 化工廠液體泄漏識別預警算法
化工廠液體泄漏識別預警算法
化工廠液體泄漏識別預警基于圖像識別算法是計算機視覺的基礎算法,例如VGG,GoogLeNet,ResNet等,化工廠液體泄漏識別這類算法主要是判斷圖片中目標的種類液體泄漏識別預警自動識別監控視頻中機械管道是否存在液體泄漏行為。如檢測到液體泄漏,立即反饋給后臺人員及時處理。
要對圖片中一個物體進行分類,首先要解決如何從圖片中發現這個物體,最直觀的方法就是用不同尺寸的方框進行掃描,這個方框可以被稱為window,和要得到的物體尺寸是兩回事。這就是RNN的方法,但這種方法計算量大,因此出現了Yolo,其核心思想就體現在如何從一張圖像準確獲取目標的方法上。
至于目標檢測的用處,現在最大的場景就是無人駕駛,在無人駕駛中,需要實時檢測出途中的人、車、物體、信號燈、交通標線等,再通過融合技術將各類傳感器獲得的數據提供給控制中心進行決策。而目標檢測相當于無人駕駛系統的眼睛。在目標檢測技術領域,有包含region proposals提取階段的兩階段(two-stage)檢測框架如R-CNN/Fast-RCNN/R-FCN等。
卷積神經網絡訓練與硬件加速器實現圖像識別系統的第二部分是 CNN 加速器,CNN 加速器的實現包含訓練與推理兩個階段。一是卷積神經網絡訓練,提取相應的權重值和偏置值,即訓練階段。二是根據網絡模型實現卷積神經網絡,并做硬件加速,提升卷積神經網絡運算的速率,即推理階段。CNN 網絡訓練完畢后,采用 PyTorch 神經網絡框架將卷積神經網絡模型及其參數保存在pt 文件中。而 PyTorch 神經網絡框架提供了 load 方法,可以很方便地讀取文件中保存的參數,但輸出格式為張量,無法直接使用。故先轉換為 Numpy[61]的數據格式,再提取其中的參數,以固定的格式保存數據。
class Detect(nn.Module): stride = None # strides computed during build onnx_dynamic = False # ONNX export parameter def __init__(self, nc=80, anchors=(), ch=(), inplace=True): # detection layer super().__init__() self.nc = nc # number of classes self.no = nc + 5 # number of outputs per anchor self.nl = len(anchors) # number of detection layers self.na = len(anchors[0]) // 2 # number of anchors self.grid = [torch.zeros(1)] * self.nl # init grid self.anchor_grid = [torch.zeros(1)] * self.nl # init anchor grid self.register_buffer('anchors', torch.tensor(anchors).float().view(self.nl, -1, 2)) # shape(nl,na,2) self.m = nn.ModuleList(nn.Conv2d(x, self.no * self.na, 1) for x in ch) # output conv self.inplace = inplace # use in-place ops (e.g. slice assignment) def forward(self, x): z = [] # inference output for i in range(self.nl): x[i] = self.m[i](x[i]) # conv bs, _, ny, nx = x[i].shape # x(bs,255,20,20) to x(bs,3,20,20,85) x[i] = x[i].view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous() if not self.training: # inference if self.onnx_dynamic or self.grid[i].shape[2:4] != x[i].shape[2:4]: self.grid[i], self.anchor_grid[i] = self._make_grid(nx, ny, i) y = x[i].sigmoid() if self.inplace: y[..., 0:2] = (y[..., 0:2] * 2 - 0.5 + self.grid[i]) * self.stride[i] # xy y[..., 2:4] = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i] # wh else: # for YOLOv5 on AWS Inferentia https://github.com/ultralytics/yolov5/pull/2953 xy = (y[..., 0:2] * 2 - 0.5 + self.grid[i]) * self.stride[i] # xy wh = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i] # wh y = torch.cat((xy, wh, y[..., 4:]), -1) z.append(y.view(bs, -1, self.no)) return x if self.training else (torch.cat(z, 1), x) def _make_grid(self, nx=20, ny=20, i=0): d = self.anchors[i].device if check_version(torch.__version__, '1.10.0'): # torch>=1.10.0 meshgrid workaround for torch>=0.7 compatibility yv, xv = torch.meshgrid([torch.arange(ny).to(d), torch.arange(nx).to(d)], indexing='ij') else: yv, xv = torch.meshgrid([torch.arange(ny).to(d), torch.arange(nx).to(d)]) grid = torch.stack((xv, yv), 2).expand((1, self.na, ny, nx, 2)).float() anchor_grid = (self.anchors[i].clone() * self.stride[i]) \ .view((1, self.na, 1, 1, 2)).expand((1, self.na, ny, nx, 2)).float() return grid, anchor_grid
-
圖像識別
+關注
關注
9文章
519瀏覽量
38235 -
人工智能
+關注
關注
1791文章
46853瀏覽量
237543 -
預警
+關注
關注
1文章
45瀏覽量
14453
發布評論請先 登錄
相關推薦
煤化工廠人員定位系統解決方案
化工廠如何實現人員定位及軌跡管理?
化工廠室內外4G/5G+藍牙+GPS/北斗RTK人員定位系統解決方案
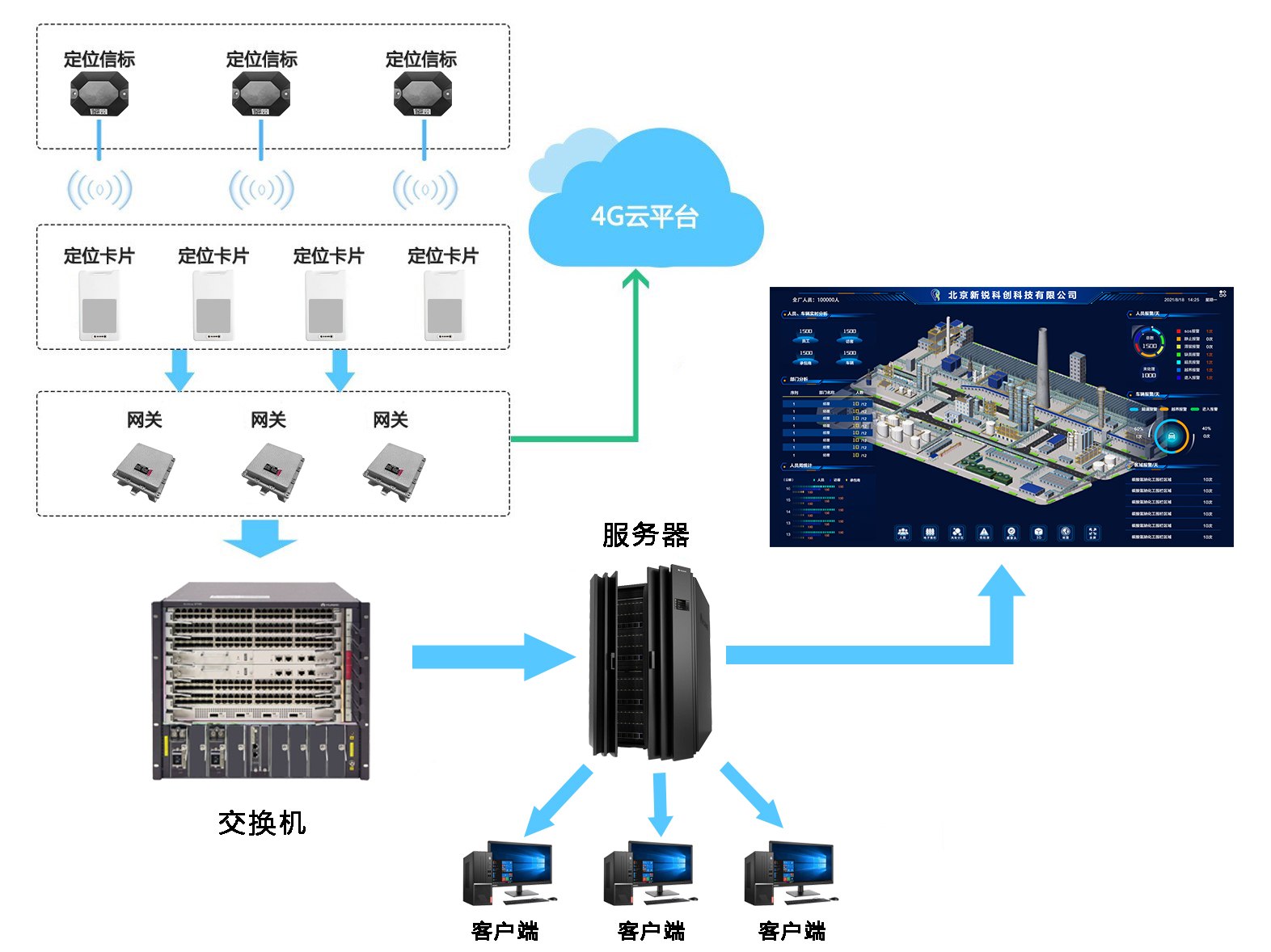
化工廠室內藍牙+LoRa人員定位系統解決方案
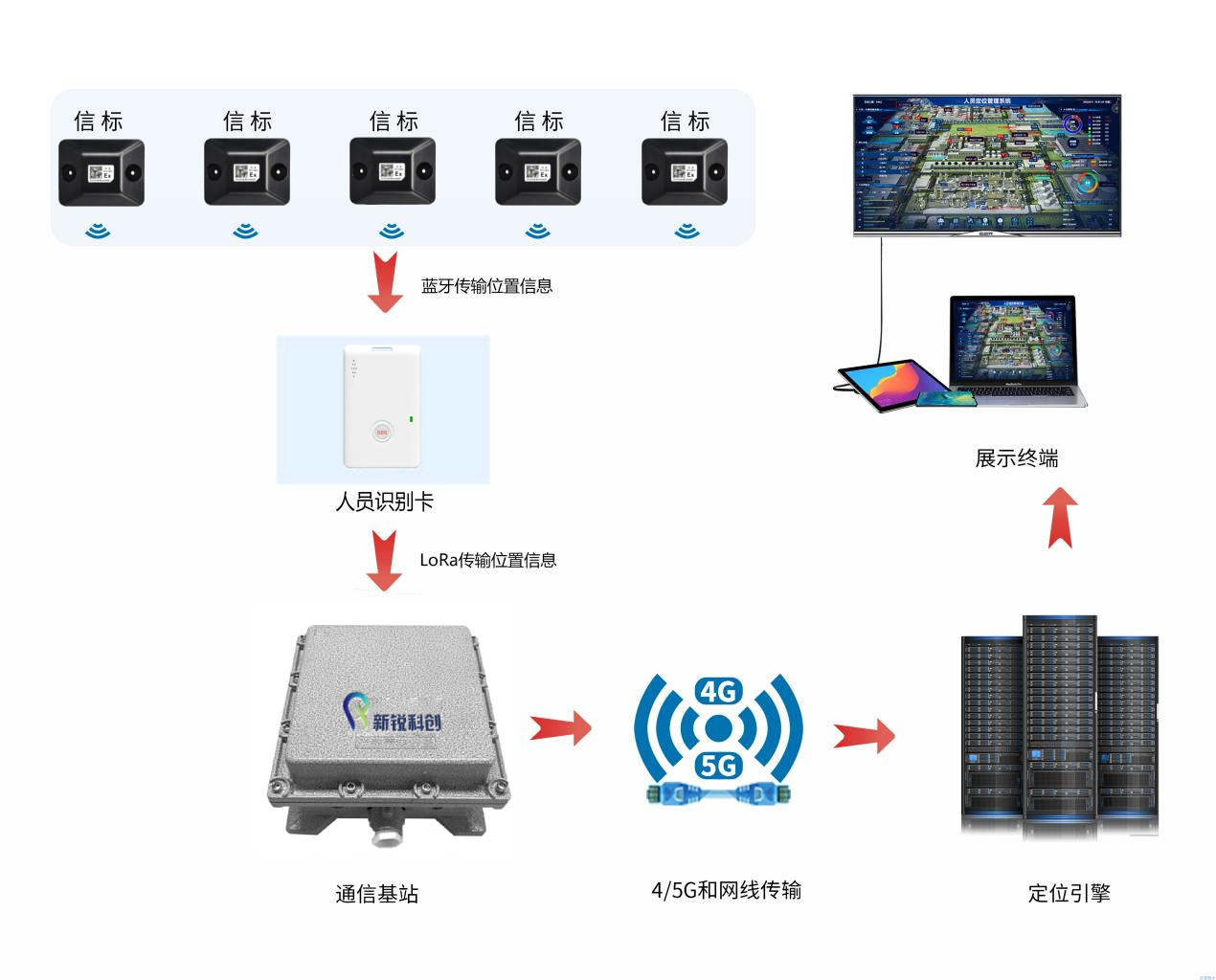
化工廠精確人員定位系統解決方案
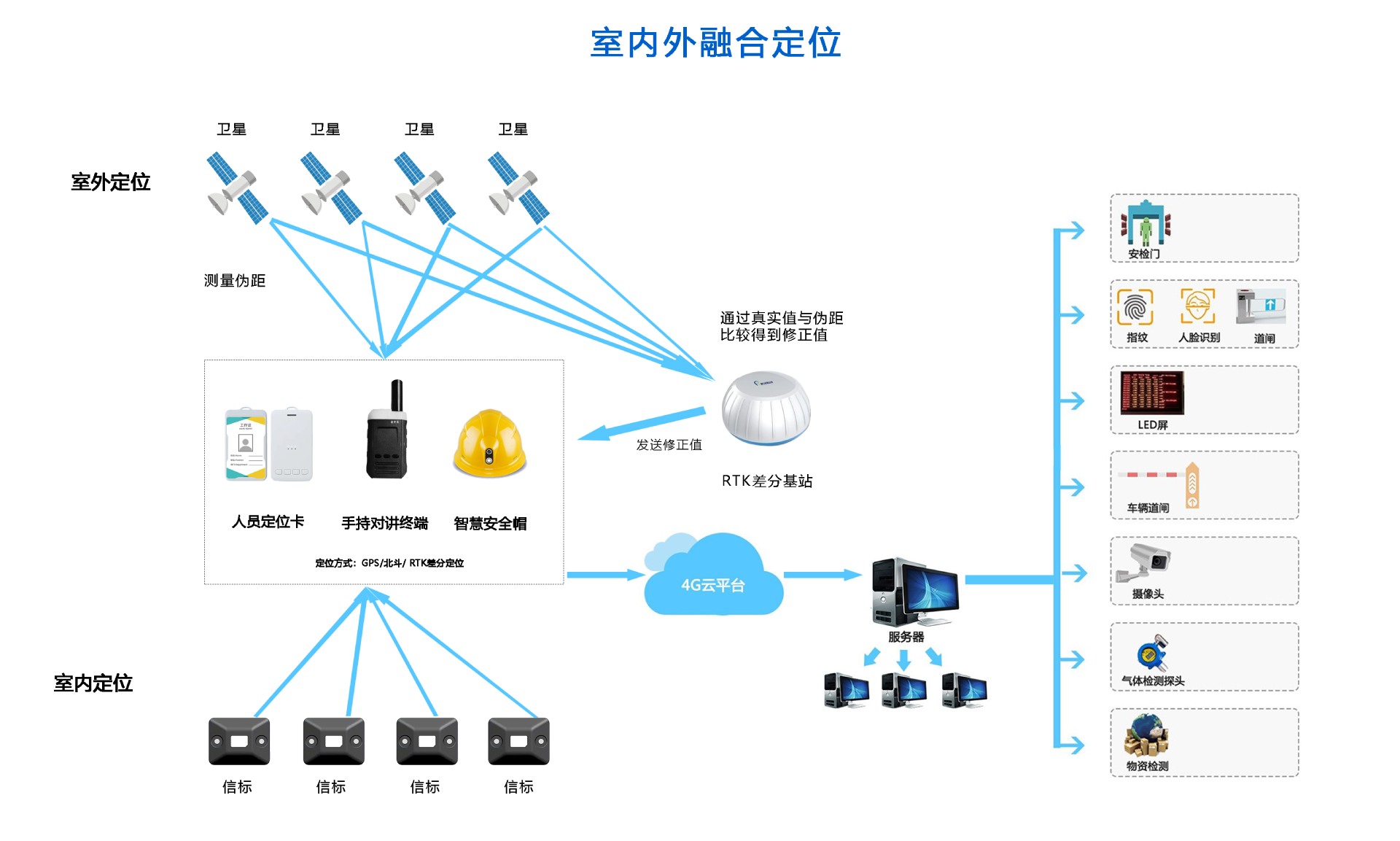
化工廠藍牙+GPS 北斗RTK人員定位系統解決方案
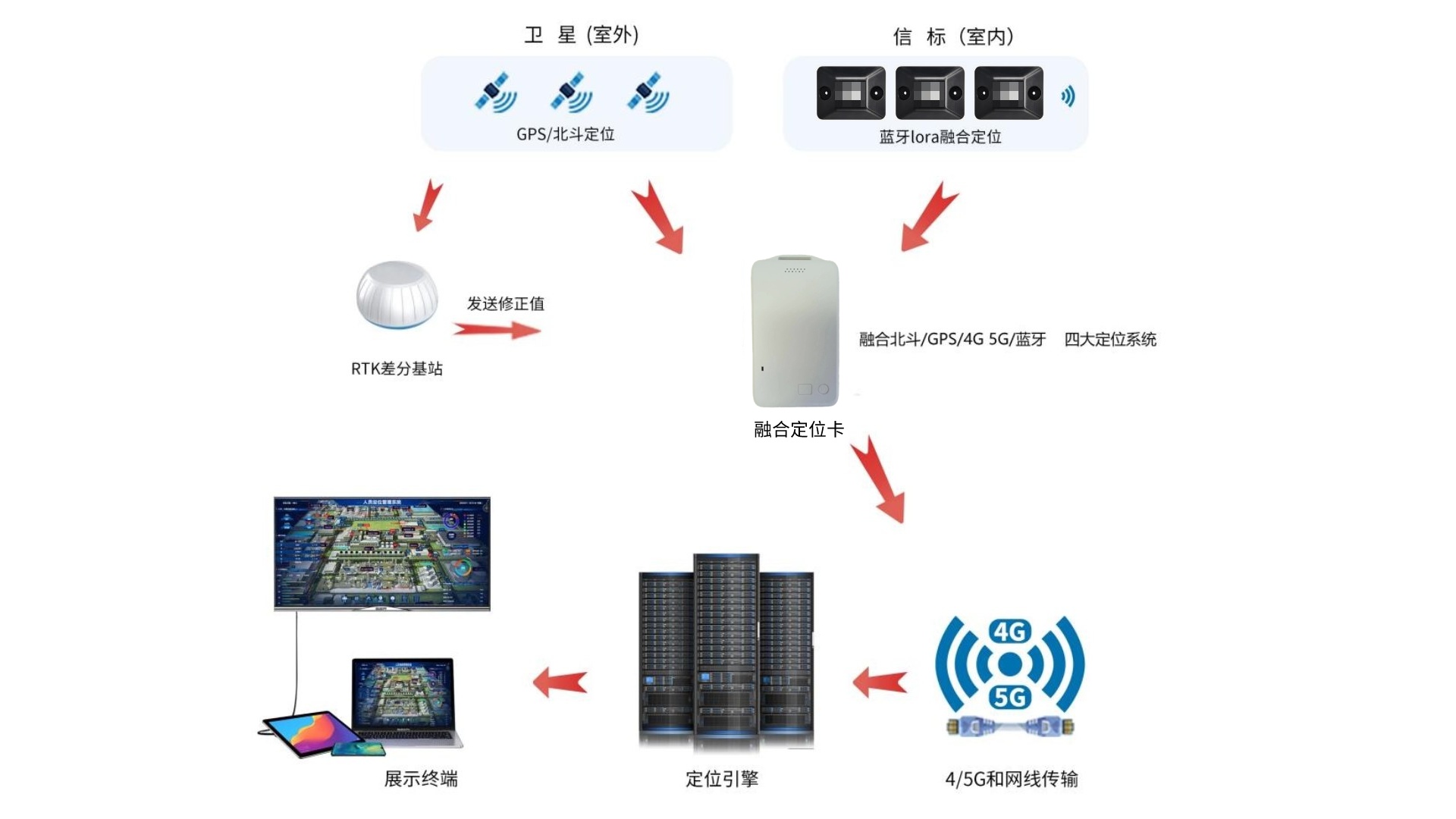
化工廠人員定位系統應遵循哪些原則?答案在這里!
人員定位系統可以解決化工廠哪些管理薄弱點?
化工廠定位的解決方案是什么?可以解決哪些難題
防爆巡檢終端在石化工廠安全保障中的應用

化工廠防爆對講機應用方案

化工廠環境監測系統是什么
盤古信息助力PCB企業構建智能化工廠 引領產業變革的未來之路
化工廠人員定位系統的應用分享
設置RFID感應門的化工廠二道門主要建設方案





 工商網監
工商網監
評論