 關于Spark的從0實現30s內實時監控指標計算
關于Spark的從0實現30s內實時監控指標計算
前言
說起Spark,大家就會自然而然地想到Flink,而且會不自覺地將這兩種主流的大數據實時處理技術進行比較。然后最終得出結論:Flink實時性大于Spark。
的確,Flink中的數據計算是以事件為驅動的,所以來一條數據就會觸發一次計算,而Spark基于數據集RDD計算,RDD最小生成間隔就是50毫秒,所以Spark就被定義為亞實時計算。
窗口Window
這里的RDD就是“天然的窗口”,將RDD生成的時間間隔設置成1min,那么這個RDD就可以理解為“1min窗口”。所以如果想要窗口計算,首選Spark。
但當需要對即臨近時間窗口進行計算時,必須借助滑動窗口的算子來實現。
臨近時間如何理解
例如“3分鐘內”這種時間范圍描述。這種時間范圍的計算,需要計算歷史的數據。例如1 ~ 3是3min,2 ~ 4也是3min,這里就重復使用了2和3的數據,依次類推,3 ~ 5也是3min,同樣也重復使用了3和4。
如果使用普通窗口,就無法滿足“最近3分鐘內”這種時間概念。
很多窗口都丟失了臨近時間,例如第3個RDD的臨近時間其實是第二個RDD,但是他們就沒法在一起計算,這就是為什么不用普通窗口的原因。
滑動窗口
滑動窗口三要素:RDD的生成時間、窗口的長度、滑動的步長。
我在本次實踐中,將RDD的時間間隔設置為10s,窗口長度為30s、滑動步長為10s。也就是說每10s就會生成一個窗口,計算最近30s內的數據,每個窗口由3個RDD組成。
數據源構建
1. 數據規范
假設我們采集了設備的指標信息,這里我們只關注吞吐量和響應時間,在采集之前定義數據字段和規范[throughput, response_time],這里都定義成int類型,響應時間單位這里定義成毫秒ms。
實際情況中,我們不可能只采集一臺設備,如果我們想要得出每臺或者每個種類設備的指標監控,就要在采集數據的時候對每個設備加上唯一ID或者TypeID。
我這里的想法是對每臺設備的指標進行分析,所以我給每個設備都增加了一個唯一ID,最終字段[id, throughput, response_time],所以我們就按照這個數據格式,在SparkStreaming中構建數據源讀取部分。
2. 讀取kafka
代碼語言:scala
復制
val conf = new SparkConf().setAppName("aqi").setMaster("local[1]")
val ssc = new StreamingContext(conf, Seconds(10))
val kafkaParams = Map[String, Object](
"bootstrap.servers" -> "121.91.168.193:9092",
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
"group.id" -> "aqi",
"auto.offset.reset" -> "earliest",
"enable.auto.commit" -> (true: java.lang.Boolean)
)
val topics = Array("evt_monitor")
val stream: DStream[String] = KafkaUtils.createDirectStream[String, String](
ssc,
PreferConsistent,
Subscribe[String, String](topics, kafkaParams)
).map(_.value)
這里我們將一個RDD時間間隔設置為10S,因為使用的是筆記本跑,所以這里要將Master設置為local,表示本地運行模式,1代表使用1個線程。
我們使用Kafka作為數據源,在讀取時就要構建Consumer的config,像bootstrap.servers這些基本配置沒有什么好說的,關鍵的是auto.offset.reset和enable.auto.commit,
這兩個參數分表控制讀取topic消費策略和是否提交offset。這里的earliest會從topic中現存最早的數據開始消費,latest是最新的位置開始消費。
當重啟程序時,這兩種消費模式又被enable.auto.commit控制,設置true提交offset時,earliest和latest不再生效,都是從消費組記錄的offset進行消費。設置為false不提交offset,offset不被提交記錄earliest還是從topic中現存最早的數據開始消費,latest還是從最新的數據消費。
最后就是設置要讀取的topic和創建Kafka的DStream數據流。至此,整個數據源的讀取就已經完成了,下面就是對數據處理邏輯的開發。
3. 指標聚合計算
代碼語言:scala
復制
stream.map(x => {
val s = x.split(",")
(s(0), (s(2).toInt, 1))
}).reduceByKey((x, y) => (x._1 + y._1, x._2 + y._2))
.reduceByKeyAndWindow((x: (Int, Int), y: (Int, Int)) => (x._1 + y._1, x._2 + y._2), Seconds(30), Seconds(10))
.foreachRDD(rdd => {
rdd.foreach(x => {
val id = x._1
val responseTimes = x._2._1
val num = x._2._2
val responseTime_avg = responseTimes / num
println(id, responseTime_avg)
})
})
我們從自身需求出發,來構思程序邏輯的開發。從需求看,關鍵字無非是最近一段時間內、平均值。想要取一段時間內的數據,就要使用滑動窗口,以當前時間為基準,向前圈定時間范圍。
而平均值,無非就是將時間范圍內,即窗口所有的響應時間加起來,然后除以數據條數即可。想要把所有的響應時間加起來,這里使用reduceByKey() 將窗口內相同ID的設備時間相加,將數據條數進行相加。
所以我在第一步切分數據的時候,就將數據切分成KV的元組形式,V有兩個字段,第一個是響應時間,第二個1表示一條數據。reduceByKey一共分為兩步,第一是RDD內的reduceByKey,這也算是數據的預處理,RDD的數據只會計算一次,當這個RDD被多個窗口使用,就不會重復計算了。第二步是基于窗口的reduceByKey,將窗口所有RDD的數據再一次聚合,最后在foreachRDD中獲取輸出
4. 驗證結果
我們向kafka的evt_monitor這個topic中寫入數據。
備注:(最后11那個id是終端顯示問題,其實是1),然后可以輸出平均值。
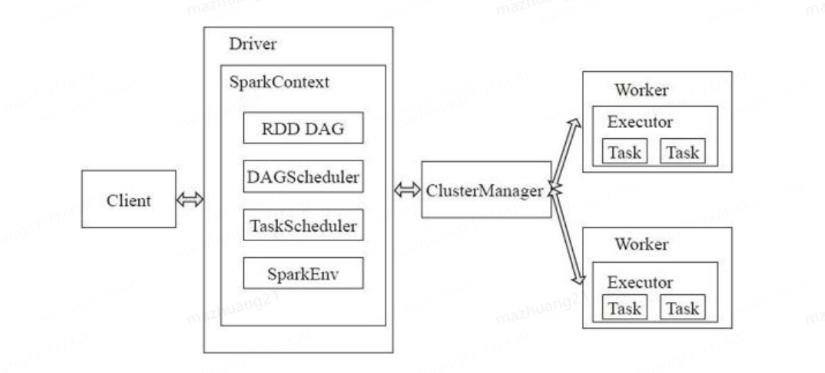
驗證結果是沒有問題的,換個角度,我們也可以從DAG來看。
這個窗口一共計算了3個RDD,其中左側的兩個是灰色的,上面是skipped標識,代表著這兩個RDD在上一個窗口已經計算完成了,在這個窗口只需要計算當前的RDD,然后再一起對RDD的結果數據進行窗口計算。
結語
本篇文章主要是利用Spark的滑動窗口,做了一個計算平均響應時長的應用場景,以Kafka作為數據源、通過滑動窗口和reduceByKey算子得以實現。同時,開發Spark還是強烈推薦scala,整個程序看起來沒有任何多余的部分。
最后對于Spark和Flink的選型看法,Spark的確是在實時性上比Flink差一些,但是Spark對于窗口計算還是有優勢的。所以對于每種技術,也不用人云亦云,適合自己的才是最好的。
審核編輯 黃宇
-
RDD
+關注
關注
0文章
7瀏覽量
7957 -
實時監控
+關注
關注
1文章
82瀏覽量
13414 -
SPARK
+關注
關注
1文章
105瀏覽量
19823
發布評論請先 登錄
相關推薦
spark為什么比mapreduce快?
監控系統原理揭秘-數據運算篇
30元如何實現車輛防后撞

spark運行的基本流程
Spark基于DPU的Native引擎算子卸載方案

上位監控程序如何實現
從MRAM的演進看存內計算的發展
淺談存內計算生態環境搭建以及軟件開發
Spark基于DPU Snappy壓縮算法的異構加速方案
RDMA技術在Apache Spark中的應用

基于DPU和HADOS-RACE加速Spark 3.x






 工商網監
工商網監
評論