") 阿里通義千問Qwen2大模型發(fā)布并同步開源
阿里通義千問Qwen2大模型發(fā)布并同步開源
阿里巴巴集團旗下的通義千問團隊宣布,全新的Qwen2大模型正式發(fā)布,并在全球知名的開源平臺Hugging Face和ModelScope上同步開源。這一里程碑式的事件標志著中國在人工智能領域的又一次重要突破。
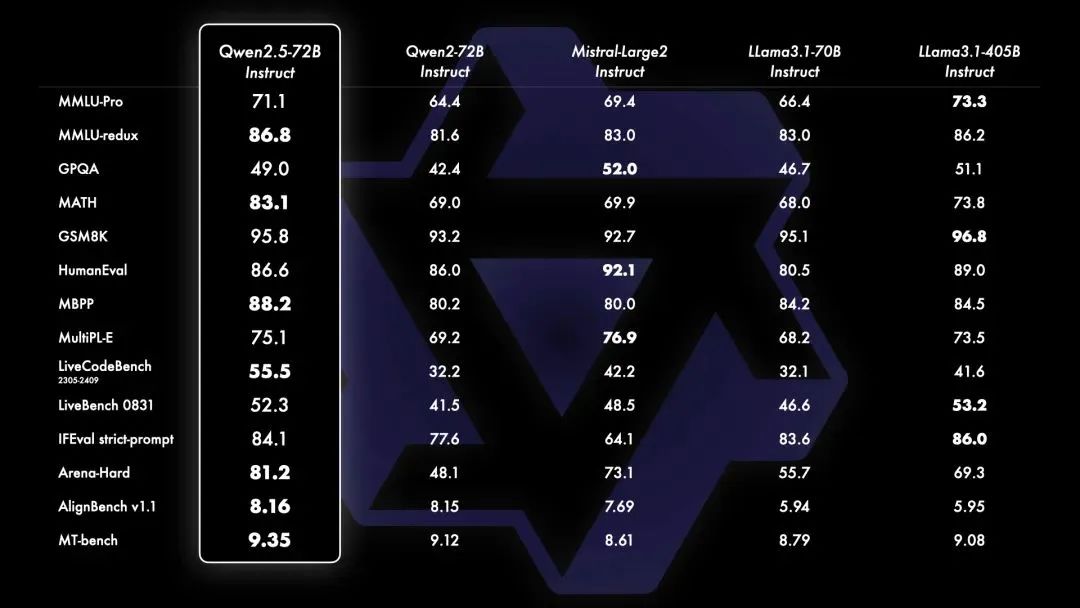
Qwen2系列大模型共包含5個不同尺寸的預訓練和指令微調(diào)模型,分別是Qwen2-0.5B、Qwen2-1.5B、Qwen2-7B、Qwen2-57B-A14B和Qwen2-72B,這些模型不僅在中英文處理上表現(xiàn)出色,更在性能上超越了美國當前最強的開源模型Llama3-70B,展示了中國人工智能技術的卓越實力。
值得一提的是,Qwen2大模型在訓練數(shù)據(jù)中增加了與27種語言相關的數(shù)據(jù),這一舉措極大地提升了模型的多語言能力。如今,Qwen2不僅在中英文處理上占據(jù)優(yōu)勢,更能在全球范圍內(nèi)為不同語言背景的用戶提供高效、準確的智能服務。
此外,Qwen2大模型在上下文長度支持上也實現(xiàn)了新的突破,最高可支持達128K tokens的文本處理,這在很大程度上滿足了用戶對長文本處理的需求,為各類應用場景提供了更加靈活、便捷的智能解決方案。
此次Qwen2大模型的發(fā)布,不僅展示了阿里巴巴在人工智能領域的創(chuàng)新能力和技術實力,更為全球人工智能領域的發(fā)展注入了新的活力。我們期待Qwen2大模型在未來能夠發(fā)揮更大的作用,為人類社會的進步和發(fā)展做出更大的貢獻。
聲明:本文內(nèi)容及配圖由入駐作者撰寫或者入駐合作網(wǎng)站授權(quán)轉(zhuǎn)載。文章觀點僅代表作者本人,不代表電子發(fā)燒友網(wǎng)立場。文章及其配圖僅供工程師學習之用,如有內(nèi)容侵權(quán)或者其他違規(guī)問題,請聯(lián)系本站處理。
舉報投訴
-
人工智能
+關注
關注
1791文章
46845瀏覽量
237535 -
開源
+關注
關注
3文章
3245瀏覽量
42396 -
通義千問
+關注
關注
1文章
24瀏覽量
231
發(fā)布評論請先 登錄
相關推薦
阿里通義千問發(fā)布Qwen2.5-Turbo開源AI模型
近日,阿里通義千問官方宣布,經(jīng)過數(shù)月的精心優(yōu)化與改進,正式推出了Qwen2.5-Turbo開源A
號稱全球最強開源模型 ——Qwen2.5 系列震撼來襲!PerfXCloud同步上線,快來體驗!
9月19日凌晨,阿里通義千問 正式開源Qwen2.5系列大模
通義千問發(fā)布第二代視覺語言模型Qwen2-VL
阿里巴巴旗下的通義千問近日宣布,其第二代視覺語言模型Qwen2-VL正式問世,并宣布旗艦
阿里Qwen2-Math系列震撼發(fā)布,數(shù)學推理能力領跑全球
阿里巴巴近期震撼發(fā)布了Qwen2-Math系列模型,這一系列模型基于其強大的Qwen2 LLM構(gòu)
Qwen2強勢來襲,AIBOX支持本地化部署
Qwen2是阿里通義推出的新一代多語言預訓練模型,經(jīng)過更深入的預訓練和指令調(diào)整,在多個基準評測結(jié)果中表現(xiàn)出色,尤其在代碼和數(shù)學方面有顯著提升,同時拓展了上下文長度支持,最高可達128K

阿里云正式發(fā)布通義千問2.5,中文性能全面趕超GPT-4 Turbo
在通義大模型發(fā)布一周年之際,阿里云邁出了歷史性的一步。近日,阿里云正式發(fā)布
阿里云發(fā)布通義千問2.5
阿里云近日正式發(fā)布了通義千問2.5,標志著其人工智能技術在中文語境下取得了重要突破。據(jù)阿里云智能
通義千問開源千億級參數(shù)模型
通義千問近日開源了其首個千億級參數(shù)模型Qwen1.5-110B,這是其全系列中首個達到千億級別的
聯(lián)發(fā)科天璣9300搭載通義千問大模型,阿里云提供解決方案
通義千問大模型已開源多項版本,包括18億、70億、140億及720億參數(shù)等版本伴隨視覺、音頻多模態(tài)能力提升。





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論