") HBase集群數(shù)據(jù)在線遷移方案探索
HBase集群數(shù)據(jù)在線遷移方案探索
一、背景
訂單本地化系統(tǒng)目前一個月的訂單的讀寫已經(jīng)切至jimkv存儲,對應的HBase集群已下線。但存儲全量數(shù)據(jù)的HBase集群仍在使用,計劃將這個HBase集群中的數(shù)據(jù)全部遷到jimkv,徹底下線這個HBase集群。由于這個集群目前仍在線上讀寫,本文從原理和實踐的角度探索對HBase集群數(shù)據(jù)的在線遷移的方案,歡迎大家補充。
二、基礎理論梳理
HBase整體架構
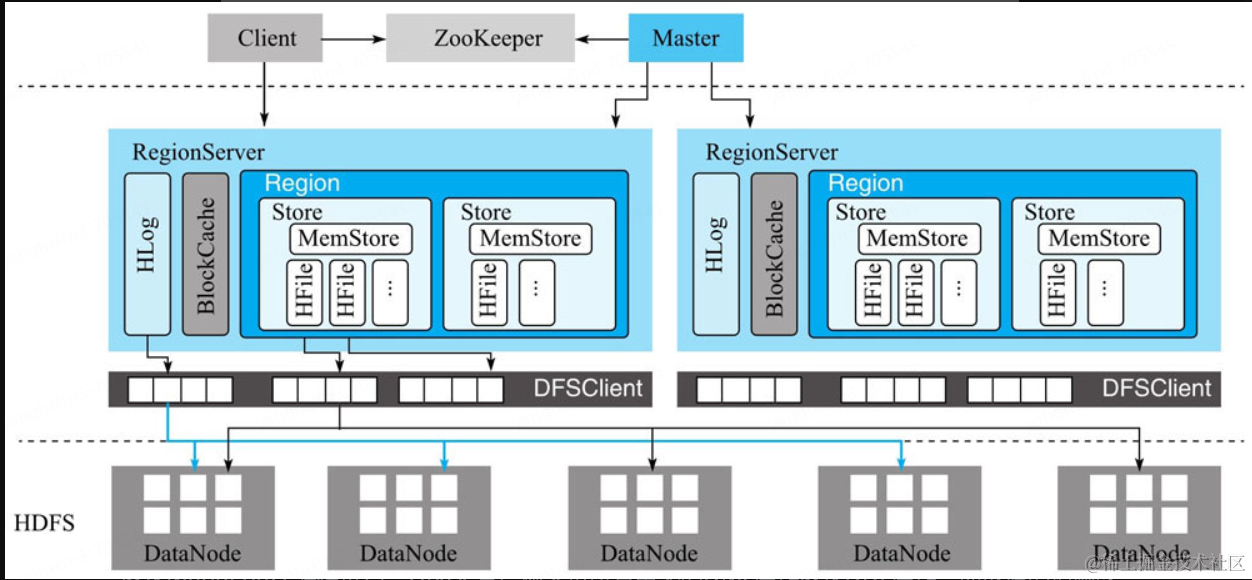
重溫一下各個模塊的職責
HBase客戶端
HBase客戶端(Client)提供了Shell命令行接口、原生Java API編程接口、Thrift/REST API編程接口以及MapReduce編程接口。HBase客戶端支持所有常見的DML操作以及DDL操作,即數(shù)據(jù)的增刪改查和表的日常維護等。其中Thrift/REST API主要用于支持非Java的上層業(yè)務需求,MapReduce接口主要用于批量數(shù)據(jù)導入以及批量數(shù)據(jù)讀取。HBase客戶端訪問數(shù)據(jù)行之前,首先需要通過元數(shù)據(jù)表定位目標數(shù)據(jù)所在RegionServer,之后才會發(fā)送請求到該RegionServer。同時這些元數(shù)據(jù)會被緩存在客戶端本地,以方便之后的請求訪問。如果集群RegionServer發(fā)生宕機或者執(zhí)行了負載均衡等,從而導致數(shù)據(jù)分片發(fā)生遷移,客戶端需要重新請求最新的元數(shù)據(jù)并緩存在本地。
Master
Master主要負責HBase系統(tǒng)的各種管理工作:
?處理用戶的各種管理請求,包括建表、修改表、權限操作、切分表、合并數(shù)據(jù)分片以及Compaction等。
?管理集群中所有RegionServer,包括RegionServer中Region的負載均衡、RegionServer的宕機恢復以及Region的遷移等。
?清理過期日志以及文件,Master會每隔一段時間檢查HDFS中HLog是否過期、HFile是否已經(jīng)被刪除,并在過期之后將其刪除。
RegionServer
RegionServer主要用來響應用戶的IO請求,是HBase中最核心的模塊,由WAL(HLog)、BlockCache以及多個Region構成。
?WAL(HLog):HLog在HBase中有兩個核心作用——其一,用于實現(xiàn)數(shù)據(jù)的高可靠性,HBase數(shù)據(jù)隨機寫入時,并非直接寫入HFile數(shù)據(jù)文件,而是先寫入緩存,再異步刷新落盤。為了防止緩存數(shù)據(jù)丟失,數(shù)據(jù)寫入緩存之前需要首先順序寫入HLog,這樣,即使緩存數(shù)據(jù)丟失,仍然可以通過HLog日志恢復;其二,用于實現(xiàn)HBase集群間主從復制,通過回放主集群推送過來的HLog日志實現(xiàn)主從復制。
?BlockCache:HBase系統(tǒng)中的讀緩存。客戶端從磁盤讀取數(shù)據(jù)之后通常會將數(shù)據(jù)緩存到系統(tǒng)內(nèi)存中,后續(xù)訪問同一行數(shù)據(jù)可以直接從內(nèi)存中獲取而不需要訪問磁盤。對于帶有大量熱點讀的業(yè)務請求來說,緩存機制會帶來極大的性能提升。
對于帶有大量熱點讀的業(yè)務請求來說,緩存機制會帶來極大的性能提升。BlockCache緩存對象是一系列Block塊,一個Block默認為64K,由物理上相鄰的多個KV數(shù)據(jù)組成。BlockCache同時利用了空間局部性和時間局部性原理,前者表示最近將讀取的KV數(shù)據(jù)很可能與當前讀取到的KV數(shù)據(jù)在地址上是鄰近的,緩存單位是Block(塊)而不是單個KV就可以實現(xiàn)空間局部性;后者表示一個KV數(shù)據(jù)正在被訪問,那么近期它還可能再次被訪問。當前BlockCache主要有兩種實現(xiàn)——LRUBlockCache和BucketCache,前者實現(xiàn)相對簡單,而后者在GC優(yōu)化方面有明顯的提升。
?Region:數(shù)據(jù)表的一個分片,當數(shù)據(jù)表大小超過一定閾值就會“水平切分”,分裂為兩個Region。Region是集群負載均衡的基本單位。通常一張表的Region會分布在整個集群的多臺RegionServer上,一個RegionServer上會管理多個Region,當然,這些Region一般來自不同的數(shù)據(jù)表。
一個Region由一個或者多個Store構成,Store的個數(shù)取決于表中列簇(column family)的個數(shù),多少個列簇就有多少個Store。HBase中,每個列簇的數(shù)據(jù)都集中存放在一起形成一個存儲單元Store,因此建議將具有相同IO特性的數(shù)據(jù)設置在同一個列簇中。每個Store由一個MemStore和一個或多個HFile組成。MemStore稱為寫緩存,用戶寫入數(shù)據(jù)時首先會寫到MemStore,當MemStore寫滿之后(緩存數(shù)據(jù)超過閾值,默認128M)系統(tǒng)會異步地將數(shù)據(jù)f lush成一個HFile文件。顯然,隨著數(shù)據(jù)不斷寫入,HFile文件會越來越多,當HFile文件數(shù)超過一定閾值之后系統(tǒng)將會執(zhí)行Compact操作,將這些小文件通過一定策略合并成一個或多個大文件。
HDFS
HBase底層依賴HDFS組件存儲實際數(shù)據(jù),包括用戶數(shù)據(jù)文件、HLog日志文件等最終都會寫入HDFS落盤。HDFS是Hadoop生態(tài)圈內(nèi)最成熟的組件之一,數(shù)據(jù)默認三副本存儲策略可以有效保證數(shù)據(jù)的高可靠性。HBase內(nèi)部封裝了一個名為DFSClient的HDFS客戶端組件,負責對HDFS的實際數(shù)據(jù)進行讀寫訪問。
三、數(shù)據(jù)遷移方案調(diào)研
1、如何定位一條數(shù)據(jù)在哪個region
HBase一張表的數(shù)據(jù)是由多個Region構成,而這些Region是分布在整個集群的RegionServer上的。那么客戶端在做任何數(shù)據(jù)操作時,都要先確定數(shù)據(jù)在哪個Region上,然后再根據(jù)Region的RegionServer信息,去對應的RegionServer上讀取數(shù)據(jù)。因此,HBase系統(tǒng)內(nèi)部設計了一張?zhí)厥獾谋怼猦base:meta表,專門用來存放整個集群所有的Region信息。
hbase:meta表的結構如下,整個表只有一個名為info的列族。而且HBase保證hbase:meta表始終只有一個Region,這是為了確保meta表多次操作的原子性。
hbase:meta的一個rowkey就對應一個Region,rowkey主要由TableName(業(yè)務表名)、StartRow(業(yè)務表Region區(qū)間的起始rowkey)、Timestamp(Region創(chuàng)建的時間戳)、EncodedName(上面3個字段的MD5 Hex值)4個字段拼接而成。每一行數(shù)據(jù)又分為4列,分別是info:regioninfo、info:seqnumDuringOpen、info:server、info:serverstartcode。
?info:regioninfo:該列對應的Value主要存儲4個信息,即EncodedName、RegionName、Region的StartRow、Region的StopRow。
?info:seqnumDuringOpen:該列對應的Value主要存儲Region打開時的sequenceId。
?info:server:該列對應的Value主要存儲Region落在哪個RegionServer上。
?info:serverstartcode:該列對應的Value主要存儲所在RegionServer的啟動Timestamp。
為了解決如果所有的流量都先請求hbase:meta表找到Region,再請求Region所在的RegionServer,那么hbase:meta表的將承載巨大的壓力,這個Region將馬上成為熱點Region這個問題,HBase會把hbase:meta表的Region信息緩存在HBase客戶端。在HBase客戶端有一個叫做MetaCache的緩存,在調(diào)用HBase API時,客戶端會先去MetaCache中找到業(yè)務rowkey所在的Region。

2、HBase client Scan用法
HBase客戶端提供了一系列可以批量掃描數(shù)據(jù)的api,主要有ScanAPI、TableScanMR、SnapshotScanM
HBase client scan demo
public class TestDemo {
private static final HBaseTestingUtility TEST_UTIL=new HBaseTestingUtility();
public static final TableName tableName=TableName.valueOf("testTable");
public static final byte[] ROW_KEY0=Bytes.toBytes("rowkey0");
public static final byte[] ROW_KEY1=Bytes.toBytes("rowkey1");
public static final byte[] FAMILY=Bytes.toBytes("family");
public static final byte[] QUALIFIER=Bytes.toBytes("qualifier");
public static final byte[] VALUE=Bytes.toBytes("value");
@BeforeClass
public static void setUpBeforeClass() throws Exception {
TEST_UTIL.startMiniCluster();
}
@AfterClass
public static void tearDownAfterClass() throws Exception {
TEST_UTIL.shutdownMiniCluster();
}
@Test
public void test() throws IOException {
Configuration conf=TEST_UTIL.getConfiguration();
try (Connection conn=ConnectionFactory.createConnection(conf)) {
try (Table table=conn.getTable(tableName)) {
for (byte[] rowkey : new byte[][] { ROW_KEY0, ROW_KEY1 }) {
Put put=new Put(rowkey).addColumn(FAMILY, QUALIFIER, VALUE);
table.put(put);
}
Scan scan=new Scan().withStartRow(ROW_KEY1).setLimit(1);
try (ResultScanner scanner=table.getScanner(scan)) {
List< Cell > cells=new ArrayList< >();
for (Result result : scanner) {
cells.addAll(result.listCells());
}
Assert.assertEquals(cells.size(), 1);
Cell firstCell=cells.get(0);
Assert.assertArrayEquals(CellUtil.cloneRow(firstCell), ROW_KEY1);
Assert.assertArrayEquals(CellUtil.cloneFamily(firstCell), FAMILY);
Assert.assertArrayEquals(CellUtil.cloneQualifier(firstCell), QUALIFIER);
Assert.assertArrayEquals(CellUtil.cloneValue(firstCell), VALUE);
}
}
}
}
}
Scan API
使用ScanAPI獲取Result的流程如下,在上面的demo代碼中,table.getScanner(scan)可以拿到一個scanner,然后只要不斷地執(zhí)行scanner.next()就能拿到一個Result,客戶端Scan的核心流程如下

用戶每次執(zhí)行scanner.next(),都會嘗試去名為cache的隊列中拿result(步驟4)。如果cache隊列已經(jīng)為空,則會發(fā)起一次RPC向服務端請求當前scanner的后續(xù)result數(shù)據(jù)(步驟1)。客戶端收到result列表之后(步驟2),通過scanResultCache把這些results內(nèi)的多個cell進行重組,最終組成用戶需要的result放入到Cache中(步驟3)。其中,步驟1+步驟2+步驟3統(tǒng)稱為loadCache操作。為什么需要在步驟3對RPC response中的result進行重組呢?這是因為RegionServer為了避免被當前RPC請求耗盡資源,實現(xiàn)了多個維度的資源限制(例如timeout、單次RPC響應最大字節(jié)數(shù)等),一旦某個維度資源達到閾值,就馬上把當前拿到的cell返回給客戶端。這樣客戶端拿到的result可能就不是一行完整的數(shù)據(jù),因此在步驟3需要對result進行重組。
梳理完scanner的執(zhí)行流程之后,再看下Scan的幾個重要的概念。
?caching:每次loadCache操作最多放caching個result到cache隊列中。控制caching,也就能控制每次loadCache向服務端請求的數(shù)據(jù)量,避免出現(xiàn)某一次scanner.next()操作耗時極長的情況。
?batch:用戶拿到的result中最多含有一行數(shù)據(jù)中的batch個cell。如果某一行有5個cell,Scan設的batch為2,那么用戶會拿到3個result,每個result中cell個數(shù)依次為2,2,1。
?allowPartial:用戶能容忍拿到一行部分cell的result。設置了這個屬性,將跳過圖4-3中的第三步重組流程,直接把服務端收到的result返回給用戶。
?maxResultSize:loadCache時單次RPC操作最多拿到maxResultSize字節(jié)的結果集。
缺點:不能并發(fā)執(zhí)行,如果掃描的數(shù)據(jù)分布在不同的region上面,scan不會并發(fā)執(zhí)行,而是一行一行的去掃,且在步驟1和步驟2期間,client端一致在阻塞等待,所以從客戶端視角來看整個掃描時間=客戶端處理數(shù)據(jù)時間+服務器端掃描數(shù)據(jù)時間。
應用場景:根據(jù)上面的分析,scan API的效率很大程度上取決于掃描的數(shù)據(jù)量。通常建議OLTP業(yè)務中少量數(shù)據(jù)量掃描的scan可以使用scan API,大量數(shù)據(jù)的掃描使用scan API,掃描性能有時候并不能夠得到有效保證。
最佳實踐:
1.批量OLAP掃描業(yè)務建議不要使用ScanAPI,ScanAPI適用于少量數(shù)據(jù)掃描場景(OLTP場景)
2.建議所有scan盡可能都設置startkey以及stopkey減少掃描范圍
3.建議所有僅需要掃描部分列的scan盡可能通過接口setFamilyMap設置列族以及列
TableScanMR
對于掃描大量數(shù)據(jù)的這類業(yè)務,HBase目前提供了兩種基于MR掃描的用法,分別為TableScanMR以及SnapshotScanMR。首先來介紹TableScanMR,具體用法參考官方文檔https://hbase.apache.org/book.html#mapreduce.example.read,TableScanMR的工作原理說白了就是ScanAPI的并行化。如下圖所示:

TableScanMR會將scan請求根據(jù)目標region的分界進行分解,分解成多個sub-scan,每個sub-scan本質(zhì)上就是一個ScanAPI。假如scan是全表掃描,那這張表有多少region,就會將這個scan分解成多個sub-scan,每個sub-scan的startkey和stopkey就是region的startkey和stopkey。
最佳實踐:
1.TableScanMR設計為OLAP場景使用,因此在離線掃描時盡可能使用該種方式
2.TableScanMR原理上主要實現(xiàn)了ScanAPI的并行化,將scan按照region邊界進行切分。這種場景下整個scan的時間基本等于最大region掃描的時間。在某些有數(shù)據(jù)傾斜的場景下可能出現(xiàn)某一個region上有大量待掃描數(shù)據(jù),而其他大量region上都僅有很少的待掃描數(shù)據(jù)。這樣并行化效果并不好。針對這種數(shù)據(jù)傾斜的場景TableScanMR做了平衡處理,它會將大region上的scan切分成多個小的scan使得所有分解后的scan掃描的數(shù)據(jù)量基本相當。這個優(yōu)化默認是關閉的,需要設置參數(shù)”hbase.mapreduce.input.autobalance”為true。因此建議大家使用TableScanMR時將該參數(shù)設置為true。
3.盡量將掃描表中相鄰的小region合并成大region,而將大region切分成稍微小點的region
SnapshotScanMR
SnapshotScanMR與TableScanMR相同都是使用MR并行化對數(shù)據(jù)進行掃描,兩者用法也基本相同,直接使用TableScanMR的用法,在此基礎上做部分修改即可,它們最大的區(qū)別主要有兩點:
1.SnapshotScanMR掃描于原始表對應的snapshot之上(更準確來說根據(jù)snapshot restore出來的hfile),而TableScanMR掃描于原始表。
2.SnapshotScanMR直接會在客戶端打開region掃描HDFS上的文件,不需要發(fā)送Scan請求給RegionServer,再有RegionServer掃描HDFS上的文件。在客戶端直接掃描HDFS上的文件,這類scanner稱之為ClientSideRegionScanner。

總體來看和TableScanMR工作流程基本一致,最大的不同來自region掃描HDFS這個模塊,TableScanMR中這個模塊來自于regionserver,而SnapshotScanMR中客戶端直接繞過regionserver在客戶端借用region中的掃描機制直接掃描hdfs中數(shù)據(jù)。這樣做的優(yōu)點如下:
1.減小對RegionServer的影響。很顯然,SnapshotScanMR這種繞過RegionServer的實現(xiàn)方式最大限度的減小了對集群中其他業(yè)務的影響。
2.極大的提升了掃描效率。SnapshotScanMR相比TableScanMR在掃描效率上會有2倍~N倍的性能提升(下一小節(jié)對各種掃描用法性能做個對比評估)。主要原因如下:掃描的過程少了一次網(wǎng)絡傳輸,對于大數(shù)據(jù)量的掃描,網(wǎng)絡傳輸花費的時間是非常龐大的,這主要可能牽扯到數(shù)據(jù)的序列化以及反序列化開銷。TableScanMR掃描中RegionServer很可能會成為瓶頸,而SnapshotScanMR掃描并沒有這個瓶頸點。
性能對比(來自網(wǎng)圖)

3、業(yè)界常用的數(shù)據(jù)遷移方案
Hadoop層數(shù)據(jù)遷移
Hadoop層的數(shù)據(jù)遷移主要用到DistCp(Distributed Copy), HBase的所有文件都存儲在HDFS上,因此只要使用Hadoop提供的文件復制工具distcp將HBASE目錄復制到同一HDFS或者其他HDFS的另一個目錄中,就可以完成對源HBase集群的備份工作。
缺點:源集群需要停寫,不可行。
HBase層數(shù)據(jù)遷移
- copyTable
copyTable也是屬于HBase層的數(shù)據(jù)遷移工具之一,從0.94版本開始支持,以表級別進行數(shù)據(jù)遷移。通過MapReduce程序全表掃描待備份表數(shù)據(jù)并寫入另一個集群,與DistCp不同的時,它是利用MR去scan 原表的數(shù)據(jù),然后把scan出來的數(shù)據(jù)寫入到目標集群的表。
缺點:全表臊面+數(shù)據(jù)深拷貝,對源表的讀寫性能有很大影響,效率低。需要在使用過程中限定掃描原表的速度和傳輸?shù)膸挘襝opyTable不保證數(shù)據(jù)一致性,在大型集群遷移上這個工具使用比較少,很難控制。
- Export/Import
此方式與CopyTable類似,主要是將HBase表數(shù)據(jù)轉換成Sequence File并dump到HDFS,也涉及Scan表數(shù)據(jù),與CopyTable相比,還多支持不同版本數(shù)據(jù)的拷貝,同時它拷貝時不是將HBase數(shù)據(jù)直接Put到目標集群表,而是先轉換成文件,把文件同步到目標集群后再通過Import到線上表。
- Snapshot
Snapshot備份以快照技術為基礎原理,備份過程不需要拷貝任何數(shù)據(jù),因此對當前集群幾乎沒有任何影響,備份速度非常快而且可以保證數(shù)據(jù)一致性。筆者推薦在0.98之后的版本都使用Snapshot工具來完成在線備份任務。 參考: https://hbase.apache.org/book.html#ops.backup
4、Snapshot功能
常用場景
HBase在0.98版本推出在線Snapshot備份功能,使用在線snapshot備份功能常用于如下兩種情況:
?全量/增量備份。
○使用場景一:通常情況下,對于重要的業(yè)務數(shù)據(jù),建議每天執(zhí)行一次Snapshot來保存數(shù)據(jù)的快照記錄,并且定期清理過期快照,這樣如果業(yè)務發(fā)生嚴重錯誤,可以回滾到之前的一個快照點。
○使用場景二:如果要對集群做重大升級,建議升級前對重要的表執(zhí)行一次Snapshot,一旦升級有任何異常可以快速回滾到升級前。
?數(shù)據(jù)遷移
可以使用ExportSnapshot功能將快照導出到另一個集群,實現(xiàn)數(shù)據(jù)的遷移。
○使用場景一:機房在線遷移。比如業(yè)務集群在A機房,因為A機房機位不夠或者機架不夠需要將整個集群遷移到另一個容量更大的B集群,而且在遷移過程中不能停服。基本遷移思路是,先使用Snapshot在B集群恢復出一個全量數(shù)據(jù),再使用replication技術增量復制A集群的更新數(shù)據(jù),等待兩個集群數(shù)據(jù)一致之后將客戶端請求重定向到B機房。
○使用場景二:利用Snapshot將表數(shù)據(jù)導出到HDFS,再使用HiveSpark等進行離線OLAP分析,比如審計報表、月度報表等。
基本原理
Snapshot機制并不會拷貝數(shù)據(jù),可以理解為它是原數(shù)據(jù)的一份指針。在HBase的LSM樹類型系統(tǒng)結構下是比較容易理解的,我們知道HBase數(shù)據(jù)文件一旦落到磁盤就不再允許更新刪除等原地修改操作,如果想更新刪除只能追加寫入新文件。這種機制下實現(xiàn)某個表的Snapshot,只需為當前表的所有文件分別新建一個引用(指針)。對于其他新寫入的數(shù)據(jù),重新創(chuàng)建一個新文件寫入即可。如下圖所示

實踐過程
我在阿里云上搭建了一個輕量級的haddop和HBase集群,使用Snapshot功能步驟如下:
- 在目標集群上建立表結構一樣的表。
$ hbase shell
hbase > create 'myTable', 'cf1', 'cf2'
- 在原集群上對表初始化數(shù)據(jù)。
$ hbase shell
hbase > put 'myTable', 'row1', 'cf1:a', 'value1'
hbase > put 'myTable', 'row2', 'cf2:b', 'value2'
hbase > scan 'myTable'
ROW COLUMN+CELL row1 column=cf1:a, timestamp=2023-08-09T16:43:10.024, value=value1 row2 column=cf2:b, timestamp=2023-08-09T16:43:20.036, value=value2
- 使用 hbase shell 在原始集群中創(chuàng)建一個快照。
$ hbase shell
hbase >snapshot 'myTable', 'myTableSnapshot'
這里 'myTable' 是 hbase 的表名,'myTableSnapshot' 是快照的名稱。創(chuàng)建完成后可使用 list_snapshots 確認是否成功,或使用 delete_snapshot 刪除快照。
hbase > delete_snapshot 'myTableSnapshot'
- 在源集群中導出快照到目標集群。
hbase org.apache.hadoop.hbase.snapshot.ExportSnapshot -snapshot myTableSnapshot -copy-to hdfs://10.0.0.38:4007/hbase/snapshot/myTableSnapshot
這里 10.0.0.38:4007 是目標集群的 **activeip:**rpcport,導出快照時系統(tǒng)級別會啟動一個 mapreduce 的任務,可以在后面增加 -mappers 16 -bandwidth 200 來指定 mapper 和帶寬。其中200指的是200MB/sec。
- 快照還原到目標集群的目標 HDFS,在目標集群中執(zhí)行如下命令。
hbase org.apache.hadoop.hbase.snapshot.ExportSnapshot -snapshot myTableSnapshot -copy-from /hbase/snapshot/myTableSnapshot -copy-to /hbase/
- 在目標集群從 hdfs 恢復相應的 hbase 表及數(shù)據(jù)。
hbase > disable "myTable"
hbase > restore_snapshot 'myTableSnapshot'
hbase > enable 'myTable'
- 對于新表進行測試
注意事項
訂單本地化HDD目前order_info_2023這張表分布在1500多個不同的region上,按照各種參考資料的理論來說,使用snapshot易超時,該如何解決這個問題?有沒有什么方法能使做Snapshot更高效?網(wǎng)上關于這部分的資料太少,目前找不到太深入全面的解析。還有測試環(huán)境如何走這個流程?
使用snapshot注意需要申請zk、hbase-master節(jié)點的shell的管理員權限。
5、讀數(shù)據(jù)時的注意事項
關于scan時緩存的設置
原理:HBase業(yè)務通常一次scan就會返回大量數(shù)據(jù),因此客戶端發(fā)起一次scan請求,實際并不會一次就將所有數(shù)據(jù)加載到本地,而是分成多次RPC請求進行加載,這樣設計一方面因為大量數(shù)據(jù)請求可能會導致網(wǎng)絡帶寬嚴重消耗進而影響其他業(yè)務,另一方面因為數(shù)據(jù)量太大可能導致本地客戶端發(fā)生OOM。在這樣的設計體系下,用戶會首先加載一部分數(shù)據(jù)到本地,然后遍歷處理,再加載下一部分數(shù)據(jù)到本地處理,如此往復,直至所有數(shù)據(jù)都加載完成。數(shù)據(jù)加載到本地就存放在scan緩存中,默認為100條數(shù)據(jù)。通常情況下,默認的scan緩存設置是可以正常工作的。但是對于一些大scan(一次scan可能需要查詢幾萬甚至幾十萬行數(shù)據(jù)),每次請求100條數(shù)據(jù)意味著一次scan需要幾百甚至幾千次RPC請求,這種交互的代價是很大的。因此可以考慮將scan緩存設置增大,比如設為500或者1000條可能更加合適。《HBase原理與實踐》作者提到,之前做過一次試驗,在一次scan 10w+條數(shù)據(jù)量的條件下,將scan緩存從100增加到1000條,可以有效降低scan請求的總體延遲,延遲降低了25%左右。
建議:大scan場景下將scan緩存從100增大到500或者1000,用以減少RPC次數(shù)。
關于離線批量讀時緩存的設置
原理:通常在離線批量讀取數(shù)據(jù)時會進行一次性全表掃描,一方面數(shù)據(jù)量很大,另一方面請求只會執(zhí)行一次。這種場景下如果使用scan默認設置,就會將數(shù)據(jù)從HDFS加載出來放到緩存。可想而知,大量數(shù)據(jù)進入緩存必將其他實時業(yè)務熱點數(shù)據(jù)擠出,其他業(yè)務不得不從HDFS加載,進而造成明顯的讀延遲毛刺。
建議:離線批量讀取請求設置禁用緩存,scan.setCacheBlocks (false)。
四、方案設計
五、代碼實現(xiàn)
對于HBase各種常用的DDL、DML操作的api匯總到這里
http://xingyun.jd.com/codingRoot/yanghelin3/hbase-api/
使用mapreduce方式遷移實現(xiàn)匯總到這里
http://xingyun.jd.com/codingRoot/yanghelin3/hbase-mapreduce/
REFERENCE
參考資料
HBase官方文檔:[http://hbase.apache.org/book.html#arch.overview]
HBase官方博客:[https://blogs.apache.org/hbase]
cloudera官方HBase博客:[https://blog.cloudera.com/blog/category/hbase]
HBasecon官網(wǎng):[http://hbase.apache.org/www.hbasecon.com]
HBase開發(fā)社區(qū):[https://issues.apache.org/jira/pr
HBase中文社區(qū):[http://hbase.group]
《Hbase原理與實踐 》
snapshot功能介紹
[https://blog.cloudera.com/introduction-to-apache-hbase-snapshots/]
[https://blog.cloudera.com/introduction-to-apache-hbase-snapshots-part-2-deeper-dive/]
[https://hbase.apache.org/book.html#ops.backup]
如何使用snapshot進行復制
[https://docs.cloudera.com/documentation/enterprise/5-5-x/topics/cdh_bdr_hbase_replication.html#topic_20_11_7]
審核編輯 黃宇
-
接口
+關注
關注
33文章
8496瀏覽量
150834 -
編程
+關注
關注
88文章
3591瀏覽量
93593 -
數(shù)據(jù)遷移
+關注
關注
0文章
68瀏覽量
6939 -
HDFS
+關注
關注
1文章
30瀏覽量
9570 -
Hbase
+關注
關注
0文章
27瀏覽量
11163
發(fā)布評論請先 登錄
相關推薦
再談全局網(wǎng)HBase八大應用場景
HBase性能優(yōu)化方法總結
阿里HBase的數(shù)據(jù)管道設施實踐與演進
大數(shù)據(jù)時代數(shù)據(jù)庫-云HBase架構&生態(tài)&實踐
企業(yè)打開云HBase的正確方式,來自阿里云云數(shù)據(jù)庫團隊的解讀
HBase read replicas 功能介紹系列
大數(shù)據(jù)學習之Hbase shell的基本操作
兌吧:從自建HBase遷移到阿里云HBase實戰(zhàn)經(jīng)驗
hbase工作原理_hbase超詳細介紹
hbase性能測試總結






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論