 深度學習與傳統機器學習的對比
深度學習與傳統機器學習的對比
在人工智能的浪潮中,機器學習和深度學習無疑是兩大核心驅動力。它們各自以其獨特的方式推動著技術的進步,為眾多領域帶來了革命性的變化。然而,盡管它們都屬于機器學習的范疇,但深度學習和傳統機器學習在方法、應用、優勢等方面卻存在顯著的差異。本文將對這兩者進行深入的對比和分析。
一、定義與基礎
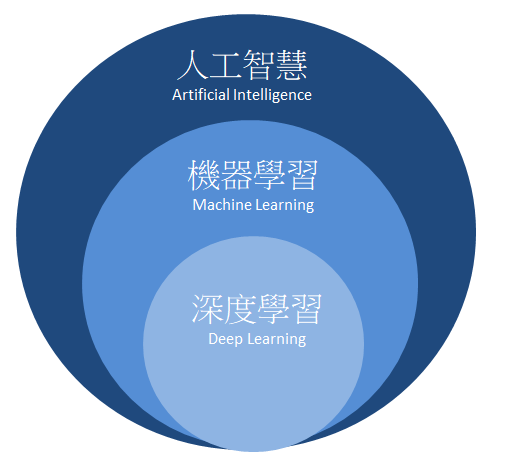
機器學習是一種讓計算機系統能夠自動學習并改進的技術,它基于大量的數據,通過算法來發現數據中的規律,從而對新的數據進行預測或分類。機器學習可以分為監督式學習、無監督式學習和半監督式學習三種主要類型。而深度學習,作為機器學習的一個子集,特指利用深層神經網絡進行學習的方法。與傳統的機器學習相比,深度學習在神經網絡的結構和層次上更為復雜,能夠處理更加復雜的數據和任務。
二、算法與模型
傳統機器學習的算法主要包括決策樹、支持向量機、樸素貝葉斯等。這些算法通常基于數學和統計的原理,通過人工設計的特征進行數據的分類和預測。而深度學習則采用了神經網絡這一特殊的算法,它可以模擬人腦的結構和工作方式,通過多層神經元之間的連接和權重的調整,自動學習數據的特征表示。這種自動特征學習的能力使得深度學習在處理圖像、聲音、自然語言等復雜數據時具有顯著的優勢。
在模型方面,傳統機器學習模型通常較為簡單,適用于中小規模的問題。而深度學習模型則更為復雜,包含多個隱藏層和大量的參數。這種復雜的模型結構使得深度學習能夠處理更加復雜的任務和數據,但同時也對計算資源和數據量的需求更高。
三、數據需求與處理
傳統機器學習對數據量的需求相對較小,能夠在小數據集上表現出色。這主要得益于其基于數學和統計的原理,以及人工設計的特征提取方法。然而,這種方法在處理大規模和復雜數據時往往顯得力不從心。相比之下,深度學習對大量數據的需求較大,尤其在處理圖像、語音等復雜數據時更為明顯。這是因為深度學習需要通過大量的數據來訓練和調整模型的參數,從而使其能夠自動學習到數據的特征表示。
在數據處理方面,傳統機器學習通常需要手動進行特征工程,即從原始數據中提取有意義的特征。這不僅需要豐富的專業知識和經驗,而且容易引入主觀性和誤差。而深度學習則能夠自動從原始數據中學習特征表示,無需人工干預。這種自動特征學習的能力使得深度學習在處理復雜數據時更加高效和準確。
四、應用與優勢
傳統機器學習已經在許多領域得到了廣泛的應用,如金融、醫療、電商等。這些領域通常具有明確的數據特征和業務需求,可以通過傳統的機器學習算法進行有效地分類和預測。然而,在面對更加復雜的數據和任務時,如圖像識別、語音識別等,傳統機器學習往往難以勝任。這時,深度學習就顯示出了其獨特的優勢。
深度學習在圖像識別、語音識別、自然語言處理等領域中取得了顯著的成果。它能夠自動學習到數據的特征表示,從而捕捉到數據中的隱含模式和規律。這種能力使得深度學習在處理復雜數據時具有更高的準確率和效率。同時,深度學習還具有很強的適應性和通用性,能夠處理各種類型的數據和任務。
然而,深度學習也存在一些局限性。例如,它通常需要大量的數據和計算資源來訓練模型,這使得它在一些資源有限的環境下難以應用。此外,深度學習的模型結構較為復雜,往往難以解釋和理解其決策過程。這使得深度學習在一些需要可解釋性的應用中受到限制。
五、總結與展望
綜上所述,深度學習和傳統機器學習在方法、應用、優勢等方面存在顯著的差異。它們各自具有獨特的特點和優勢,在不同的場景和任務中發揮著重要的作用。隨著人工智能技術的不斷發展,深度學習和傳統機器學習將繼續相互補充、相互促進,共同推動人工智能技術的進步和應用。
在未來,我們可以期待深度學習和傳統機器學習在更多領域得到應用和發展。例如,在醫療健康領域,深度學習可以用于疾病的診斷和治療方案的制定;在智能交通領域,深度學習可以用于交通流量預測和智能調度等方面。同時,隨著計算能力的提升和數據量的增加,深度學習的性能和效率將得到進一步提升,為更多領域帶來更大的價值。
-
計算機
+關注
關注
19文章
7418瀏覽量
87712 -
人工智能
+關注
關注
1791文章
46845瀏覽量
237535 -
深度學習
+關注
關注
73文章
5492瀏覽量
120975
發布評論請先 登錄
相關推薦
探討機器學習與深度學習基本概念與運算過程
圖像分類的方法之深度學習與傳統機器學習

機器學習與深度學習之間比較
深度學習與機器學習的區別是什么
機器學習和深度學習有什么區別?


機器學習和深度學習的區別
深度學習算法和傳統機器視覺助力工業外觀檢測





 工商網監
工商網監
評論