") 托寄物智能識別——大模型在京東快遞物流場景中的應(yīng)用與落地
托寄物智能識別——大模型在京東快遞物流場景中的應(yīng)用與落地
一、前言
在現(xiàn)代物流場景中,包裹信息的準(zhǔn)確性和處理效率至關(guān)重要。當(dāng)前,京東快遞在郵寄場景中面臨著日益豐富的寄遞品類和多樣化的個性化需求。本文將深入探討托寄物智能識別——大模型在京東快遞物流場景中的應(yīng)用與落地,分析其產(chǎn)生背景、應(yīng)用效果及未來發(fā)展方向。
二、背景
隨著電子商務(wù)的迅猛發(fā)展,物流行業(yè)面臨著前所未有的挑戰(zhàn)和機遇[1]。尤其是在中國,作為全球最大的電子商務(wù)市場之一,物流行業(yè)的效率、準(zhǔn)確性和智能化成為各大電商平臺競爭的關(guān)鍵因素。
當(dāng)前,京東快遞在郵寄場景中面臨著日益豐富的寄遞品類和多樣化的個性化需求。消費者對寄遞服務(wù)的期望不斷提升,他們希望能夠享受到更加快速、可靠和個性化的物流服務(wù)。這種需求的多樣化給物流企業(yè)帶來了巨大的壓力,但同時也提供了提升服務(wù)質(zhì)量和客戶滿意度的機會[2]。與此同時,京東快遞內(nèi)部運營也面臨著高破損率和高理賠成本的問題。詳細分析后發(fā)現(xiàn),理賠和破損問題主要集中在3C產(chǎn)品和生鮮品類。這些高價值和高時效的品類對托寄物的精準(zhǔn)識別提出了更高的要求。3C產(chǎn)品通常價格昂貴且易損壞,而生鮮品類則對運輸時效和溫控要求極高,任何延誤或處理不當(dāng)都可能導(dǎo)致嚴重的損失。這些高價值和高時效的品類對托寄物的精準(zhǔn)識別提出了更高的要求。核心體現(xiàn)在以下幾個方面:
1. 攬收要求
(1) 航空違禁品識別:通過精確匹配托寄物信息,減少人工判斷的誤差,提高航空違禁品的識別準(zhǔn)確性。
(2) 包裝推薦:
① 實時包裝推薦:在下單和攬收時實時推薦合適的包裝,減少破損風(fēng)險。
② 包裝預(yù)測:基于歷史客戶的下單習(xí)慣和需求,提前為每個站點推薦所需的包裝材料。
(3) 生鮮品類免賠:針對超標(biāo)準(zhǔn)時效要求的寄遞需求,通過簽署免賠協(xié)議允許寄遞,降低理賠成本。
2. 運營保障
針對高價值和高時效的品類(如大閘蟹、櫻桃、草莓、牛羊肉等),需要在攬收、轉(zhuǎn)運、派送、客戶服務(wù)和理賠全流程中提供保障和提效措施,提升京東物流的產(chǎn)品競爭力。
綜上所述,傳統(tǒng)的包裹信息處理方式往往依賴人工操作,不僅效率低下,還容易出錯。隨著人工智能和自然語言處理技術(shù)的迅猛發(fā)展,如何利用這些技術(shù)提升包裹信息處理的智能化水平,成為了一個重要課題。這不僅可以顯著提高處理效率,還能減少錯誤率,優(yōu)化整體運營流程,提升客戶滿意度和企業(yè)競爭力。
三、托寄物智能識別的產(chǎn)生
在目前的京東快遞郵寄場景中,用戶需要輸入托寄物名稱,系統(tǒng)會根據(jù)輸入的名稱匹配設(shè)定的品類,并基于托寄物的品類建立相應(yīng)的業(yè)務(wù)規(guī)則和優(yōu)化下單邏輯,如何提升托寄物匹配率,是我們研究的課題。首先我們需要分析匹配率現(xiàn)狀及原因

??
成功識別到品類的運單:通過某種手段成功識別托寄物屬于哪種品類,舉例說明:托寄物為“陽澄湖大螃蟹”的品類為海鮮或者螃蟹
識別結(jié)果成功匹配品類庫:對成功識別到的托寄物品類能夠匹配現(xiàn)有品類庫中的三級品類,例如:“陽澄湖大閘蟹”識別結(jié)果是螃蟹,對應(yīng)品類庫三級品類為:生鮮-海鮮-螃蟹
3.1 托寄物智能識別匹配率現(xiàn)狀及原因分析
根據(jù)2023年給出的歷史數(shù)據(jù)可以看到,運單托寄物匹配率相對較低,具體分析低匹配率的主要原因有以下幾個點:
(1) 品類庫不完善:當(dāng)京東快遞與快手、拼多多、抖音等多種電商平臺對接后,這些平臺上的商品種類繁多且更新頻繁,當(dāng)前品類庫的不足之處在于不能全面覆蓋所有商品類別,導(dǎo)致在實際應(yīng)用中可能出現(xiàn)識別錯誤或遺漏的情況。因此,品類庫有待進一步完善,以提高系統(tǒng)的識別準(zhǔn)確性和全面性。
(2) 用戶輸入的多樣性:用戶在輸入托寄物名稱時,往往會使用各種各樣的描述方式,這些描述方式可能包含錯別字、方言、縮寫或是個性化的命名方式。這種多樣性給系統(tǒng)帶來了極大的挑戰(zhàn),使得系統(tǒng)難以準(zhǔn)確匹配用戶輸入的托寄物名稱。例如,同一種商品可能會有多種不同的稱呼,或者用戶可能會使用模糊或不標(biāo)準(zhǔn)的名稱來描述物品,導(dǎo)致系統(tǒng)無法識別或匹配錯誤。因此,系統(tǒng)需要具備更強的自然語言處理能力和更豐富的語義理解能力,以應(yīng)對用戶輸入的多樣性。
(3) B端商家的商品名稱干擾:B端商家在使用零售平臺的商品名稱作為托寄物名稱時,往往會在名稱中加入大量用于營銷或SEO優(yōu)化的關(guān)鍵詞和描述信息。這些信息雖然有助于商品在平臺上的曝光和搜索排名,但卻給托寄物識別系統(tǒng)帶來了干擾。例如,商品名稱中可能會包含促銷信息、規(guī)格參數(shù)、品牌名等非必要信息,影響了系統(tǒng)對商品本身的準(zhǔn)確識別和匹配。因此,需要對這些干擾信息進行有效過濾和處理,以提高系統(tǒng)的匹配準(zhǔn)確性和識別效果。通過優(yōu)化算法和改進數(shù)據(jù)處理流程,可以更好地應(yīng)對B端商家商品名稱中的干擾信息,提升系統(tǒng)的整體性能。
3.2 托寄物匹配率低的影響
托寄物匹配率低會對物流和快遞業(yè)務(wù)產(chǎn)生多方面的負面影響,包括無法準(zhǔn)確分析和預(yù)測托寄物特性及流通趨勢,導(dǎo)致業(yè)務(wù)規(guī)劃和營銷策略不夠精準(zhǔn);在生鮮業(yè)務(wù)中,匹配錯誤可能引發(fā)產(chǎn)品變質(zhì)、客戶投訴和理賠問題,增加運營成本;同時,增值服務(wù)推薦不準(zhǔn)確會影響快遞員的攬收效率和客戶滿意度,進而削弱整體服務(wù)質(zhì)量和公司的市場競爭力。因此,提高識別匹配率對于優(yōu)化運營流程、提升客戶體驗和增強企業(yè)競爭力至關(guān)重要。具體影響歸納如下:
(1) 生鮮業(yè)務(wù)問題:在處理生鮮寄遞業(yè)務(wù)時,由于系統(tǒng)未能準(zhǔn)確識別生鮮或者易碎匹配產(chǎn)品,常常導(dǎo)致客戶投訴和理賠問題。生鮮產(chǎn)品對時效性和溫控要求極高,一旦匹配錯誤,可能導(dǎo)致配送延誤或溫控失效,進而引發(fā)產(chǎn)品變質(zhì)。這不僅損害了客戶體驗,還增加了公司的運營成本和賠償風(fēng)險。例如,某些生鮮產(chǎn)品需要特殊的包裝和運輸條件,如果系統(tǒng)無法識別并匹配這些需求,可能導(dǎo)致運輸過程中的損壞和質(zhì)量問題。因此,提升生鮮產(chǎn)品的識別準(zhǔn)確性和匹配能力,是減少客戶投訴和理賠問題的關(guān)鍵。
(2) 增值服務(wù)推薦不準(zhǔn)確:如果托寄物品類識別不準(zhǔn)確,會造成基于托寄物的增值服務(wù)推薦不夠精準(zhǔn),可能會影響快遞員上門攬收的效率。例如,對于某些高價值或易碎物品,系統(tǒng)應(yīng)推薦保險服務(wù)或特殊包裝服務(wù),但由于識別不準(zhǔn)確,可能未能及時提供這些建議,導(dǎo)致客戶體驗不佳和潛在的風(fēng)險增加。此外,增值服務(wù)推薦不準(zhǔn)確也可能造成快遞員在攬收過程中需要額外溝通和確認,降低了整體攬收效率。
(3) 缺乏底層數(shù)據(jù):由于整體識別匹配率較低,導(dǎo)致缺乏全面和準(zhǔn)確的底層數(shù)據(jù),系統(tǒng)無法對托寄物進行深入的分析。這種數(shù)據(jù)缺失限制了對托寄物特征、流通路徑、用戶偏好等方面的洞察,進而影響了業(yè)務(wù)決策和營銷策略的制定。例如,無法準(zhǔn)確掌握某類托寄物的高峰期和低谷期,導(dǎo)致庫存管理和配送資源的調(diào)配不夠優(yōu)化。此外,缺乏底層數(shù)據(jù)也使得難以進行精準(zhǔn)的市場細分和個性化營銷,無法有效提升客戶滿意度和忠誠度。因此,建立完善的底層數(shù)據(jù)采集和分析體系,對于提升業(yè)務(wù)規(guī)劃和營銷策略的科學(xué)性和有效性至關(guān)重要。
基于以上原因和影響,京東快遞亟需一種更智能的托寄物識別系統(tǒng),以提高匹配率和服務(wù)質(zhì)量,提升客戶體驗和增強企業(yè)競爭力。
3.3 大模型賦能托寄物智能識別
自BERT(Bidirectional Encoder Representations from Transformers)和GPT系列模型的成功之后,我們就關(guān)注到大模型的發(fā)展能為快遞行業(yè)的快速發(fā)展助力賦能。在進行托寄物智能識別時,選擇合適的大模型是一個關(guān)鍵的決策,這將直接影響到識別的準(zhǔn)確性、效率以及系統(tǒng)的可擴展性。
3.3.1選擇什么樣的大模型?
以下是在選擇大模型時需要考慮的幾個關(guān)鍵因素:
(1) 模型性能與準(zhǔn)確性:首先,模型在托寄物識別任務(wù)上的性能和準(zhǔn)確性是最重要的考量點。這包括模型對各類托寄物的識別能力,以及在不同條件下的穩(wěn)定性。
(2) 處理速度與實時性:在快遞行業(yè)中,處理速度至關(guān)重要,因此模型的推理速度(即完成識別所需的時間)是一個重要的考慮因素。理想的模型應(yīng)能夠在保證準(zhǔn)確性的同時,實現(xiàn)快速的識別,滿足實時處理的需求。
(3) 資源消耗:大模型通常需要較多的計算資源,包括CPU/GPU計算能力和內(nèi)存。因此,模型的資源消耗情況也是一個需要考慮的因素,特別是在資源有限的環(huán)境下。
(4) 易用性與集成:模型的易用性,包括其在現(xiàn)有系統(tǒng)中的集成難易度,以及后續(xù)的維護和升級需求,也是重要的考慮點。一個好的模型不僅應(yīng)該在技術(shù)上表現(xiàn)優(yōu)秀,還應(yīng)該容易被集成到公司業(yè)務(wù)的現(xiàn)有工作流程中。
(5) 可擴展性與靈活性:隨著快遞行業(yè)的發(fā)展和業(yè)務(wù)需求的變化,模型可能需要處理更多類型的托寄物或適應(yīng)新的識別場景。因此,模型的可擴展性和靈活性也是選擇時需要考慮的因素。
(6) 安全性與隱私:在處理客戶托寄物的信息時,模型需要確保數(shù)據(jù)的安全性和客戶隱私的保護。這包括數(shù)據(jù)加密、訪問控制等安全特性。
結(jié)合以上因素,我們評估到當(dāng)托寄物名稱識別為物品類型時,暫不涉及用戶隱私等安全信息問題,同時,基于識別效果和成本考慮,在當(dāng)前環(huán)境下的最優(yōu)解,我們最終選擇了最適合我們的大模型,該大模型的自然語言處理技術(shù)已經(jīng)能夠滿足我們以上訴求。
自然語言處理(Natural Language Processing,簡稱NLP)是人工智能的一個關(guān)鍵領(lǐng)域,致力于讓計算機理解、解釋和生成自然語言,通過大規(guī)模預(yù)訓(xùn)練模型,實現(xiàn)文本生成、情感分析、機器翻譯、問答系統(tǒng)等多種應(yīng)用[3]。雖然其強大的上下文理解、多語言處理和知識豐富等優(yōu)勢顯著提升了人機交互的智能化水平,但也面臨計算資源需求高、數(shù)據(jù)隱私和安全問題、解釋性不足以及偏見和公平性等挑戰(zhàn)[4]。
3.3.2 大模型在托寄物識別中的應(yīng)用
托寄物智能識別是基于自然語言處理技術(shù)的智能系統(tǒng),旨在自動識別、處理和管理包裹信息[5]。通過對包裹標(biāo)簽、物流單據(jù)等信息的智能解析,能夠大幅提升包裹信息處理的效率和準(zhǔn)確性,減少人工操作的工作量,并降低出錯率[6]。
京東快遞借助大模型的強大能力,通過對文本信息的精準(zhǔn)解析,實現(xiàn)了托寄物的高效識別和匹配。具體來說,大模型根據(jù)實現(xiàn)預(yù)設(shè)的業(yè)務(wù)規(guī)則能夠理解并處理用戶和商家輸入的復(fù)雜描述,自動提取出關(guān)鍵特征,從而將托寄物精準(zhǔn)匹配到正確的品類。這一過程不僅提高了識別的準(zhǔn)確性,還大幅減少了因匹配錯誤導(dǎo)致的物流問題。以下是對大模型能力與現(xiàn)有能力對比情況:
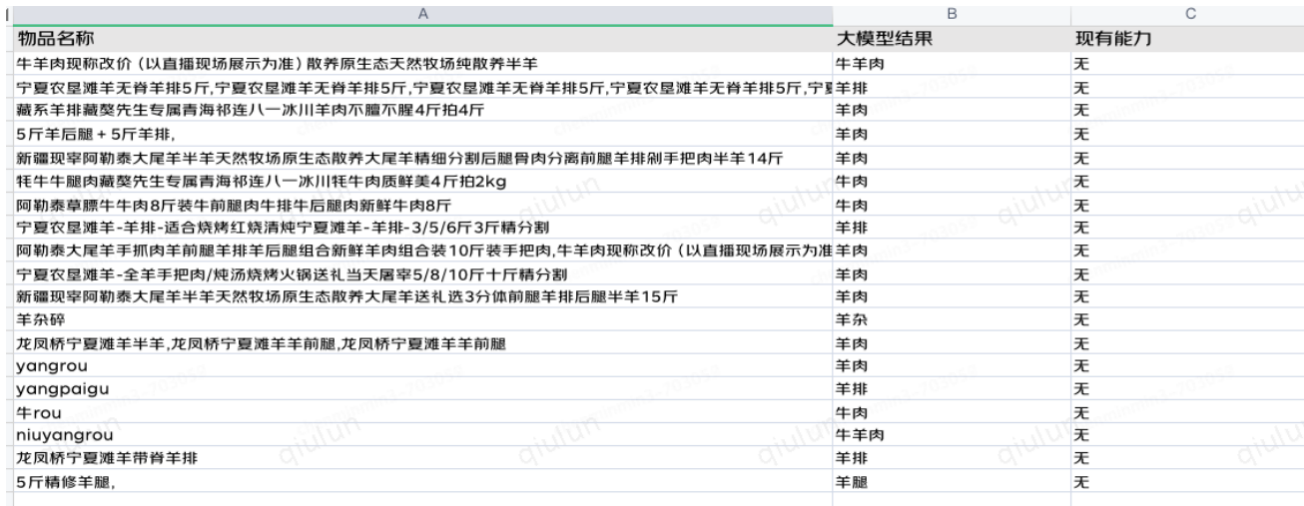
??
大模型在文本解析方面的應(yīng)用,使得托寄物能夠被精準(zhǔn)識別并匹配到正確的品類。通過對現(xiàn)有品類的深入分析和理解,大模型能夠提出更準(zhǔn)確的命名,并自動生成新的品類名稱,確保品類庫的不斷更新和豐富。這種動態(tài)擴展的能力,使得品類庫能夠及時涵蓋新興商品和細分市場,提升了整體匹配的精度和效率。此外,通過更精準(zhǔn)的托寄物品智能識別打標(biāo),系統(tǒng)能夠推薦更符合托寄物品類的運輸路線和時效。比如,對于易碎品和生鮮商品,系統(tǒng)會自動選擇更適合的運輸方式和更快的配送時效,確保商品的安全和新鮮度。這種精準(zhǔn)的路線和時效推薦,不僅提高了物流運營的效率,還顯著減少了客戶投訴,挽回了因運輸問題導(dǎo)致的托寄物理賠損失。
通過對托寄物品類型數(shù)據(jù)的深入分析,京東快遞能夠推薦更合理的增值服務(wù),從而提升攬收效率。例如,通過分析某一區(qū)域內(nèi)的托寄物品類型和數(shù)量,系統(tǒng)可以預(yù)測未來的攬收需求,并提前安排快遞員進行高效的攬收操作。此外,系統(tǒng)還可以根據(jù)托寄物的特性,推薦相關(guān)的增值服務(wù),如保價服務(wù)、特殊包裝服務(wù)等,進一步提高客戶滿意度和攬收效率。
從長遠規(guī)劃來看,京東快遞還可以利用大模型對同類型托寄物郵寄較多的地區(qū)進行重新規(guī)劃郵寄路線。通過對歷史數(shù)據(jù)的分析,系統(tǒng)能夠識別出某些地區(qū)對特定類型托寄物的需求較高,從而優(yōu)化這些地區(qū)的郵寄路線,提高郵寄時效。例如,對于某些地區(qū)頻繁郵寄的電子產(chǎn)品,系統(tǒng)可以規(guī)劃專門的運輸路線,以確保這些產(chǎn)品能夠更快速地送達目的地。這不僅提高了用戶體驗,減少了客戶投訴,還進一步提升了整體物流運營的效率。
四、托寄物智能識別的具體實施落地
如何有效的將大模型與我們的業(yè)務(wù)結(jié)合起來?如何控制成本?如何保證安全可控?如何高效率協(xié)作?這些都是我們面臨的難題。
京東快遞業(yè)務(wù)是面向C和B的業(yè)務(wù),包括寄件、下單、查件等多個核心流程。其中托寄物信息識別是其核心流程下單環(huán)節(jié)中重要的一環(huán)。我們需要考慮以下幾點:
(1) 在進行大模型查詢識別過程中,我們要保證識別時效,不能影響下單效率。
(2) 京東快遞業(yè)務(wù)量較大,如果每一單都進行大模型識別,使用成本較高,業(yè)務(wù)成本無法把控。
(3) 我們還要驗證大模型識別結(jié)果的準(zhǔn)確性是否滿足訴求。
(4) 對于識別的結(jié)果無法匹配怎么處理?
4.1 架構(gòu)設(shè)計
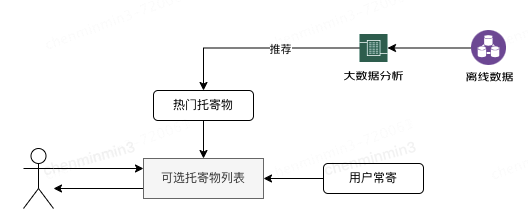
京東快遞業(yè)務(wù)TOB和TOC特點不同,TOC大部分是用戶輸入,一般用戶最多只輸入幾個字,用戶更傾向使用熱門推薦或者用戶常寄列表中的記錄,這類托寄物名稱大概率即為品類名稱,例如“文件”“衣服”等,這類詞大部分都能在品類庫中通過全匹配的形式匹配上。如下圖所示:
??
而TOB大部分是商家,托寄物名稱一般是電商平臺的商品名稱,夾帶各種SEO搜索關(guān)鍵字和吸引眼球的描述信息,一般詞條較長肉眼難以快速辨認,一般無法通過簡單匹配的方式在品類庫找到對應(yīng)的三級品類,這類運單往往需要AI幫助識別出合適的類別,然后再進行品類庫對應(yīng)尋找。
針對以上TOB和TOC的不同特點,我們對托寄物智能識別系統(tǒng)設(shè)計了兩種形式不同的架構(gòu)。
4.1.1 B端架構(gòu)設(shè)計
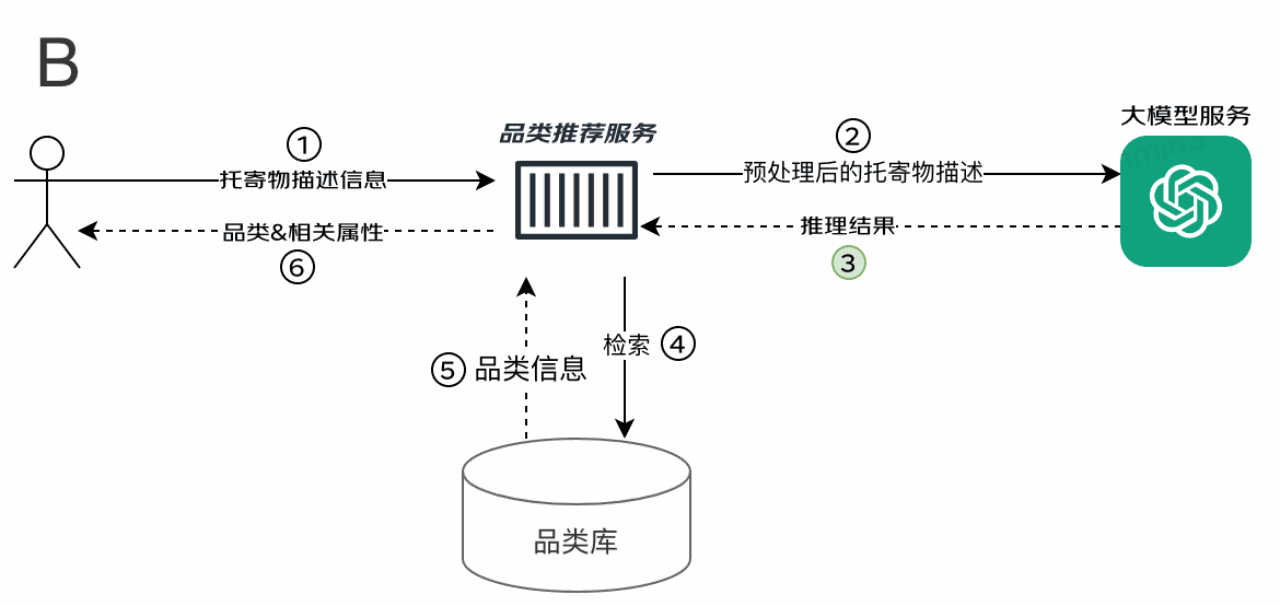
??
TOB流程:
① 托寄物描述信息:客戶端將真實的B運單商品信息推送給品類推薦服務(wù)器進行處理,商品名稱舉例:“寧夏農(nóng)墾灘羊無脊羊排5斤,寧夏農(nóng)墾灘羊無脊羊排5斤,寧夏農(nóng)灘羊無脊羊排5斤,寧夏農(nóng)灘羊無脊羊排5斤,寧夏羊排”
② 品類推薦服務(wù)器經(jīng)過處理后給大模型輸入預(yù)處理后的托寄物描述,預(yù)處理后的托寄物描述可參考如下模式:您的任務(wù)是根據(jù)#物品描述#提取出x個字內(nèi)的物品的品類和名稱,只返回最明確且能體現(xiàn)用戶意圖的那個。忽略地域,品牌,型號,重量,體積,尺寸,數(shù)量,價格,包裝,形容詞等干擾信息。輸出JSON對象:<包含以下鍵:品類 和 名稱>,如果無法提取或確認,則鍵值為空,其中物品描述替換為#寧夏農(nóng)墾灘羊無脊羊排5斤,寧夏農(nóng)墾灘羊無脊羊排5斤,寧夏農(nóng)灘羊無脊羊排5斤,寧夏農(nóng)灘羊無脊羊排5斤,寧夏羊排#
③ 大模型根據(jù)輸入的要求推理得到識別結(jié)果,#品類:肉,名稱:羊排#
④ 識別結(jié)果與現(xiàn)有的品類庫進行匹配,如果匹配上則將相應(yīng)的品類返回給品類推薦服務(wù)器,如果匹配不上則返回空。這里,應(yīng)該返回“生鮮-肉類-羊排”
⑤ 品類推薦服務(wù)器再將拿到的識別結(jié)果反饋給客戶端。客戶端展示“生鮮-羊排”
4.1.2 C端架構(gòu)設(shè)計
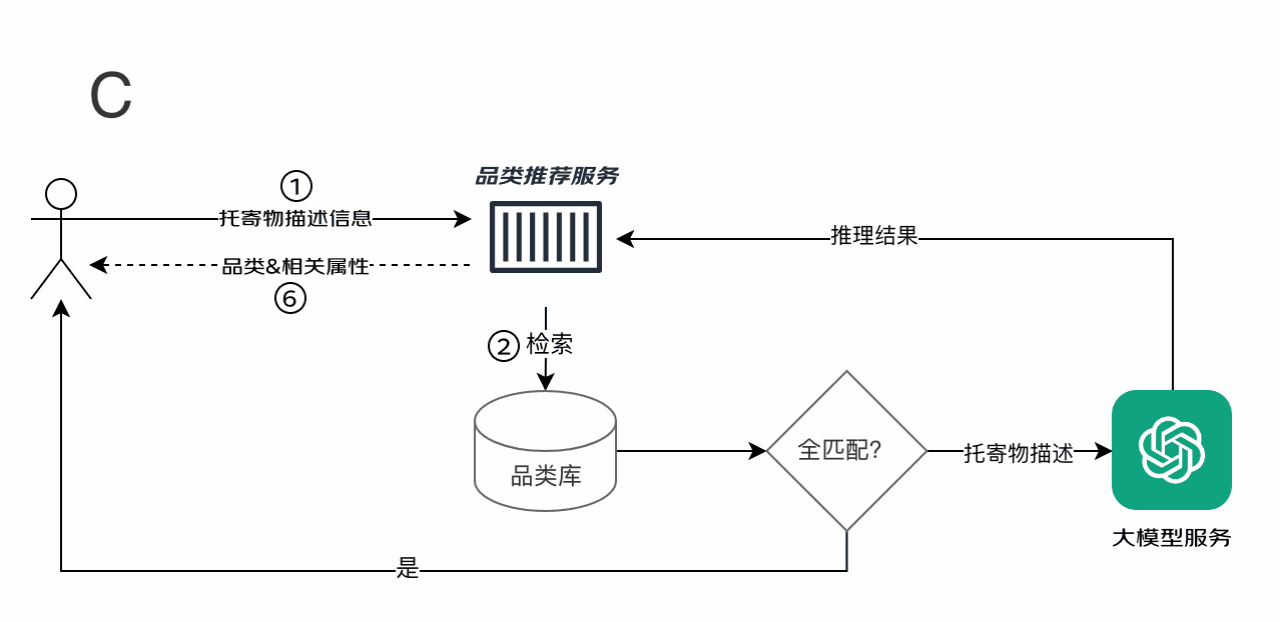
??
TOC流程:
① 托寄物描述信息:客戶端將真實的C運單商品信息推送給品類推薦服務(wù)器進行處理,商品名稱舉例:“一箱大蘋果”
② 品類推薦服務(wù)器首先會在品類庫進行全匹配,如果匹配上,則直接返回給客戶端品類信息,結(jié)束。
③ 如果匹配不上則重復(fù)TOB的第二個步驟,品類推薦服務(wù)器給大模型輸入預(yù)處理后的托寄物描述,預(yù)處理后的托寄物描述可參考如下模式:您的任務(wù)是根據(jù)#物品描述#提取出6個字內(nèi)的物品的品類和名稱,只返回最明確且能體現(xiàn)用戶意圖的那個。忽略地域,品牌,型號,重量,體積,尺寸,數(shù)量,價格,包裝,形容詞等干擾信息。輸出JSON對象:<包含以下鍵:品類 和 名稱>,如果無法提取或確認,則鍵值為空。這里的物品描述為#一箱大蘋果#
④ 大模型根據(jù)輸入的要求推理得到識別結(jié)果,#品類:水果,名稱:蘋果#
⑤ 識別結(jié)果與現(xiàn)有的品類庫三級品類名稱進行匹配,如果匹配上則將相應(yīng)的品類返回給品類推薦服務(wù)器,如果匹配不上則返回空。這里,應(yīng)該返回三級品類#生鮮-水果-蘋果#
⑥ 品類推薦服務(wù)器再將拿到的識別結(jié)果反饋給客戶端。客戶端展示#生鮮-蘋果#
4.2 準(zhǔn)確性校驗
4.2.1 實施前期準(zhǔn)確性校驗
為了驗證大模型識別結(jié)果的準(zhǔn)確性,我們隨機選取了線上1000個不同品類的托寄物運單進行識別,然后將識別結(jié)果進行人工校驗,將大模型匹配后的結(jié)果分為0未匹配、1 匹配且正確、2識別錯誤、3待決(有歧義需要討論)、4有更精準(zhǔn)的選項(有更精確的品類可匹配),去除人工無法識別的情況,最終結(jié)果有88%匹配,正確率在95%以上,基于此次驗證,可以得到結(jié)論:可以將大模型識別結(jié)果應(yīng)用到快遞業(yè)務(wù)中。
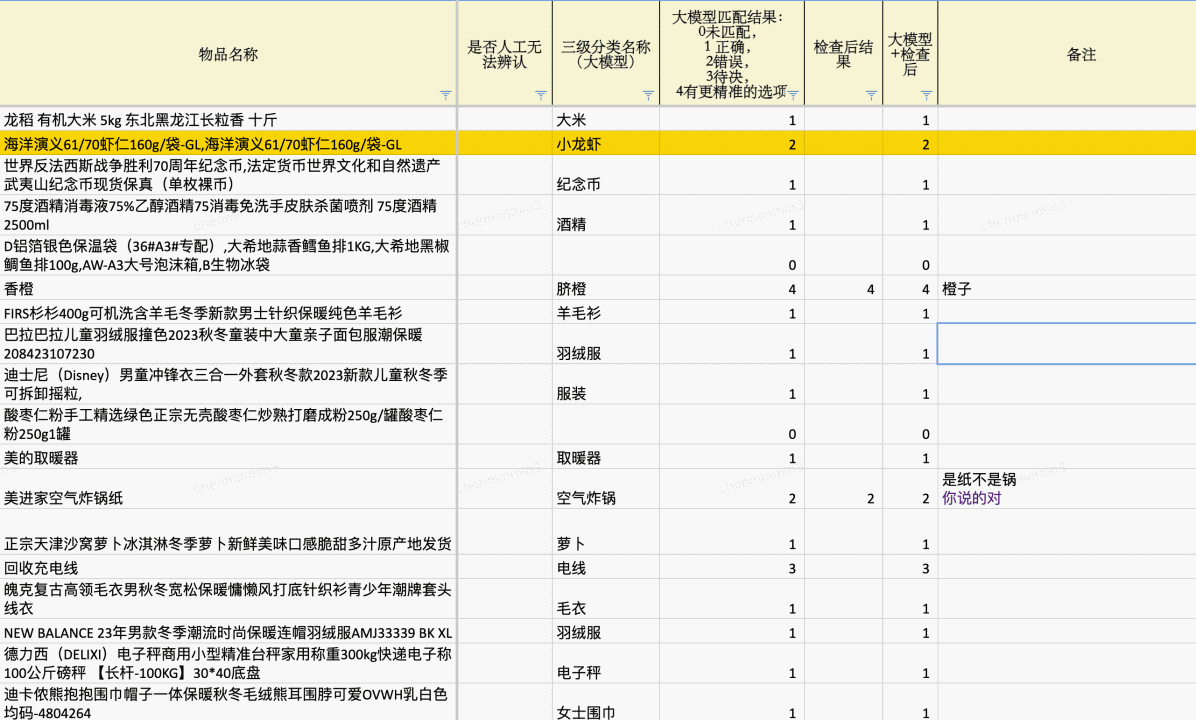
??
4.2.2 實施后期人工干預(yù)矯正
此外,我們還有一個可人工干預(yù)結(jié)果的運營后臺系統(tǒng),大模型識別的結(jié)果會在該平臺上進行展示,業(yè)務(wù)和運營人員可操作結(jié)果,分別為:無法識別、人工修復(fù)、新增品類和確認三級品類無誤,一旦經(jīng)過人工干預(yù),后續(xù)大模型結(jié)果會按照人工干預(yù)的結(jié)果矯正返回。
無法識別:表示無論人還是大模型都無法識別,這類托寄物名稱一般是較短的幾個字,比如一個字或者兩個字,太泛泛無法分析出所屬的類別
人工修復(fù):認為大模型識別錯誤或者不夠準(zhǔn)確,進行人為干預(yù)矯正,后續(xù)大模型識別的結(jié)果會按照矯正后的類別進行返回
新增品類:表示大模型識別的結(jié)果正確,但是無法匹配到現(xiàn)有品類庫中的三級品類,并且經(jīng)過業(yè)務(wù)核實確實缺少該品類,需要增加到現(xiàn)有品類庫中
確認三級品類無誤:表示大模型識別到的結(jié)果正確且能夠匹配到現(xiàn)有品類庫中的三級品類
4.3如何用更少的成本更快速的識別?
在本章節(jié)開頭我們提到了京東快遞業(yè)務(wù)量巨大,如果每一單都進行大模型識別,調(diào)用大模型的使用成本就會很高,業(yè)務(wù)成本無法把控。此外,AI智能識別是需要一定的思考時間,接口響應(yīng)時間有長有短,下單流程不能因為識別接口響應(yīng)較慢影響用戶下單,如何用更少的成本進行更快速的智能識別?也是我們需要解決的一大難題。
為了把控成本,我們對托寄物名稱進行分析,發(fā)現(xiàn)很多運單的托寄物名稱相同,原因是B端商家在發(fā)貨時,使用的基本都是商品名稱,比如每天該商品銷售了1000單,則這1000單的托寄物名稱均為同一商品名稱。同時為了解決大模型接口時效的問題,我們采取的策略是“預(yù)熱”,具體方案如下:
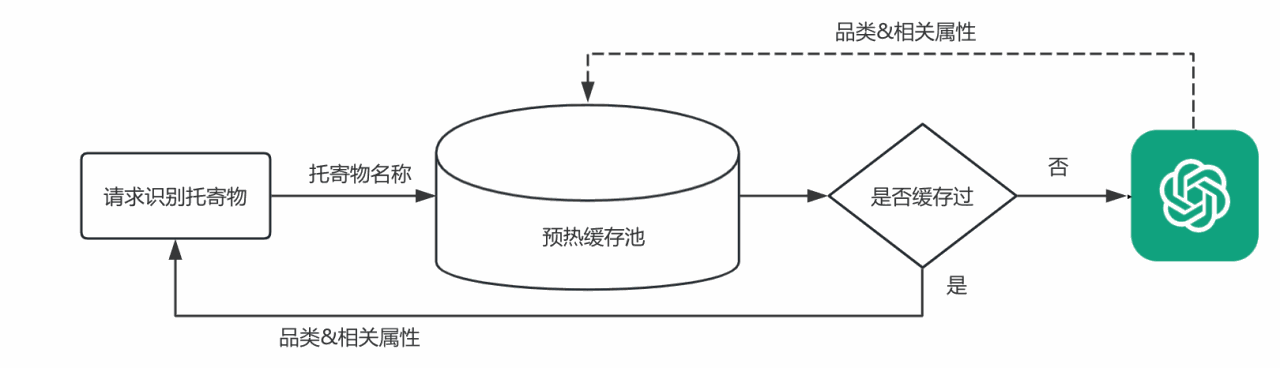
??
設(shè)置一個預(yù)熱緩存,下單進行托寄物識別時,首先在預(yù)熱緩存池中查找是否之前已經(jīng)識別過相同名稱的托寄物,找到則直接返回緩存結(jié)果,找不到則返回空,并同步進行第一次大模型結(jié)果識別,識別后的結(jié)果再次放入緩存池中,等下次有同樣名稱識別時返回使用。
這樣做的好處是:
① 不需要等識別結(jié)果,緩存取值時效能夠得到保證
② 大大減少托寄物使用大模型識別的次數(shù),極大的節(jié)約了成本
4.4 托寄物匹配準(zhǔn)確后的效果
① 一些生鮮、酒水等需要特殊包裝的托寄物,在匹配成正確的品類后,推薦更符合托寄物品類的路線和時效,促進快遞路線更精確化,有效的減少了包裹的破損率,減少客訴
② 推薦更合理的增值服務(wù),提升攬收效率,提高客單價
③ 針對現(xiàn)有品類提出更準(zhǔn)確的命名,自動生成新的品類,補充豐富品類庫,達到品類庫標(biāo)準(zhǔn)化
④ 降低人工投入和糾錯成本
⑤ 生成商家托寄物行業(yè)屬性用戶畫像,定向推送優(yōu)惠政策
下圖是從今年1月至今年6月匹配率數(shù)據(jù)趨勢圖,從圖中可以看到匹配率得到顯著提升,由于目前還在灰度階段,相信隨著后續(xù)逐步放量,托寄物匹配率能達到更高的高度。
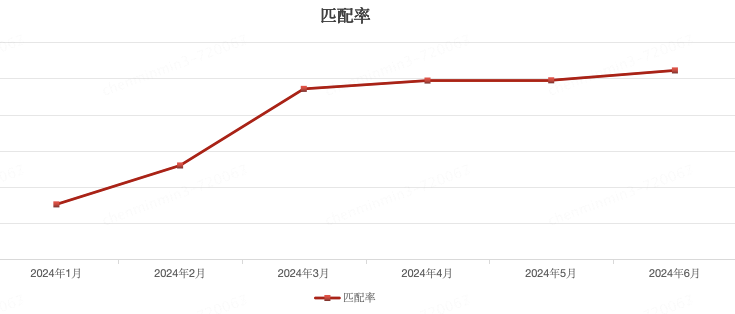
??
五、未來與展望
隨著人工智能、機器學(xué)習(xí)和大數(shù)據(jù)技術(shù)的不斷發(fā)展,托寄物識別技術(shù)的未來展望十分廣闊。托寄物識別技術(shù)的進步將使得物流公司不僅能夠提升物流效率和安全性,還能夠利用這些技術(shù)生成更加細致和深入的商家托寄物行業(yè)屬性用戶畫像。這種用戶畫像的生成,將基于對托寄物品類別、頻率、體積、目的地等多維度數(shù)據(jù)的分析,從而描繪出一個全面的商家物流需求圖譜。具體未來規(guī)劃體現(xiàn)在以下幾點:
個性化增值服務(wù)推薦:通過對托寄物品類型的深入分析,京東快遞能夠為不同客戶推薦更加個性化的增值服務(wù)。例如,對于易碎品,系統(tǒng)會推薦特殊包裝服務(wù);對于高價值物品,推薦保價服務(wù)。這種個性化的服務(wù)推薦不僅提升了客戶的使用體驗,還有助于增加客戶對京東快遞服務(wù)的信賴和滿意度。
預(yù)測未來攬收需求:利用大數(shù)據(jù)和人工智能技術(shù),京東快遞可以準(zhǔn)確預(yù)測未來的攬收需求,提前安排快遞員進行攬收,從而大幅提高攬收效率。這種預(yù)測性攬收策略,不僅優(yōu)化了資源分配,減少了等待時間,還提高了整體的服務(wù)質(zhì)量。
優(yōu)化郵寄路線:通過對托寄物類型和郵寄頻率的分析,京東快遞能夠重新規(guī)劃郵寄路線,特別是對于需求量大的特定類型托寄物,如電子產(chǎn)品,系統(tǒng)可以規(guī)劃專門的運輸路線。
降低運營成本:通過提高托寄物匹配率,京東快遞能夠更精準(zhǔn)地預(yù)測和規(guī)劃物流資源,從而降低無效運輸和重復(fù)分揀的成本。這種成本優(yōu)化直接反映在運營效率的提升上,長期來看,有助于快遞公司在競爭中保持優(yōu)勢,實現(xiàn)可持續(xù)發(fā)展。
高度個性化的服務(wù)提供:通過對商家托寄物行業(yè)屬性的深入了解,物流公司能夠為不同行業(yè)的商家提供更加個性化的物流解決方案。例如,對于經(jīng)常托寄易碎物品的商家,物流公司可以提供特殊的包裝和快遞服務(wù);對于需要跨境物流的商家,提供更加便捷的清關(guān)服務(wù)和國際物流方案。
向推送優(yōu)惠政策:基于商家托寄物行業(yè)屬性用戶畫像,物流公司可以更精準(zhǔn)地定向推送優(yōu)惠政策。這種定向推送不僅能夠提升優(yōu)惠政策的使用率和滿意度,還能夠增強商家的忠誠度。例如,對于常年有大量托寄需求的商家,物流公司可以提供量身定制的折扣方案或增值服務(wù)。
?
參考文獻
[1] 笙婷婷.數(shù)字經(jīng)濟背景下我國跨境電子商務(wù)物流運作模式研究[J].商場現(xiàn)代化,2024,(11):38-40.DOI:10.14013/j.cnki.scxdh.2024.11.045.
[2] 郭永麗,高紅.基于創(chuàng)新創(chuàng)業(yè)的應(yīng)用型農(nóng)村電商物流人才培養(yǎng)模式研究[J].中國儲運,2024,(06):132-133.DOI:10.16301/j.cnki.cn12-1204/f.2024.06.003.
[3] Mun M ,Kim A ,Woo K .Natural Language Processing Application in Nursing Research: A Study Using Text Network Analysis and Topic Modeling.[J].Computers, informatics, nursing : CIN,2024
[4] García P D ,Benito C J ,Pe?alvo G J F .Comparing Natural Language Processing and Quantum Natural Processing approaches in text classification tasks[J].Expert Systems With Applications,2024,254124427
[5] 楊紫超,吳恒,吳悅文,等.基于性能建模的深度學(xué)習(xí)訓(xùn)練任務(wù)調(diào)度綜述[J/OL].軟件學(xué)報,1-21[2024-06-24].https://doi.org/10.13328/j.cnki.jos.007202.
[6] 楊力,陳齊萌,朱俊奇.ChatGPT對物流行業(yè)發(fā)展的影響分析[J].安徽理工大學(xué)學(xué)報(社會科學(xué)版),2024,26(02):19-26.
審核編輯 黃宇
-
AI
+關(guān)注
關(guān)注
87文章
30239瀏覽量
268475 -
智能識別
+關(guān)注
關(guān)注
0文章
200瀏覽量
18114 -
大模型
+關(guān)注
關(guān)注
2文章
2339瀏覽量
2500
發(fā)布評論請先 登錄
相關(guān)推薦
京東物流-智能運輸調(diào)度系統(tǒng)方案 榮獲IF、紅點國際設(shè)計大獎

京東物流與銳捷網(wǎng)絡(luò)合作再深化,共啟智慧物流新紀(jì)元

把大模型做實 把供應(yīng)鏈做透: 京東推出言犀大模型

智能快遞柜中的嵌入式一體機解決方案

NFC協(xié)議分析儀的技術(shù)原理和應(yīng)用場景
京東云智能編程助手與安全大模型雙雙獲獎!

云天勵飛加速推動大模型行業(yè)落地
【必看】2024長三角快遞物流展即將開幕點擊收藏逛展不迷路~

人臉識別模型訓(xùn)練是什么意思
海康威視助力快遞行業(yè)場景數(shù)字化

**十萬級口語識別,離線自然說技術(shù),讓智能照明更懂你**
杭州掀起快遞物流創(chuàng)新浪潮,2024長三角快遞物流展7月共繪智慧物流新藍圖






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論