 大象機器人開源協作機械臂機械臂接入GPT4o大模型!
大象機器人開源協作機械臂機械臂接入GPT4o大模型!
本文已經或者同濟子豪兄作者授權對文章進行編輯和轉載
引言
隨著人工智能和機器人技術的快速發展,機械臂在工業、醫療和服務業等領域的應用越來越廣泛。通過結合大模型和多模態AI,機械臂能夠實現更加復雜和智能化的任務,提升了人機協作的效率和效果。我們個人平時接觸不太到機械臂這類的機器人產品,但是有一種小型的機械臂我們人人都可以擁有它myCobot,價格低廉的一種桌面型機械臂。
案例介紹
本文介紹同濟子豪兄開源的一個名為“vlm_arm”項目,這個項目中將mycobot 機械臂與大模型和多模態AI結合,創造了一個具身智能體。該項目展示了如何利用先進的AI技術提高機械臂的自動化和智能化水平。本文的目的是通過詳細介紹該案例的方法和成功,展示機械臂具身智能體的實際應用。
產品介紹
myCobot 280 Pi
myCobot 280 Pi是一款6自由度的桌面型機械臂,主要的控制核心是Raspberry Pi 4B,輔助控制核心是ESP32,同時配備了 Ubuntu Mate 20.04 操作系統和豐富的開發環境。這使得 myCobot 280 Pi 在無需外接 PC 的情況下,只需連接顯示器、鍵盤和鼠標即可進行開發。

這款機械臂重量輕,尺寸小,具有多種軟硬件交互功能,兼容多種設備接口。它支持多平臺的二次開發,適用于人工智能相關學科教育、個人創意開發、商業應用探索等多種應用場景。
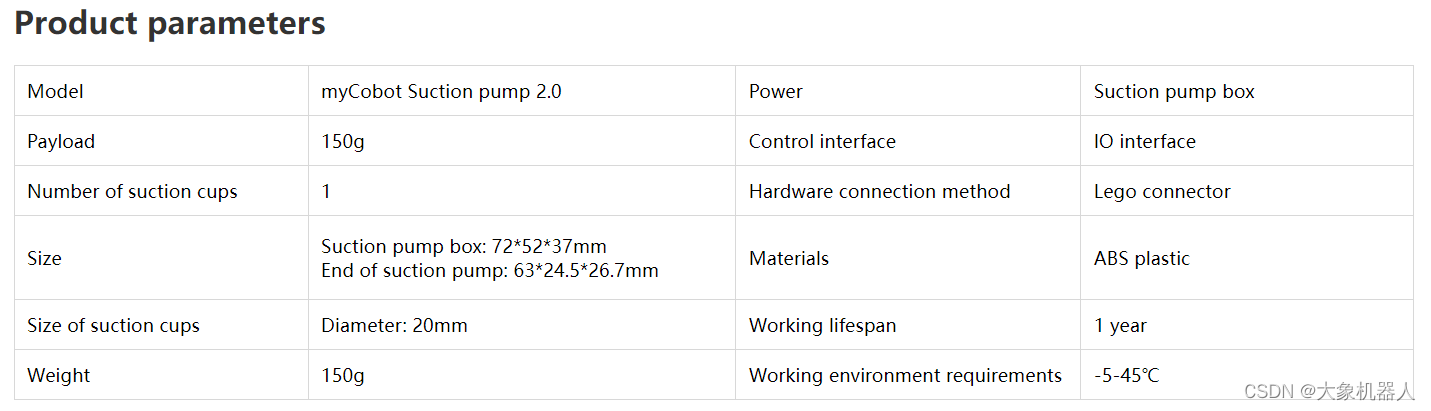
Camera Flange 2.0
在案例中使用到的攝像頭,通過usb數據線跟raspberry pi鏈接,可以獲取到圖像來進行機器視覺的處理。

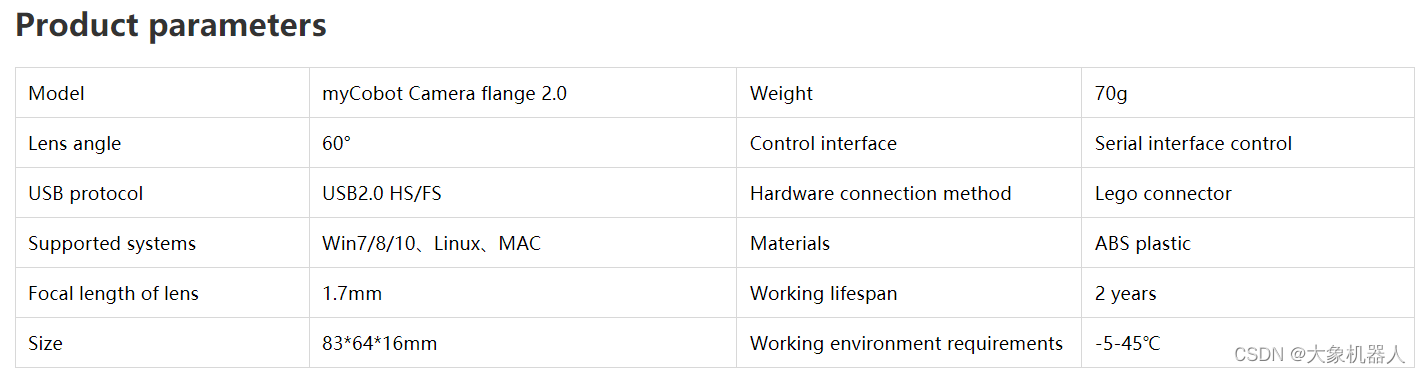
Suction Pump 2.0
吸泵,工作原理通過電磁閥抽空起造成壓強差然后將物體吸起來。通過IO接口鏈接機械臂,用pymycobot 的API進行控制吸泵的開關。

機械臂的末端都是通過LEGO連接件連接起來的,所以它們之間可以很方便的連接起來不需要額外的結構件。

技術介紹
整個的案例將在python環境中進行編譯,下面講介紹使用到的庫。
pymycobot:
elephant robotics編寫的對myCobot 控制的python庫,可以通過坐標,角度來控制機械臂的運動,也可以控制官方適配的末端執行器例如夾爪,吸泵的運動。
Yi-Large:
Yi-large 是由中國人工智能公司 01.AI 開發的大型語言模型,擁有超過 1000 億參數。Yi-large 使用了一種叫做“Transformer”的架構,并對其進行了改進,使其在處理語言和視覺任務時表現得更好。
Claude 3 Opus:
該模型還展示了強大的多語言處理能力和改進的視覺分析功能,能夠進行圖像的轉錄和分析。此外,Claude 3 Opus 被設計為更具責任感和安全性,減少了偏見和隱私問題,確保其輸出更加可信和中立。
AppBuilder-SDK:
AppBuilder-SDK 的功能非常廣泛,包含了諸如語音識別、自然語言處理、圖像識別等AI能力組件 (Read the Docs) 。具體來說,它包括了短語音識別、通用文字識別、文檔解析、表格抽取、地標識別、問答對挖掘等多個組件 (Read the Docs) (GitHub) 。這些功能使開發者可以構建從基礎AI功能到復雜應用的各種項目,提升開發效率。
該案例中提到了很多的大語言模型,都是可以自行去測試每個大語言輸出的不同的結果如何。
項目結構
介紹項目之前必須得介紹一下項目的構成,制作了一張流程圖方便理解。
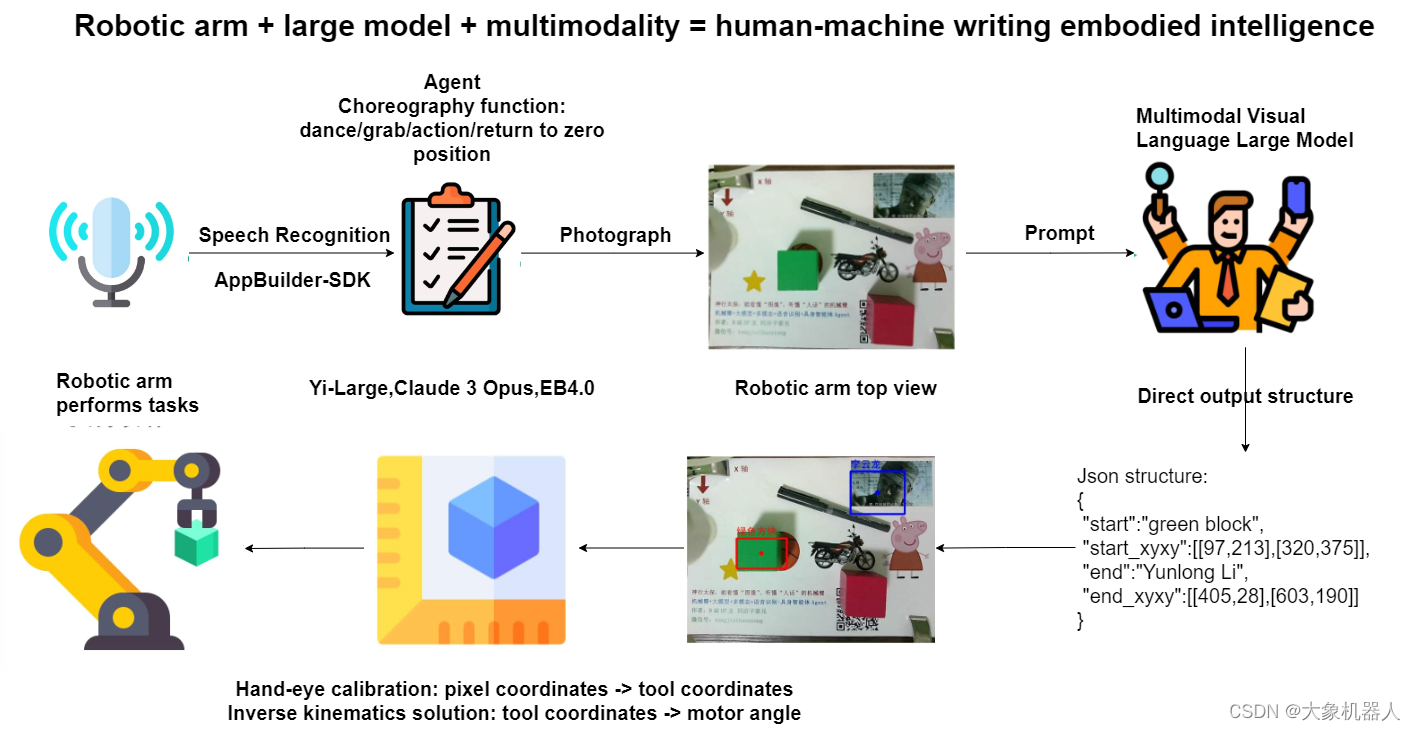
語音識別-appbuild
首先通過調用本地的電腦進行麥克風的錄音制作成音頻文件。
#調用麥克風錄音。 def record(MIC_INDEX=0, DURATION=5): ''' 調用麥克風錄音,需用arecord -l命令獲取麥克風ID DURATION,錄音時長 ''' os.system('sudo arecord -D "plughw:{}" -f dat -c 1 -r 16000 -d {} temp/speech_record.wav'.format(MIC_INDEX, DURATION))
當然這種默認的錄音在一些特定的環境中效果是不好的,所以要設定相關的參數保證錄音的質量。
CHUNK = 1024 # 采樣寬度 RATE = 16000 # 采樣率 QUIET_DB = 2000 # 分貝閾值,大于則開始錄音,否則結束 delay_time = 1 # 聲音降至分貝閾值后,經過多長時間,自動終止錄音 FORMAT = pyaudio.paInt16 CHANNELS = 1 if sys.platform == 'darwin' else 2 # 采樣通道數
根據參數的設定,然后開始錄音,之后要對文件進行保存。
output_path = 'temp/speech_record.wav' wf = wave.open(output_path, 'wb') wf.setnchannels(CHANNELS) wf.setsampwidth(p.get_sample_size(FORMAT)) wf.setframerate(RATE) wf.writeframes(b''.join(frames[START_TIME-2:END_TIME])) wf.close() print('保存錄音文件', output_path)
有了錄音文件,電腦當然沒那么智能我們需要用到appbuild-sdk來對音頻文件的語音進行識別,這樣LLM才能夠獲取我們說的話然后做出一些對應的操作。
import appbuilder
os.environ["APPBUILDER_TOKEN"] = APPBUILDER_TOKEN
asr = appbuilder.ASR() # 語音識別組件
def speech_recognition(audio_path='temp/speech_record.wav'):
# 載入wav音頻文件
with wave.open(audio_path, 'rb') as wav_file:
# 獲取音頻文件的基本信息
num_channels = wav_file.getnchannels()
sample_width = wav_file.getsampwidth()
framerate = wav_file.getframerate()
num_frames = wav_file.getnframes()
# 獲取音頻數據
frames = wav_file.readframes(num_frames)
# 向API發起請求
content_data = {"audio_format": "wav", "raw_audio": frames, "rate": 16000}
message = appbuilder.Message(content_data)
speech_result = asr.run(message).content['result'][0]
return speech_result
Prompt-Agent
緊接著,我們要prompt大語言模型,提前告訴它出現某種情況應該如何進行應對。這邊對調用LLM的API 就不做過多的介紹了,讓我們來看看如何對LLM做預訓練。
prompt: (截取部分片段,以下是做中文的翻譯) 你是我的機械臂助手,機械臂內置了一些函數,請你根據我的指令,以json形式輸出要運行的對應函數和你給我的回復 【以下是所有內置函數介紹】 機械臂位置歸零,所有關節回到原點:back_zero() 放松機械臂,所有關節都可以自由手動拖拽活動:back_zero() 做出搖頭動作:head_shake() 做出點頭動作:head_nod() 做出跳舞動作:head_dance() 打開吸泵:pump_on() 關閉吸泵:pump_off()【輸出json格式】 你直接輸出json即可,從{開始,不要輸出包含```json的開頭或結尾 在'function'鍵中,輸出函數名列表,列表中每個元素都是字符串,代表要運行的函數名稱和參數。每個函數既可以單獨運行,也可以和其他函數先后運行。列表元素的先后順序,表示執行函數的先后順序 在'response'鍵中,根據我的指令和你編排的動作,以第一人稱輸出你回復我的話,不要超過20個字,可以幽默和發散,用上歌詞、臺詞、互聯網熱梗、名場面。比如李云龍的臺詞、甄嬛傳的臺詞、練習時長兩年半。 【以下是一些具體的例子】 我的指令:回到原點。你輸出:{'function':['back_zero()'], 'response':'回家吧,回到最初的美好'} 我的指令:先回到原點,然后跳舞。你輸出:{'function':['back_zero()', 'head_dance()'], 'response':'我的舞姿,練習時長兩年半'} 我的指令:先回到原點,然后移動到180, -90坐標。你輸出:{'function':['back_zero()', 'move_to_coords(X=180, Y=-90)'], 'response':'精準不,老子打的就是精銳'}
智能視覺抓取
在這個過程中,只需要myCobot移動到俯視的一個位置,對目標進行拍攝,然后將拍攝后的照片交給視覺模型進行處理,獲取到目標的參數就可以返回給機械臂做抓取運動。
調用相機進行拍攝
def check_camera():
cap = cv2.VideoCapture(0)
while(True):
ret, frame = cap.read()
# gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
cv2.imshow('frame', frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
講圖像交給大模型進行處理,之后得到的參數需要進一步的處理,繪制可視化的效果,最終將返回得到歸一化坐標轉化為實際圖像中的像素坐標。
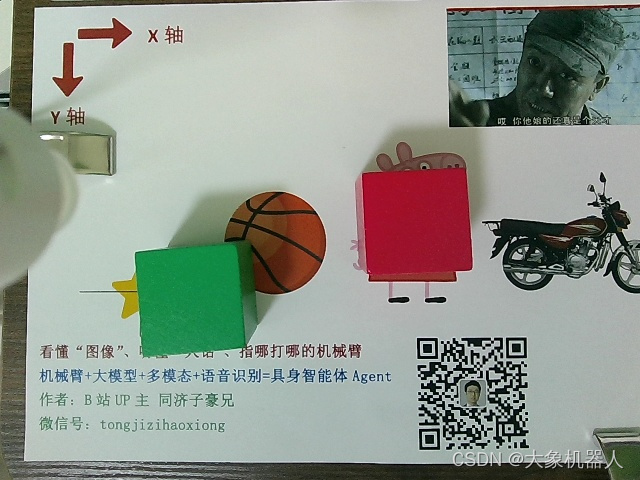
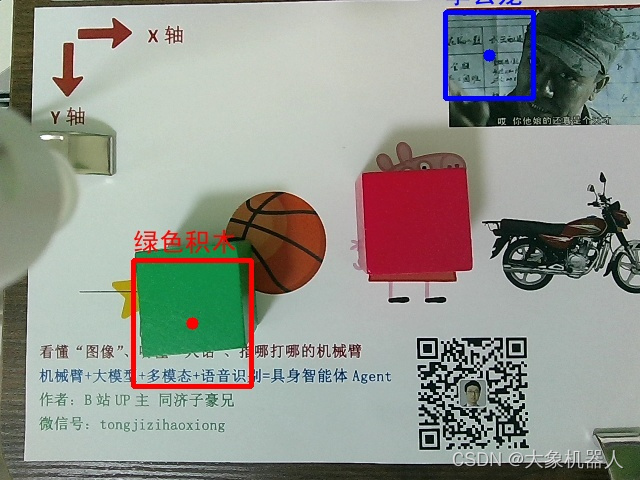
def post_processing_viz(result, img_path, check=False): ''' 視覺大模型輸出結果后處理和可視化 check:是否需要人工看屏幕確認可視化成功,按鍵繼續或退出 ''' # 后處理 img_bgr = cv2.imread(img_path) img_h = img_bgr.shape[0] img_w = img_bgr.shape[1] # 縮放因子 FACTOR = 999 # 起點物體名稱 START_NAME = result['start'] # 終點物體名稱 END_NAME = result['end'] # 起點,左上角像素坐標 START_X_MIN = int(result['start_xyxy'][0][0] * img_w / FACTOR) START_Y_MIN = int(result['start_xyxy'][0][1] * img_h / FACTOR) # 起點,右下角像素坐標 START_X_MAX = int(result['start_xyxy'][1][0] * img_w / FACTOR) START_Y_MAX = int(result['start_xyxy'][1][1] * img_h / FACTOR) # 起點,中心點像素坐標 START_X_CENTER = int((START_X_MIN + START_X_MAX) / 2) START_Y_CENTER = int((START_Y_MIN + START_Y_MAX) / 2) # 終點,左上角像素坐標 END_X_MIN = int(result['end_xyxy'][0][0] * img_w / FACTOR) END_Y_MIN = int(result['end_xyxy'][0][1] * img_h / FACTOR) # 終點,右下角像素坐標 END_X_MAX = int(result['end_xyxy'][1][0] * img_w / FACTOR) END_Y_MAX = int(result['end_xyxy'][1][1] * img_h / FACTOR) # 終點,中心點像素坐標 END_X_CENTER = int((END_X_MIN + END_X_MAX) / 2) END_Y_CENTER = int((END_Y_MIN + END_Y_MAX) / 2) # 可視化 # 畫起點物體框 img_bgr = cv2.rectangle(img_bgr, (START_X_MIN, START_Y_MIN), (START_X_MAX, START_Y_MAX), [0, 0, 255], thickness=3) # 畫起點中心點 img_bgr = cv2.circle(img_bgr, [START_X_CENTER, START_Y_CENTER], 6, [0, 0, 255], thickness=-1) # 畫終點物體框 img_bgr = cv2.rectangle(img_bgr, (END_X_MIN, END_Y_MIN), (END_X_MAX, END_Y_MAX), [255, 0, 0], thickness=3) # 畫終點中心點 img_bgr = cv2.circle(img_bgr, [END_X_CENTER, END_Y_CENTER], 6, [255, 0, 0], thickness=-1) # 寫中文物體名稱 img_rgb = cv2.cvtColor(img_bgr, cv2.COLOR_BGR2RGB) # BGR 轉 RGB img_pil = Image.fromarray(img_rgb) # array 轉 pil draw = ImageDraw.Draw(img_pil) # 寫起點物體中文名稱 draw.text((START_X_MIN, START_Y_MIN-32), START_NAME, font=font, fill=(255, 0, 0, 1)) # 文字坐標,中文字符串,字體,rgba顏色 # 寫終點物體中文名稱 draw.text((END_X_MIN, END_Y_MIN-32), END_NAME, font=font, fill=(0, 0, 255, 1)) # 文字坐標,中文字符串,字體,rgba顏色 img_bgr = cv2.cvtColor(np.array(img_pil), cv2.COLOR_RGB2BGR) # RGB轉BGR return START_X_CENTER, START_Y_CENTER, END_X_CENTER, END_Y_CENTER
要用到手眼標定將圖像中的像素坐標,轉化為機械臂的坐標,以至于機械臂能夠去執行抓取。
def eye2hand(X_im=160, Y_im=120): # 整理兩個標定點的坐標 cali_1_im = [130, 290] # 左下角,第一個標定點的像素坐標,要手動填! cali_1_mc = [-21.8, -197.4] # 左下角,第一個標定點的機械臂坐標,要手動填! cali_2_im = [640, 0] # 右上角,第二個標定點的像素坐標 cali_2_mc = [215, -59.1] # 右上角,第二個標定點的機械臂坐標,要手動填! X_cali_im = [cali_1_im[0], cali_2_im[0]] # 像素坐標 X_cali_mc = [cali_1_mc[0], cali_2_mc[0]] # 機械臂坐標 Y_cali_im = [cali_2_im[1], cali_1_im[1]] # 像素坐標,先小后大 Y_cali_mc = [cali_2_mc[1], cali_1_mc[1]] # 機械臂坐標,先大后小 # X差值 X_mc = int(np.interp(X_im, X_cali_im, X_cali_mc)) # Y差值 Y_mc = int(np.interp(Y_im, Y_cali_im, Y_cali_mc)) return X_mc, Y_mc
最后將全部的技術整合在一起就形成了一個完成的Agent了,就能夠實現指哪打哪的功能。
https://www.youtube.com/watch?v=VlSQQJreIrI
總結
vlm_arm項目展示了將多個大模型與機械臂結合的巨大潛力,為人機協作和智能化應用提供了新的思路和方法。這一案例不僅展示了技術的創新性和實用性,也為未來類似項目的開發提供了寶貴的經驗和參考。通過對項目的深入分析,我們可以看到多模型并行使用在提升系統智能化水平方面的顯著效果,為機器人技術的進一步發展奠定了堅實基礎。
離實現鋼鐵俠中的賈維斯越來越近了,未來電影中的畫面終將會成為現實。
審核編輯 黃宇
-
人工智能
+關注
關注
1787文章
46041瀏覽量
234923 -
開源
+關注
關注
3文章
3123瀏覽量
42066 -
機械臂
+關注
關注
12文章
502瀏覽量
24285 -
大模型
+關注
關注
2文章
2131瀏覽量
1969
發布評論請先 登錄
相關推薦






 工商網監
工商網監
評論