") 后摩智能推出邊端大模型AI芯片M30,展現(xiàn)出存算一體架構優(yōu)勢
后摩智能推出邊端大模型AI芯片M30,展現(xiàn)出存算一體架構優(yōu)勢
電子發(fā)燒友網(wǎng)報道(文/李彎彎)近日,后摩智能推出基于存算一體架構的邊端大模型AI芯片——后摩漫界??M30,最高算力100TOPS,典型功耗12W。為了進一步提升部署的便捷性,后摩智能還同步推出了基于M30芯片的智算模組(SoM)和力謀??AI加速卡。
后摩智能存算一體架構芯片產(chǎn)品
后摩智能是一家專注于存算一體芯片技術的創(chuàng)新型企業(yè),成立于2020年。該公司基于先進的存算一體技術和存儲工藝,致力于突破芯片的性能與功耗瓶頸。存算一體架構將存儲和計算功能融合,比傳統(tǒng)架構更接近人腦的計算方式,具備遠高于傳統(tǒng)方式的計算效率。
2023年5月10日,后摩智能發(fā)布了其第一款芯片產(chǎn)品——后摩鴻途??H30智駕芯片,該芯片最高物理算力達到256TOPS,這一數(shù)值略高于英偉達Orin-X的254TOPS,展現(xiàn)出強大的計算能力。在Int8數(shù)據(jù)精度下,其AI核心IPU能效比高達15Tops/W,是傳統(tǒng)架構芯片的7倍以上,實現(xiàn)了高效的AI計算。
后摩鴻途??H30智駕芯片典型功耗僅為35W,這使得鴻途??H30在提供高算力的同時,也保持了較低的能耗水平。SoC能效比達到7.3Tops/W,體現(xiàn)了存算一體架構在提升能效比方面的優(yōu)勢。鴻途??H30獲得了ASIL D級功能安全流程認證,這是車規(guī)安全等級中的最高標準,確保了芯片在智能駕駛應用中的可靠性和穩(wěn)定性。
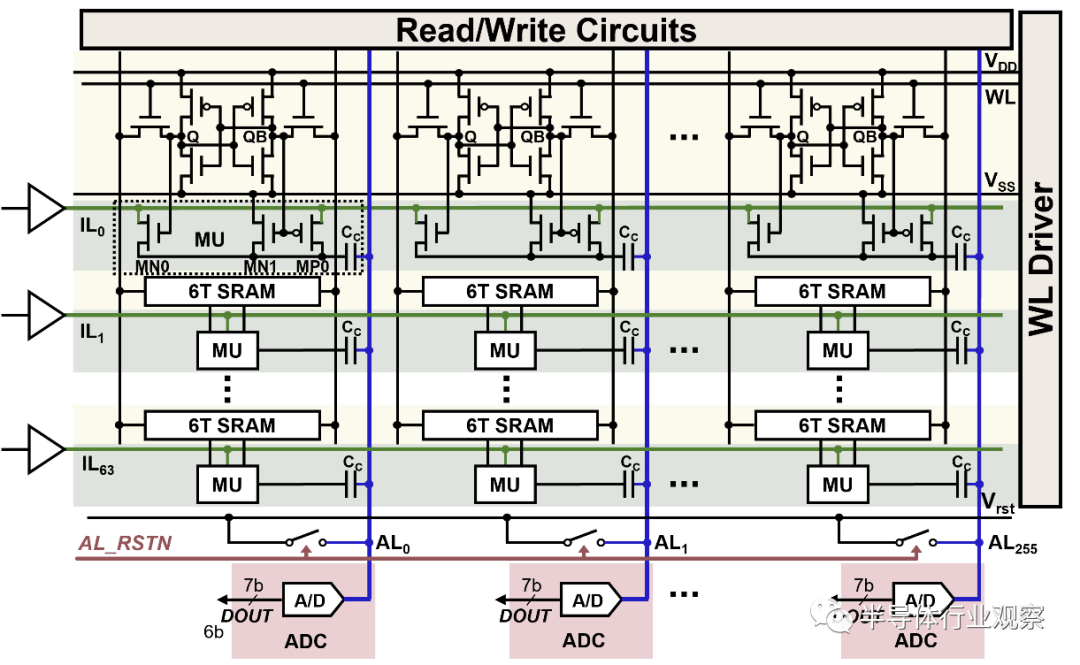
鴻途??H30采用存算一體架構,將存儲和計算功能融合,比傳統(tǒng)架構更接近人腦的計算方式,具備遠高于傳統(tǒng)方式的計算效率。基于SRAM的純數(shù)字設計,實現(xiàn)存內(nèi)運算,在存儲器內(nèi)能完全實現(xiàn)數(shù)據(jù)處理,打破了傳統(tǒng)芯片性能瓶頸并提升了能效比。
此外,該芯片基于自研IPU(Intelligence Processing Unit)架構——天樞架構,通過多核、多硬件線程以及雙環(huán)拓撲總線的設計,保證了計算資源利用效率的同時可以靈活擴展算力。支持外擴Memory,最高帶寬為128GB/s,以及16路FHD Encoder/Decoder和PCIe 4.0等多種接口,滿足了不同應用場景的需求。
鴻途??H30智駕芯片專為智能駕駛設計,支持運行點云網(wǎng)絡、BEV網(wǎng)絡等智能駕駛主流算法,能夠支持L4級自動駕駛。該芯片已經(jīng)成功在無人配送車上完成路測,展現(xiàn)了避讓前方行人、識別紅綠燈等智能駕駛能力。基于鴻途??H30,后摩智能還推出了力馭?智能駕駛計算平臺,為智能駕駛提供了更充沛的算力支持。
近期,后摩智能推出其第二款產(chǎn)品——后摩漫界?M30邊端大模型AI芯片,該芯片在邊端設備的大模型部署中展現(xiàn)出了卓越的性能和能效比。
后摩漫界??M30最高算力達到100TOPS,這一強大的算力使得M30能夠輕松應對邊端側(cè)大模型部署對高算力的需求。其典型功耗僅為12W,實現(xiàn)了高性能與低功耗的完美融合,為邊端設備提供了更長的續(xù)航時間和更低的能耗成本。
據(jù)介紹,M30是一款通用的邊端大模型AI芯片,能夠支持多種大模型,包括但不限于ChatGLM、Llama2、通義千問等。這一特性使得M30在處理復雜AI任務時具有更高的靈活性和適應性。在運行Qwen1.5-7B-Chat等大模型時,M30的運行性能可達15-20 Tokens/s,這一表現(xiàn)足以證明其在處理復雜AI任務時的卓越能力。
為了進一步提升部署的便捷性,后摩智能還同步推出了基于M30芯片智算模組(SoM)和力謀??AI加速卡。智算模組(SoM),支持PCIe EP模式,以其小巧的體積、強勁的性能和極低的功耗,成為小型化設備和功耗敏感嵌入式場景的理想選擇。
力謀??AI加速卡,作為標準的半高半長PCIe加速卡,能在PC、一體機和服務器中實現(xiàn)快速部署。支持主動散熱和被動散熱兩種模式,確保設備在不同環(huán)境下的穩(wěn)定運行。
后摩漫界?M30芯片具有高性能、低功耗和通用性特點,可廣泛應用于多個領域,包括AI PC、邊緣AI一體機、智能座艙、商用顯示、智能融合網(wǎng)關、NAS(網(wǎng)絡附加存儲)等。
存算一體架構在邊端大模型AI芯片中的優(yōu)勢
隨著AI大模型部署需求從云端迅速向端側(cè)和邊緣側(cè)設備遷移,AI芯片的性能、功耗和響應速度面臨前所未有的挑戰(zhàn)。基于存算一體架構的后摩漫界??M30芯片在這方面表現(xiàn)出顯著的優(yōu)勢,它兼具高性能與低功耗特性,可滿足邊端側(cè)大模型部署對高效率和實時性的嚴苛要求。
具體來看,在性能提升方面,存算一體架構通過將存儲單元與計算單元集成在同一片芯片上,實現(xiàn)了計算與存儲的緊密耦合,從而提高了數(shù)據(jù)處理的速度和效率。同時,由于數(shù)據(jù)在芯片內(nèi)部直接進行計算,避免了傳統(tǒng)架構中數(shù)據(jù)在存儲器和處理器之間頻繁傳輸所產(chǎn)生的延遲。這對于需要實時響應的邊端應用場景尤為重要。
在功耗降低方面,存算一體架構減少了數(shù)據(jù)傳輸?shù)哪芰繐p耗,使得芯片在保持高性能的同時,能夠顯著降低功耗。而且,采用非易失性存儲介質(zhì)(如ReRAM)的存算一體芯片,在不需要進行數(shù)據(jù)讀寫時,可以保持極低的靜態(tài)功耗,甚至為零功耗。
在數(shù)據(jù)處理效率方面,存算一體架構避免了傳統(tǒng)架構中數(shù)據(jù)在存儲器和處理器之間的大量搬運,減少了數(shù)據(jù)傳輸?shù)膸捫枨螅岣吡藬?shù)據(jù)處理的效率。存算一體架構能夠支持更多的并行計算任務,提高了芯片的整體處理能力和吞吐量。
在成本控制方面,存算一體架構可以在不依賴先進制程的前提下,通過優(yōu)化芯片設計和算法,實現(xiàn)較高的算力和能效比。這有助于降低芯片的生產(chǎn)成本,提高市場競爭力。同時,由于芯片內(nèi)部集成了存儲單元,減少了對外部存儲器的依賴,從而降低了系統(tǒng)的整體成本。
從應用場景方面來看,存算一體架構特別適用于對算力、功耗和實時性有較高要求的邊端設備,如智能手機、可穿戴設備、智能家居設備等。在大數(shù)據(jù)處理和AI推理等應用場景中,存算一體架構能夠提供高效的數(shù)據(jù)處理能力和低延遲的響應速度,滿足復雜計算任務的需求。
寫在最后
存算一體架構的邊端大模型AI芯片,如后摩漫界??M30,通過創(chuàng)新的設計實現(xiàn)了高性能、低功耗和實時性的完美結合。隨著AI大模型應用的不斷擴展和邊端設備需求的增加,這種架構的芯片將在未來發(fā)揮更加重要的作用,推動AI技術在更多領域的深入應用和發(fā)展。
-
AI芯片
+關注
關注
17文章
1807瀏覽量
34584 -
后摩智能
+關注
關注
0文章
20瀏覽量
1148 -
大模型
+關注
關注
2文章
2053瀏覽量
1774
發(fā)布評論請先 登錄
相關推薦
后摩智能與聯(lián)想攜手共創(chuàng)AI PC新紀元
后摩智能與聯(lián)想集團簽署戰(zhàn)略協(xié)議 共同探索AI PC技術創(chuàng)新與應用
存算一體AI芯片企業(yè)后摩智能完成數(shù)億元戰(zhàn)略融資
知存科技助力AI應用落地:WTMDK2101-ZT1評估板實地評測與性能揭秘
探索存內(nèi)計算—基于 SRAM 的存內(nèi)計算與基于 MRAM 的存算一體的探究


后摩智能與優(yōu)控智行共同打造智能汽車硬件平臺及綜合解決方案

什么是存算一體芯片?存算一體芯片的優(yōu)勢和應用領域






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論