") 利用大模型服務(wù)一線小哥的探索與實(shí)踐
利用大模型服務(wù)一線小哥的探索與實(shí)踐
一、小哥作業(yè)+大模型
2022年OpenAI基于GPT推出了聊天機(jī)器人ChatGPT,帶來(lái)了非常驚艷的語(yǔ)言理解、內(nèi)容生成、知識(shí)推理等能力,能夠準(zhǔn)確理解人的語(yǔ)言、意圖,并能夠回答出清晰、完整的內(nèi)容,讓人很難分辨出溝通交流的是人類還是機(jī)器人。
大模型會(huì)嘗試基于已有的內(nèi)容,生成內(nèi)容的延續(xù)。基于預(yù)訓(xùn)練階段加入的海量文章、電子圖書、網(wǎng)頁(yè)內(nèi)容等等,大模型給出最接近我們期望的內(nèi)容。比如我們提供的內(nèi)容是“北京是...”,大模型掃描海量?jī)?nèi)容進(jìn)行排名,為了讓內(nèi)容更有創(chuàng)造力,大模型使用了巫術(shù),一般采用基于可配置參數(shù)(top K, top P, Temperature) 的概率隨機(jī)采樣來(lái)選擇單詞,而不是總采用排名最高的單詞。通過(guò)延續(xù)生成了“北京是一座充滿活力的城市”。人類反饋強(qiáng)化學(xué)習(xí)(RLHF)即基于人類反饋對(duì)大語(yǔ)言模型進(jìn)行強(qiáng)化學(xué)習(xí),通過(guò)人工標(biāo)注來(lái)構(gòu)建獎(jiǎng)懲網(wǎng)絡(luò),強(qiáng)化學(xué)習(xí)基于獎(jiǎng)懲網(wǎng)絡(luò)對(duì)模型進(jìn)行迭代優(yōu)化,改善生成內(nèi)容的質(zhì)量。
快遞快運(yùn)終端系統(tǒng)是快遞小哥、快運(yùn)司機(jī)、網(wǎng)點(diǎn)管理者日常使用的系統(tǒng),是物流作業(yè)人員最多、作業(yè)流程最末端、服務(wù)形態(tài)最多元的系統(tǒng)。大模型帶來(lái)了新的方法來(lái)解決小哥提出的問(wèn)題、遇到的異常、需要的支持,并提供幫助網(wǎng)點(diǎn)管理者進(jìn)行運(yùn)營(yíng)和經(jīng)營(yíng)管理的工具。
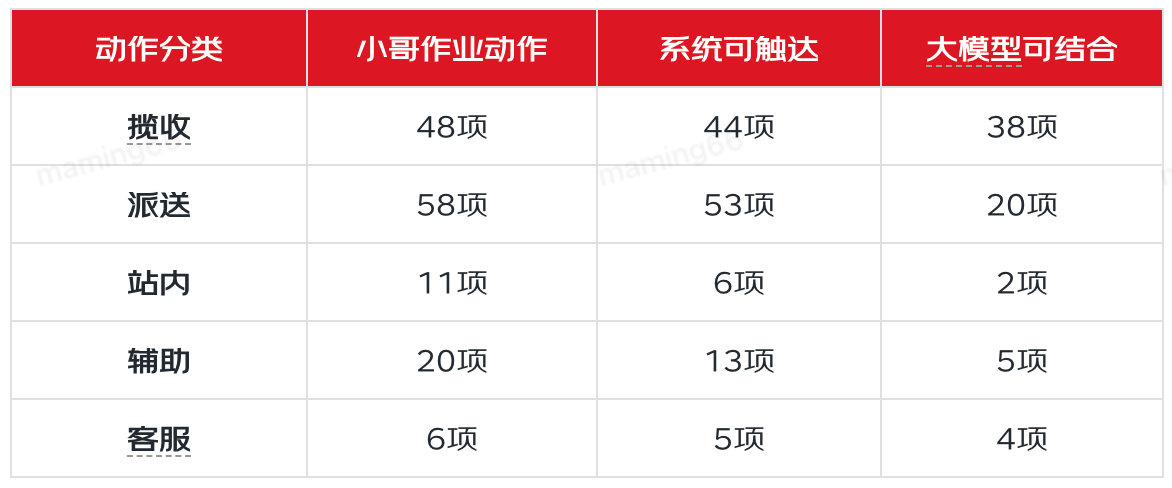
提升小哥作業(yè)效率,就需要了解小哥日常工作中有哪些作業(yè)動(dòng)作,然后根據(jù)作業(yè)動(dòng)作的特點(diǎn),來(lái)分析大模型有什么樣的機(jī)會(huì)來(lái)實(shí)現(xiàn)效率提升。通過(guò)調(diào)研和分析,小哥有143項(xiàng)作業(yè)動(dòng)作,可分類為:攬收、派送、站內(nèi)、輔助、客戶服務(wù)五大類,其中22項(xiàng)動(dòng)作是系統(tǒng)外的線下動(dòng)作,其他動(dòng)作中有69項(xiàng)被認(rèn)為有大模型結(jié)合的機(jī)會(huì)。在69項(xiàng)中我們選取了小哥攬收信息錄入、外呼、發(fā)短信、查詢運(yùn)單信息、聚合查詢、知識(shí)問(wèn)答、精準(zhǔn)提示等場(chǎng)景,通過(guò)大模型與大數(shù)據(jù)、GIS、語(yǔ)音等技術(shù)的結(jié)合,為小哥提供高效、易用的作業(yè)工具。
二、智能操作
小哥日常作業(yè)中,會(huì)頻繁給客戶打電話、發(fā)短信。出于客戶個(gè)人隱私安全的考慮,面單中隱藏了電話,所以外呼前需要小哥一次次在系統(tǒng)中查找電話,經(jīng)常是掃單號(hào)、在詳情頁(yè)點(diǎn)擊外呼按鈕、撥打電話等一系列動(dòng)作。通過(guò)小哥語(yǔ)音,大模型可以幫助我們分析小哥的意圖,識(shí)別出撥打電話,就可以通過(guò)語(yǔ)音中提到的運(yùn)單尾號(hào)、地址等特征完成外呼。
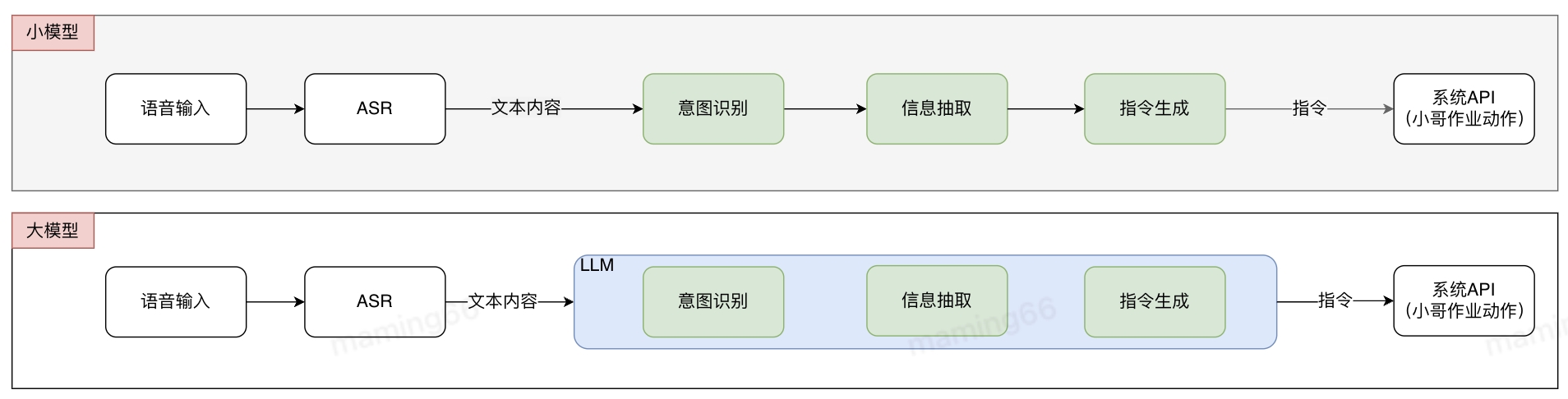
基于常規(guī)算法的解決方式是多個(gè)小模型組合成pipline,各小模型分別進(jìn)行標(biāo)注和訓(xùn)練,pipline存在誤差傳遞問(wèn)題。使用大模型后,不需要進(jìn)行標(biāo)記和訓(xùn)練,可以直接投入使用,減少了算法開(kāi)發(fā)的難度和周期,提升研發(fā)交付效率。在接收到小哥語(yǔ)音輸入后,語(yǔ)音識(shí)別(ASR)將語(yǔ)音轉(zhuǎn)化為文字,文字通過(guò)大模型意圖識(shí)別、信息抽取等方式生成指令,并調(diào)用系統(tǒng)API實(shí)現(xiàn)作業(yè)功能。
小哥智能助手中智能操作的實(shí)現(xiàn)方法如下:
在小哥發(fā)短信時(shí),需要查找電話,在短信界面編輯文字,通過(guò)語(yǔ)音+大模型,識(shí)別小哥需要給客戶發(fā)短信,并通過(guò)大模型對(duì)短信內(nèi)容進(jìn)行再加工,完成正式的短信編寫。
在填寫攬收信息時(shí),小哥需要頻繁切換電子稱、卷尺、工業(yè)機(jī)來(lái)完成稱重量方和信息錄入等作業(yè)動(dòng)作,同時(shí)攬收還需要填寫托寄物、時(shí)效產(chǎn)品、增值服務(wù)等內(nèi)容,如果通過(guò)語(yǔ)音+大模型,就可以減少工業(yè)機(jī)的多次輸入,會(huì)直接識(shí)別語(yǔ)音,分析出小哥的輸入意圖和內(nèi)容,將信息正確填寫。
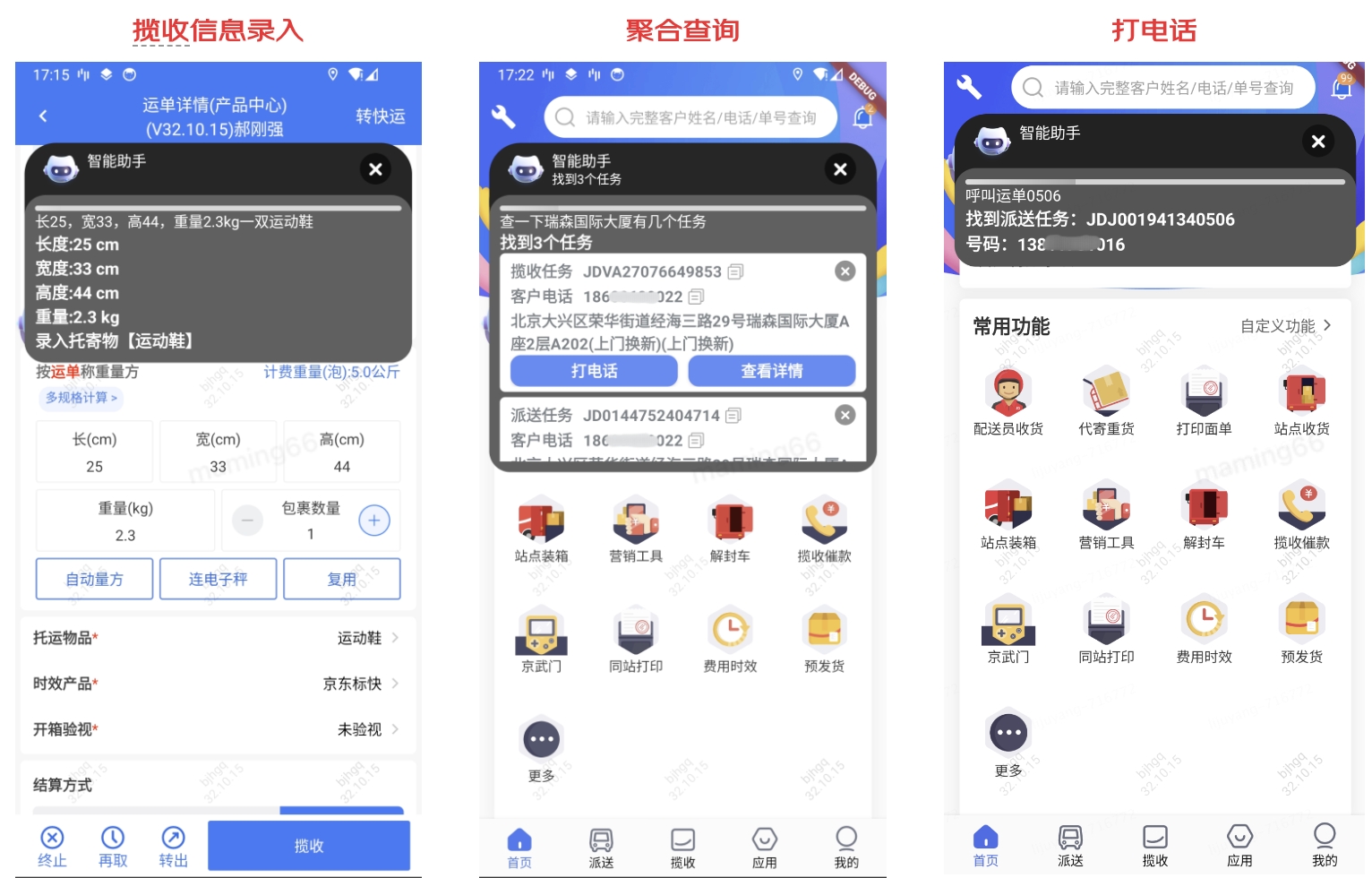
小哥查詢信息,也可以通過(guò)語(yǔ)音輸入,大模型識(shí)別意圖,進(jìn)行結(jié)果的反饋。如下是通過(guò)大模型實(shí)現(xiàn)的意圖識(shí)別示例:

三、智能問(wèn)答
業(yè)務(wù)快速發(fā)展的同時(shí),也對(duì)小哥作業(yè)提出了非常高的要求,據(jù)不完全統(tǒng)計(jì),僅終端相關(guān)文件就有915個(gè),如貨物處理規(guī)程、安全操作標(biāo)準(zhǔn)、KA客戶服務(wù)要求等等。對(duì)于小哥來(lái)說(shuō),記憶并掌握這么多業(yè)務(wù)要求無(wú)疑是一項(xiàng)巨大的挑戰(zhàn),小哥對(duì)標(biāo)準(zhǔn)作業(yè)流程或規(guī)范了解不全面,會(huì)影響服務(wù)質(zhì)量,也會(huì)影響一線作業(yè)效率,造成時(shí)間和成本浪費(fèi)。
小哥不了解流程、規(guī)則或者遇到運(yùn)營(yíng)問(wèn)題,目前通過(guò)問(wèn)站長(zhǎng)/站助/其他小哥、提報(bào)IT工單、聯(lián)系終端小秘等方式解決,但是被咨詢?nèi)艘矔?huì)因?yàn)閷?duì)業(yè)務(wù)規(guī)則、流程了解不全面而無(wú)法給出正確的回答。大模型出現(xiàn)后能夠更清晰的理解小哥的問(wèn)題和意圖,提供更加簡(jiǎn)潔的回答,提高回答的準(zhǔn)確率,降低了小哥的理解成本。
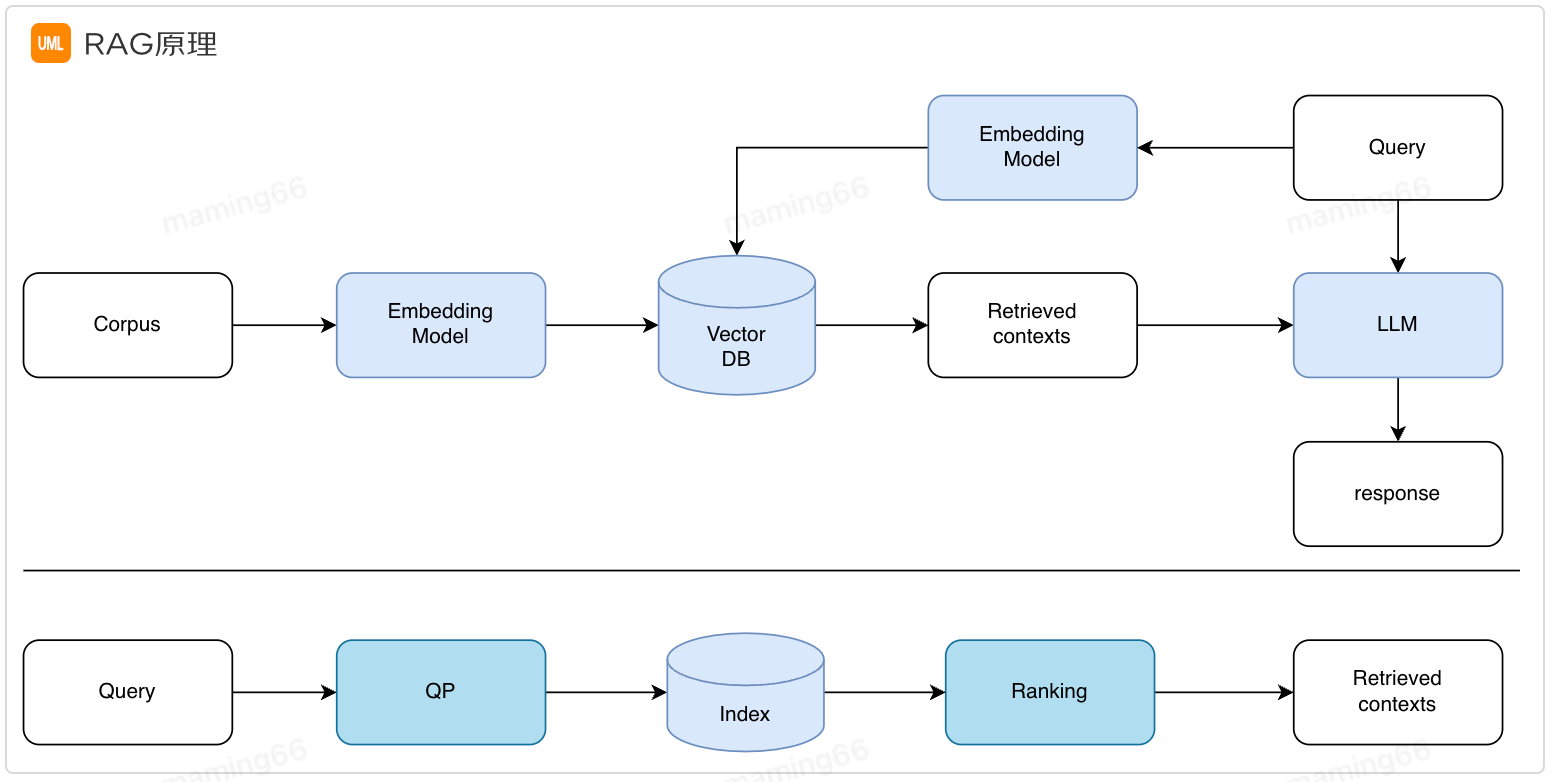
通過(guò)Prompt+檢索增強(qiáng)生成(RAG)實(shí)現(xiàn)了第一階段的智能問(wèn)答。之所以需要檢索增強(qiáng)生成是因?yàn)榇竽P湍壳按嬖诨糜X(jué)、知識(shí)過(guò)時(shí)等問(wèn)題,RAG實(shí)現(xiàn)從外部知識(shí)庫(kù)中檢索相關(guān)信息進(jìn)行回答,提高答案的準(zhǔn)確性。
小哥智能助手中智能問(wèn)答的實(shí)現(xiàn)方法如下:
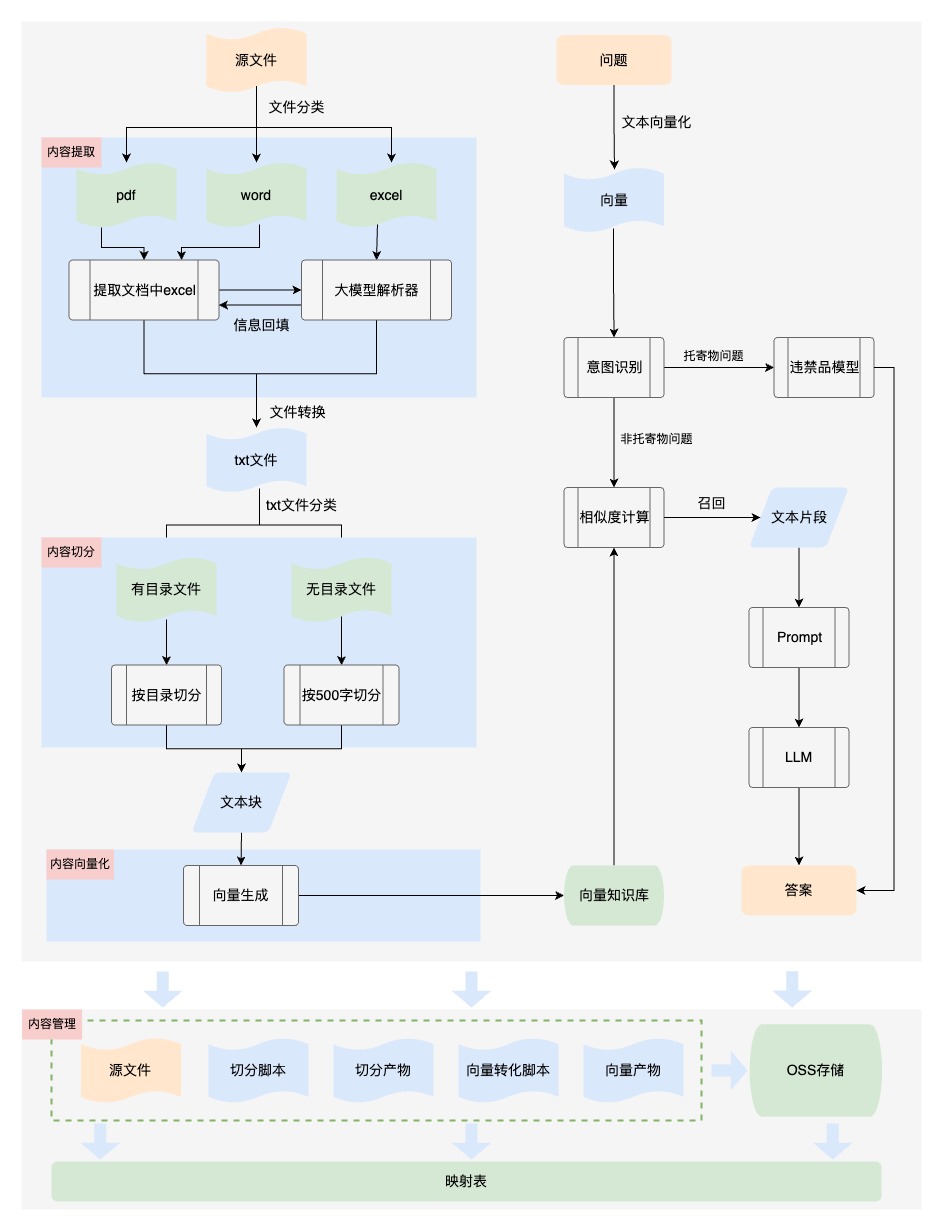
【內(nèi)容提取】業(yè)務(wù)文檔格式多樣,也包含各種內(nèi)容元素,比如包含表格的文檔,只進(jìn)行文字提取,無(wú)法保證內(nèi)容的結(jié)構(gòu)性、可讀性,輸入給大模型后無(wú)法理解,導(dǎo)致回答不準(zhǔn)確。所以我們對(duì)文件內(nèi)容進(jìn)行提取時(shí),將文件中的表格轉(zhuǎn)換為語(yǔ)義化的內(nèi)容,保證知識(shí)的可讀性。如下是業(yè)務(wù)文檔中的表格內(nèi)容:

【內(nèi)容切分】大模型能夠找到的相關(guān)知識(shí)的質(zhì)量和數(shù)量決定了回答的正確性和完整性,但是由于大模型token的數(shù)量限制,我們必須將文檔內(nèi)容切分。最初我們?cè)O(shè)置300個(gè)字符為一個(gè)知識(shí)塊進(jìn)行切分,從回答的效果上看,有很多問(wèn)題回答的內(nèi)容不完整,因?yàn)閱渭兊陌凑兆謹(jǐn)?shù)切分會(huì)破壞內(nèi)容的完整性,需要引入段落切分,保持段落完整性。

具體實(shí)現(xiàn)方法如下:
a. 內(nèi)容提取
第一版采用了DocumentLoaderUtil直接提取文本,將文本信息存入txt文件,具體實(shí)現(xiàn)方式如下:
from src.document_loader.document_loader import DocumentLoaderUtil processor = DocumentLoaderUtil(file_path=path_ori, pic_save_dir=dir_save_picture) texts = processor.load() texts = json.dumps(texts, ensure_ascii=False, indent=4) with open(os.path.join(dir_save_text, f"{os.path.basename(path_ori)}.txt"), "w") as f: f.write(texts)
優(yōu)化后處理DOCX文件:
1.讀取文檔信息時(shí),遇到表格,將表格單獨(dú)存儲(chǔ)到excel中,并在文本中使用特殊占位符標(biāo)注表格位置;
2.結(jié)合大模型對(duì)表格進(jìn)行語(yǔ)義化處理,使表格信息轉(zhuǎn)化成語(yǔ)義化文本;
3.根據(jù)特殊占位符將語(yǔ)義化文本回填至文檔對(duì)應(yīng)位置;
# 提取word中的表格 def extract_tables_to_excel(docx_path, excel_result_path): doc = Document(docx_path) docx_name = os.path.splitext(os.path.basename(docx_path))[0] folder_path = os.path.join(excel_result_path, docx_name) if not os.path.exists(folder_path): os.makedirs(folder_path) table_count = 0 for table in doc.tables: table_count += 1 data = [[cell.text for cell in row.cells] for row in table.rows] df = pd.DataFrame(data) # 保存DataFrame到Excel文件 excel_path = os.path.join(folder_path, f"【表格{table_count}】.xlsx") df.to_excel(excel_path, index=False, header=False) return folder_path # 根據(jù)占位符插入表格內(nèi)容 def replace_marker_in_txt(file_path, marker, replacement_text): # 讀取原始文件內(nèi)容 with open(file_path, 'r+', encoding='utf-8') as file: content = file.read() if replacement_text is None: replacement_text = '' # 替換特定標(biāo)記 content = content.replace(marker, replacement_text) file.seek(0) file.write(content) file.truncate() # txt中插入表格 def insertTable(folder_path, txt_path): for filename in os.listdir(folder_path): filepath = os.path.join(folder_path, filename) filename_without_extension, _ = os.path.splitext(filename) # 處理表格為語(yǔ)義化文本 result = excel_to_txt_single(filepath) # 占位符替換處理后的文本 replace_marker_in_txt(txt_path, filename_without_extension, result)
優(yōu)化后處理PDF文件:
1.讀取文檔信息提取表格,結(jié)合大模型對(duì)表格進(jìn)行語(yǔ)義化處理,使表格信息轉(zhuǎn)化成語(yǔ)義化文本;
2.尋找表格內(nèi)容并替換內(nèi)容;
# 處理pdf
def process_pdf(file_path, file_name, output_directory, save_directory, txt_file):
individual_file_names = save_pdf_tables_to_excel(file_path, file_name, output_directory)
content = DocumentLoaderUtil(file_path, save_directory).load()
content = [doc['page_content'] for doc in content]
with open(txt_file, 'w', encoding='utf-8') as f:
for line in content:
f.write(line + 'n')
replace_similar_module_in_txt(individual_file_names, txt_file, file_path)
# 特殊pdf二次處理
def handle_exception(extension, file_path, file_name, output_directory, save_directory):
try:
if extension == '.pdf':
individual_file_names = save_pdf_tables_to_excel(file_path, file_name, output_directory)
text, txt_file = convert_pdf_to_txt(file_path, os.path.join(save_directory, 'txt'))
else:
return
with open(txt_file, 'w', encoding='utf-8') as output_file:
output_file.write(text)
replace_similar_module_in_txt(individual_file_names, txt_file, file_path)
except FileNotFoundError as e:
with open('error.md', 'a') as file:
file.write(f"文件未找到錯(cuò)誤:{file_path}n")
except Exception as e:
with open('error.md', 'a') as file:
file.write(f"handle_exception處理異常時(shí)發(fā)生錯(cuò)誤:{file_path}n")
# 查找表格位置并替換為語(yǔ)義化內(nèi)容
def replace_similar_module_in_txt(individual_file_names, txt_file, file_path):
# 讀取文本文件的原始內(nèi)容
with open(txt_file, 'r', encoding='utf-8') as file:
txt_content = file.read()
for excel_path in individual_file_names:
excel_content = read_excel_content(excel_path)
# 查找最相似的片段
most_similar_part = find_most_similar_part(txt_content, excel_content, threshold=0.02)
if most_similar_part:
# 替換成語(yǔ)義化文本
replacement_text = excel_to_txt_single(excel_path)
txt_content = safe_replace(txt_content, most_similar_part, replacement_text)
else:
# 找不到時(shí) 將內(nèi)容追加到文檔后
replacement_text = excel_to_txt_single(excel_path)
txt_content += replacement_text
with open(txt_file, 'w', encoding='utf-8') as file:
file.write(txt_content)
b. 內(nèi)容切分
第一版按照字符數(shù)切分,固定300字符+15%的滑動(dòng)窗口。核心代碼如下:
from src.text_splitter.text_splitter import TextSplitterUtil
splitter_name = "RecursiveCharacterTextSplitter"
splitter_args = {
"chunk_size": 300,
"chunk_overlap": round(300 * 0.15),
"length_function": len,
}
splitter = TextSplitterUtil(splitter_name, splitter_args)
with open(os.path.join(dir_save_text, f"{os.path.basename(path_ori)}.txt")) as f:
texts = json.load(f)
texts_splitted = splitter.create_documents(
texts=[t["page_content"] for t in texts],
metadatas=[{"source": f"{path_ori}_{ti}"} for ti, t in enumerate(texts)],
)
print(texts_splitted)
優(yōu)化后按照段落+500字符+10%的重疊進(jìn)行切分。經(jīng)過(guò)測(cè)試回歸發(fā)現(xiàn),效果明顯提升。
import os
import json
import re
import csv
# 按優(yōu)先級(jí)順序存儲(chǔ)正則表達(dá)式
def find_all_matches(doc, patterns):
last_end = 0
matches = []
# 搜索所有的匹配項(xiàng)
for pattern in patterns:
for match in pattern.finditer(doc):
start, end = match.span()
# 如果當(dāng)前匹配塊前有未匹配的內(nèi)容,則將其作為單獨(dú)的匹配塊
if start > last_end:
matches.append(doc[last_end:start])
matches.append(match.group())
last_end = end
if last_end < len(doc):
matches.append(doc[last_end:])
return matches
def trim_regex_title(path_ori):
with open(path_ori, 'r', encoding='utf-8') as file:
document = file.read()
# 使用非貪婪匹配 .*? 來(lái)捕獲標(biāo)題后的內(nèi)容,直到遇到下一個(gè)標(biāo)題或文檔末尾
# 初始化 matches 為空列表,用于存儲(chǔ)找到的匹配項(xiàng)
# 按優(yōu)先級(jí)順序存儲(chǔ)正則表達(dá)式
patterns = [
re.compile(r'((?:一、|二、|三、|四、|五、|六、|七、|八、|九、|十、|d+.)[^n]+)([sS]*?)(?=n(?:一、|二、|三、|四、|五、|六、|七、|八、|九、|十、|d+.)[^n]+|$)'),
re.compile(r'(n.+?)(?=n.+|$)'),
re.compile(r'(?s)(nd+.d+s+.*?)(?=nd+.d+s+|$)')
]
matches = find_all_matches(document, patterns)
page_contents = []
for match in matches:
section_content = match.strip()
page_contents.append({
'page_content': section_content,
'metadata': {
'source': path_ori,
},
})
# 組裝成500字
# 創(chuàng)建一個(gè)空列表用于存儲(chǔ)處理后的page_checks
page_checks = []
# 用于累積不足500字符的內(nèi)容
accumulated_content = ""
for page in page_contents:
page_content = page['page_content']
# 如果當(dāng)前行內(nèi)容加上累積的內(nèi)容超過(guò)500字符,則需要分割
if len(accumulated_content) + len(page_content) > 500:
# 如果之前有累積的內(nèi)容,先處理
if accumulated_content:
page_check_dict = {
"page_content": accumulated_content,
"metadata": {"source": path_ori}
}
page_checks.append(page_check_dict)
accumulated_content = ""
# 處理當(dāng)前行的內(nèi)容
start_index = 0
while start_index < len(page_content):
end_index = min(start_index + 500, len(page_content))
page_check_dict = {
"page_content": page_content[start_index:end_index],
"metadata": {"source": path_ori}
}
page_checks.append(page_check_dict)
# 更新start_index以便獲取下一個(gè)500字符的片段,與前一個(gè)片段有50字符重疊
start_index += 450
else:
# 如果當(dāng)前累積內(nèi)容與新行內(nèi)容總和不超過(guò)500字符 繼續(xù)累積內(nèi)容
if len(accumulated_content) + len(page_content) < 500:
accumulated_content += page_content
else:
# 累積內(nèi)容已足夠,創(chuàng)建一個(gè)page_check
page_check_dict = {
"page_content": accumulated_content,
"metadata": {"source": path_ori}
}
page_checks.append(page_check_dict)
accumulated_content = page_content
# 處理文件末尾的累積內(nèi)容
if accumulated_content:
page_check_dict = {
"page_content": accumulated_content,
"metadata": {"source": path_ori}
}
page_checks.append(page_check_dict)
return page_checks
c. 向量化 Embedding
用戶的問(wèn)題往往非常口語(yǔ)化,而文檔和知識(shí)往往都是非常的專業(yè)和正式。比如用戶的問(wèn)題是:“我去年已經(jīng)離職了,現(xiàn)在自己干,如何交公積金?”。從文檔中需要檢索出“靈活就業(yè)人員”辦理公積金的材料和流程。內(nèi)容檢索只能進(jìn)行精確匹配,對(duì)于近義詞、語(yǔ)義關(guān)聯(lián)詞的檢索效果較差。文本向量化后,搜索就可以通過(guò)計(jì)算詞語(yǔ)之間的相似度,實(shí)現(xiàn)對(duì)近義詞和語(yǔ)義關(guān)聯(lián)詞的模糊匹配,從而擴(kuò)大了搜索的覆蓋范圍并提高了準(zhǔn)確性。Embedding 就是將這些離散的文本內(nèi)容轉(zhuǎn)換成連續(xù)的向量。我們將向量存儲(chǔ)到Vearch庫(kù)中,選擇相似度top9的向量對(duì)應(yīng)的內(nèi)容文本輸入給大模型,通過(guò)Prompt進(jìn)行回答。
from src.embedding.get_embedding import get_openai_embedding
model_key = "xxxx"
model_name = "text-embedding-ada-002-2"
texts_embedding = [
get_openai_embedding(
text=t.page_content, model_name=model_name, model_key=model_key
)
for t in texts_splitted
]
d. 內(nèi)容管理
我們?yōu)橄蛄縿?chuàng)建索引,以便于檢索和更新,同時(shí)將各階段產(chǎn)物包括源文件、切分腳本、切分文本塊、向量嵌入腳本、向量存儲(chǔ)通過(guò)oss進(jìn)行管理,并建立映射表。當(dāng)業(yè)務(wù)知識(shí)進(jìn)行更新時(shí),可以對(duì)向量庫(kù)中的內(nèi)容進(jìn)行更新替換。

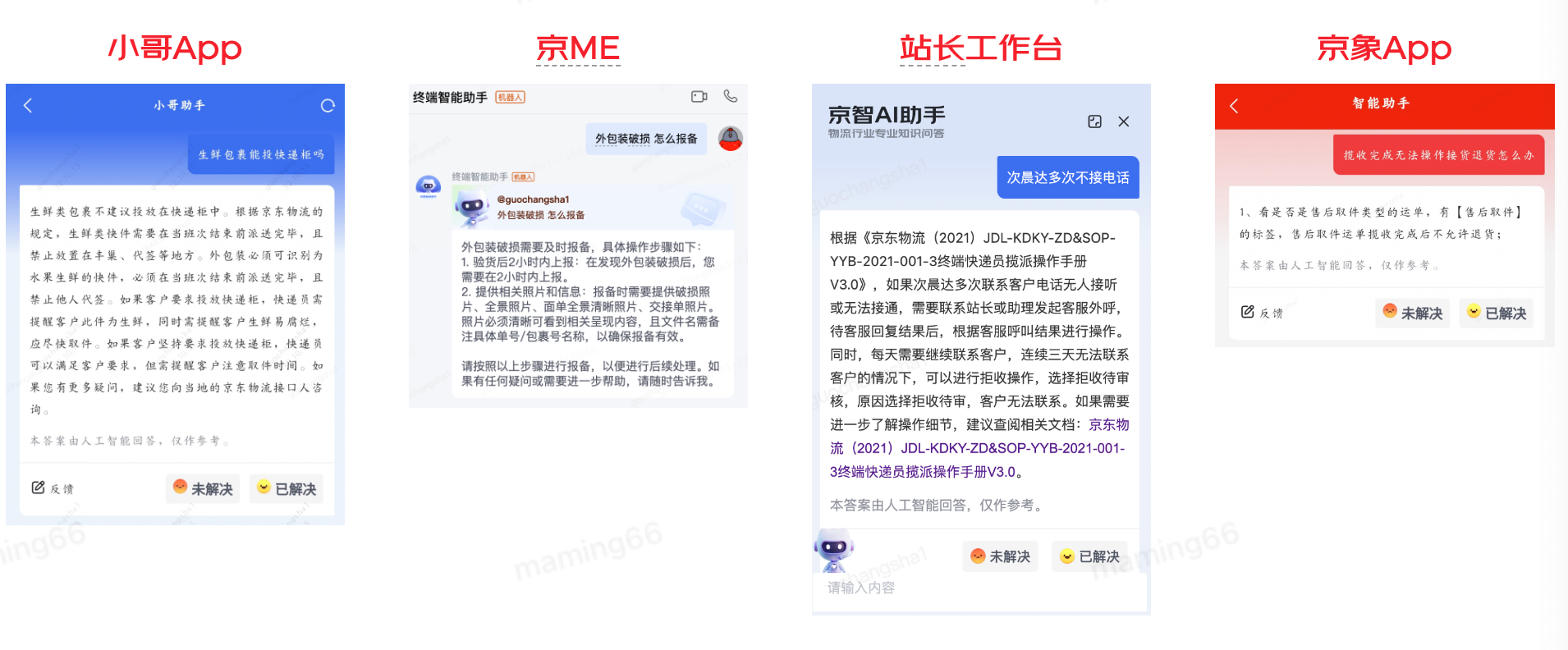
通過(guò)持續(xù)優(yōu)化智能問(wèn)答準(zhǔn)確率90%,目前已接入小哥App、京ME、站長(zhǎng)工作臺(tái)、京象App等,功能如下:
四、智能提示
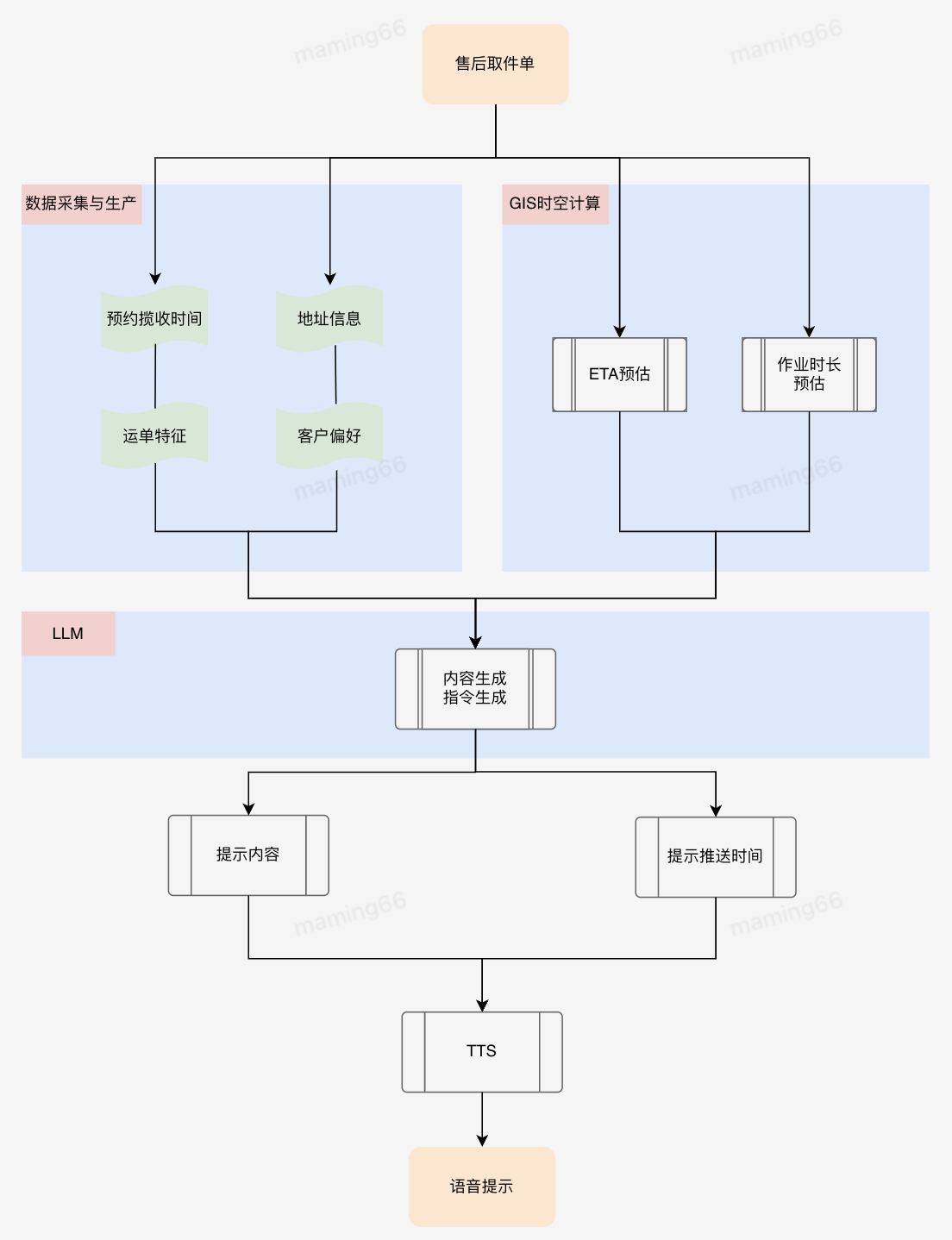
小哥作業(yè)流程規(guī)范,以及履約中的時(shí)效預(yù)測(cè)和提醒等等,都可以使用大模型將復(fù)雜的業(yè)務(wù)文檔和流程規(guī)范轉(zhuǎn)化為小哥容易理解和執(zhí)行的操作提示,在任務(wù)下發(fā)、臨期提醒方面也可以發(fā)揮大模型的理解和總結(jié)能力,使小哥關(guān)注到最需要關(guān)注的信息,幫助小哥做進(jìn)一步的作業(yè)決策。比如KA商家對(duì)攬收打包方式、交接方式有各自不同的定制化需求,如果通過(guò)小哥記憶或者查資料的方式了解攬收打包要求,非常麻煩且耗時(shí),利用大模型總結(jié)KA商家操作要求,通過(guò)語(yǔ)音合成(TTS)引導(dǎo)小哥按照客戶要求作業(yè),能夠提升業(yè)務(wù)的履約質(zhì)量。

?
小哥智能助手中智能提示的實(shí)現(xiàn)方法,以售后取件單下發(fā)為例:
提示的差異對(duì)比如下:

五、智能體
以GPTs為代表的大模型智能體帶給了人們非常震撼的功能效果,引起的社會(huì)關(guān)注度遠(yuǎn)超之前任何一項(xiàng)技術(shù)的出現(xiàn)。但是OpenAI也坦言在智能體這個(gè)領(lǐng)域,自己并沒(méi)有比其他公司掌握的更多,這也是目前很多科技公司在同一起跑線上奮力奔跑的機(jī)遇。
An agent is anything that can be viewed as perceiving its environment through sensors and acting upon that environment through actuators.
—— Stuart J. Russell and Peter Norvig
在智能操作、問(wèn)答、提示的實(shí)踐過(guò)程中,我們積累了模型、Prompt、知識(shí)庫(kù)、微調(diào)等相關(guān)經(jīng)驗(yàn),但是在模型編排、領(lǐng)域模型訓(xùn)練、安全性等方面需要進(jìn)一步學(xué)習(xí)和應(yīng)用。同時(shí)我們也在探索終端智能體對(duì)業(yè)務(wù)異常分析、定位和解決的能力。
審核編輯 黃宇
-
機(jī)器人
+關(guān)注
關(guān)注
209文章
27718瀏覽量
203618 -
GPT
+關(guān)注
關(guān)注
0文章
342瀏覽量
15151 -
OpenAI
+關(guān)注
關(guān)注
9文章
961瀏覽量
6199 -
大模型
+關(guān)注
關(guān)注
2文章
2053瀏覽量
1776
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
神話游戲熱浪推動(dòng)文化輸出,第一線全棧云網(wǎng)安服務(wù)助力游戲企業(yè)加速全球化部署

大語(yǔ)言模型:原理與工程實(shí)踐+初識(shí)2
【大語(yǔ)言模型:原理與工程實(shí)踐】探索《大語(yǔ)言模型原理與工程實(shí)踐》2.0
【大語(yǔ)言模型:原理與工程實(shí)踐】大語(yǔ)言模型的基礎(chǔ)技術(shù)
【大語(yǔ)言模型:原理與工程實(shí)踐】揭開(kāi)大語(yǔ)言模型的面紗
【大語(yǔ)言模型:原理與工程實(shí)踐】探索《大語(yǔ)言模型原理與工程實(shí)踐》
名單公布!【書籍評(píng)測(cè)活動(dòng)NO.31】大語(yǔ)言模型:原理與工程實(shí)踐
名單公布!【書籍評(píng)測(cè)活動(dòng)NO.30】大規(guī)模語(yǔ)言模型:從理論到實(shí)踐
應(yīng)用大模型提升研發(fā)效率的實(shí)踐與探索

Dynamics 365 Field Service:為每位一線員工配備隨身智能助手

芯知識(shí) | 語(yǔ)音芯片支持一線串口和兩線串口的作用與應(yīng)用優(yōu)勢(shì)

STM32用一線式驅(qū)動(dòng)SD NAND,SDIO的一線式驅(qū)動(dòng)






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論