將配置錯誤信息寫到Event queue中,軟件通過讀取Event queue獲得配置錯誤信息并進行配置錯誤處理。
 ? ?
? ?
7、 GIC Controller
6.1 gic的版本號
§gic400,支持gicv2架構版本。
§gic500,支持gicv3架構版本。
§gic600,支持gicv3架構版本
§gic700, 支持gicv4.1架構版本
6.2 gic中斷類型
GIC 分為不同類型的中斷源:
§Shared Peripheral Interrupt (SPI) : 共享中斷
§Private Peripheral Interrupt (PPI) : 私有中斷
§Software Generated Interrupt (SGI) : 軟件產生中斷
§Locality-specific Peripheral Interrupt (LPI)
每個中斷源都由一個 ID 號標識,稱為 INTID。 前面列表中介紹的中斷類型就是根據 INTID 的范圍定義的:
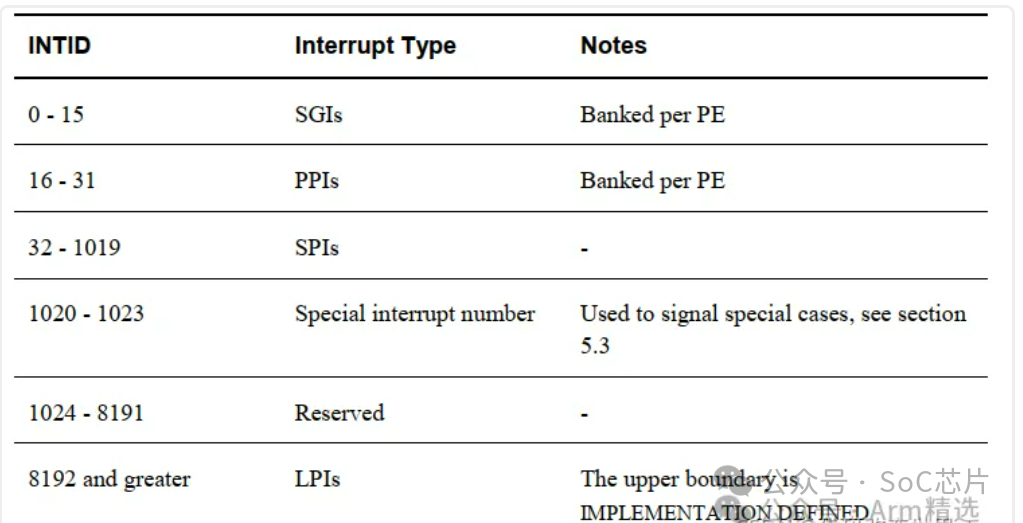
6.3 LPI介紹
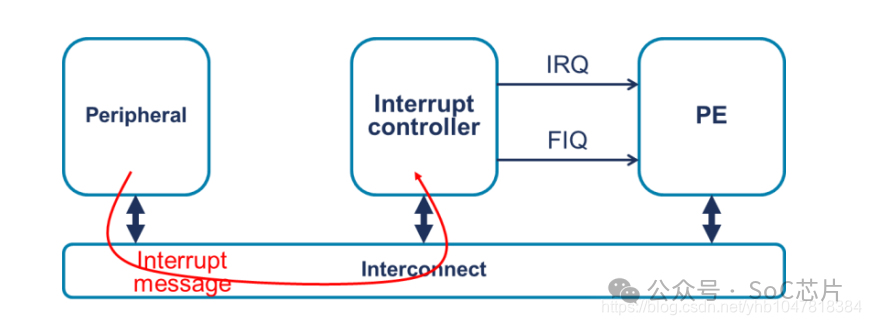
Locality Specific Interrupts(LPI),這是一個與GICv3及之后版本相關的概念。LPI中斷是GIC架構中用來優化中斷管理的一部分,特別是針對PCI Express (PCIe) 設備的中斷處理,它與傳統的共享中斷線方法不同,提供了更高效的中斷處理機制。以下是LPI的主要特點和工作原理:
1. 基于消息的中斷:LPI中斷不同于傳統的硬件中斷線機制,它基于消息傳遞,即中斷信號通過寫入內存中的特定地址(中斷向量寄存器)來觸發,而非通過物理線路。
2. 中斷優化:LPI機制設計用于優化了中斷處理,減少中斷延遲和提高吞吐量,特別是在多核和虛擬化環境中。它避免了物理中斷線的限制,簡化了系統設計和擴展性。
3. 中斷狀態表:LPI中斷的狀態信息存儲在內存中,GIC通過配置的中斷狀態表(Pending狀態表)來跟蹤這些中斷,這允許快速查詢和處理狀態,減少了硬件開銷耗。
4. GICv3及以后支持:GICv3開始引入了對LPI中斷的直接注入支持,包括了中斷狀態表和中斷配置寄存取址等,而GICv4在此基礎上進一步優化,如支持虛擬中斷直接注入到虛擬機。
5. 中斷路由與優先級:LPI中斷也涉及到中斷的路由和優先級管理,GIC的Distributor組件會根據中斷的屬性和系統策略,決定如何路由到適當的CPU核心,以及處理的優先級。
綜上所述,LPI在GIC框架下是針對高性能和高效中斷處理的一個設計,特別是在現代的多核處理器和虛擬化系統中,它利用內存消息機制替代傳統的硬件中斷線,優化中斷管理,提升了系統響應速度和效率。
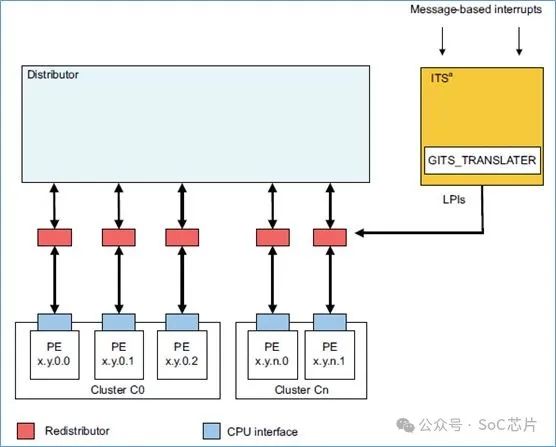
LPI,和SPI,PPI,SGI有些差別,LPI的中斷的配置,以及中斷的狀態,是保存在memory的表中,而不是保存在gic的寄存器中的。
·GICR_PROPBASER:保存LPI中斷配置表的基地址
·GICR_PENDBASER: 保存LPI中斷狀態表的基地址
這里,就涉及到兩個表:
6.3.1 LPI中斷配置表
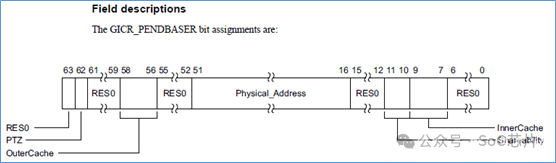
該表,保存在memory中。基地址,由GICR_PROPBASER寄存器決定。

該寄存器描述如下:

其中的Physical_Address字段,指定了LPI中斷配置表的基地址。
對于LPI配置表,每個LPI中斷,占用1個字節,指定了該中斷的使能和中斷優先級。

當外部發送LPI中斷給redistributor,redistributor首先要查該表,也就是要訪問memory來獲取LPI中斷的配置。為了加速這過程,redistributor中可以配置cache,用來緩存LPI中斷的配置信息。
因為有了cache,所以LPI中斷的配置信息,就有了2份拷貝,一份在memory中,一份在redistributor的cache中。如果軟件修改了memory中的LPI中斷的配置信息,需要將redistributor中的cache信息給無效掉。
6.3.2 LPI中斷狀態表
該表,處于memory中,保存了LPI中斷的狀態,是否pending狀態。
LPI中斷的狀態,不是保存在寄存器中,而是保存在memory中的pending表中。該狀態表,由redistributor來進行更改。而該table的基地址,是由軟件來設置的。
軟件通過設置 GICR_PENDBASER 寄存器來設置。

該寄存器,設置LPI狀態表的基地址,該狀態表的memory的屬性,如shareability,cache屬性等。
每個LPI中斷,占用一個bit空間
·0: 該LPI中斷,沒有處于pending狀態
·1: 該LPI中斷,處于pending狀態
該狀態表,由redistributor來設置。軟件如果修改該表,會引發unpredictable行為。
6.4 LPI的實現方式
為了實現LPI,gicv3定義了以下兩種方法來實現:
·使用ITS,將外設發送到eventID,轉換成LPI 中斷號
·forwarding方式,直接訪問redistributor的寄存器GICR_SERLPIR,直接發送LPI中斷
6.4.1、forwarding方式
這種方式,比較簡單,主要由下面幾個寄存器來實現:
·GICR_SERLPIR
·GICR_CLRLPIR
·GICR_INVLPIR
·GICR_INVALLR
·GICR_SYNCR
其gic框圖如下所示:
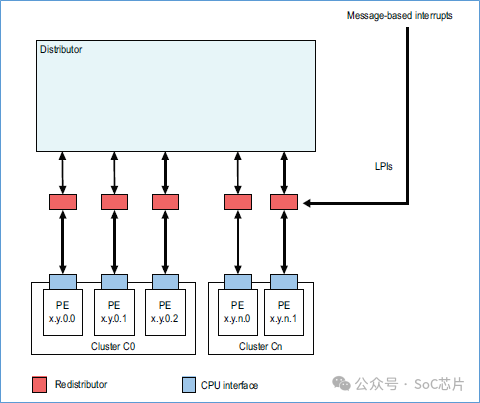
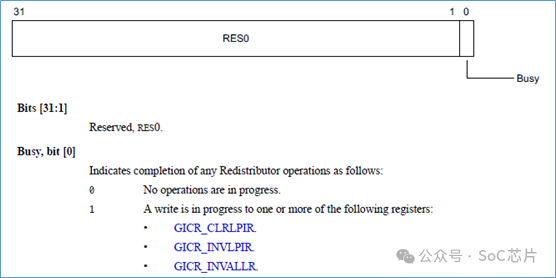
GICR_SERLPIR,將指定的LPI中斷,設置為pending狀態。

GICR_INVLPIR,將指定的LPI中斷,清除pending狀態。寄存器內容和GICR_SERLPIR一致。
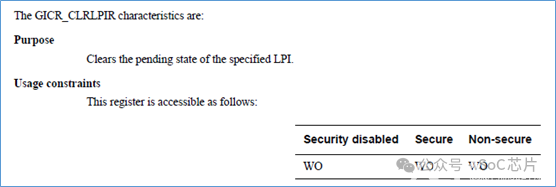
GICR_INVLPIR,將緩存中,指定LPI的緩存給無效掉,使GIC重新從memory中載入LPI的配置。
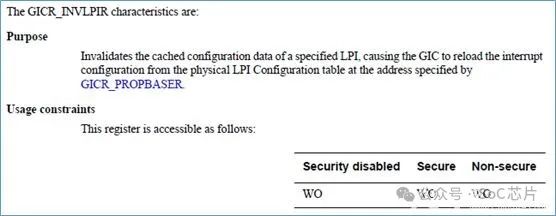
GICR_INVALLR,將緩存中,所有LPI的緩存給無效掉,使GIC重新從memory中,載入LPI中斷的配置。
GICR_SYNCR,對redistributor的操作是否完成。

寄存器,只有第0bit是有效的。如果為0,表示當前對redistributor的操作是完成的,如果為1,那么是沒有完成的。
6.4.2、使用ITS方式
理解了forwarding方式,那么理解ITS方式,就要容易了。forwarding方式,是直接得到了LPI的中斷號。
但是對于ITS方式,是不知道LPI的中斷號的。需要將外設發送的DeviceID,eventID,通過一系列查表,得到LPI的中斷號以及該中斷對應的target redistributor,然后將LPI中斷,發送給對應的redistributor。
下圖是帶有ITS的gic框圖:
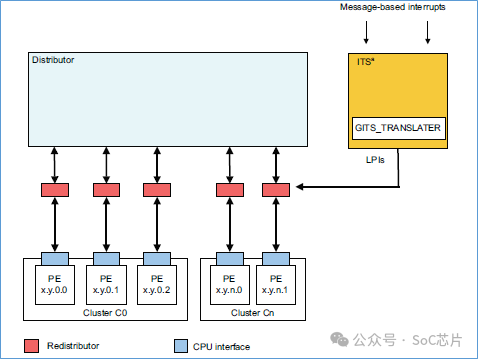
外設,通過寫GITS_TRANSLATER寄存器,發起LPI中斷。寫操作,給ITS提供2個信息:
·EventID:值保存在GITS_TRANSLATER寄存器中,表示外設發送中斷的事件類型
·DeviceID:表示哪一個外設發起LPI中斷。該值的傳遞,是實現自定義,例如,可以使用AXI的user信號來傳遞。
ITS將DeviceID和eventID,通過一系列查表,得到LPI中斷號,再使用LPI中斷號查表,得到該中斷的目標cpu。
ITS將LPI中斷號,LPI中斷對應的目標cpu,發送給對應的redistributor。redistributor再將該中斷信息,發送給CPU。
6.5 ITS組件
ITS(Interrupt Translation Service)是GICv3及之后版本中引入的一項高級特性,特別針對PCI Express (PCIe) 系統的中斷處理進行了優化。以下是GIC的ITS的主要工作原理和功能:
1. 中斷轉換與路由優化:ITS的主要職責是將PCIe的Message Signaled Interrupts (MSI) 轉換為系統內部中斷ID,進而路由到適當的CPU核心。這一轉換過程優化了中斷的分配,尤其是對于多核處理器和虛擬化環境中的中斷路由。
2. 高效中斷處理:通過硬件加速中斷的翻譯和路由,ITS降低了中斷處理延遲,提高了系統響應速度,特別是在處理大量中斷的場景下,如數據中心、高性能計算和網絡設備。
3. 中斷虛擬化支持:在虛擬化環境中,ITS可以更高效地重定向中斷到正確的虛擬機,支持中斷隔離和虛擬中斷的靈活管理,增強虛擬化平臺的性能和可擴展性。
4. 中斷表管理:ITS維護一個中斷轉換表,存儲了中斷源到中斷ID的映射關系,以及相關的優先級和路由信息。這個表支持動態更新,允許系統根據需要調整中斷配置。
5. 硬件輔助的中斷分配:GIC的Distributor組件與ITS協同工作,確保中斷被高效地分配給CPU Interface,而CPU Interface負責中斷的發送EOI(End of Interrupt)信號,告知中斷已處理完畢,完成循環。
GIC的ITS特性是現代中斷處理技術的一個重要進展,它提高了中斷處理的效率、靈活性和可擴展性,特別是在復雜的多核處理器和虛擬化系統中,確保了中斷處理的高效和及時響應。
6.5.1、ITS處理流程
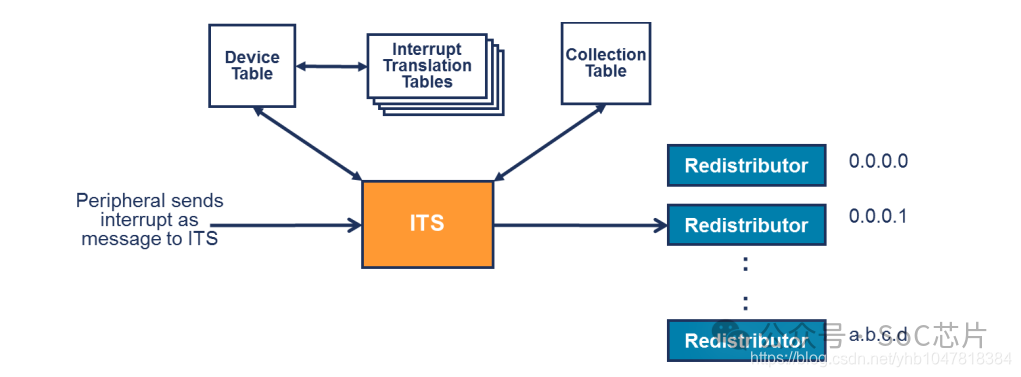
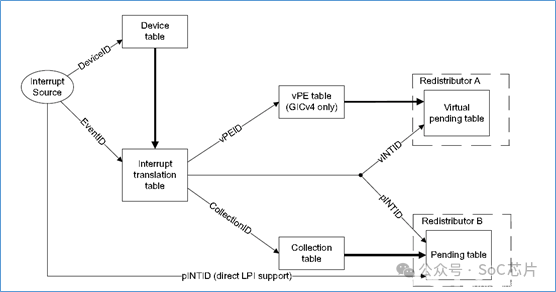
ITS使用三類表格,實現LPI的轉換和映射:
·device table: 映射deviceID到中斷轉換表
·interrupt translation table:映射EventID到INTID。以及INTID屬于的collection組
·collection table:映射collection到redistributor
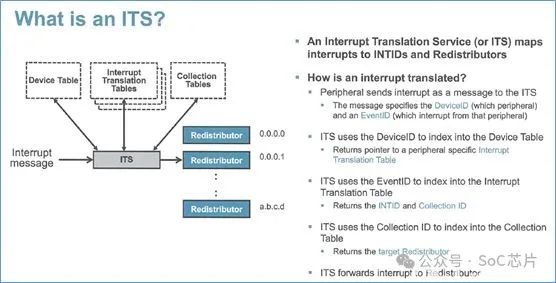
當外設往GITS_TRANSLATER寄存器中寫數據后,ITS做如下操作:
·使用DeviceID,從設備表(device table)中選擇索引為DeviceID的表項。從該表項中,得到中斷映射表的位置
·使用EventID,從中斷映射表中選擇索引為EventID的表項。得到中斷號,以及中斷所屬的collection號
·使用collection號,從collection表格中,選擇索引為collection號的表項。得到redistributor的映射信息
·根據collection表項的映射信息,將中斷信息,發送給對應的redistributor
以上是物理LPI中斷的ITS流程。虛擬LPI中斷的ITS流程與之類似。以下是處理流程圖:
6.5.2、ITS命令
ITS操作,會涉及到很多表,而這些表的創建,維護是通過ITS命令,來實現的。雖然這些表,是在內存中的,但是GICv3和GICv4,不支持直接訪問這些表,而是要通過ITS命令,來配置這些表。
ITS的操作,是通過命令,來控制的。外部通過發送命令給ITS,ITS然后去執行命令,每個命令,占32字節。
ITS有command隊列,命令寫在這個隊列里面。ITS會自動的按照隊列順序,一一執行。
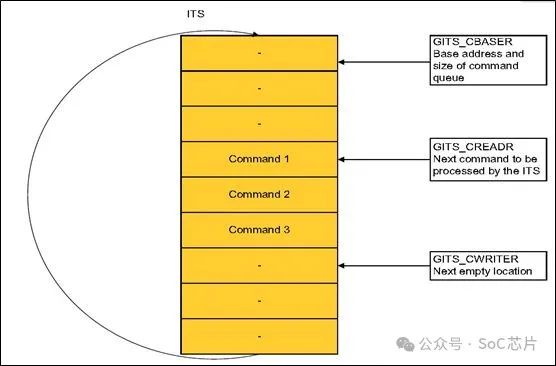
每個命令占32個字節。
命令,存放在內存中,GITS_CBASE,保存命令的首地址。GITS_CREADR,是由ITS控制,表示下一個命令的地址。GITS_CWRITER,是下一個待寫命令的地址。軟件往GITS_CWRITER地址處,寫入命令,之后ITS就會執行這個命令。
ITS提供的命令,有很多,可以查閱GIC手冊獲取更多。
以下是CLEAR命令。
 ? ?
? ?
6.5.3、ITS table
ITS包括很多個表,這些表均處于 non-secure區域。
GITS_BASER,指定ITS表的基地址和大小。軟件,在使用ITS之前,必須要配置。
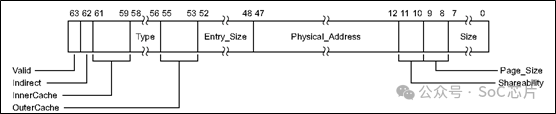
其中的Physical_Address字段,就指定了表的基地址所在位置。
以下是各個表的基地址,對應的寄存器。

審核編輯:劉清
-
控制器
+關注
關注
112文章
15885瀏覽量
175370 -
DDR
+關注
關注
11文章
697瀏覽量
64936 -
ARM處理器
+關注
關注
6文章
360瀏覽量
41516 -
SoC芯片
+關注
關注
1文章
584瀏覽量
34758 -
Cortex-A
+關注
關注
0文章
19瀏覽量
34247
原文標題:SoC芯片設計系列---ARM CPU子系統組件介紹
文章出處:【微信號:gh_9d9a609c9302,微信公眾號:SoC芯片】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
ARM系列之PCSA資料介紹
ARM GIC(一)之ARM soc中斷的處理介紹
Arm Corstone SSE-700子系統技術參考手冊
Arm Corstone SSE-710子系統技術參考手冊
Arm CoreLink? SSE-200嵌入式子系統技術概述
基于ARM7TDMI的SoC中MP3子系統的設計
ARM是什么意思,arm與cpu是什么關系
ARM Architecture, Core, CPU,SOC概念簡明介紹資料下載

手機處理器叫soc還是cpu soc包含哪些模塊 中端芯soc和中端soc區別
什么是片上系統(SoC)?SoC是如何工作的?





 工商網監
工商網監
評論