 深度學習中的無監督學習方法綜述
深度學習中的無監督學習方法綜述
引言
深度學習作為機器學習領域的一個重要分支,近年來在多個領域取得了顯著的成果,特別是在圖像識別、語音識別、自然語言處理等領域。然而,深度學習模型的強大性能往往依賴于大量有標簽的數據進行訓練,這在實際應用中往往難以實現。因此,無監督學習在深度學習中扮演著越來越重要的角色。本文旨在綜述深度學習中的無監督學習方法,包括自編碼器、生成對抗網絡、聚類算法等,并分析它們的原理、應用場景以及優缺點。
無監督學習的基本概念
無監督學習是機器學習的一個分支,其主要任務是從沒有標簽的數據中發現和提取有用的信息和結構。與有監督學習相比,無監督學習不需要提供預定義的標簽或結果,而是依賴于數據本身的結構和關系進行學習。無監督學習的方法包括聚類、降維、密度估計和表示學習等。
聚類
聚類是無監督學習中最常見的任務之一,目的是將數據點分組,使得同一組內的數據點盡可能相似,而不同組的數據點盡可能不同。聚類算法如K-means、層次聚類、DBSCAN等都是基于數據點的距離或密度進行分組。
K-means聚類
K-means是一種典型的劃分聚類算法,通過優化評價函數將數據集分割為K個部分。該算法需要K作為輸入參數,并迭代更新每個簇的中心點,直到滿足停止條件。K-means算法簡單高效,但對初始點的選擇敏感,且容易陷入局部最優。
層次聚類
層次聚類由不同層次的分割聚類組成,層次之間的分割具有嵌套的關系。它不需要輸入參數,但終止條件必須具體指定。典型的分層聚類算法有BIRCH、DBSCAN和CURE等。層次聚類能夠產生更加復雜的聚類結構,但計算復雜度較高。
降維
降維是無監督學習的另一重要應用,旨在減少數據的維度,同時保留數據的主要特征。降維算法如主成分分析(PCA)、t-SNE、自編碼器等,通過找到數據的主要特征或結構,將數據從高維空間映射到低維空間。
PCA
PCA是一種線性降維方法,通過計算數據的主成分(即方差最大的方向)來降低數據的維度。PCA能夠保留數據的主要特征,但可能忽略數據中的非線性關系。
自編碼器
自編碼器是一種特殊的神經網絡模型,通過無監督學習訓練得到輸入數據的壓縮表示。自編碼器通過編碼器和解碼器的組合,實現數據的壓縮和重構。這種特性使得自編碼器在數據降維、去噪、特征學習等方面有廣泛的應用。
密度估計
無監督學習還可以用于估計數據的概率密度函數,這可以通過參數方法(如高斯混合模型)或非參數方法(如核密度估計)來實現。密度估計對于異常檢測、生成模型等任務非常有用。
表示學習
表示學習是無監督學習的一個重要方向,旨在學習數據的低維、有意義的表示。這可以通過自編碼器、生成對抗網絡(GANs)等深度學習模型來實現。表示學習的目標是使得學習到的表示能夠捕獲數據的本質結構和特征,從而有利于后續的監督學習任務。
深度學習中的無監督學習方法
自編碼器
自編碼器是一種無監督學習的神經網絡模型,其主要目的是學習輸入數據的壓縮表示。通過訓練,自編碼器能夠學習到一個從輸入空間到隱藏空間的映射,然后再從隱藏空間恢復到輸入空間。自編碼器在數據降維、去噪、特征學習等方面有廣泛的應用。
稀疏自編碼器和降噪自編碼器
稀疏自編碼可以學習一個相等函數,使得可見層數據和經過編碼解碼后的數據盡可能相等。然而,其魯棒性較差,尤其是在測試樣本和訓練樣本概率分布相差較大時。為此,降噪自編碼被提出,通過以一定概率使輸入層某些節點的值為0,提高模型的魯棒性。
生成對抗網絡(GANs)
GANs是一種基于博弈論的無監督學習方法,包含兩個神經網絡:生成器和判別器。生成器的任務是生成盡可能接近真實數據的假數據,而判別器的任務是盡可能準確地判斷輸入數據是真實的還是生成的。通過不斷的博弈訓練,GANs可以生成高質量、多樣化的數據,在圖像生成、文本生成等領域有著廣泛的應用。
聚類在深度學習中的應用
深度學習中的聚類方法,如深度嵌入聚類(DEC)等,通過深度神經網絡學習數據的低維表示,然后在此表示上進行聚類。這種方法在圖像分割、文本分類等領域有著廣泛的應用。
降維在深度學習中的應用
深度學習中的降維方法,如PCA的神經網絡版本等,通過深度學習模型學習數據的低維表示,從而實現降維。這種方法在圖像識別、語音識別等領域有著廣泛的應用。
挑戰與未來展望
盡管無監督學習方法在多個領域取得了顯著的進展,但仍面臨著一些挑戰和問題需要解決。
理論基礎尚不完備
與有監督學習相比,無監督學習的理論基礎相對薄弱。無監督學習的目標、優化過程以及評估標準等方面仍缺乏統一和明確的數學框架。這限制了無監督學習方法的進一步發展和應用。
模型解釋性不足
無監督學習模型往往難以解釋其決策過程和結果。例如,在聚類任務中,雖然模型能夠將數據點分組,但很難解釋為什么某些數據點被歸為一類,而另一些數據點被歸為另一類。這在一定程度上限制了無監督學習在需要高度解釋性的領域的應用。
評估標準不統一
由于無監督學習的任務多樣且沒有明確的標簽信息,因此很難制定統一的評估標準來評價不同無監督學習方法的性能。這使得在選擇和比較無監督學習模型時存在一定的困難。
未來展望
面對上述挑戰,無監督學習在未來有以下幾個發展方向:
- 強化理論基礎 :加強無監督學習的數學和統計基礎研究,構建更加完善和嚴謹的理論框架。這將有助于更好地理解無監督學習的本質和機制,并推動其在實際應用中的進一步發展。
- 提高模型解釋性 :研究和發展具有更高解釋性的無監督學習模型。例如,通過引入注意力機制、可解釋性正則化項等方法,使模型能夠生成可解釋的聚類結果或降維表示。這將有助于無監督學習在醫療、金融等需要高度解釋性的領域的應用。
- 統一評估標準 :探索制定適用于不同無監督學習任務的統一評估標準。例如,可以基于數據的內在結構、模型的泛化能力、結果的穩定性等方面來制定評估指標。這將有助于更公平、客觀地比較和選擇無監督學習模型。
- 結合多模態數據 :隨著多模態數據的日益增多,如何有效地利用這些數據進行無監督學習成為了一個重要的研究方向。未來的研究可以關注如何結合圖像、文本、音頻等多種模態的數據進行無監督學習,以提取更豐富、更全面的信息。
- 強化學習與無監督學習的結合 :強化學習是一種通過試錯來學習最優策略的方法,而無監督學習則擅長從數據中提取有用信息。將兩者結合起來,可以形成更加智能和靈活的學習系統。例如,可以利用無監督學習來初始化強化學習的狀態空間或動作空間,從而提高學習效率和效果。
- 隱私保護與無監督學習 :隨著數據隱私保護意識的增強,如何在保護隱私的前提下進行無監督學習成為了一個重要的研究課題。未來的研究可以關注差分隱私、聯邦學習等隱私保護技術與無監督學習的結合,以實現數據的安全共享和有效利用。
總之,無監督學習作為深度學習的一個重要分支,在多個領域都有著廣泛的應用前景。然而,要實現其更大的潛力和價值,還需要在理論基礎、模型解釋性、評估標準以及與其他技術的結合等方面進行深入的研究和探索。
-
模型
+關注
關注
1文章
3171瀏覽量
48711 -
機器學習
+關注
關注
66文章
8377瀏覽量
132405 -
深度學習
+關注
關注
73文章
5492瀏覽量
120975
發布評論請先 登錄
相關推薦
采用無監督學習的方法,用深度摘要網絡總結視頻
基于半監督學習框架的識別算法
深度解析機器學習三類學習方法
利用機器學習來捕捉內部漏洞的工具運用無監督學習方法可發現入侵者
你想要的機器學習課程筆記在這:主要討論監督學習和無監督學習

機器學習算法中有監督和無監督學習的區別
最基礎的半監督學習
半監督學習最基礎的3個概念
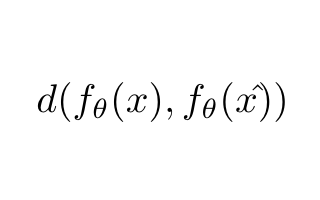
為什么半監督學習是機器學習的未來?
機器學習中的無監督學習應用在哪些領域
融合零樣本學習和小樣本學習的弱監督學習方法綜述







 工商網監
工商網監
評論